Forecasting at scale: many models and distributed training
This article is about training forecasting models on large quantities of historical data. Instructions and examples for training forecasting models in AutoML can be found in our set up AutoML for time series forecasting article.
Time series data can be large due to the number of series in the data, the number of historical observations, or both. Many models and hierarchical time series, or HTS, are scaling solutions for the former scenario, where the data consists of a large number of time series. In these cases, it can be beneficial for model accuracy and scalability to partition the data into groups and train a large number of independent models in parallel on the groups. Conversely, there are scenarios where one or a small number of high-capacity models is better. Distributed DNN training targets this case. We review concepts around these scenarios in the remainder of the article.
Many models
The many models components in AutoML enable you to train and manage millions of models in parallel. For example, suppose you have historical sales data for a large number of stores. You can use many models to launch parallel AutoML training jobs for each store, as in the following diagram:

The many models training component applies AutoML's model sweeping and selection independently to each store in this example. This model independence aids scalability and can benefit model accuracy especially when the stores have diverging sales dynamics. However, a single model approach may yield more accurate forecasts when there are common sales dynamics. See the distributed DNN training section for more details on that case.
You can configure the data partitioning, the AutoML settings for the models, and the degree of parallelism for many models training jobs. For examples, see our guide section on many models components.
Hierarchical time series forecasting
It's common for time series in business applications to have nested attributes that form a hierarchy. Geography and product catalog attributes are often nested, for instance. Consider an example where the hierarchy has two geographic attributes, state and store ID, and two product attributes, category and SKU:

This hierarchy is illustrated in the following diagram:

Importantly, the sales quantities at the leaf (SKU) level add up to the aggregated sales quantities at the state and total sales levels. Hierarchical forecasting methods preserve these aggregation properties when forecasting the quantity sold at any level of the hierarchy. Forecasts with this property are coherent with respect to the hierarchy.
AutoML supports the following features for hierarchical time series (HTS):
- Training at any level of the hierarchy. In some cases, the leaf-level data may be noisy, but aggregates may be more amenable to forecasting.
- Retrieving point forecasts at any level of the hierarchy. If the forecast level is "below" the training level, then forecasts from the training level are disaggregated via average historical proportions or proportions of historical averages. Training level forecasts are summed according to the aggregation structure when the forecast level is "above" the training level.
- Retrieving quantile/probabilistic forecasts for levels at or "below" the training level. Current modeling capabilities support disaggregation of probabilistic forecasts.
HTS components in AutoML are built on top of many models, so HTS shares the scalable properties of many models. For examples, see our guide section on HTS components.
Distributed DNN training (preview)
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Data scenarios featuring large amounts of historical observations and/or large numbers of related time series may benefit from a scalable, single model approach. Accordingly, AutoML supports distributed training and model search on temporal convolutional network (TCN) models, which are a type of deep neural network (DNN) for time series data. For more information on AutoML's TCN model class, see our DNN article.
Distributed DNN training achieves scalability using a data partitioning algorithm that respects time series boundaries. The following diagram illustrates a simple example with two partitions:
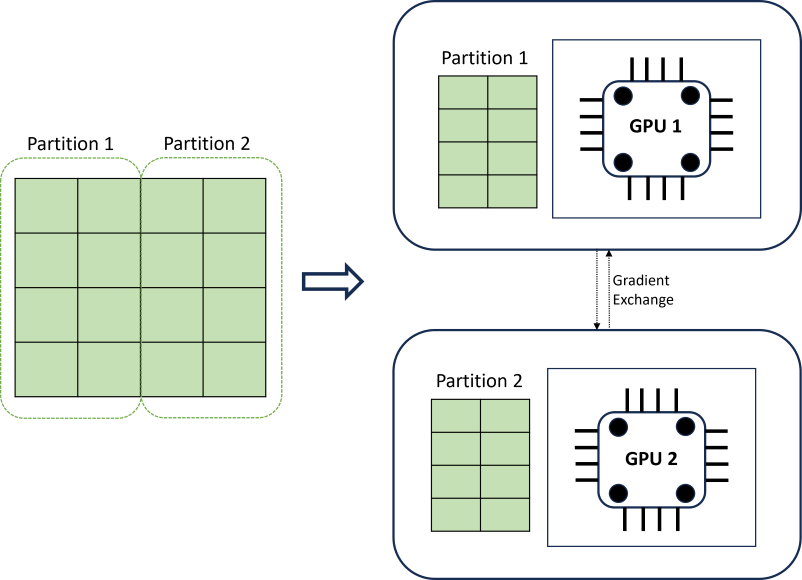
During training, the DNN data loaders on each compute load just what they need to complete an iteration of back-propagation; the whole dataset is never read into memory. The partitions are further distributed across multiple compute cores (usually GPUs) on possibly multiple nodes to accelerate training. Coordination across computes is provided by the Horovod framework.
Next steps
- Learn more about how to set up AutoML to train a time-series forecasting model.
- Learn about how AutoML uses machine learning to build forecasting models.
- Learn about deep learning models for forecasting in AutoML
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for