V mnoha rozsáhlých řešeních se data dělí na oddíly , které je možné spravovat a přistupovat k nich samostatně. Dělení může vylepšit škálovatelnost, omezit kolize a optimalizovat výkon. Může také poskytovat mechanismus rozdělování dat podle způsobu používání. Můžete například archivovat starší data v levnějším úložišti dat.
Strategie dělení ale musí být zvolena pečlivě, aby se maximalizovaly výhody a zároveň minimalizovaly nepříznivé účinky.
Poznámka
Termín dělení v tomto článku označuje proces fyzického rozdělení dat do samostatných úložišť dat. Není to tedy to samé jako dělení tabulek SQL Serveru.
Proč dělit data?
Zlepšení škálovatelnosti. Když vertikálně navyšujete kapacitu jednoho databázového systému, časem se dosáhne fyzického limitu hardwaru. Pokud rozdělíte data mezi více oddílů, z nichž každý je hostovaný na samostatném serveru, můžete systém škálovat téměř na neomezenou dobu.
Zvyšte výkon. Operace přístupu k datům v jednotlivých oddílech probíhají v menších objemech dat. Správně provedené dělení může váš systém zefektivnit. Operace, které ovlivňují víc než jeden oddíl, mohou běžet paralelně.
Vylepšení zabezpečení. V některých případech můžete citlivá a nesmyslná data rozdělit do různých oddílů a použít u citlivých dat různé bezpečnostní prvky.
Zajištění provozní flexibility. Dělení nabízí řadu příležitostí pro doladění operací, maximalizaci efektivity správy a minimalizaci nákladů. Můžete například definovat různé strategie pro správu, monitorování, zálohování a obnovení a další úlohy správy na základě důležitosti dat v jednotlivých oddílech.
Zajištění shody mezi úložištěm dat a způsobem použití. Dělení umožňuje nasadit jednotlivé oddíly do různých typů úložišť dat, a to na základě nákladů a integrovaných funkcí, které úložiště dat nabízejí. Například velká binární data mohou být uložena v úložišti objektů blob, zatímco strukturovanější data mohou být uložena v databázi dokumentů. Přečtěte si o volbě správného úložiště dat.
Zlepšení dostupnosti. Rozdělení dat napříč několika servery umožňuje vyhnout se kritickému prvku způsobujícímu selhání. Pokud dojde k selhání jedné instance, nebudou k dispozici pouze data v tomto oddílu. Operace s dalšími oddíly mohou pokračovat. U spravovaných úložišť dat PaaS je tato úvaha méně relevantní, protože tyto služby jsou navržené s integrovanou redundancí.
Navrhování oddílů
Existují tři typické strategie dělení dat:
Horizontální dělení (označované také jako sharding). V této strategii je každý oddíl samostatným úložištěm dat, ale všechny oddíly mají stejné schéma. Každý oddíl se označuje jako horizontální oddíl a obsahuje určitou podmnožinu dat, například všechny objednávky pro konkrétní sadu zákazníků.
Vertikální dělení. Při použití této strategie každý oddíl obsahuje podmnožinu polí pro položky v úložišti dat. Pole jsou rozdělená podle způsobu jejich použití. Můžete například dát často používaná pole do jednoho vertikálního oddílu a méně používaná pole do jiného.
Funkční dělení. Při použití této strategie jsou data agregovaná podle způsobu použití v jednotlivých ohraničených kontextech v rámci systému. Systém elektronického obchodování může například ukládat data faktur do jednoho oddílu a data inventáře produktů do jiného.
Tyto strategie lze kombinovat a doporučujeme, abyste je při návrhu schématu dělení zvážili všechny. Můžete například rozdělit data do horizontálních oddílů a data v jednotlivých horizontálních oddílech dál rozdělit pomocí vertikálního dělení.
Horizontální dělení (sharding)
Obrázek 1 znázorňuje horizontální dělení nebo horizontální dělení. V tomto příkladu jsou data o zásobách produktů rozdělená do horizontálních oddílů na základě kódu Product Key. Každý horizontální oddíl uchovává data pro souvislý rozsah klíčů horizontálního oddílu (A-G a H-Z) v abecedním pořadí. Horizontální dělení rozděluje zatížení na více počítačů, což snižuje kolize a zvyšuje výkon.
