Антишаблон лишней выборки
Антишаблоны — это распространенные конструкторские недостатки, которые могут привести к неработоспособности программного обеспечения или приложений в стрессовых ситуациях и которые не следует игнорировать. В антишаблоне лишней выборки для бизнес-операции извлекается лишний объем данных, что часто приводит к избыточной нагрузке на систему ввода-вывода и сниженной скорости реагирования.
Примеры антишаблона лишней выборки
Антишаблон может возникнуть, если приложение пытается уменьшить количество запросов ввода-вывода путем извлечения всех данных, которые могут потребоваться. Обычно это связано с излишней компенсацией для антишаблона отправки множественных операций ввода-вывода. Например, приложение может получать сведения о каждом продукте в базе данных. Однако пользователю нужно только подмножество сведений (некоторые могут не интересовать клиентов) и не нужно видеть все продукты одновременно. Даже если пользователь просматривает весь каталог, имеет смысл разбить результаты. Например, чтобы одновременно просматривать только 20 результатов.
Еще одна причина этой проблемы — выполнение некорректных рекомендаций по разработке и программированию. Например, в указанном ниже коде используется Entity Framework, чтобы получить полные сведения по каждому продукту. Затем результаты фильтруются, чтобы возвратить только подмножество полей, отклоняя все остальное. Полный пример см. здесь.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
В указанном ниже примере приложение извлекает данные, чтобы выполнить агрегирование, которое также можно выполнить в базе данных. Приложение вычисляет общий объем продаж путем извлечения каждой записи для всех оплаченных заказов, а затем вычисляет суму этих записей. Полный пример см. здесь.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
В следующем примере показана простая проблема, вызванная тем, как платформа Entity Framework использует LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Приложение пытается найти продукты, с даты продажи (SellStartDate) которых прошло больше недели. В большинстве случаев LINQ to Entities будет преобразовывать предложение where в инструкцию SQL, которая выполняется в базе данных. В этом случает, однако, LINQ to Entities не может сопоставить метод AddDays с SQL. Вместо этого возвращается каждая строка таблицы Product, а результаты фильтруются в памяти.
Вызов метода AsEnumerable указывает, что имеется проблема. Этот метод преобразовывает результаты в интерфейс IEnumerable. Тем не менее IEnumerable поддерживает фильтрацию, которая выполняется на стороне клиента, а не базы данных. По умолчанию LINQ to Entities использует IQueryable, что передает ответственность за фильтрацию источнику данных.
Как исправить антишаблон лишней выборки
Избегайте получения огромных объемов данных, которые могут быстро устареть или быть удалены. Извлекайте только данные, которые нужны для выполнения операции.
Вместо того чтобы извлекать каждый столбец из таблицы, а затем их фильтровать, выберите необходимые столбцы в базе данных.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Аналогичным образом выполните агрегирование в базе данных, а не в памяти приложения.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
При использовании Entity Framework убедитесь в том, что запросы LINQ разрешаются с помощью интерфейса IQueryable, а не IEnumerable. Возможно, может потребоваться настроить запрос для использования только функций, которые можно сопоставить с источником данных. Вы можете выполнить рефакторинг указанного выше примера, чтобы удалить метод AddDays из очереди, что позволяет выполнить фильтрацию в базе данных.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Рекомендации
В некоторых случаях можно повысить производительность путем горизонтального секционирования данных. Если различные операции получают доступ к различным атрибутам данных, горизонтальное секционирование может уменьшить количество конфликтов. Зачастую большинство операций выполняются для небольшого подмножества данных, поэтому распределение этой нагрузки может повысить производительность. Ознакомьтесь со статьей Секционирование данных.
Реализуйте разбиение и извлекайте только ограниченное количество записей одновременно в операциях, которые должны поддерживать неограниченные запросы. Например, если клиент просматривает каталог продуктов, за раз можно отображать только одну страницу результатов.
По возможности воспользуйтесь функциями, встроенными в хранилище данных. Например, базы данных SQL обычно предоставляют агрегатные функции.
