Руководство по связям "многие ко многим"
Эта статья предназначена для моделирователя данных, работающего с Power BI Desktop. В нем описаны три различных сценария моделирования "многие ко многим". Он также предоставляет рекомендации по успешному проектированию их в моделях.
Примечание.
Общие сведения о связях модели не рассматриваются в этой статье. Если вы не знакомы с связями, их свойствами или настройкой, рекомендуем сначала прочитать связи модели в статье Power BI Desktop .
Важно также понимать схему звездочки. Дополнительные сведения см. в статье "Общие сведения о схеме звезды" и важности для Power BI.
На самом деле есть три сценария "многие ко многим". Они могут возникать при необходимости:
- Связывание двух таблиц типов измерений
- Связывание двух таблиц типа фактов
- Связана с таблицами типа фактов более высокого уровня, если таблица типа фактов хранит строки на более высоком уровне, чем строки таблицы типа измерения
Примечание.
Power BI теперь изначально поддерживает связи "многие ко многим". Дополнительные сведения см. в статье "Применение связей "многие ко многим" в Power BI Desktop.
Связывание измерений "многие ко многим"
Рассмотрим первый тип сценария "многие ко многим" с примером. Классический сценарий относится к двум сущностям: банковским клиентам и банковским счетам. Учитывайте, что у клиентов может быть несколько учетных записей, а у них может быть несколько клиентов. Если у учетной записи несколько клиентов, они обычно называются общими владельцами учетных записей.
Моделирование этих сущностей прямо вперед. Одна таблица типа измерения хранит учетные записи, а другая таблица типа измерения хранит клиентов. Как и в таблицах типов измерений, в каждой таблице есть столбец идентификатора. Для моделирования связи между двумя таблицами требуется третья таблица. Эта таблица обычно называется мостовой таблицей. В этом примере предназначено хранить одну строку для каждой связи с учетной записью клиента. Интересно, что если эта таблица содержит только столбцы идентификаторов, она называется таблицей фактов без фактов.
Ниже приведена упрощенная схема модели трех таблиц.
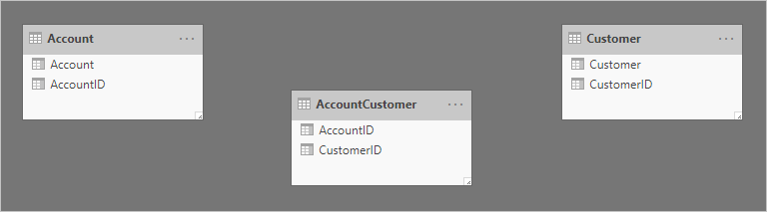
Первая таблица называется Account, и она содержит два столбца: AccountID и Account. Вторая таблица называется AccountCustomer и содержит два столбца: AccountID и CustomerID. Третья таблица называется Customer и содержит два столбца: CustomerID и Customer. Связи не существуют между таблицами.
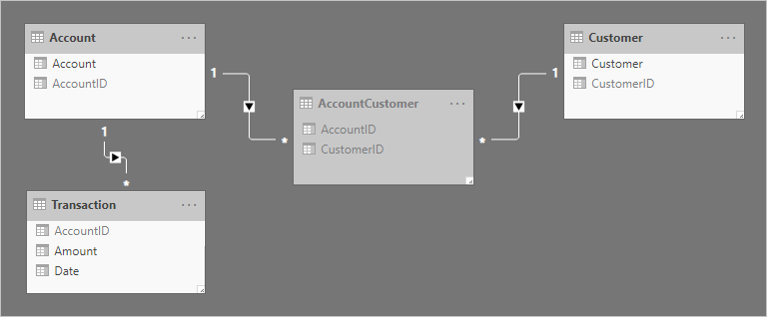
Для связи таблиц добавляются две связи "один ко многим". Ниже приведена обновленная схема модели связанных таблиц. Добавлена таблица типа фактов с именем Transaction . Он записывает транзакции учетной записи. Таблица бриджинга и все столбцы идентификаторов были скрыты.
Чтобы узнать, как работает распространение фильтра связей, схема модели была изменена, чтобы отобразить строки таблицы.
Примечание.
Невозможно отобразить строки таблицы на схеме модели Power BI Desktop. Это сделано в этой статье для поддержки обсуждения с четкими примерами.

