Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,348 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Error: {"message":"Job failed due to reason: at Sink 'MetaSink': org.apache.spark.sql.AnalysisException: The column number of the existing table default.phaseone(struct<>) doesn't match the data schema(struct<Id:int,Name:string>);. Details:org.apache.spark.sql.AnalysisException: The column number of the existing table default.phaseone(struct<>) doesn't match the data schema(struct<Id:int,Name:string>);\n\tat org.apache.spark.sql.execution.datasources.PreprocessTableCreation$$anonfun$apply$2.applyOrElse(rules.scala:131)\n\tat org.apache.spark.sql.execution.datasources.PreprocessTableCreation$$anonfun$apply$2.applyOrElse(rules.scala:76)\n\tat org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1$$anonfun$2.apply(AnalysisHelper.scala:108)\n\tat org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1$$anonfun$2.apply(AnalysisHelper.scala:108)\n\tat org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:69)\n\tat org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1.apply(AnalysisHelper.scala:107)\n\tat org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsDown$1.apply(AnalysisHelper.scala:106)\n\tat org.ap","failureType":"UserError","target":"DataFlow_SourceToLanding","errorCode":"DFExecutorUserError"}
I am mentioning my steps which I have performed :
Step1: got metadata using lookup activity
Step2: Passed the values in for each loop for ne by one table execution
