Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,539 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERK%3C/text%3E%3C/svg%3E)
Hi Experts,
I have created a pipeline in ADF that calls a web api using http connector and stores the json file in datalake container using copy activity. This pipeline runs at certain intervals in a day, may be 6times a day. Each time when the pipeline runs, i need to capture the timestamp of the last successful run and after retrieving that timestamp I will use it to pass the query parameters during the api call inside the copy activity; something like ("modifiedtimestamp >= last successful run timestamp") as part of the api url.
It would be very much appreciated if you could throw some ideas of how to achieve this in ADF.
Thanks&Regards,
Kesavan.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Ramamoorthy, Kesavan and welcome to MIcrosoft Q&A.
There are a couple ways to implement your ask.
One is to alter your pipeline so that if all other steps succeed, at the end of the pipeline, create a file/blob/record with the timestamp. At the beginning of the pipeline use a Lookup Activity to get the timestamp from the same file/blob/record. Let there be only one file/blob/record so that each successful run overwrites it with a more recent timestamp, while failed runs do not update it.
Another option is to use a Web activity to call the Data Factory REST API to get an ordered list of pipeline runs, filter the successful ones, and get the most recent.
Here is the other solution, @Ramamoorthy, Kesavan . It is quite long, but I provided pictures and videos to help.
In this solution I synchronize and record the file location / datetime for use in subsequent runs. To do this I leverage two key ideas/features.
First, I synchronize all references to the current datetime by creating a variable and setting its value to utcnow(). All other occurrences of utcnow() are replaced by references to this variable. There are a number of side-benefits to this. The side-benefits include making code simpler and easier to read, and avoiding discrepancies, and avoiding the midnight-to-next-day edge case.
Second, I leverage the csv dataset's Additional columns feature. By taking an (almost) empty source file, and adding the aforementioned utcnow() variable, I effectively can record the datetime used in creating the file name and folder path. In subsequent runs, I use the lookup activity to retrieve this value.
Overview:
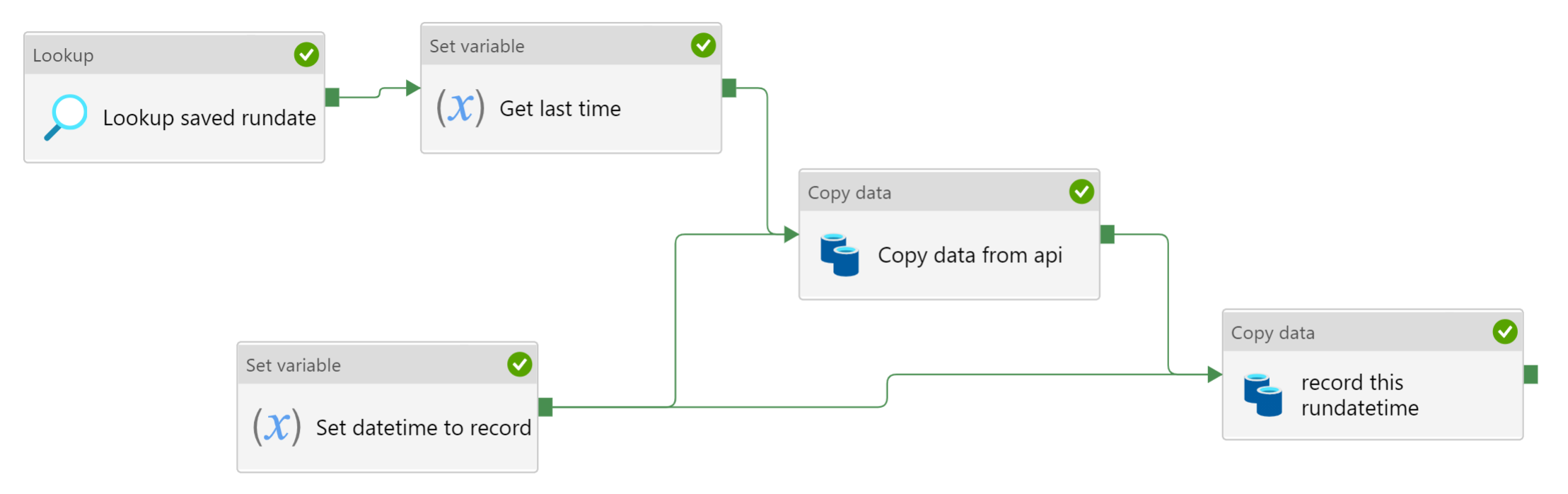
Preparation work:
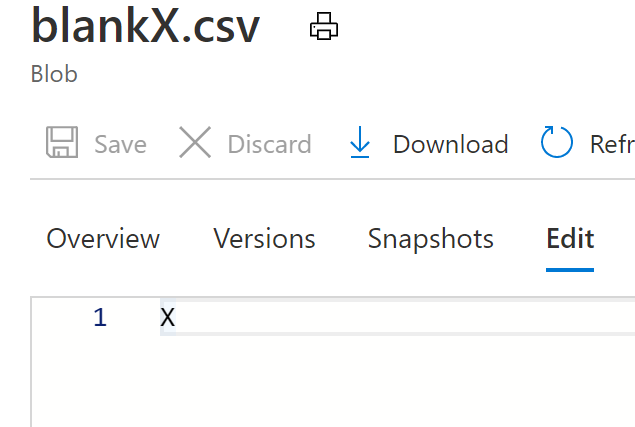
Create and upload an almost empty text file. This will be used as source when recording the datetime. In my example, I typed the letter X and left at that. The reason for leaving something is to ensure Data Factory interprests this as having 1 row rather than 0 rows.