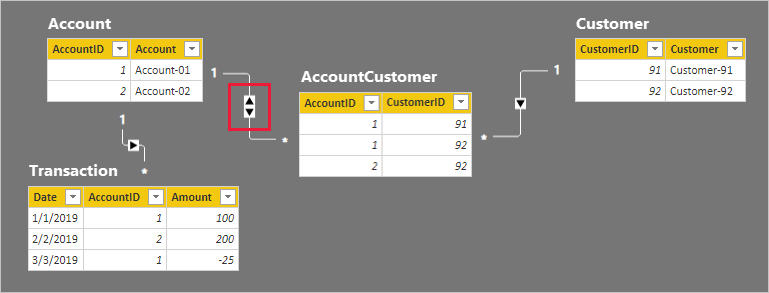
Сведения о строке для четырех таблиц описаны в следующем маркированном списке:
- В таблице "Учетная запись" есть две строки:
- AccountID 1 предназначен для учетной записи-01
- AccountID 2 — для учетной записи-02
- В таблице Customer есть две строки:
- CustomerID 91 предназначен для Customer-91
- CustomerID 92 предназначен для Customer-92
- Таблица AccountCustomer имеет три строки:
- AccountID 1 связан с CustomerID 91
- AccountID 1 связан с CustomerID 92
- AccountID 2 связан с CustomerID 92
- Таблица транзакций содержит три строки:
- Дата 1 января 2019 года, AccountID 1, сумма 100
- Дата 2 февраля 2019 года, AccountID 2, сумма 200
- Дата 3 марта 2019 года, AccountID 1, сумма -25
Давайте посмотрим, что происходит при запросе модели.
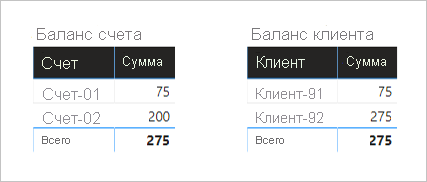
Ниже приведены два визуальных элемента, которые суммируют столбец "Сумма " из таблицы "Транзакция ". Первые визуальные группы по учетной записи, поэтому сумма столбцов "Сумма" представляет баланс учетной записи. Вторая визуальная группа по клиенту, поэтому сумма столбцов "Сумма" представляет баланс клиента.
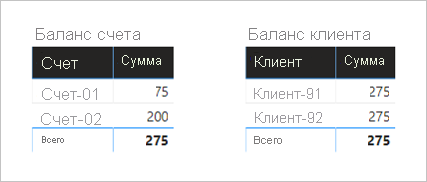
Первый визуальный элемент называется "Баланс учетной записи" и имеет два столбца: "Учетная запись " и "Сумма". Отображается следующий результат:
- Сумма баланса на счете-01 составляет 75
- Сумма баланса на счете 02 составляет 200
- Общий объем составляет 275
Второй визуальный элемент называется Customer Balance, и он имеет два столбца: Customer и Amount. Отображается следующий результат:
- Сумма баланса клиента-91 составляет 275
- Сумма баланса клиента-92 составляет 275
- Общий объем составляет 275
Краткий обзор строк таблицы и визуальный элемент "Баланс учетной записи " показывает, что результат правильный, для каждой учетной записи и суммы. Это связано с тем, что каждая группа учетных записей приводит к распространению фильтра в таблицу транзакций для этой учетной записи.
Однако что-то не отображается в визуальном элементе Customer Balance . Каждый клиент в визуальном элементе "Баланс клиента" имеет тот же баланс, что и общий баланс. Этот результат может быть правильным, только если каждый клиент был совместным владельцем каждой учетной записи. Это не так в этом примере. Проблема связана с распространением фильтров. Она не будет передаваться в таблицу транзакций.
Следуйте указаниям фильтра связей из таблицы Customer в таблицу транзакций. Должно быть очевидно, что связь между таблицей Account и AccountCustomer распространяется в неправильном направлении. Направление фильтра для этой связи должно иметь значение "Оба".
Как ожидалось, не было изменений в визуальном элементе "Баланс учетной записи ".