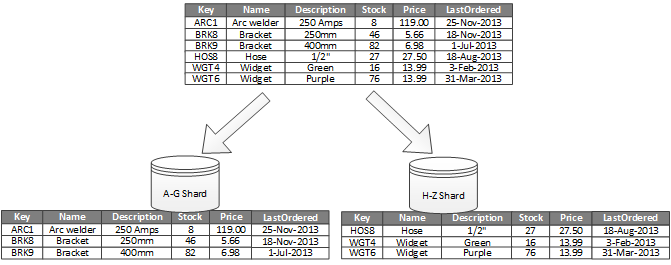
Obrázek 1 – Horizontální dělení (horizontální dělení) dat na základě klíče oddílu
Nejdůležitějším faktorem je volba klíče horizontálního dělení. Jakmile je systém v provozu, může být změna klíčů někdy obtížná. Klíč musí zajistit, aby se data rozdělila na oddíly, aby se úloha rozložila co nej rovnoměrně napříč horizontálními oddíly.
Horizontální oddíly nemusí mít stejnou velikost. Důležitější je vyvážit počet žádostí. Některé horizontální oddíly můžou být velmi velké, ale každá položka má nízký počet operací přístupu. Jiné horizontální oddíly mohou být menší, ale k jednotlivým položkám se přistupuje mnohem častěji. Je také důležité zajistit, aby jeden horizontální oddíl nepřekračoval limity škálování (z hlediska kapacity a prostředků zpracování) úložiště dat.
Vyhněte se vytváření "horkých" oddílů, které můžou ovlivnit výkon a dostupnost. Například použití prvního písmena jména zákazníka způsobí nevyváženou distribuci, protože některá písmena jsou běžnější. Místo toho použijte hodnotu hash identifikátoru zákazníka k rovnoměrnější distribuci dat napříč oddíly.
Zvolte klíč horizontálního dělení, který minimalizuje budoucí požadavky na rozdělení velkých horizontálních oddílů, sdružování malých horizontálních oddílů do větších oddílů nebo změnu schématu. Tyto operace mohou být časově velmi náročné a jejich provádění může vyžadovat převedení jednoho nebo více horizontálních oddílů do offline režimu.
Pokud se horizontální oddíly replikují, je možné zachovat některé z replik online, zatímco se jiné dělí, slučují nebo se mění jejich konfigurace. Systém ale může potřebovat omezit operace, které je možné provést během rekonfigurace. Například data v replikách můžou být označená jako jen pro čtení, aby se zabránilo inkonzistenci dat.
Další informace o horizontálním dělení najdete v tématu Model horizontálního dělení.
Vertikální dělení
Nejběžnějším využitím vertikálního dělení je snížit náklady na vstupně-výstupní operace a výkon spojené s načítáním položek, ke kterým se často přistupuje. Obrázek 2 ukazuje příklad vertikálního dělení. V tomto příkladu jsou různé vlastnosti položky uloženy v různých oddílech. Jeden oddíl obsahuje data, ke kterým se přistupuje častěji, včetně názvu produktu, popisu a ceny. Jiný oddíl obsahuje data zásob: počet zásob a datum poslední objednávky.
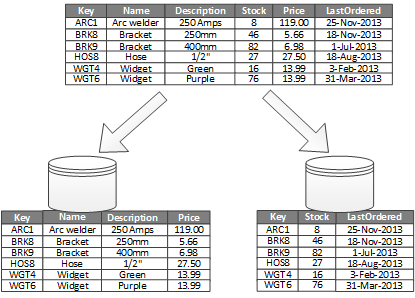
Obrázek 2 – Vertikální dělení dat podle způsobu použití
V tomto příkladu se aplikace pravidelně se dotazuje na název, popis a cenu produktů, když zákazníkům zobrazuje informace o produktech. Počet zásob a datum poslední objednávky se drží v samostatném oddílu, protože tyto dvě položky se běžně používají společně.
Další výhody vertikálního dělení:
Relativně pomalu se pohybující data (název produktu, popis a cena) je možné oddělit od dynamičtějších dat (úroveň zásob a datum poslední objednávky). Pomalý přesun dat je vhodným kandidátem pro aplikaci k ukládání do mezipaměti.
Citlivá data je možné uložit do samostatného oddílu s dalšími bezpečnostními prvky.
Vertikální dělení může snížit množství souběžného přístupu, který je potřeba.