Create a dataset for this blank file. Create a dataset for the file we will use to store the last successful run datetime ("LastRecord"). Both locations are permanent and unchanging. There is nothing special in these two delimited text datasets.
Create two variables, one for fetching the past run datetime ("Last_Time"), the other for storing this run datetime ("This_Time").
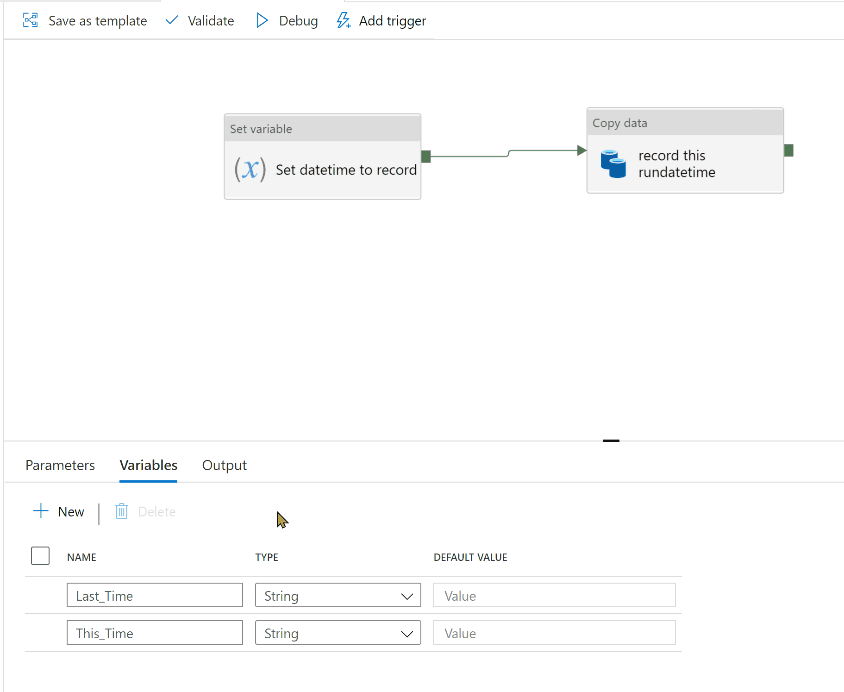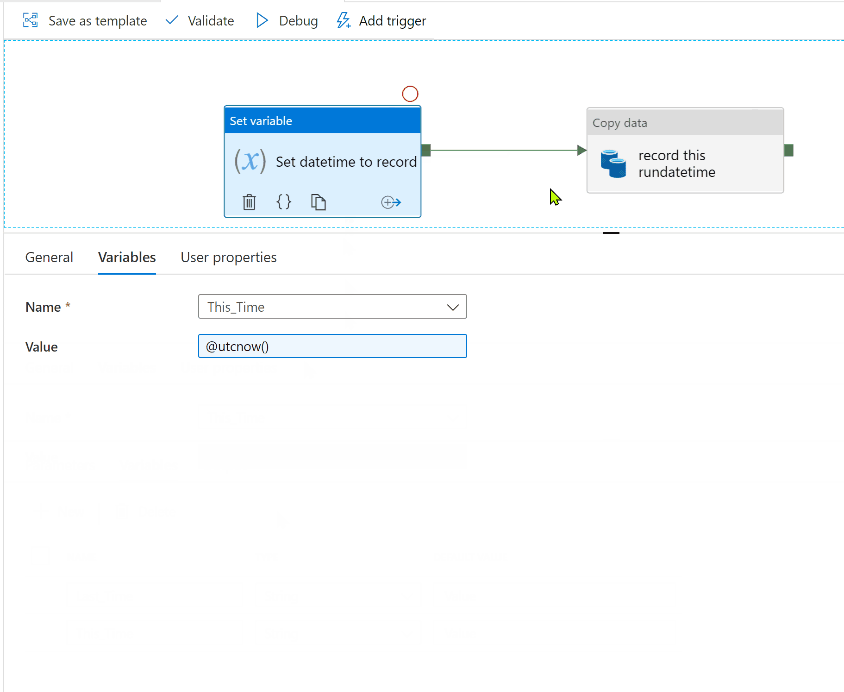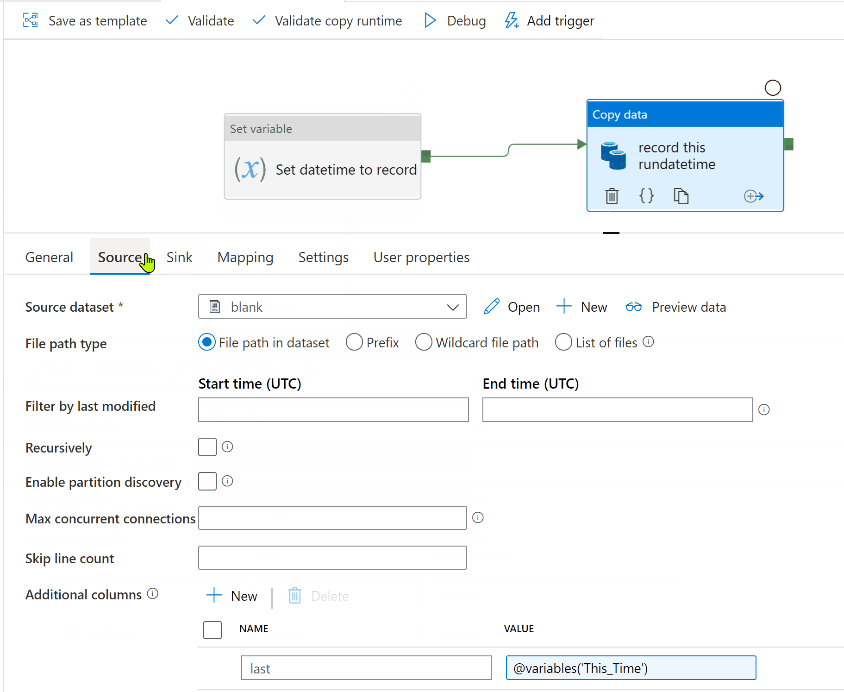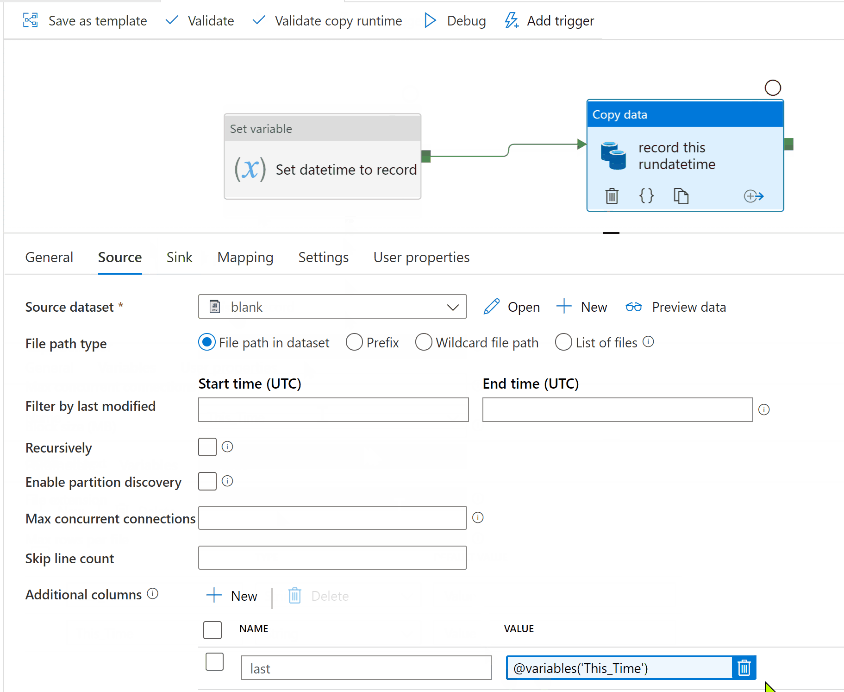
Create a Set Variable activity using the variable for storing this run datetime ("This_Time"). Assign it the expression @utcnow().
Create a Copy Activity, whose source is the blank file, and sink is the other dataset. In the Copy activity Source options, go to the bottom and add an "Additional column". The name can be anything you want, but the value should be @variables('This_Time')
Do a debug run to test. A new file should be written , and its contents should contain the datetime of your test.