Однако визуальные элементы Customer Balance теперь отображают следующий результат:
- Сумма баланса "Клиент-91" составляет 75
- Сумма баланса клиента-92 составляет 275
- Общий объем составляет 275
Визуальный элемент "Баланс клиентов" теперь отображает правильный результат. Следуйте указаниям фильтра для себя и узнайте, как были рассчитаны балансы клиентов. Кроме того, понять, что визуальный итог означает всех клиентов.
Кто-то не знакомы с связями модели может заключить, что результат неверный. Они могут попросить: Почему не общий баланс для Customer-91 и Customer-92 равны 350 (75 + 275)?
Ответ на их вопрос заключается в понимании отношений "многие ко многим". Каждый баланс клиента может представлять собой добавление нескольких балансов учетных записей, поэтому балансы клиентов не являются аддитивными.
Руководство по использованию измерений "многие ко многим"
При наличии связи "многие ко многим" между таблицами типов измерений мы предоставляем следующие рекомендации:
- Добавление каждой связанной сущности "многие ко многим" в качестве таблицы модели, обеспечивая наличие уникального столбца идентификатора (идентификатора)
- Добавление таблицы бриджинга для хранения связанных сущностей
- Создание связей "один ко многим" между тремя таблицами
- Настройте двунаправленную связь, чтобы разрешить распространение фильтров продолжать работу с таблицами типа фактов
- Если у него нет отсутствующих значений идентификатора, задайте для свойства Is Nullable столбцов ИДЕНТИФИКАТОРа значение FALSE. Обновление данных завершится ошибкой, если отсутствующие значения являются источником
- Скрыть мостовую таблицу (если она не содержит дополнительные столбцы или меры, необходимые для создания отчетов)
- Скрытие столбцов идентификаторов, которые не подходят для создания отчетов (например, когда идентификаторы являются суррогатными ключами)
- Если имеет смысл оставить столбец идентификатора видимым, убедитесь, что он находится на слайде связи "один" — всегда скрывает боковой столбец "многие". Это обеспечивает лучшую производительность фильтра.
- Чтобы избежать путаницы или неправильной интерпретации, сообщите о объяснениях пользователям отчета— вы можете добавить описания с текстовыми полями или подсказками визуального заголовка.
Мы не рекомендуем напрямую связывать таблицы типа "многие ко многим". Этот подход к проектированию требует настройки связи с карта инальностью "многие ко многим". Концептуально его можно достичь, но подразумевается, что связанные столбцы будут содержать повторяющиеся значения. Однако это хорошо принятая практика проектирования, но в таблицах типов измерений есть столбец идентификатора. Таблицы типа измерения всегда должны использовать столбец идентификатора в качестве одной стороны связи.
Связь с фактами "многие ко многим"
Второй тип сценария "многие ко многим" включает в себя связывание двух таблиц типа фактов. Две таблицы типа фактов могут быть связаны напрямую. Этот метод проектирования может быть полезным для быстрого и простого изучения данных. Однако и быть ясным, мы, как правило, не рекомендуем этот подход к проектированию. Мы объясним, почему далее в этом разделе.
Рассмотрим пример, который включает в себя две таблицы типа фактов: Порядок и выполнение. Таблица order содержит одну строку для каждой строки заказа, а таблица "Выполнение " может содержать ноль или несколько строк на строку заказа. Строки в таблице заказов представляют заказы на продажу. Строки в таблице "Выполнение " представляют элементы заказа, которые были отправлены. Связь "многие ко многим" относится к двум столбцам OrderID с распространением фильтров только из таблицы заказов (выполнение фильтров заказов).
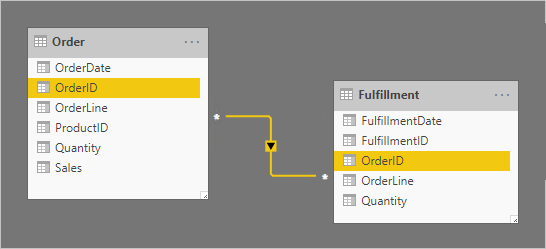
Связь карта inality имеет значение "многие ко многим" для поддержки сохранения повторяющихся значений OrderID в обеих таблицах. В таблице Order повторяющиеся значения OrderID могут существовать, так как порядок может иметь несколько строк. В таблице "Выполнение" повторяющиеся значения OrderID могут существовать, так как заказы могут иметь несколько строк, а строки заказов могут выполняться многими отгрузками.