Если вы используете хранилище данных, которое не поддерживает соответствующую функцию, например агрегирование, можно хранить вычисленный результат в другом месте и обновлять значения при добавлении и обновлении записей, чтобы приложение не пересчитывало значение каждый раз, когда оно требуется.
Если вы видите, что запросы извлекают большое количество полей, просмотрите исходный код, чтобы определить, являются ли все эти поля обязательными. Иногда эти запросы являются результатом неверно созданного запроса
SELECT *.Аналогичным образом, если есть запросы, которые извлекают большое количество записей, это может означать, что приложение выполняет неправильную фильтрацию данных. Убедитесь, что все эти записи действительно необходимы. По возможности выполните фильтрацию на стороне базы данных, например с помощью предложений
WHEREв SQL.Разгрузка обработки в базу данных не всегда является лучшим вариантом. Этот подход можно использовать, только если база данных разработана и оптимизирована для выполнения этой задачи. Большинство систем базы данных оптимизированы для выполнения некоторых функций, однако их нельзя использовать в качестве модулей приложения общего назначения. Дополнительные сведения см. в статье Антишаблон занятости базы данных.
Как выявить антишаблон лишней выборки
Признаками лишней выборки являются высокая задержка и низкая пропускная способность. Если данные извлекаются из хранилища данных, также может увеличиться число конфликтов. Конечные пользователи, скорее всего, сообщают о расширенных времени отклика или сбоях, вызванных истечением времени ожидания служб. Эти ошибки могут возвращать ошибки HTTP 500 (внутренний сервер) или ошибки HTTP 503 (служба недоступна). Изучите журналы событий веб-сервера, которые, скорее всего, содержат более подробные сведения о причинах и обстоятельствах возникновения ошибок.
Признаки этого антишаблона и некоторой полученной телеметрии могут быть очень похожи на признаки антишаблона монолитной сохраняемости.
Чтобы определить причину, сделайте следующее:
- Определите медленные рабочие нагрузки или транзакции, выполнив нагрузочное тестирование, наблюдение за процессами или другие методы для сбора данных инструментирования.
- Понаблюдайте за шаблонами поведения в системе. Проверьте, имеются ли определенные ограничения для количества транзакций в секунду или количества пользователей.
- Выполните корреляцию экземпляров медленных рабочих нагрузок с шаблонами поведения.
- Определите используемые хранилища данных. Для каждого источника данных выполните анализ данных телеметрии нижнего уровня, чтобы просмотреть поведение операций.
- Определите все медленно выполняемые запросы, которые ссылаются на эти источники данных.
- Выполните анализ медленно выполняемых запросов для конкретных ресурсов и выясните, как используются и потребляются данные.
Обратите внимание, имеются ли любые из следующих признаков:
- Частые и большие запросы ввода-вывода к тому самому ресурсу или хранилищу данных.
- Конфликты в общем ресурсе или хранилище данных.
- Операцию, которая часто получает большие объемы данных по сети.
- Приложения и службы, которые тратят много времени на ожидание завершения операций ввода-вывода.
Пример диагностики
Для указанных выше примеров можно выполнить действия из следующих разделов.