Vertikální dělení funguje v rámci úložiště dat na úrovni entit, částečně je normalizuje a dělí široké položky do sady úzkých položek. Je ideální pro sloupcově orientovaná úložiště dat, jako je například HBase a Cassandra. Pokud se data v kolekci sloupců pravděpodobně nebudou měnit, měli byste také zvážit použití sloupcových úložišť v SQL Serveru.
Funkční dělení
Pokud je možné identifikovat ohraničený kontext pro každou jednotlivou obchodní oblast v aplikaci, funkční dělení je způsob, jak zlepšit izolaci a výkon přístupu k datům. Dalším běžným použitím funkčního dělení je oddělení dat pro čtení a zápisu od dat jen pro čtení. Obrázek 3 ukazuje přehled funkčního dělení, kde jsou data o zásobách oddělená od zákaznických dat.

Obrázek 3 – Funkční dělení dat podle ohraničeného kontextu nebo subdomény
Tato strategie dělení pomáhá omezit kolize přístupu k datům napříč různými částmi systému.
Navrhování oddílů pro zajištění škálovatelnosti
Pro dosažení maximální škálovatelnosti je potřeba vzít v úvahu velikost a úlohy pro každý oddíl a vyvážit je tak, aby byla data distribuovaná. Musíte ale data rozdělit tak, aby nepřekračovala limity škálování pro oddíly úložiště.
Při navrhování oddílů pro zajištění škálovatelnosti postupujte takto:
- Proveďte analýzu aplikace, abyste pochopili vzory přístupu k datům, jako je například velikost sad výsledků vracených jednotlivými dotazy, četnost přístupu a s ní spojená latence a požadavky na zpracování výpočetních funkcí na straně serveru. V řadě případů bude většinu prostředků zpracování požadovat jenom několik málo hlavních entit.
- Pomocí této analýzy stanovte aktuální a budoucí cíle škálovatelnosti, jako je například velikost dat a zatížení. Distribucí dat napříč oddíly potom splňte cíle škálovatelnosti. Pro horizontální dělení je výběr správného klíče horizontálního dělení důležitý, aby byla distribuce rovnoměrná. Další informace najdete v tématu Model horizontálního dělení.
- Ujistěte se, že každý oddíl má dostatek prostředků pro zvládnutí požadavků na škálovatelnost z hlediska velikosti a propustnosti dat. V závislosti na úložišti dat může být velikost úložného prostoru, výpočetního výkonu nebo šířky pásma sítě na oddíl omezena. Pokud požadavky pravděpodobně překročí tato omezení, možná budete muset upřesnit strategii dělení nebo dále rozdělit data, případně zkombinovat dvě nebo více strategií.
- Monitorujte systém a ověřte, že se data distribuují podle očekávání a že oddíly zvládnou zatížení. Skutečné využití nemusí vždy odpovídat tomu, co analýza predikuje. Pokud ano, může být možné oddíly znovu vybalancovat nebo jinak přepracovat některé části systému tak, aby získaly požadovanou rovnováhu.
Některá cloudová prostředí přidělují prostředky z hlediska hranic infrastruktury. Zajistěte, aby omezení vaší vybrané hranice poskytovala dostatek místa pro veškerý předpokládaný nárůst objemu dat, a to z hlediska úložiště dat, výpočetního výkonu a šířky pásma.
Pokud například používáte Azure Table Storage, existuje omezení objemu požadavků, které může v určitém časovém období zpracovat jeden oddíl. (Další informace najdete v tématu Cíle škálovatelnosti a výkonu úložiště Azure.) Zaneprázdněný horizontální oddíl může vyžadovat více prostředků, než dokáže zpracovat jeden oddíl. Pokud ano, možná bude potřeba horizontální oddíl rozdělit na oddíly, aby se zatížení rozložilo. Pokud celková velikost nebo propustnost těchto tabulek překročí kapacitu účtu úložiště, možná budete muset vytvořit další účty úložiště a rozprostřít tabulky mezi tyto účty.
Navrhování oddílů pro zajištění výkonu dotazů
Výkon dotazů se často dá zvýšit použitím menších sad dat a spouštěním paralelních dotazů. Každý oddíl by měl obsahovat malou část celé datové sady. Toto omezení objemu může zlepšit výkon dotazů. Vytváření oddílů ale není alternativou správného návrhu a konfigurace databáze. Ujistěte se například, že máte potřebné indexy.