Давайте рассмотрим строки таблицы. В таблице "Выполнение" обратите внимание, что линии заказов могут выполняться несколькими отгрузками. (Отсутствие строки заказа означает, что заказ еще не выполнен.)
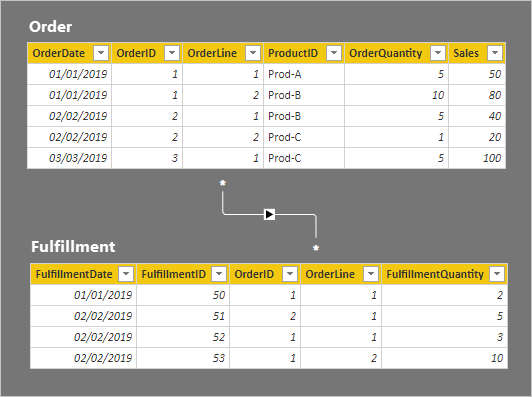
Сведения о строке для двух таблиц описаны в следующем маркированном списке:
- Таблица Order содержит пять строк:
- OrderDate 1 января 2019 года, OrderID 1, OrderLine 1, ProductID Prod-A, OrderQuantity 5, Sales 50
- OrderDate 1 января 2019 г., OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- OrderDate 2 февраля 2019 г., OrderID 2, OrderLine 1, ProductID Prod-B, OrderQuantity 5, Sales 40
- OrderDate 2 февраля 2019 г., OrderID 2, OrderLine 2, ProductID Prod-C, OrderQuantity 1, Sales 20
- OrderDate 3 марта 2019 г., OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- Таблица выполнения содержит четыре строки:
- Выполнение 1 января 2019 года, ВыполнениеID 50, OrderID 1, OrderLine 1, ВыполнениеQuantity 2
- Выполнение 2 февраля 2019 года, ВыполнениеID 51, OrderID 2, OrderLine 1, ВыполнениеQuantity 5
- Выполнение 2 февраля 2019 года, ВыполнениеID 52, OrderID 1, OrderLine 1, ВыполнениеQuantity 3
- Выполнение 1 января 2019 года, ВыполнениеID 53, OrderID 1, OrderLine 2, ВыполнениеQuantity 10
Давайте посмотрим, что происходит при запросе модели. Ниже приведен визуальный элемент сравнения порядка и количества выполнения по столбцу OrderID таблицы OrderID.

Визуальный элемент представляет точный результат. Однако полезность модели ограничена— можно фильтровать или группировать только по столбцу OrderID таблицы OrderID.
Руководство по использованию фактов "многие ко многим"
Как правило, мы не рекомендуем использовать две таблицы типа фактов напрямую с использованием много ко многим карта inality. Основная причина заключается в том, что модель не обеспечивает гибкость в способах фильтрации визуальных элементов или групп. В примере визуальные элементы можно фильтровать или группировать по столбцу OrderID таблицы OrderID. Дополнительная причина связана с качеством данных. Если данные имеют проблемы целостности, возможно, некоторые строки могут быть опущены во время запроса из-за характера ограниченной связи. Дополнительные сведения см. в разделе "Отношения модели" в Power BI Desktop (оценка связей).
Вместо прямого связывания таблиц типа фактов рекомендуется внедрить принципы проектирования схемы Star. Это можно сделать, добавив таблицы типа измерения. Затем таблицы типа измерения относятся к таблицам типа фактов с помощью связей "один ко многим". Такой подход к проектированию является надежным, так как он предоставляет гибкие возможности создания отчетов. Он позволяет фильтровать или группировать с помощью любого столбца типа измерения и суммировать любую связанную таблицу типа фактов.
Рассмотрим лучшее решение.
