Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,654 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EP%3C/text%3E%3C/svg%3E)
I'm putting together a Proof Of Concept for using Azure Data Factory as our primary ETL/MDM tool, and I'm struggling a lot with almost everything I'm trying to do. I'm wondering if this is the same for everyone, or if I've just managed to get four 'edge' cases from the first five use cases I have.
Mainly, this comes down to ingesting data. The first task pulls JSON data from a web API, so it was a straight shot. I thought it was plain sailing.
The remaining use cases are loading data with custom formats. These arrive as CSV files, but internally they are nonstandard. For example:
100,DMS,AUGUST
200,419215.52,1,1,15,L
300,20200510,20,20,20,20,20,20,15,20,15,20,15,15,20,15,20,15,15,20,20,20,30,30,25,30,25,30,25,25,30,25,30,25,25,30,25,25,30,25,25,25,25,30,25,25,25,25,30,25,25,25,25,30,25,25,25,25,25,30,25,25,25,25,30,25,25,25,25,25,30,25,30,15,15,15,15,15,10,15,15,20,15,15,0,30,15,20,15,20,15,15,20,15,20,20,20,20,A
200,119934.22,1,1,15,L
300,20200510,0,0,0,0,0,0,15,0,15,0,15,15,20,15,20,15,15,20,20,20,30,30,25,30,25,30,25,25,30,25,30,25,25,30,25,25,30,25,25,25,25,30,25,25,25,25,30,25,25,25,25,30,25,25,25,25,25,30,25,25,5,5,30,5,5,5,5,5,0,5,30,15,15,15,15,15,0,15,15,20,15,15,0,30,15,20,15,20,15,15,0,15,0,20,0,0,A
900
In this case, I only need the rows starting with 200 and 300, but I need to associate the data from each 200 row with one or more 300 rows under it. This is tough, but I've come up with an Azure function to convert the data into JSON that I can import, but I'll come back to this.
In another use case, I have the following format in a CSV file
C,NEMP.WORLD,PRICES,AEMO,PUBLIC,2021/02/09,04:05:56,0000000336337615,,0000000336337609
I,DREGION,,2,SETTLEMENTDATE,RUNNO,REGIONID,INTERVENTION,RRP,EEP,ROP,APCFLAG,MARKETSUSPENDEDFLAG,TOTALDEMAND,DEMANDFORECAST,DISPATCHABLEGENERATION,DISPATCHABLELOAD,NETINTERCHANGE,EXCESSGENERATION,LOWER5MINDISPATCH,LOWER5MINIMPORT,LOWER5MINLOCALDISPATCH,LOWER5MINLOCALPRICE,LOWER5MINLOCALREQ,LOWER5MINPRICE,LOWER5MINREQ,LOWER5MINSUPPLYPRICE,LOWER60SECDISPATCH,LOWER60SECIMPORT,LOWER60SECLOCALDISPATCH,LOWER60SECLOCALPRICE,LOWER60SECLOCALREQ,LOWER60SECPRICE,LOWER60SECREQ,LOWER60SECSUPPLYPRICE,LOWER6SECDISPATCH,LOWER6SECIMPORT,LOWER6SECLOCALDISPATCH,LOWER6SECLOCALPRICE,LOWER6SECLOCALREQ,LOWER6SECPRICE,LOWER6SECREQ,LOWER6SECSUPPLYPRICE,RAISE5MINDISPATCH,RAISE5MINIMPORT,RAISE5MINLOCALDISPATCH,RAISE5MINLOCALPRICE,RAISE5MINLOCALREQ,RAISE5MINPRICE,RAISE5MINREQ,RAISE5MINSUPPLYPRICE,RAISE60SECDISPATCH,RAISE60SECIMPORT,RAISE60SECLOCALDISPATCH,RAISE60SECLOCALPRICE,RAISE60SECLOCALREQ,RAISE60SECPRICE,RAISE60SECREQ,RAISE60SECSUPPLYPRICE,RAISE6SECDISPATCH,RAISE6SECIMPORT,RAISE6SECLOCALDISPATCH,RAISE6SECLOCALPRICE,RAISE6SECLOCALREQ,RAISE6SECPRICE,RAISE6SECREQ,RAISE6SECSUPPLYPRICE,AGGREGATEDISPATCHERROR,AVAILABLEGENERATION,AVAILABLELOAD,INITIALSUPPLY,CLEAREDSUPPLY,LOWERREGIMPORT,LOWERREGLOCALDISPATCH,LOWERREGLOCALREQ,LOWERREGREQ,RAISEREGIMPORT,RAISEREGLOCALDISPATCH,RAISEREGLOCALREQ,RAISEREGREQ,RAISE5MINLOCALVIOLATION,RAISEREGLOCALVIOLATION,RAISE60SECLOCALVIOLATION,RAISE6SECLOCALVIOLATION,LOWER5MINLOCALVIOLATION,LOWERREGLOCALVIOLATION,LOWER60SECLOCALVIOLATION,LOWER6SECLOCALVIOLATION,RAISE5MINVIOLATION,RAISEREGVIOLATION,RAISE60SECVIOLATION,RAISE6SECVIOLATION,LOWER5MINVIOLATION,LOWERREGVIOLATION,LOWER60SECVIOLATION,LOWER6SECVIOLATION,RAISE6SECRRP,RAISE6SECROP,RAISE6SECAPCFLAG,RAISE60SECRRP,RAISE60SECROP,RAISE60SECAPCFLAG,RAISE5MINRRP,RAISE5MINROP,RAISE5MINAPCFLAG,RAISEREGRRP,RAISEREGROP,RAISEREGAPCFLAG,LOWER6SECRRP,LOWER6SECROP,LOWER6SECAPCFLAG,LOWER60SECRRP,LOWER60SECROP,LOWER60SECAPCFLAG,LOWER5MINRRP,LOWER5MINROP,LOWER5MINAPCFLAG,LOWERREGRRP,LOWERREGROP,LOWERREGAPCFLAG
D,DREGION,,2,"2021/02/08 04:05:00",1,NSW1,0,34.99,0,34.99,0,0,6235.84,52.18066,5803.66,0,-432.18,0,,,75,,,,,,,,118.92,,,,,,,,75,,,,,,,,102.1,,,,,,,,182,,,,,,,,228,,,,,,15.14925,12147.08561,0,6202.88281,6276.99,,67,,,,88,,,,,,,,,,,,,,,,,,,0.73,0.73,0,0.99,0.99,0,0.49,0.49,0,7,7,0,0.99,0.99,0,3.66,3.66,0,0.44,0.44,0,9.25,9.25,0
D,DREGION,,2,"2021/02/08 04:05:00",1,QLD1,0,37.93549,0,37.93549,0,0,6054.71,11.02148,5767.71,0,-287.01,0,,,5,,,,,,,,5,,,,,,,,5,,,,,,,,24,,,,,,,,64.72,,,,,,,,60.72,,,,,,9.08572,10501.758,0,6039.77344,6062.67,,64.1,,,,66,,,,,,,,,,,,,,,,,,,0.73,0.73,0,0.99,0.99,0,0.49,0.49,0,7,7,0,0.99,0.99,0,3.66,3.66,0,0.44,0.44,0,9.25,9.25,0
D,DREGION,,2,"2021/02/08 04:05:00",1,SA1,0,9.59703,0,9.59703,0,0,1016.24,0.37307,1046.83,0,30.6,0,,,83,,,,,,,,66,,,,,,,,134,,,,,,,,118,,,,,,,,73,,,,,,,,137,,,,,,4.57945,2503.8339,106,1020.93158,1024.19,,59.9,,,,66,,,,,,,,,,,,,,,,,,,0.73,0.73,0,0.99,0.99,0,0.49,0.49,0,7,7,0,0.99,0.99,0,3.66,3.66,0,0.44,0.44,0,9.25,9.25,0
D,DREGION,,2,"2021/02/08 04:05:00",1,TAS1,0,9.31373,0,9.31373,0,0,861.53,3.39758,632.98,0,-228.55,0,,,34.57,,,,,,,,71.67,,,,,,,,0,,,,,,,,58.81,,,,,,,,114.99,,,,,,,,92,,,,,,-0.46144,1981.2,0,858.59454,861.53,,19,,,,0,,,,,,,,,,,,,,,,,,,4.98,4.98,0,4.49,4.49,0,0.9,0.9,0,7.41,7.41,0,0.99,0.99,0,3.66,3.66,0,0.44,0.44,0,9.25,9.25,0
C,"END OF REPORT",3366
This one IS actually standard CSV apart from the first and last rows, but because of those rows, I just cannot get ADF to import the data for anything deeper per line than the number of columns on the first row. So given my work with the first case, this is simple really. I don't need the data in the first or last lines, so I can pretty quickly put together a function to trim the problem lines, which should let me open the CSV.