Při navrhování oddílů pro zajištění výkonu dotazů postupujte takto:
Prověřte výkon a požadavky aplikací:
- Pomocí obchodních požadavků určete důležité dotazy, které musí vždy rychle provádět.
- Sledujte systém a určete případné dotazy, jejichž zpracování je pomalé.
- Zjistěte, které dotazy se provádějí nejčastěji. I když má jeden dotaz minimální náklady, kumulativní spotřeba prostředků může být významná.
Data, která jsou příčinou nízkého výkonu, rozdělte do oddílů:
- Omezte velikosti jednotlivých oddílů, aby doba odezvy dotazů odpovídala cílovým hodnotám.
- Pokud používáte horizontální dělení, navrhněte klíč horizontálního dělení tak, aby aplikace snadno vybrala správný oddíl. Zabrání tak tomu, aby dotaz musel procházet všechny oddíly.
- Zamyslete se nad umístěním oddílu. Pokud je to možné, zkuste ponechat data v oddílech, které jsou geograficky umístěné blízko aplikacím a uživatelům, kteří k nim přistupují.
Pokud nějaká entita má požadavky na propustnost a výkon dotazů, použijte funkční dělení na základě této entity. Pokud ani to požadavky nesplní, použijte také horizontální dělení. Ve většině případů bude stačit jedna strategie dělení, ale v některých případech je efektivnější obě strategie zkombinovat.
Zvažte paralelní spouštění dotazů napříč oddíly, abyste zlepšili výkon.
Navrhování oddílů pro zajištění dostupnosti
Rozdělení dat do oddílů může vylepšit dostupnost aplikací, protože zajistí, že celá datová sada nepředstavuje jeden kritický prvek způsobující selhání a že jednotlivé dílčí sady se dají spravovat nezávisle.
Vezměte v úvahu následující faktory, které mají vliv na dostupnost:
Důležitost dat pro obchodní operace. Určete, která data jsou důležité obchodní informace, jako jsou transakce, a která data jsou méně důležitá provozní data, jako jsou soubory protokolů.
Zvažte ukládání důležitých dat do vysoce dostupných oddílů s vhodným plánem zálohování.
Vytvořte samostatné postupy správy a monitorování pro různé datové sady.
Data se stejnou úrovní důležitosti umístěte do stejného oddílu, aby je bylo možné zálohovat společně s odpovídající frekvencí. Například oddíly, které obsahují transakční data, může být potřeba zálohovat častěji než oddíly, které obsahují informace o protokolování nebo trasování.
Způsob správy jednotlivých oddílů. Navrhování oddílů pro podporu nezávislé správy a údržby má několik výhod. Příklad:
Pokud oddíl selže, je možné ho obnovit nezávisle bez aplikací, které přistupují k datům v jiných oddílech.
Dělení dat podle zeměpisné oblasti umožňuje provádění úloh plánované údržby mimo špičku v jednotlivých oblastech. Ujistěte se, že oddíly nejsou příliš velké, aby se zabránilo dokončení plánované údržby během tohoto období.
Určení, jestli se mají důležitá data replikovat napříč oddíly. Tato strategie může zlepšit dostupnost a výkon, ale může také přinést problémy s konzistencí. Synchronizace změn s každou replikou nějakou dobu trvá. Během tohoto období budou různé oddíly obsahovat různé hodnoty dat.
Aspekty návrhu aplikace
Dělení zvyšuje složitost návrhu a vývoje systému. Berte dělení jako základní část návrhu systému, i když systém zpočátku obsahuje pouze jeden oddíl. Pokud dělení řešíte jako domýšlání, bude náročnější, protože už máte aktivní systém, který je potřeba udržovat:
- Logiku přístupu k datům bude potřeba upravit.
- Kvůli distribuci mezi oddíly může být potřeba migrovat velké množství existujících dat.
- Uživatelé očekávají, že během migrace budou moct systém dál používat.
V některých případech se dělení nepovažuje za důležité, protože počáteční datová sada je malá a snadno ji zvládne jediný server. To může platit pro některé úlohy, ale s rostoucím počtem uživatelů je potřeba rozšířit mnoho komerčních systémů.
Dělení navíc neprospívá jen velkým datovým úložištím. Například k malému úložišti dat můžou hromadně přistupovat stovky klientů souběžně. Dělení dat v této situaci může pomoct omezit kolize a vylepšit propustnost.