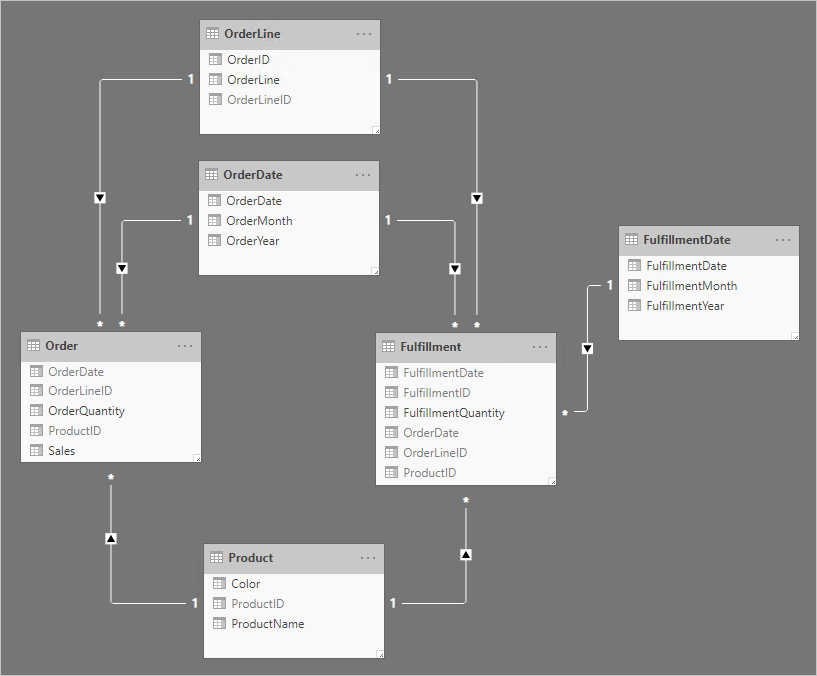
Обратите внимание на следующие изменения дизайна:
- Теперь модель содержит четыре дополнительных таблицы: OrderLine, OrderDate, Product и FulfillmentDate
- Четыре дополнительные таблицы — это все таблицы типов измерений, а связи "один ко многим" относят эти таблицы к таблицам типа фактов.
- Таблица OrderLine содержит столбец OrderLineID, представляющий значение OrderID, умноженное на 100, а также значение OrderLine — уникальный идентификатор для каждой строки заказа.
- Таблицы Заказа и выполнения теперь содержат столбец OrderLineID, и они больше не содержат столбцы OrderID и OrderLine.
- Таблица "Выполнение" теперь содержит столбцы OrderDate и ProductID
- Таблица "Выполнение" относится только к таблице "Выполнение "
- Все столбцы уникальных идентификаторов скрыты
Использование принципов проектирования схемы звезды дает следующие преимущества:
- Визуальные элементы отчета могут фильтровать или группировать по любому видимому столбцу из таблиц типа измерения
- Визуальные элементы отчета могут суммировать любой видимый столбец из таблиц типа фактов
- Фильтры, применяемые к таблицам OrderLine, OrderDate или Product , будут распространяться в обе таблицы типа фактов.
- Все связи являются "один ко многим", и каждая связь является регулярной связью. Проблемы целостности данных не будут маскированы. Дополнительные сведения см. в разделе "Отношения модели" в Power BI Desktop (оценка связей).
Связь с более высокими зернистыми фактами
Этот сценарий "многие ко многим" очень отличается от других, уже описанных в этой статье.
Рассмотрим пример с четырьмя таблицами: Date, Sales, Product и Target. Таблицы типа "Дата " и "Продукт " — это таблицы типов измерений, а связи "один ко многим" относятся к таблице "Тип фактов продаж ". До сих пор он представляет хорошую схему звезды. Однако целевая таблица еще не связана с другими таблицами.
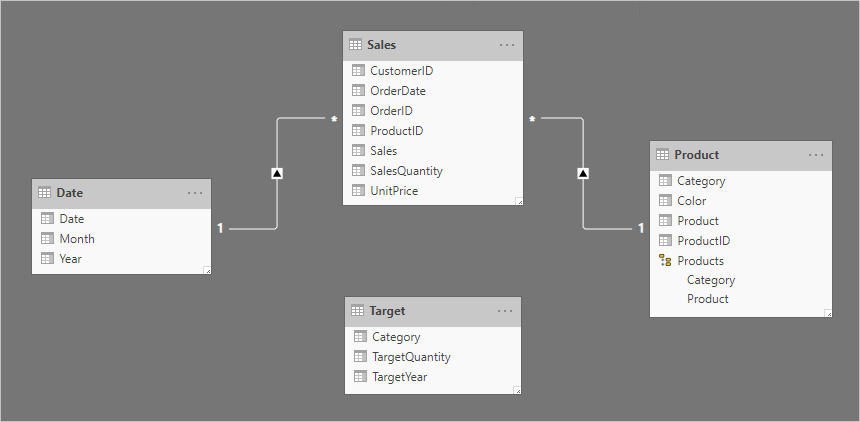
Таблица Target содержит три столбца: Category, TargetQuantity и TargetYear. Строки таблицы показывают степень детализации года и категории продуктов. Другими словами, целевые показатели, используемые для измерения производительности продаж, устанавливаются каждый год для каждой категории продуктов.