But how does this work in practice?
My first thought was to use storage triggers. I run a pipeline to drop a file in the storage account created for functions, it detects the file, processes it, then drops it into an output file. ADF then detects the output file, opens it, and ingests it.
OK. But ...
It might make sense later on to run these funtions in something other than a consumption app plan, but for now I like the low cost barrier for proof of concept. When I have a consumption plan however, triggers have been extremely hit and miss.
When you set up an Azure Function, you have to set up a storage account, which by default is v1 storage. With a consumption plan, you cant use VLANs, so it's essentially an isolated storage pool that lives outside of our primary data lake. Being v1 storage, it is also non-hierarchical, as in no folders beyond the container level. Multiple functions with separate 'in' and 'out' containers at the root level to ensure the right function picks up the right file and drops it somewhere expected to trigger the right pipeline ... it's going to get ugly fast.
So I created the functions storage as v2. But files dropped in this storage did not trigger the function. Well, they do, but only if you go to the function page. If you wait a few hours, files will just sit unprocessed until you visit the function page in the portal to 'wake' it. And this is NOT the trigger activation issue that I was first diagnosed with. Restarting the function does NOT make it work. It ALWAYS requires you to visit the portal to make the triggers fire.
After a lot of back and forth with support, they tell me that function storage triggers don't work if your storage replication is set to anything other than Locally-Redundant Storage (LRS), but I have yet to see it work. I'm still of the opinion that function storage triggers don't work with v2 storage. I'm still testing this.
In the meantime, I think, I'll just use v1 storage (where the triggers work) and keep it clean by having a single container per function as an input, and write the outputs to my v2 data lake. Nope. Azure functions can't write to storage that is firewalled. Because it can run a script, Microsoft deems this insecure, and won't let it write to secured storage.
So, OK. if I just go with the flow here and write the output files to v1 storage, it should work, right? Well No. I couldn't get data factory to reliably trigger from v1 storage. I didn't dig too deep on this to be fair. But I set it up, just like I did for v2 storage, and it just wouldn't trigger the appropriate pipeline. It was at this point I got bogged down testing various settings and storage combinations to diagnose the storage trigger issues with support.
I'd made progress across three ingest processes by now, but I was already seeing the issue with storage triggers. They're complex.
Each trigger is a disconnect point, making it hard to see what happens at the end of each stage. If a trigger fails, nothing errors or complains. It just silently stops.
So I've essentially stalled on storage triggers, so I thought maybe HTTP triggers for the Functions. I can call them directly from a pipeline, so I can copy the file to the 'in' container, trigger the function in the pipeline, and process the output file where the function returns OK. I'll probably need another layer of triggers for MDM compilation, but that's not such a big deal.
This leaves me with a few questions.
I'm inclined to copy both the original and output files back into the data lake for storage. If I ever find an issue with the way I've ingested the data, I can then go back and re-process it. I can use lifecycle management to drop old files back to archive level storage. But this makes my head hurt again. It seems like a lot of transfer work, for which I'll no doubt pay Microsoft more for.