Při návrhu schématu dělení dat zvažte následující body:
Minimalizujte operace přístupu k datům napříč oddíly. Pokud je to možné, udržujte v každém oddílu pohromadě data nejběžnějších operací s databází, abyste minimalizovali množství operací přístupu k datům napříč oddíly. Dotazování napříč oddíly může být časově náročnější než dotazování v rámci jednoho oddílu, ale optimalizace oddílů pro jednu sadu dotazů může nepříznivě ovlivnit jiné sady dotazů. Pokud potřebujete dotazovat napříč oddíly, minimalizujte čas dotazování spouštěním paralelních dotazů a agregací výsledků v rámci aplikace. (Tento přístup nemusí být v některých případech možný, například když se výsledek z jednoho dotazu použije v dalším dotazu.)
Zvažte replikaci statických referenčních dat. Pokud dotazy používají relativně statická referenční data, jako jsou tabulky PSČ nebo seznamy produktů, zvažte replikaci těchto dat do všech oddílů, abyste omezili samostatné operace vyhledávání v různých oddílech. Tento přístup může také snížit pravděpodobnost, že se referenční data stanou "horkou" datovou sadou s velkým provozem v celém systému. Se synchronizací jakýchkoli změn referenčních dat jsou ale spojené další náklady.
Minimalizujte spojení napříč oddíly. Pokud je to možné, minimalizujte požadavky na referenční integritu napříč vertikálními a funkčními oddíly. V těchto schématech je aplikace zodpovědná za udržování referenční integrity napříč oddíly. Dotazy, které spojují data napříč několika oddíly, jsou neefektivní, protože aplikace obvykle potřebuje provádět po sobě jdoucí dotazy na základě klíče a potom cizího klíče. Místo toho zvažte replikaci nebo denormalizaci relevantních dat. Pokud je potřeba spojení napříč oddíly, spusťte paralelní dotazy na oddíly a připojte data v rámci aplikace.
Zapojte konečnou konzistenci. Vyhodnoťte, jestli je silná konzistence skutečně požadavkem. Běžným přístupem v distribuovaných systémech je implementace konečné konzistence. Data v každém oddílu se aktualizují nezávisle a logika aplikace zajišťuje úspěšné dokončení všech aktualizací. Zpracovává také nekonzistence, ke kterým může docházet v důsledku dotazování dat, zatímco je operace s konečnou konzistencí spuštěná.
Zvažte, jak dotazy zjišťují správný oddíl. Pokud dotaz musí pro nalezení požadovaných dat prohledávat všechny oddíly, má to výrazný dopad na výkon, a to i když je spuštěných více paralelních dotazů. Při vertikálním a funkčním dělení můžou dotazy přirozeně specifikovat oddíl. Horizontální dělení může na druhou stranu ztížit vyhledání položky, protože každý horizontální oddíl má stejné schéma. Typické řešení pro údržbu mapy, která slouží k vyhledání umístění horizontálních oddílů pro konkrétní položky. Tuto mapu je možné implementovat do logiky horizontálního dělení aplikace nebo udržovat v úložišti dat, pokud podporuje transparentní horizontální dělení.
Zvažte pravidelné vyrovnávání horizontálních oddílů. Díky horizontálnímu dělení může vyrovnávání horizontálních oddílů pomoct rovnoměrně distribuovat data podle velikosti a úlohy, aby se minimalizovaly hotspoty, maximalizovaly výkon dotazů a obchážely omezení fyzického úložiště. Jedná se však o složitou úlohu, která často vyžaduje použití vlastního nástroje nebo procesu.
Replikujte oddíly. Pokud budete replikovat každý oddíl, získáte další ochranu před selháním. Pokud selže jedna replika, dotazy můžou být směrovány na funkční kopii.
Pokud dosáhnete fyzických omezení strategie dělení, možná bude potřeba rozšířit škálovatelnost na jinou úroveň. Pokud například dělení probíhá na úrovni databáze, možná bude potřeba umístit nebo replikovat oddíly do více databází. Pokud dělení již probíhá na úrovni databáze a přesto dochází k problémům kvůli fyzickým omezením, může to znamenat, že je potřeba umístit nebo replikovat oddíly do více hostitelských účtů.
Vyhněte se transakcím, které přistupují k datům v několika oddílech. Některá úložiště dat implementují pro operace upravující data transakční konzistenci a integritu, ale pouze pokud se tato data nacházejí v jednom oddílu. Pokud potřebujete transakční podporu napříč několika oddíly, pravděpodobně ji budete muset implementovat jako součást logiky aplikace, protože většina systémů dělení neposkytuje nativní podporu.