Так как целевая таблица хранит данные на более высоком уровне, чем таблицы типа измерения, невозможно создать связь "один ко многим". Ну, это правда только для одного из отношений. Давайте рассмотрим, как целевая таблица может быть связана с таблицами типов измерений.
Связь с более высоким периодом времени зерна
Связь между таблицами Date и Target должна быть связью "один ко многим". Это связано с тем, что значения столбца TargetYear являются датами. В этом примере каждое значение столбца TargetYear является первой датой целевого года.
Совет
При хранении фактов в более высокую степень детализации по сравнению с днем задайте для типа данных столбца значение Date (или Кто le число, если вы используете ключи даты). В столбце сохраните значение, представляющее первый день периода времени. Например, год записывается как 1 января года, а месячный период записывается в первый день этого месяца.
Однако необходимо принять меры, чтобы гарантировать, что фильтры на уровне месяца или даты дают значимый результат. Без специальной логики вычисления визуальные элементы отчетов могут сообщать о том, что целевые даты буквально первый день каждого года. Все остальные дни (и все месяцы, кроме января), обобщают целевое количество как ПУСТОе.
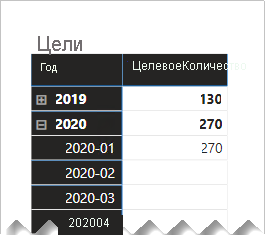
В следующем визуальном элементе матрицы показано, что происходит, когда пользователь отчета детализации от года до месяца. Визуальный элемент суммирует столбец TargetQuantity . (The Отображение элементов без параметра данных было включено для строк матрицы.)
Чтобы избежать этого поведения, рекомендуется управлять суммированием данных фактов с помощью мер. Одним из способов управления суммированием является возврат BLANK при запросе периодов времени нижнего уровня. Другой способ , определенный с некоторыми сложными значениями DAX, заключается в определении значений между периодами времени нижнего уровня.
Рассмотрим следующее определение меры, использующее функцию DAX ISFILTERED . Он возвращает значение только в том случае, если столбцы Date или Month не фильтруются.
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
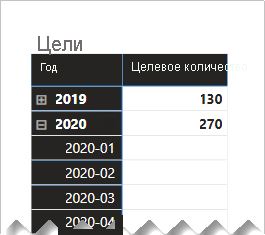
В следующем визуальном элементе матрицы теперь используется мера "Целевое количество ". В нем показано, что все ежемесячные целевые объемы пусты.
Связь с более высоким уровнем зерна (не дата)
Другой подход к проектированию требуется при связывании столбца, отличного от даты, из таблицы типа измерения в таблицу типа фактов (и она находится на более высоком уровне, чем таблица типа измерения).
Столбцы категории (из таблиц Product и Target ) содержат повторяющиеся значения. Таким образом, нет "одного" для отношений "один ко многим". В этом случае необходимо создать связь "многие ко многим". Связь должна распространять фильтры в одном направлении из таблицы типа измерения в таблицу фактов.
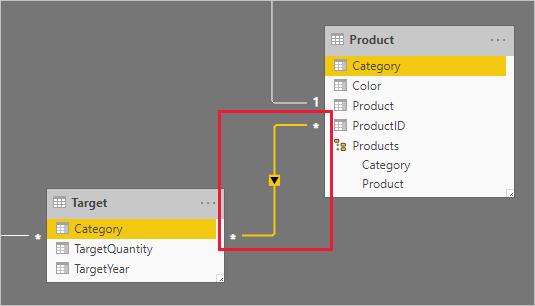
Давайте рассмотрим строки таблицы.
