Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,402 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Is there a way to create a Spark dataframe in Scala command, and then access it in Python, without explicitly writing it to disk and re-reading?
In Databricks I can do in Scala dfFoo.createOrReplaceTempView("temp_df_foo") and it then in Python spark.read.table('temp_df_foo') and Databricks will do all the work in the background.
Is something similar possible in Synapse?

@DimitriB-1079 Welcome to the Microsoft Q&A platform.
You can create an Apache Spark pool in Azure Synapse Analytics and run the same queries which you are running in Azure Databricks.
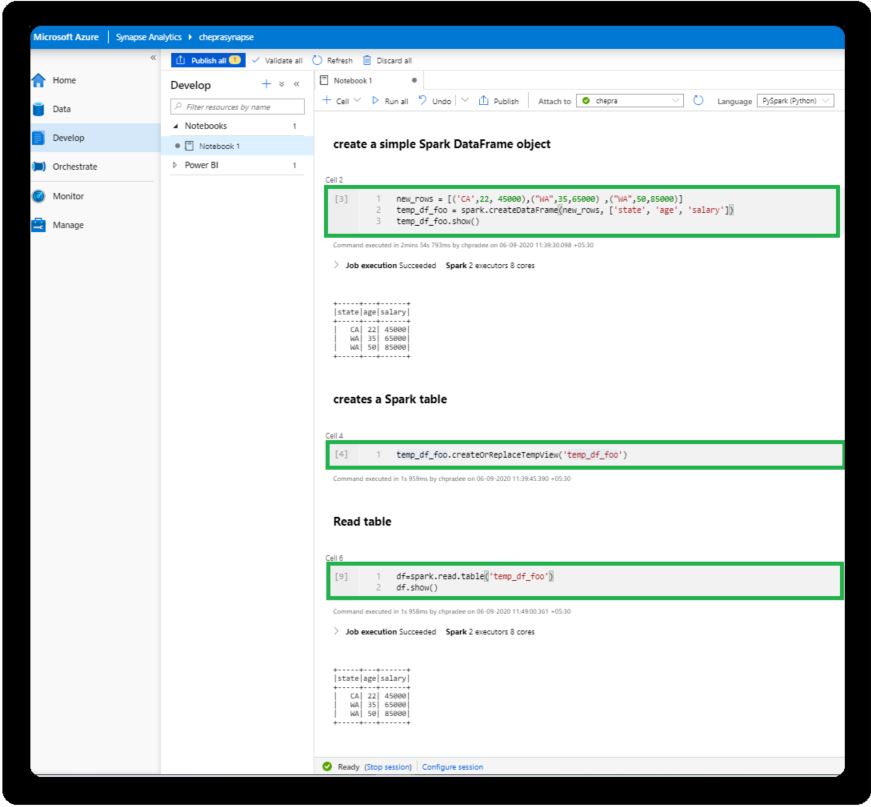
Reference: Quickstart: Create an Apache Spark pool (preview) in Azure Synapse Analytics using web tools.
Hope this helps. Do let us know if you any further queries.
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.

Exact same code should work in Synapse Spark.