Všechna úložiště dat vyžadují určité aktivity provozní správy a monitorování. Těmito úlohami může být například načtení dat, zálohování a obnovení dat, změna uspořádání dat a zajištění správného a efektivního fungování systému.
Vezměte v úvahu následující faktory, které ovlivňují provozní správu:
Způsob implementace odpovídajících úloh správy a provozních úloh při dělení dat. Mezi tyto úlohy může patřit zálohování, obnovení a archivace dat, monitorování systému a další úlohy správy. Například udržování logické konzistence během operací zálohování a obnovení může být náročné.
Způsob načtení dat do několika oddílů a přidání nových dat přicházejících z jiných zdrojů. Některé nástroje a pomůcky nemusí podporovat operace s horizontálně dělenými daty, jako je například načtení dat do správného oddílu.
Způsob pravidelné archivace a odstraňování dat. Abyste zabránili nadměrnému nárůstu oddílů, musíte pravidelně archivovat a odstraňovat data (například měsíčně). Data možná bude nutné transformovat, aby odpovídala jinému schématu archivu.
Způsob zjišťování problémů s integritou dat. Zvažte spuštění pravidelného procesu a vyhledejte případné problémy s integritou dat, například data v jednom oddílu, která odkazují na chybějící informace v jiném. Tento proces se může pokusit tyto problémy vyřešit automaticky nebo vygenerovat sestavu pro ruční kontrolu.
Vyrovnávání oddílů
S tím, jak systém zraje, možná budete muset upravit schéma dělení. Jednotlivé oddíly například můžou začít dostávat nepřiměřený objem provozu a zahřívat se, což může vést k nadměrným kolizím. Nebo jste mohli podcenit objem dat v některých oddílech, což způsobilo, že se některé oddíly blíží limitům kapacity.
Některá úložiště dat, například Azure Cosmos DB, můžou automaticky znovu vybalažovat oddíly. V ostatních případech je vyrovnávání úlohou správy, která se skládá ze dvou fází:
Určete novou strategii dělení.
- Které oddíly je potřeba rozdělit (nebo případně zkombinovat)?
- Jaký je nový klíč oddílu?
Migrujte data ze starého schématu dělení na novou sadu oddílů.
V závislosti na úložišti dat můžete být schopni migrovat data mezi oddíly, když se používají. Říká se tomu online migrace. Pokud to není možné, možná budete muset při přemístění dat nastavit oddíly jako nedostupné (offline migrace).
Offline migrace
Offline migrace je obvykle jednodušší, protože snižuje pravděpodobnost kolizí. Offline migrace funguje koncepčně takto:
- Označte oddíl jako offline.
- Rozdělit a sloučit a přesunout data do nových oddílů.
- Ověření dat.
- Převeďte nové oddíly online.
- Odeberte starý oddíl.
Volitelně můžete v kroku 1 označit oddíl jako jen pro čtení, aby aplikace mohly i nadále číst data, i když se přesunují.
Online migrace
Online migrace je složitější, ale méně rušivá. Proces se podobá offline migraci s tím rozdílem, že původní oddíl není označený jako offline. V závislosti na členitosti procesu migrace (například položka po položce versus horizontální oddíl podle horizontálního oddílu) může přístupový datový kód v klientských aplikacích zpracovávat čtení a zápis dat, která jsou uložená ve dvou umístěních, v původním oddílu a v novém oddílu.
Další kroky
- Přečtěte si o strategiích dělení pro konkrétní služby Azure. Viz Strategie dělení dat.
- Cíle škálovatelnosti a výkonu úložiště Azure
Související prostředky
Pro váš scénář můžou být relevantní následující vzory návrhu:
Model horizontálního dělení popisuje některé běžné strategie horizontálního dělení dat.
Vzor tabulky indexů ukazuje, jak vytvořit sekundární indexy pro data. Díky tomuto přístupu může aplikace rychle načítat data pomocí dotazů, které neodkazují na primární klíč kolekce.
Model materializovaného zobrazení popisuje, jak generovat předem vyplněná zobrazení, která shrnují data pro podporu rychlých operací dotazů. Tento přístup může být užitečný v děleném úložišti dat, pokud jsou oddíly obsahující data, která se sumarizují, distribuované napříč několika lokalitami.