Определение медленных рабочих нагрузок
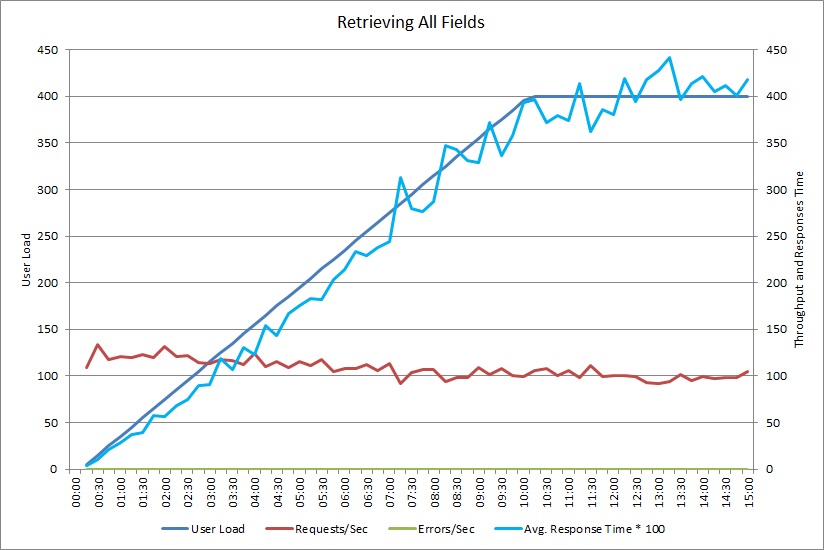
На приведенном ниже графике показаны результаты производительности из нагрузочного теста, в котором было смоделировано до 400 параллельных пользователей, выполняющих указанный выше метод GetAllFieldsAsync. Пропускная способность медленно снижается по мере увеличения нагрузки. Среднее время отклика возрастает по мере увеличения рабочей нагрузки.
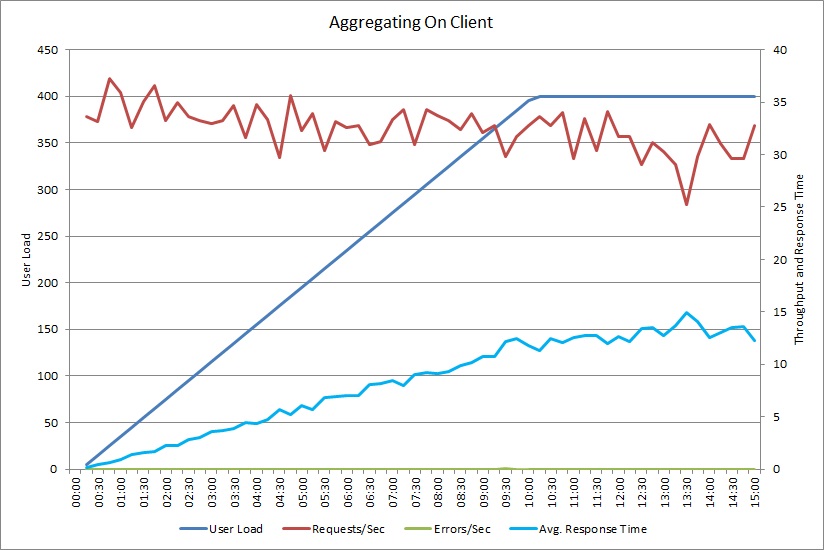
Нагрузочный текст операции AggregateOnClientAsync демонстрирует идентичный шаблон. Объем запросов достаточно стабильный. Среднее время отклика увеличивается вместе с рабочей нагрузкой, однако более медленно, чем на предыдущем графике.
Корреляция медленных рабочих нагрузок с шаблонами поведения
Любая корреляция между регулярными периодами высокого использования и замедленной производительности может указать на проблемные области. Тщательно изучите профиль производительности функциональности, которая предположительно медленно выполняется, чтобы определить, совпадает ли она с нагрузочным тестированием, выполненным ранее.
Выполните нагрузочный тест той же функциональности, используя поэтапные пользовательские нагрузки, чтобы определить точку, в которой производительность существенно снижается или происходит полный сбой. Если эта точка находится в пределах границ ожидаемого использования в реальном времени, изучите способ реализации функциональности.
Операция с низкой производительностью не всегда является проблемой, а именно если она не выполняется, когда система сильно загружена, не критически важная по времени и не влияет отрицательно на производительность важных операций. Например, создание ежемесячной операционной статистики может быть длительной операцией. Возможно, ее лучше выполнить как процесс пакетной обработки и запустить в качестве низкоприоритетного задания. С другой стороны, запрос каталога продуктов клиентами — это критически важная бизнес-операция. Сосредоточьтесь на телеметрии, созданной этими критически важными операциями, чтобы увидеть, как изменяется производительность в периоды высокой нагрузки.