I don't mind this, conceptually. Files don't accumulate in the function storage account. There are no external permissions assigned, but my org will feel more comfortable with the data being in the secured account (VNET / Firewall). For me, I like that all the files are in the same place. But geez, it seems like a lot of file movement for what should be a simple task.
My only alternative to this mess of data movement, and it is somewhat appealing, would be to drop the file into the secure v2 storage, use the HTTP function trigger in a pipeline to read the file (because Azure functions can READ from secured storage, but not write), and just return the data in JSON format to ingest directly.
Does anyone know if that latter is an option? I can't see a way to do it. I can get the function to return JSON, and I can use that to loop through elements. I do this to download JSON files from a website, where the function scrapes the URLs from a target site, loops through them, and downloads any that are new. But surely I wouldn't use a foreach loop to write individual rows. How would I even do that with a sink such as parquet? Then I am thinking there would be size limits, etc, that I would no doubt run into at some point. Any advice on this approach?
Apart from this, does the above file-based approach seem sensible? Does the file movement seem excessive? Am I just approaching it the wrong way?
And is this what I can expect from Data Factory? Will every task I need to achieve fall just outside the bounds of what it is capable of doing?
I realise this has turned into a massive rant, but if anyone can give me any advice on this, it would be greatly appreciated.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)

Hi Peter,
For the first file, you might want to consider using an Azure Function to add an index number column to the rows starting with 200 and 300 that belong together.
Now you can use the index number column to join the rows. Use a dataflow for this.
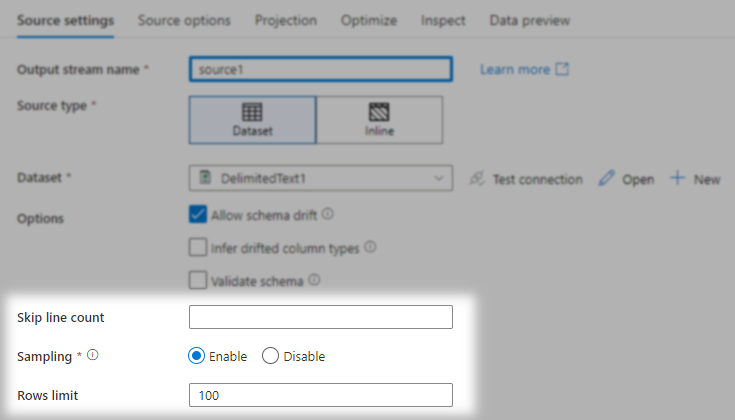
For the second file you might also want to look at using a dataflow. There you can use the "Skip line count" option to skip the first line and maybe use the "Sampling" option to only use 1 or 2 rows for sampling.
Thanks for taking the time to respond, I really do appreciate it. The delayed response is due to a much-needed break, as the apparent state of mind I was in when I wrote this post may suggest.
I believe I tried skipping lines to try to overcome this issue, I feel like I tried everything, but I will revisit it with fresh eyes. I'll let you know how that pans out.
Regarding the Azure Function, I'm tying myself up a little with the process. I don't feel entirely comfortable editing the source file, and instead feel like I should be preserving the raw version and dropping the edited output for processing. But that is where I start to fall over with where to save it, and how to minimise pushing the files between datastores.
With the first file, for example, rather than take the approach of adjusting the file so that it can be read properly, I instead just convert it to JSON as I go through the lines. It gives me a separate output and is in a format that avoids the pitfalls of CSV ingestion. But either way, what do people usually do? Drop the file somewhere and use the Azure Function action in a pipeline to initiate the function to pick up the source file and drop the output? Then pick up the output file in the next step of the pipeline?
I guess it's just starting to feel that I'm inventing something that isn't what others in this situation would do, but I can't figure out what they would do.
Any further feedback on this would be great.
Thanks again.