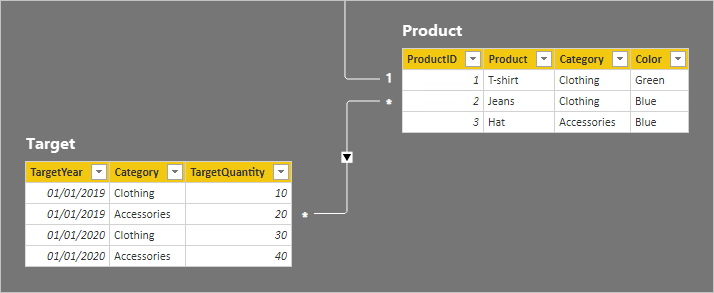
В таблице Target есть четыре строки: две строки для каждого целевого года (2019 и 2020) и две категории (одежда и аксессуары). В таблице Product есть три продукта. Два принадлежат к категории одежды, и один принадлежит категории аксессуаров. Один из цветов одежды зеленый, и остальные два являются голубыми.
Визуальный элемент таблицы сгруппирован по столбцу "Категория " из таблицы Product приводит к следующему результату.
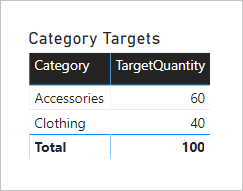
Этот визуальный элемент создает правильный результат. Теперь рассмотрим, что происходит, когда столбец Color из таблицы Product используется для группировки целевого количества.

Визуальный элемент создает неправильное представление данных. Что происходит здесь?
Фильтр по столбцу Color из таблицы Product приводит к двум строкам. Одна из строк относится к категории "Одежда", а другая — для категории "Аксессуары". Эти два значения категорий распространяются в качестве фильтров в целевую таблицу. Другими словами, поскольку цвет синим цветом используется продуктами из двух категорий, эти категории используются для фильтрации целевых объектов.
Чтобы избежать этого поведения, как описано ранее, рекомендуется управлять суммированием данных фактов с помощью мер.
Рассмотрим следующее определение меры. Обратите внимание, что все столбцы таблицы Product , находящиеся под уровнем категории, проверяются для фильтров.
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
В следующем визуальном элементе таблицы теперь используется мера "Целевое количество ". В нем показано, что все целевые значения цвета пусты.
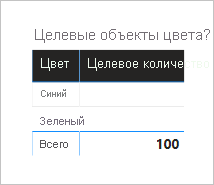
Окончательный дизайн модели выглядит следующим образом.
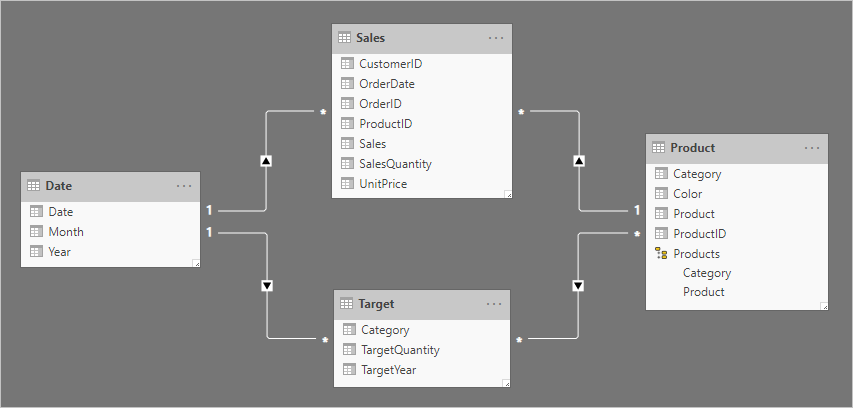
Руководство по более высокому зерню
Если необходимо связать таблицу типа измерения с таблицей типа фактов, а таблица типа фактов хранит строки на более высоком уровне, чем строки таблицы типа измерения, мы предоставляем следующее руководство.
- Для более высоких дат фактов зерна:
- В таблице типа фактов сохраните первую дату периода времени.
- Создание связи "один ко многим" между таблицей дат и таблицей типа фактов
- Для других более высоких фактов зерна:
- Создание связи "многие ко многим" между таблицей типа измерения и таблицей фактов
- Для обоих типов:
- Сводка элементов управления с помощью логики мер — возвращает значение BLANK, когда столбцы типа измерения нижнего уровня используются для фильтрации или группировки
- Скрыть сводные столбцы таблицы типа фактов. Таким образом, можно использовать только меры для сводки таблицы типа фактов.
Связанный контент
Дополнительные сведения, связанные с этой статьей, проверка следующие ресурсы:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по