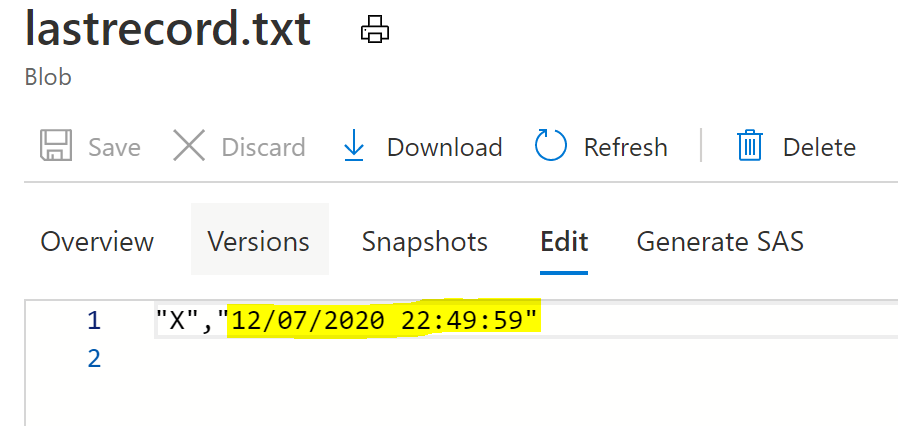
If all this is workign correctly, you are ready to move on to the next step.
Note: before running the pipeline in production for the first time, you may need to manually edit this stored datetiem to line up with any data you wrote previously.
Re-arrange the activities from the above preparation steps into this image repeated from the overview.
First the lookup activity. The lookup activity uses the same dataset as in the prep-work's sink ("LastRecord"). We only need one row, so enable "first row only".
On success of the Lookup Activity, we have a Set Variable activity. To the variable "Last_Time" it fetches the datetime from the Lookup using expression @activity('Lookup saved rundate').output.firstRow.Prop_1
@activity('Lookup saved rundate').output.firstRow.Prop_1
The first copy activity "Copy data from API", depends upon the success of both of the Set Variable activities. I assume you use the "Last_Time" variable in the source when calling the api.