Определение источников данных в медленных рабочих нагрузках
Если вы подозреваете, что низкая производительность службы связана со способом извлечения данных, проследите, как приложение взаимодействует с используемыми репозиториями. Выполните мониторинг активной системы, чтобы узнать, доступ к каким ресурсам осуществляется во время периодов низкой производительности.
Для каждого источника данных выполните инструментирование системы, чтобы получить следующие данные:
- Частоту доступа к каждому хранилищу данных.
- Объем входящих и исходящих данных в хранилище данных.
- Время этих операций, в частности задержки запросов.
- Характер и частоту всех ошибок, возникающих при доступе к каждому хранилищу данных в условиях обычной загрузки.
Сравните эти сведения с объемом данных, возвращенных приложением клиенту. Отслеживайте соотношение объема данных, возвращенного хранилищем данных, с объемом данных, возвращенным клиенту. В случае больших различий определите, извлекает ли приложение ненужные данные.
Вы можете получить эти данные, отслеживая активную систему и выполнив трассировку жизненного цикла каждого пользовательского запроса. Кроме того, можно смоделировать набор искусственных рабочих нагрузок и выполнить их в тестовой системе.
На приведенных ниже графиках показаны данные телеметрии, собранные с помощью New Relic APM во время выполнения нагрузочного теста метода GetAllFieldsAsync. Обратите внимание на разницу между объемами данных, полученными из базы данных, и соответствующих ответов HTTP.

Для каждого запроса база данных вернула 80 503 байт, но ответ клиенту содержит только 19 855 байт (около 25 % от размера ответа базы данных). Размер данных, возвращенных клиенту, может отличаться в зависимости от формата. Для этого нагрузочного теста клиент запросил данные JSON. Размер ответа отдельного тестирования с помощью XML (не показано) составлял 35 655 байт или 44 % от размера ответа базы данных.
Нагрузочный тест метода AggregateOnClientAsync показывает более предельные результаты. В этом случае в каждом тесте выполнялся запрос, который извлекал более 280 КБ данных из базы данных, однако размер запроса JSON составлял всего лишь 14 байтов. Такое сильное расхождение связано с тем, что метод рассчитывал агрегированный результат из большого объема данных.

Определение и анализ медленных запросов
Найдите запросы базы данных, которые используют больше всего ресурсов и имеют наибольшее время обработки. Вы можете выполнить инструментирование, чтобы определить время начала и завершения многих операций базы данных. Многие хранилища данных содержат подробные сведения о том, как выполняются и оптимизируются запросы. Например, панель производительности запросов на портале управления Базы данных SQL Azure позволяет выбрать запрос и просмотреть подробные сведения о производительности среды выполнения. Запрос, созданный с помощью операции GetAllFieldsAsync, выглядит так:

Реализация решения и проверка результатов
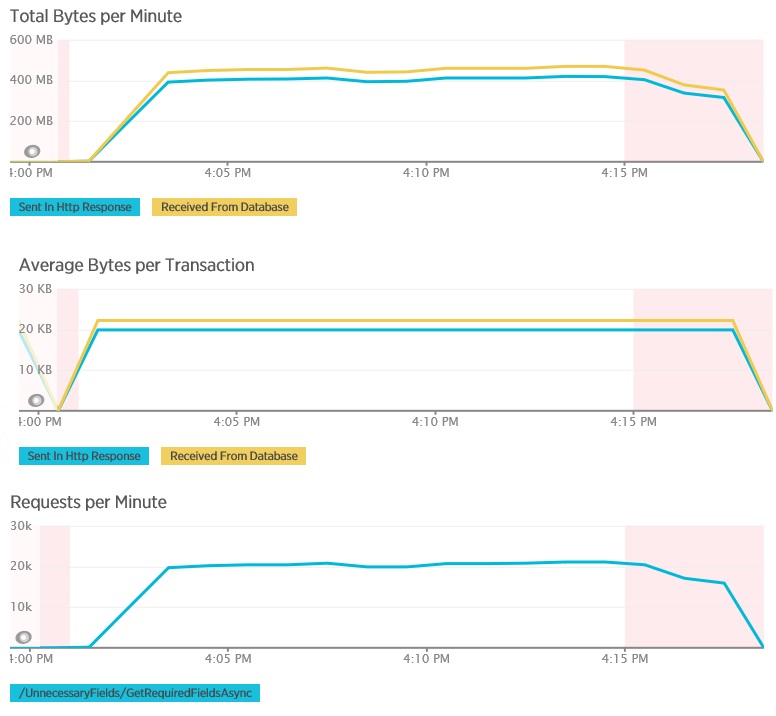
Когда метод GetRequiredFieldsAsync будет использовать инструкцию SELECT на стороне базы данных, нагрузочное тестирование будет отображать следующие результаты.

