Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
2,450 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
I have a pipeline with a series of Data Flows in them. These data flows read data from a Cosmos database and write them to a SQL DW instance. However I am required to have a staging folder location for these. So I create a Gen2 storage location, create a container and give the data factory both Contributor and Storage Blob Data Owner permissions to the storage to enable control/read/write.
I then assign the stage folder in the settings of the Data Factory pipeline and test it which seems to work:

However, I go to run the pipeline via a time trigger and the executions fail. They fail on the write to sink task, claiming there is some missing credential:

What am I doing wrong here, this looks like it should work? Everything is located in Aus East.
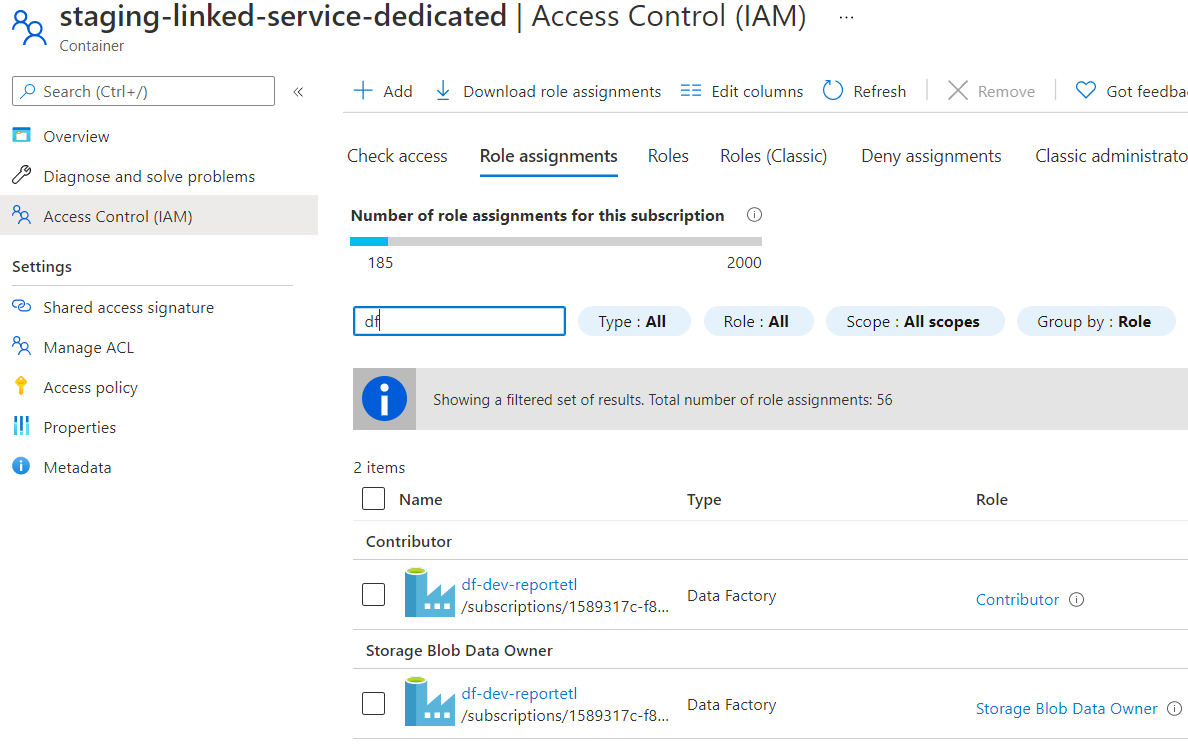
Oh, this is trying to write to a Synapse DW. This is the storage location role assignments:
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Anonymous ,
Thanks for reaching out and using Microsoft Q&A forum.
Could you please confirm what is the integration runtime being used in the staging connector/linked service? In case if it is Self Hosted IR then can you please give a try with Azure IR? The reason I would like to check this is because SHIR is not supported in Mapping data flow. Also please confirm what authentication type is being used for ADLS Gen2 connection (Account Key/Service principal/Managed Identity)?
If that didn't help could you please share the failed pipeline and activity runID for further analysis along with above clarifications?
Let us know how it goes.
Thanks
Sorry, should have been more specific. No, this is NOT a SHIR, this is an Azure IR I created:

Am using managed Identity (which I thought was the preferred?):