In the sink, I have re-written your dataset to use the "This_Time" variable passed in thru the Copy Activity.
With the dataset owning a parameter "dateparam",
The folderpath @formatdatetime(dataset().dateparam,'yyyy/MM/dd')
The filename @concat(dataset().dateparam,'ormorderstest.json')
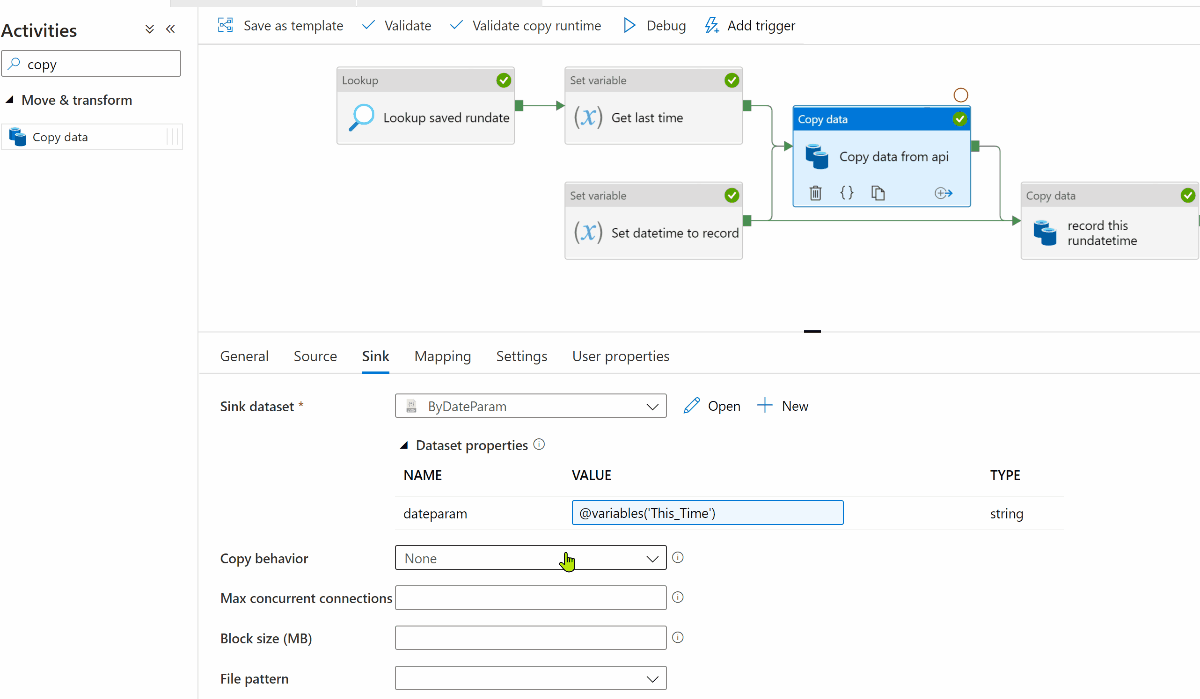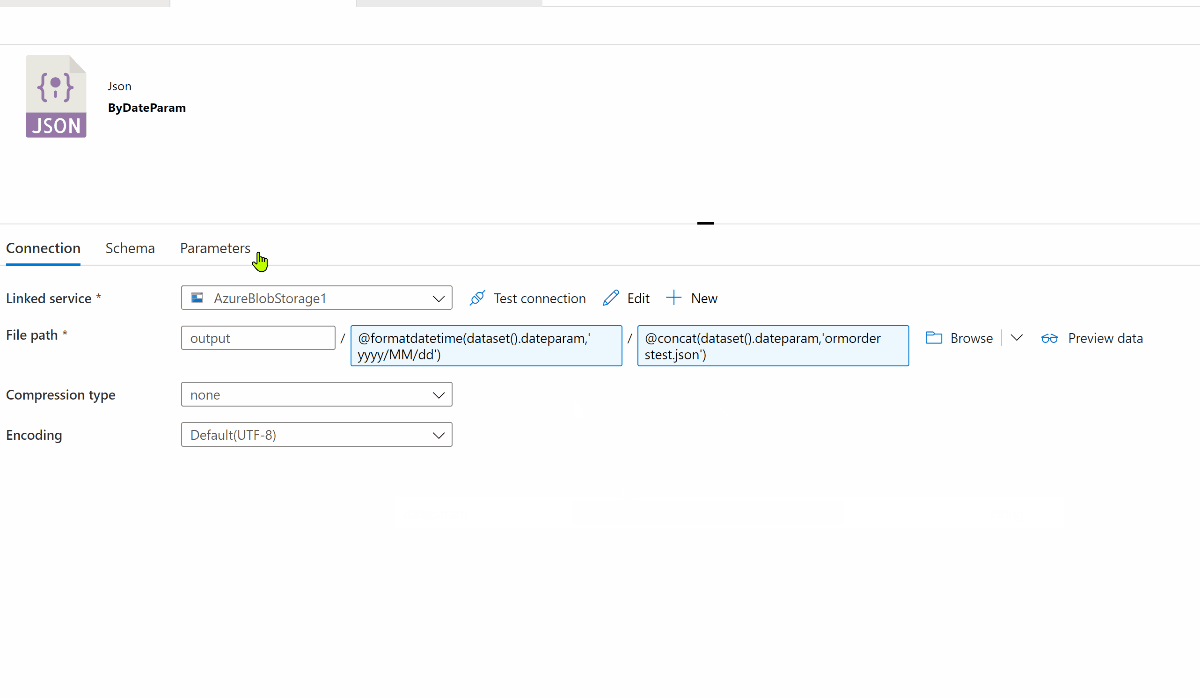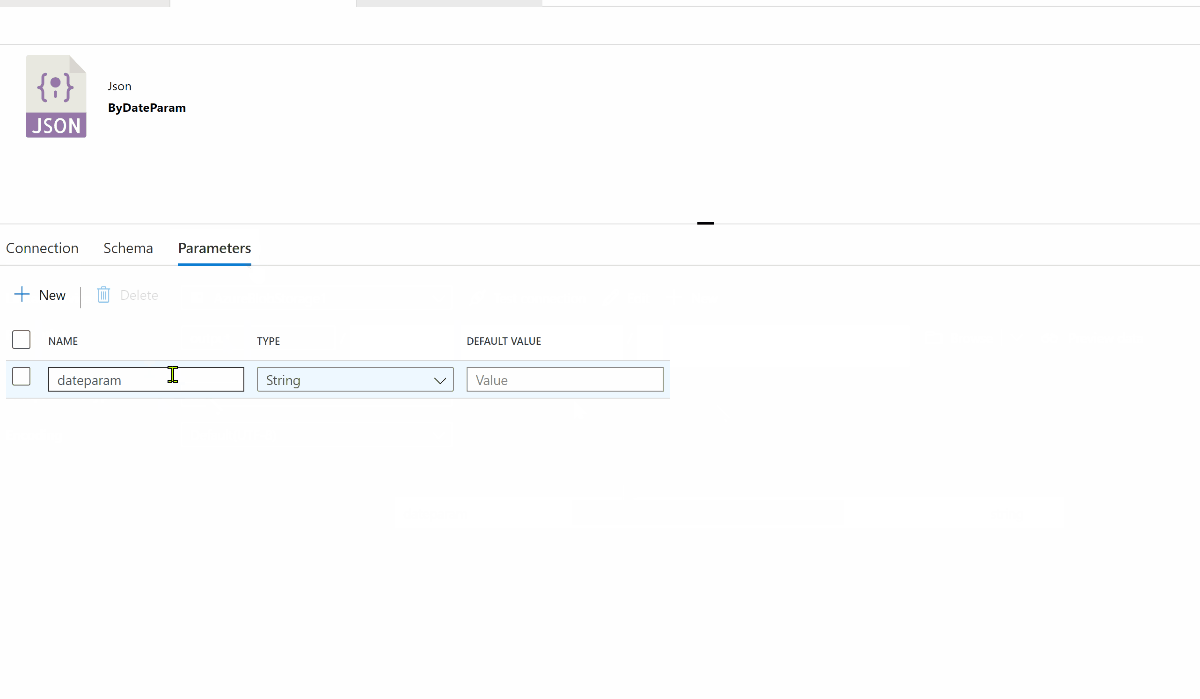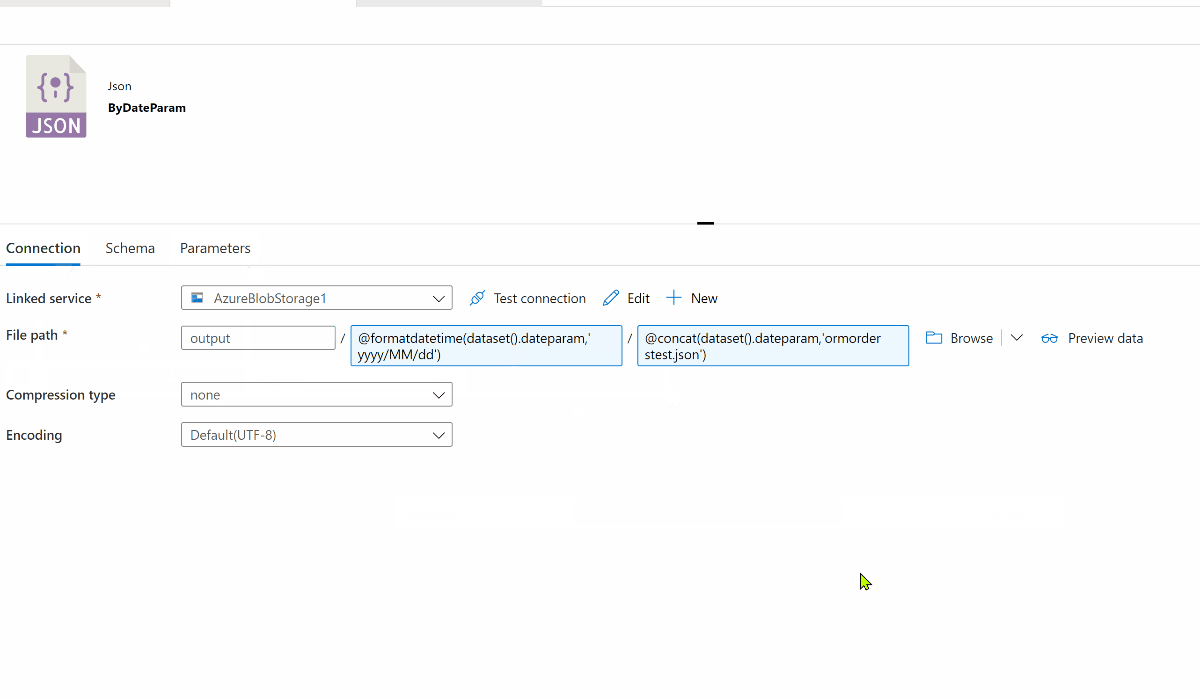
The second copy activity, ("record this rundatetime") which we set up in the preparation section, depends upon the success of the first copy activity.