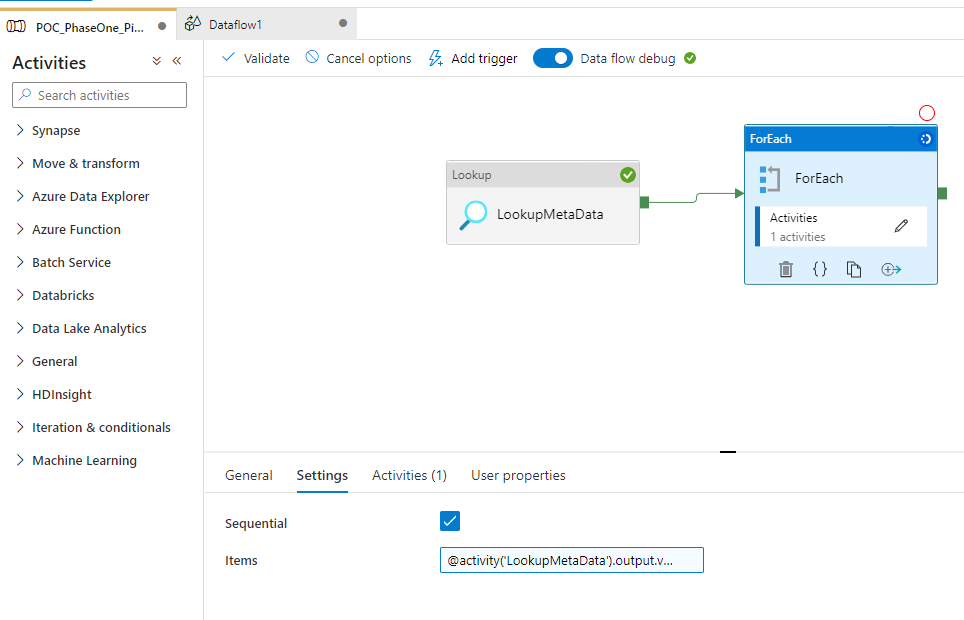
Step3: Created parameters for metadata in dataflow
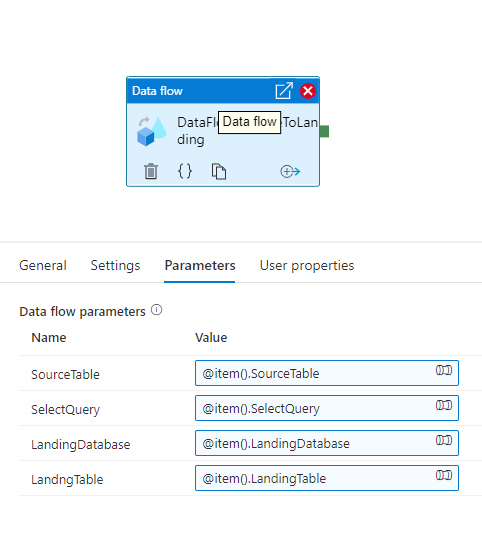
Step4: Passed the table name and columns in dataflow source activity via Inline Query
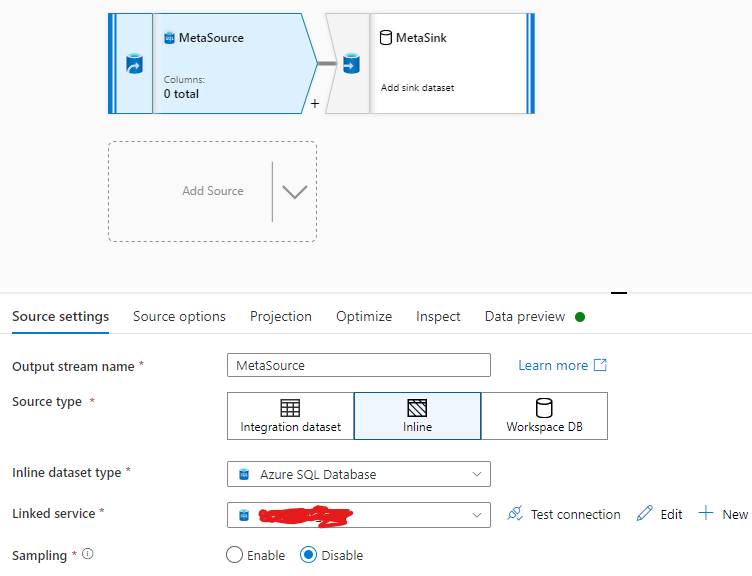
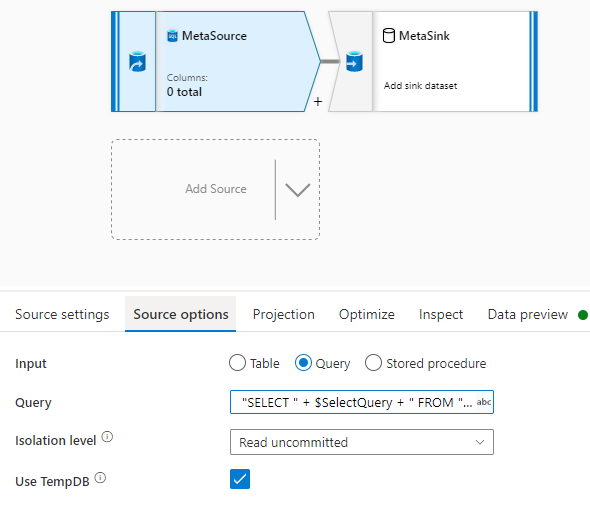
Step5: Then use the Delta Table from WorkspaceDb(Lake Database) In Sink Activity
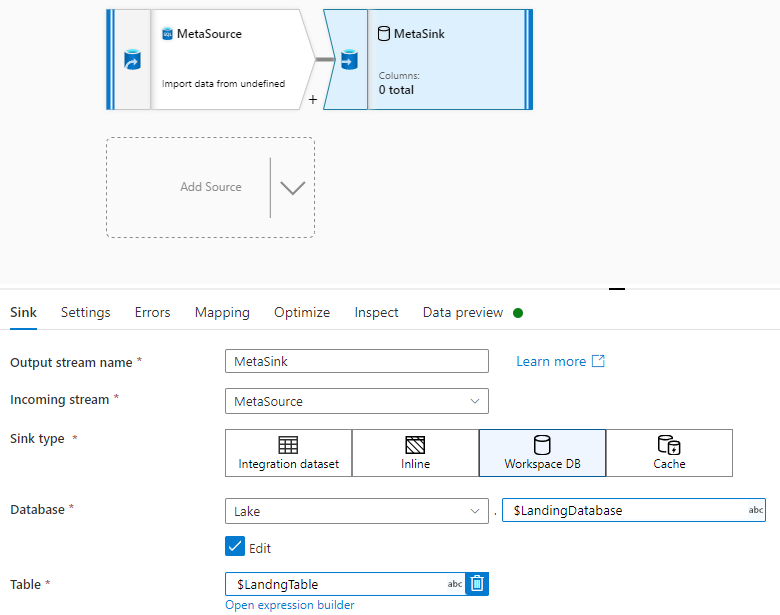
There is Two Same Columns in Azure SQL Source and Delta Lake Table
Source Table : (Id int , Name varchar(20) )
Destination Table : (Id INT , Name STRING )

Hi @Vedant Desai ,
Welcome to Microsoft Q&A platform and thanks for posting your question .
As I understand the issue it seems you are trying to load data from Az SQL table to Delta table using mapping dataflow. However, it seems to be throwing error saying column number doesn't match between source and sink. Please let me know if my understanding is incorrect.
Since , the whole pipeline architecture is dynamic to copy multiple tables in your case, I understand you can't import source schema , However, you can consider opting for Merge schema option in sink settings.
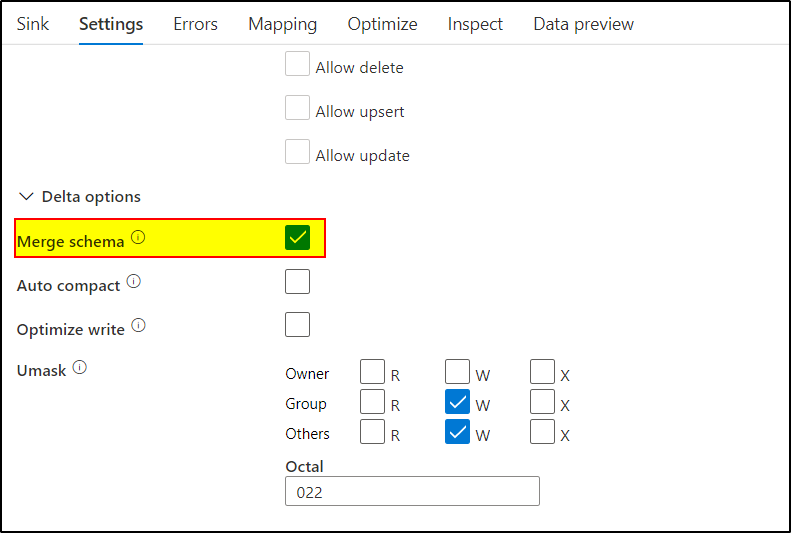
When merge schema option is enabled, any columns that are present in the previous stream but not in the Delta table are automatically added on to the end of the schema.
Please let us know how it goes.
Hi @Vedant Desai ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well.