Этот нагрузочный тест использовал то же развертывание и ту же имитированную рабочую нагрузку 400 параллельных пользователей, что и раньше. На графике показана гораздо меньшая задержка. Время отклика растет вместе с нагрузкой примерно до 1,3 секунд по сравнению с 4 секундами в описанном выше случае. Пропускная способность также является более высокой при 350 запросах в секунду по сравнению со 100, как ранее. Объем данных, полученных из базы данных, теперь более точно соответствует размеру сообщений с ответом HTTP.
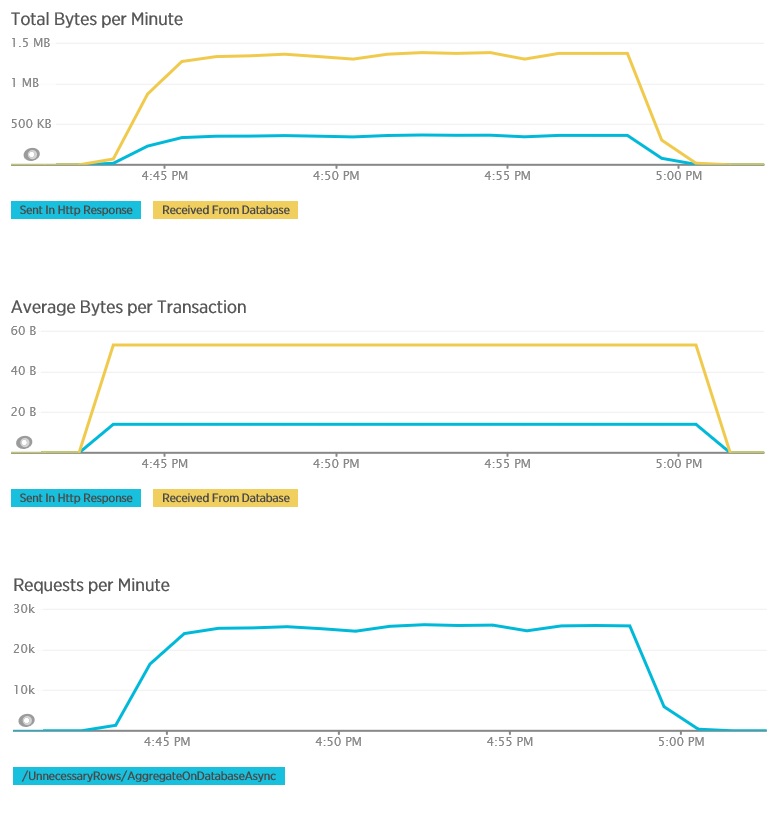
При нагрузочном тестировании с помощью метода AggregateOnDatabaseAsync будут получены следующие результаты:

Среднее время отклика теперь минимальное. Это последовательность интенсивного повышения производительности, которая в первую очередь вызвана огромным снижением операций ввода-вывода в базе данных.
Ниже приведены соответствующие данные телеметрии для метода AggregateOnDatabaseAsync. Объем данных, полученных из базы данных, был значительно снижен (с 280 КБ до 53 байтов за одну транзакцию). В результате максимальное количество непрерывных запросов в минуту было увеличено примерно с 2000 до 25 000.
Связанные ресурсы
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по