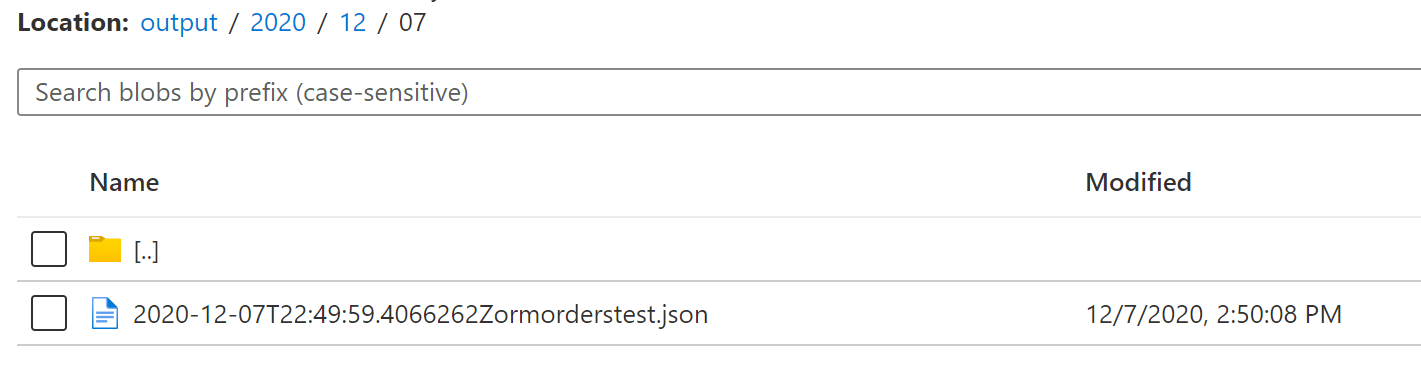
If all goes well, your data should be copied into the corresponding folder, and filename. When that is done successfully, the datetime should be overwritten in that "LastRecord" blob/file.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello ,
We have not heard back from you on this and was just following up .
Incase if you have resolution , request you to share the same here , so that other community members can benefit from that .
Thanks
Himanshu
Hi @HimanshuSinha-msft ,
Yes the solution given by Martin worked out very well. Sorry for the late response.
Thanks a lot @MartinJaffer-MSFT . It was very interesting and good stuff.
Hi @MartinJaffer-MSFT ,
Thanks a lot for your reply. Sorry i think i missed to give few more details.
The files in container are being stored in folder path as shown below.

As the pipeline needs to be triggered 6times a day, the files names are being saved with the timestamp info as defined above and shown below.
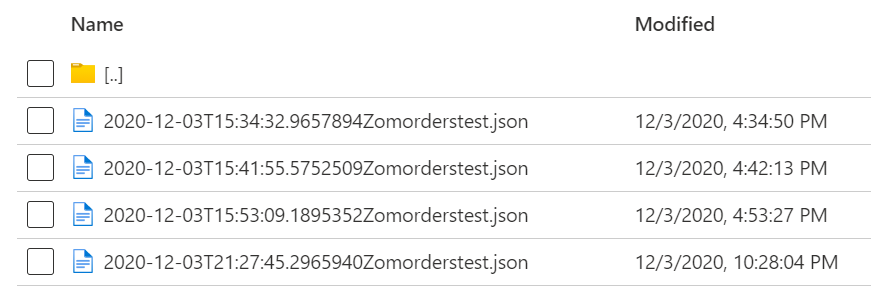
As the folders and files get increased day-by-day in the respective path, Is it a good idea to browse through each of them and find which one is latest? I am fairly new to Azure and still learning it; Is it possible to use Lookup activity in this scenario ?
I was thinking of another approach wherein we try to save/write to the metadata of the blob container inside copy activity or using some other activity in ADF if possible; If the api call is successful and when file is saved to container, is it possible to write the starttime of the pipeline as a metadata to the blob container.
If above is possible, during each pipeline run I would use 'Get Metadata' activity to identify when was the last successful file storage.
Thank you for the additional details @Ramamoorthy, Kesavan . I was busy writing the other answer when you replied.
It sounds like the API route is not as useful. However the other method I mentioned, recording the last datetime write is still applicable, with a couple changes.
You could use Get Metadata and do some looping and sorting, but I think there is a cleaner way.
Before I get into that, I would like to advise you there is an easier and safer way to write the date folder. Going by your picture, currently you are making multiple utcnow() calls to build the folderpath. There is a vulnerability with this approach. What happens when the time is 12:00 midnight, and the first call returns the previous day, and the next call returns the next day? This situation can be avoided by using a single call:
@{formatdatetime(utcnow(),'yyyy/MM/dd')}
There is another improvement I will show you in the implementation of the other solution.
