Azure Machine Learning
An Azure machine learning service for building and deploying models.
2,579 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMS%3C/text%3E%3C/svg%3E)
I have approximately 100k rows of text data (initially PDF documents that have been OCR). Most are rows of less than 5000 characters. Each of the source documents are addressed to some department. These are typically in the form of the below examples where the target department would 'Urology' (there are several departments).
I have read a bit on ML Text Analysis and it seems I should be able to make a pretty good model by reviewing several hundred documents for each department (I have built an App to help me do this) and manually Classifying those documents. Some documents may mention urology but are actually addressed to another department. Typically the addressed department text is at the top third (first 3-7 lines) of the text body.
I cannot use any online tools, i.e. I can't upload any of the Document text to servers to process I need a client side library. I have read and completed several tutorials using the ML.net but these are pretty basic (sentiment, entity detection without any initial training), and read an excellent blog at MonkeyLearn: which seems to acknowledge that can do what I imagine I should be able to do.
So can anybody point me in the right direction, can I use some offline Microsoft client library to complete my task? Is there some other Open Source client library i should look at. Will I have to learn Go, or python to complete the task (currently a C# dev).
Note: I could get fairly good matches simply using SQL Text search and a bit of C# with plenty of hard coded rules, but I thought I'd try ML -- however its a nest of complications at the moment and i am going around in circles.
Many Thanks
Mike.

@Mike Shapleski I see two possible solutions for your scenario.
The first solution can help you achieve this and ensure everything is offline or using docker containers without uploading any of your data to any storage externally. For billing purposes the containers need to connect to a metering endpoint on Azure to bill your usage of both these services(Computer Vision API & Azure text analytics containers). Also, you can use C# client library to call the local endpoint of these containers. The setup could take time to configure docker containers and passing the PDF documents to the computer vision read API to extract text. The extracted text can then be directly used or stored, to call the text analytics for health API.
The second solution can be used to index all the documents by using the search service by having your data in the cloud or behind a firewall to index the documents and make them searchable. There are some skills that can be enabled on the search service to extract entities and other PII information but this may not extract the same data as text analytics for health. This solution can be faster to setup because you can directly query your data after uploading the documents.
If an answer is helpful, please click on  or upvote
or upvote  which might help other community members reading this thread.
which might help other community members reading this thread.
Thanks for you reply Romungi, I had looked at the Azure Text Analytics for Health API but its too pricey at 100x the cost of the normal text API. The text I have could easily be from another sector (other than health),for example the below demonstrates the same problem using different keywords from a different industry.
Browns Bay Audio
101 Somewhere Road, Takapuna, 09-45286321, BBA@BestAudio.com
Refurbishment Department
RE: Unit23456
Please find the enclosed amplifier, which needs to have it's output jack looked at, the stream of audio from this unit is substandard and is potentially causing damage to the unit. Last year this unit had its front panel replaced by the Chassis department.... Much more text is possible
So the key words in this example would be Refurbishment Department and Chassis Department the former being the correct and the later being incorrect. Once I have established the correct destination I can route the document accordingly.
I had thought that somehow I can manually group/classify a of sample of the 100k rows of text I have (i.e. make a model), I am happy to do manually by looking at each row of text and assigning it some keywords. But what I am not sure about is exactly how to record those keywords (position in text for example?, include negative keywords? etc.) and how to structure this manual keyword/classification data so that I can feed it into a ML algorithm (and what type of ML do I use?).
The containerization idea is fantastic.
Thanks Mike.
@Mike Shapleski The available GA API's of text analytics help pickup entities but it cannot classify and route the document to a specific team or tag them. So, if text analytics for health pricing is higher then using just the text analytics API also performs a similar function.
However, specific to this scenario there has been an announcement to introduce a preview service called custom text classification this should help you define a schema, tag data, train a model and infer it and deploy. The service is not available as a container because it is still in preview but you can try to use it for your scenario.
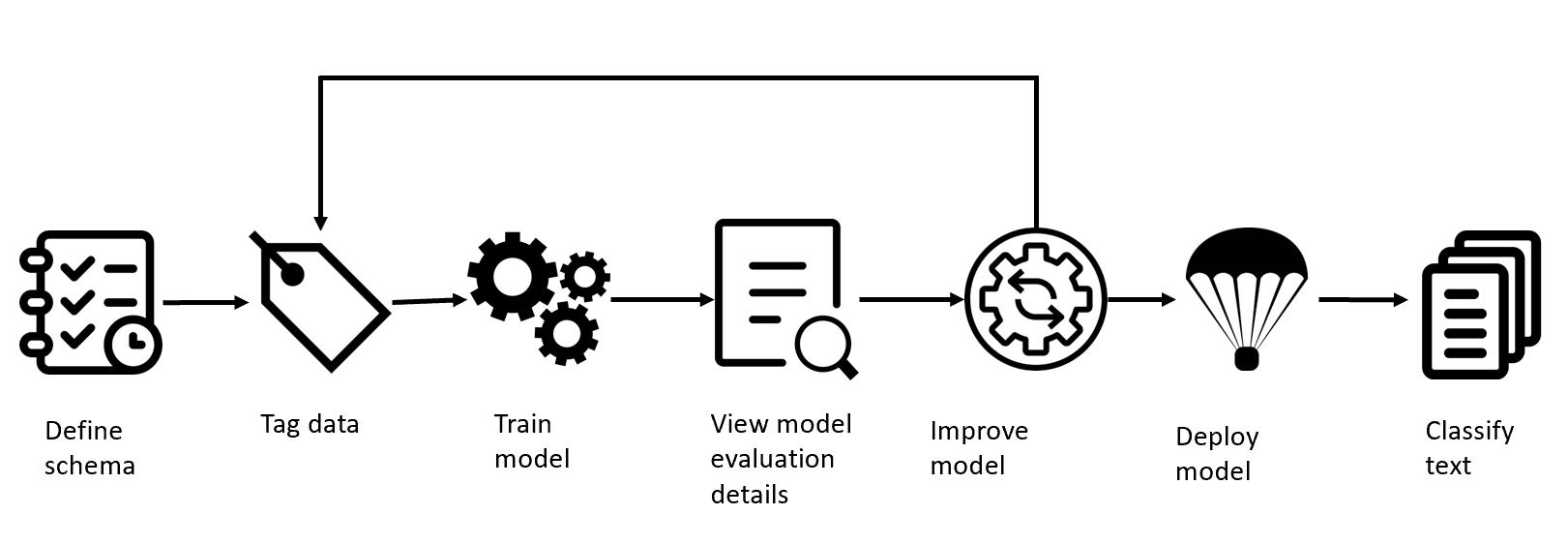
Added image from Azure documentation page for summarization.
Fantastic, that is what I was looking for I'll test the preview and await the general release.
Thanks Mike.