Connection tests successfully. Note the connection also tests successfully from the pipeline as you can see in my pic on the original post.
I also tried using account key as the authorization type, which didn't work either.
An example of a failed activity runID is below, there is only one pipeline in it:
Activity Run ID: c97af0b9-f41f-44a5-9545-2b8fd1600202
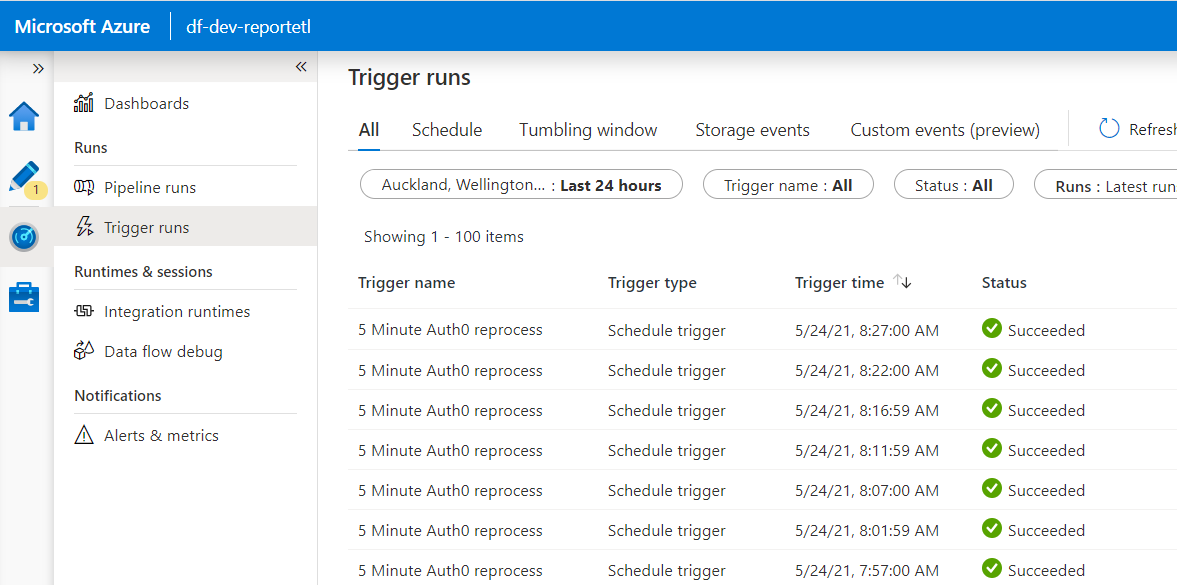
Something else a bit fishy is happening too, in the monitoring. The pipeline is failing, clearly from this screenshot:

However the trigger runs all report success!
Worked through Microsoft support for this. The error I was receiving was completely incorrect, had nothing to do with the issue that caused it. There was no credential issue and no issue with the identified data flow object (it seems to have defaulted to the last object). This went through to the DW/Synapse team who examined what was being run in the background. Looks like it was an unhandled exception which didn't surface the right error.
The issue was I was reading data from a Dimension table in Synapse. The dimension has an "Active" field, indicating whether the row is active or not. This is set as a boolean on the SQL DW side and I needed to filter all those where Active = true. In the "Filter On" statement on the Filter transformation I had:
toBoolean(byName('Active'))==true()
This was the issue, for some reason the underlying engine doesn't know what to do with this and cannot equate the true value coming from DW to Data Factories definition of true. As advised by the support team, I changed this to the following:
toString(byName('Active'))=='true'
which worked.
This was a pretty simple but obscure solution, really a work around. It was pretty much a mystery that it was the filter causing the issue as it was never specified in any of the error messages. I have told the support specialists at Microsoft that this isn't really acceptable, the appropriate error must be surfaced for the appropriate transformation, else we are just guessing at solutions. My Data flow has 20 objects in it, guessing which is causing an error (when I know the error returned may or may not be the actual error) isn't particularly enjoyable. Symptomatic of a "not quite ready for production" immature software product...
Thanks for sharing the root cause and resolution details @Anonymous .
Appreciate much for providing feedback and helping us improve the product better. I do agree that the relevant error info should be displayed. We will communicate this feedback to ADF product team for error improvements and will post here if we have any further update from the team.
Thank you so much!
Hi @Anonymous ,
Thanks for your response. Trigger run status are independent of pipeline run status, that is the reason why you are seeing the trigger runs as success.
For the storage permission issue :
Possible root cause:
To sink the data into Synapse analytics or pool the server does the "pull" of data from the staging. In case of account key auth for staging, the key will be passed to SQL Synapse by the data factory and SQL does the pull.
But with managed Identity, the pull will be using SQL's managed identity as the pull is done by SQL and it cannot use Data Factory's identity.
Resolution:
For the SQL server hosting Synapse/pools does not have a system-assigned managed identity and hence it is required to generate the identity for the server using the steps below
If you have a standalone dedicated SQL pool, register your SQL server with Azure AD by using PowerShell:
If you have an Azure Synapse Analytics workspace, register your workspace's system-managed identity:
Under your storage account, go to Access Control (IAM), and select Add role assignment. Assign the Storage Blob Data Contributor Azure role to the server or workspace hosting your dedicated SQL pool, which you've registered with Azure AD.
Once the permissions are assigned to Synapse Managed Identity, then Rerun the pipeline and see how it goes.
Hope this helps. Do let us know how it goes.
----------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
@KranthiPakala-MSFT Tried this, still doesn't work.
Went through your instructions, which all seemed to work, including assigning access to the Storage to the Synapse Workspace.
Still get the same error: {"StatusCode":"DFExecutorUserError","Message":"Job failed due to reason: at Sink 'WriteToDimension': Unable to stage data before write. Check configuration/credentials of storage","Details":"at Sink 'WriteToDimension': Unable to stage data before write. Check configuration/credentials of storage"}
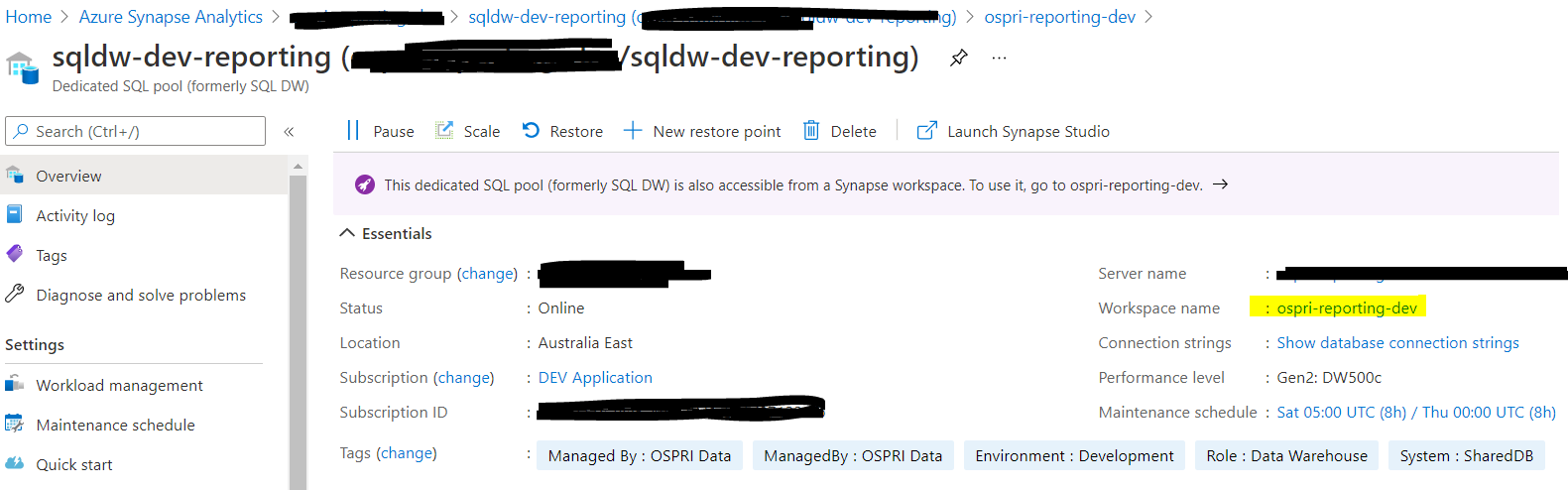
This is the workspace settings
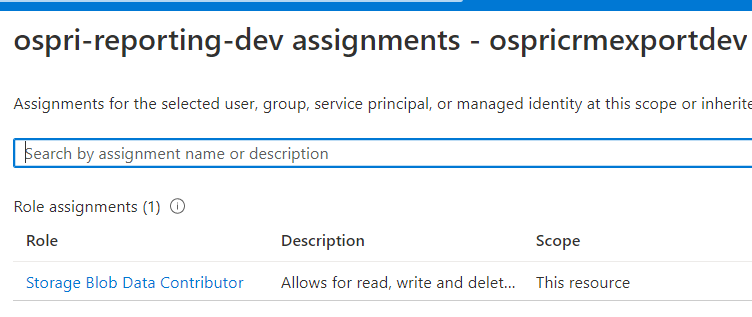
And here is the permissions assigned to the storage:
Here is the Workspace Managed Identity settings:
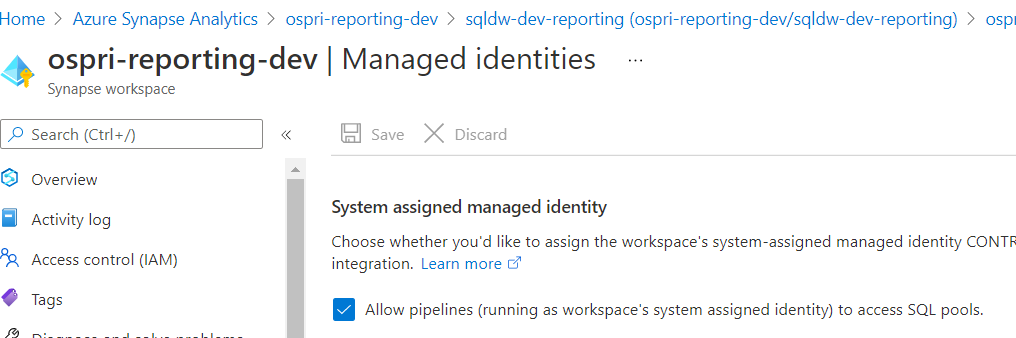
Hi @Anonymous ,
Thanks for the response and sharing the details. Looks like this requires a deeper analysis. For deeper investigation and immediate assistance, If you have a support plan you may file a support ticket, else please let us know, so that we can work with you on enabling one-time-free support ticket to work closely on this matter.
Looking forward to your response.