Hi @MartinJaffer-MSFT ,
Thank you so much for the very detailed explanation, really helpful. It sounds promising and interesting. I will definitely give a try and let you know if I am able to reproduce your logic. Thanks again. Great stuff!
Hi @MartinJaffer-MSFT ,
I have some problem while defining the linked services for file system dataset type.
Could you pls share some pics from the linked service definition that is behind the datasets for the delimited text files that you have used here("blank" and "LastRecord")
//Kesavan.
In regards to implementing the API solution I mentioned in earlier comment, @Ramamoorthy, Kesavan , here are the details:
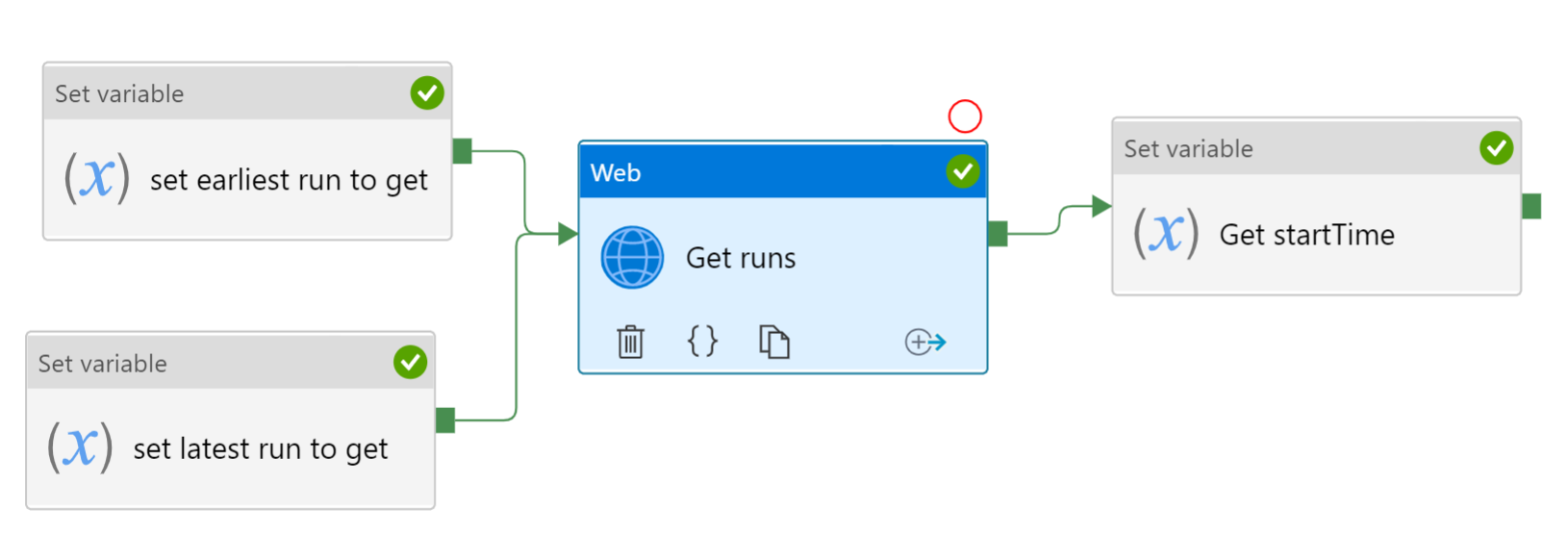
The API call requires a time period to be specified. It wants to get the runs that occurred between datetime X and datetime Y. Since you will be running this day after day, hardcoding the values does not make sense. This is the purpose of the two Set Variable activities before the Web activity.
The "set earliest run to get" assigns to variable named earliest of type string the current datetime minus some number of days. I picked 6. YOu should adjust this to be larger than the amount of time you expect the pipeline to fail.
@adddays(utcnow(),-6)
The "set latest run to get" does similar, but adds day into the future, to ensure the most recent always falls into range. To variable named latest I assign:
@adddays(utcnow(),1)
Now for the Web activity. There are four important parts. URL, Method, Body, and Authentication.
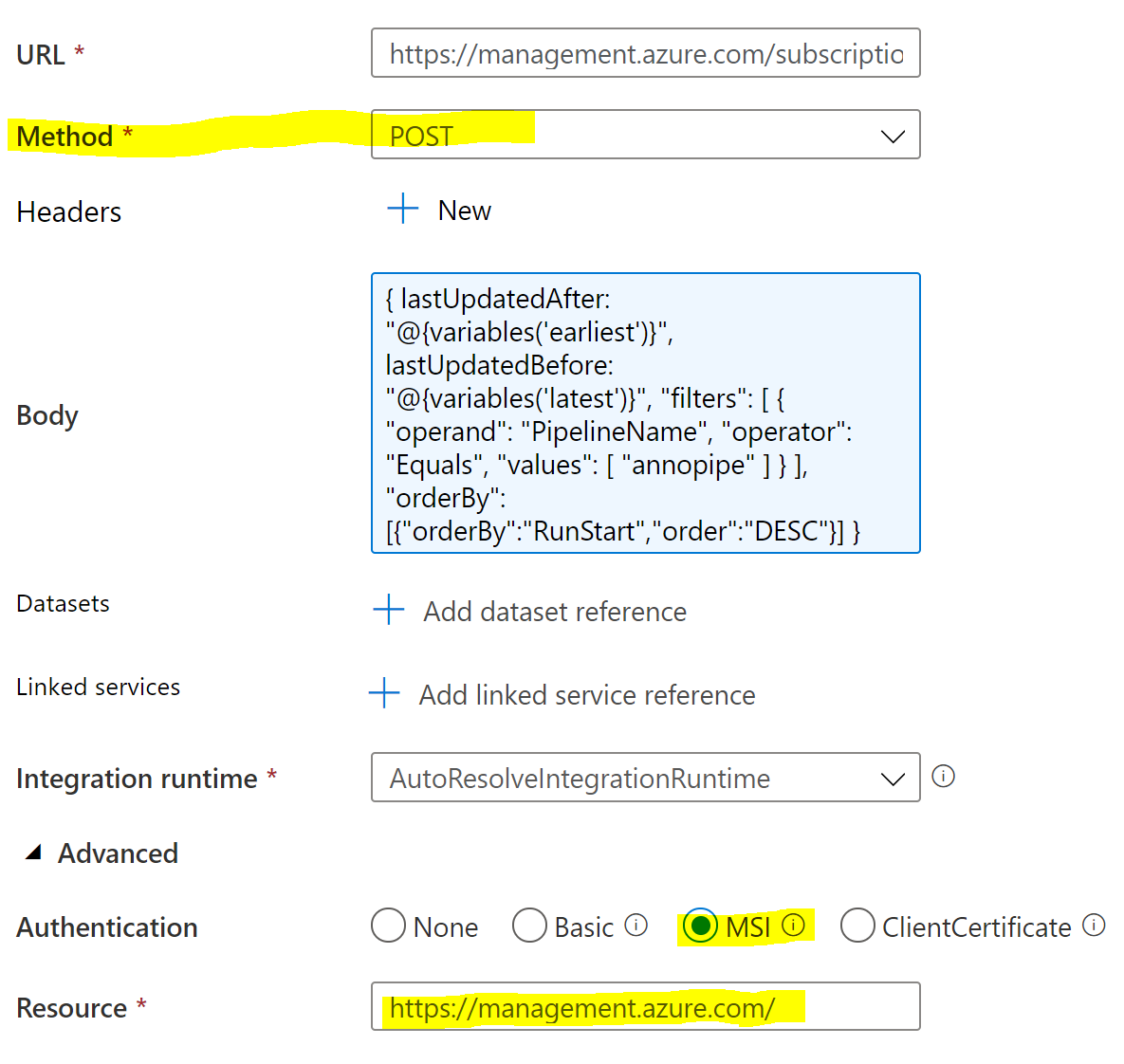
URL: You will need to edit the below with the specific subscription ID, resource group name, and Data Factory name. You can also build it in the "Try it" button in the API docs.
https://management.azure.com/subscriptions/MYSUBSCRIPTIONID/resourceGroups/MYRESOURCEGROUPNAME/providers/Microsoft.DataFactory/factories/MYDATAFACTORYNAME/queryPipelineRuns?api-version=2018-06-01
Method: Choose Post
Body: I have written the body to incorporate the two date variable we set previously. I left the pipeline name hardcoded. You will need to change the pipeline name to suit your needs. There are two filters in this call. One specifies a specific pipeline name. The other specifies only to return successful runs. Since the currently running pipeline is "in progress", it should not be included in the results.
{
lastUpdatedAfter: "@{variables('earliest')}",
lastUpdatedBefore: "@{variables('latest')}",
"filters": [
{
"operand": "PipelineName",
"operator": "Equals",
"values": [
"MYPIPELINENAME"
]
},{"operand":"Status","operator":"equals","values":["Succeeded"]}
],
"orderBy":[{"orderBy":"RunStart","order":"DESC"}]
}
Authentication: Choose MSI and for the resource enter https://management.azure.com/
Let me know if it gives you any trouble. May need to give the Data Factory some permissions.
Lastly, retrieving the run start time. Since in the call we specified the results to be ordered by Run Start time in descending order, the most recent run should be at the top of the result list. The result are returned in an array, so in the last Set Variable activity, I use:
@activity('Get runs').output.value[0].runStart
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPB%3C/text%3E%3C/svg%3E)
Hi @MartinJaffer-MSFT ,
Thank you for providing the solution. I have tried your API solution. Unfortunately, I am receiving some authorization error as shown below

You mentioned in your post to give Data Factory some permissions. What are these permissions?
Thank you in advance.
-- Piyush
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAK%3C/text%3E%3C/svg%3E)
Hi expert,
I'm able to successfully make a Get call to the API endpoint with the following parameters using ADF Rest API and get the data into the destination table
https://xxxxxxxx.azure-api.net/xxxxx/xxxx/bulk-faults?startDate=2021/09/14&startTime=00:00:00&endDate=2021/09/17&endTime=00:00:00
My question is: how can I remove these parameters from the base url (?startDate=2021/09/14&startTime=00:00:00&endDate=2021/09/17&endTime=00:00:00) and/or have the ADF pipeline utilize the current date time every time I run it? Or how can I replace the date time parameters with the current date time.
please assist,
regards
Ak
Hello @Alan kanyinda and welcome to Microsoft Q&A.
Unless I'm mistaken, your query seems not part of this coversation thread's ask. Could you please make a new thread and ask there?