Compute
يشير حساب Azure Databricks إلى تحديد موارد الحوسبة المتوفرة في مساحة عمل Azure Databricks. يحتاج المستخدمون إلى الوصول إلى الحوسبة لتشغيل هندسة البيانات وعلوم البيانات وأحمال عمل تحليلات البيانات، مثل مسارات ETL للإنتاج والتحليلات المتدفقة والتحليلات المخصصة والتعلم الآلي.
يمكن للمستخدمين إما الاتصال بالحوسبة الموجودة أو إنشاء حساب جديد إذا كان لديهم الأذونات المناسبة.
يمكنك عرض الحساب الذي لديك حق الوصول إليه باستخدام قسم الحوسبة في مساحة العمل:
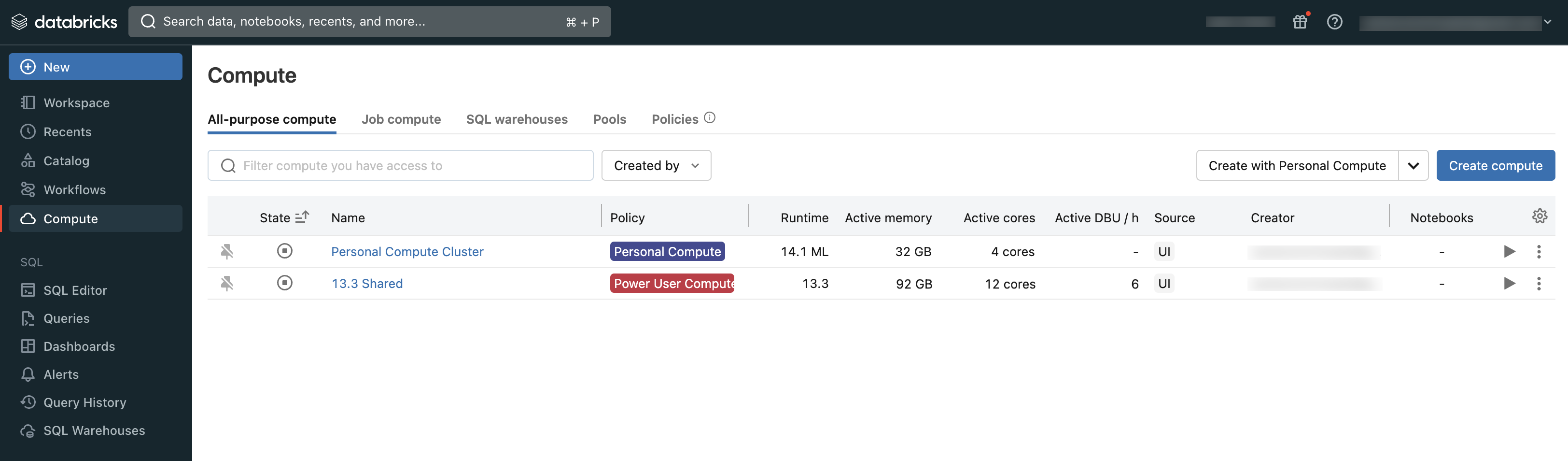
أنواع الحساب
هذه هي أنواع الحوسبة المتوفرة في Azure Databricks:
حساب بلا خادم لدفاتر الملاحظات (معاينة عامة): حساب عند الطلب وقابل للتطوير يستخدم لتنفيذ التعليمات البرمجية SQL وPython في دفاتر الملاحظات.
حساب بلا خادم لسير العمل (معاينة عامة): حساب عند الطلب وقابل للتطوير يستخدم لتشغيل مهام Databricks دون تكوين البنية الأساسية ونشرها.
الحوسبة لجميع الأغراض: الحوسبة المقدمة المستخدمة لتحليل البيانات في دفاتر الملاحظات. يمكنك إنشاء هذا الحساب وإنهائه وإعادة تشغيله باستخدام واجهة المستخدم أو CLI أو REST API.
حساب الوظيفة: الحوسبة المقدمة المستخدمة لتشغيل الوظائف التلقائية. يقوم مجدول مهمة Azure Databricks تلقائيا بإنشاء حساب وظيفة كلما تم تكوين وظيفة للتشغيل على حساب جديد. تنتهي الحوسبة عند اكتمال المهمة. لا يمكنك إعادة تشغيل حساب وظيفة. راجع استخدام حساب Azure Databricks مع وظائفك.
تجمعات المثيلات: الحساب مع المثيلات الخاملة الجاهزة للاستخدام، المستخدمة لتقليل أوقات البدء والتحجيم التلقائي. يمكنك إنشاء هذا الحساب باستخدام واجهة المستخدم أو CLI أو واجهة برمجة تطبيقات REST.
مستودعات SQL بلا خادم: الحوسبة المرنة عند الطلب المستخدمة لتشغيل أوامر SQL على كائنات البيانات في محرر SQL أو دفاتر الملاحظات التفاعلية. يمكنك إنشاء مستودعات SQL باستخدام واجهة المستخدم أو CLI أو واجهة برمجة تطبيقات REST.
مستودعات SQL الكلاسيكية: تستخدم لتشغيل أوامر SQL على كائنات البيانات في محرر SQL أو دفاتر الملاحظات التفاعلية. يمكنك إنشاء مستودعات SQL باستخدام واجهة المستخدم أو CLI أو واجهة برمجة تطبيقات REST.
تصف المقالات الواردة في هذا القسم كيفية العمل مع موارد الحوسبة باستخدام واجهة مستخدم Azure Databricks. للحصول على أساليب أخرى، راجع استخدام سطر الأوامر ومرجع Databricks REST API.
وقت تشغيل Databricks
Databricks Runtime هو مجموعة من المكونات الأساسية التي تعمل على الحساب الخاص بك. وقت تشغيل Databricks هو إعداد قابل للتكوين في جميع أغراض حساب الوظائف ولكن يتم تحديده تلقائيا في مستودعات SQL.
يتضمن كل إصدار من إصدارات وقت تشغيل Databricks تحديثات تحسن قابلية استخدام تحليلات البيانات الضخمة وأدائها وأمانها. يضيف وقت تشغيل Databricks على الحساب الخاص بك العديد من الميزات، بما في ذلك:
- Delta Lake، وهي طبقة تخزين من الجيل التالي مبنية فوق Apache Spark توفر معاملات ACID والتخطيطات والفهارس المحسنة وتحسينات محرك التنفيذ لبناء مسارات البيانات. راجع ما هو Delta Lake؟.
- مكتبات Java وSc scala وPython وR المثبتة.
- Ubuntu ومكتبات النظام المصاحبة لها.
- مكتبات GPU للمجموعات التي تدعم وحدة معالجة الرسومات.
- خدمات Azure Databricks التي تتكامل مع المكونات الأخرى للنظام الأساسي، مثل دفاتر الملاحظات والوظائف وإدارة نظام المجموعة.
للحصول على معلومات حول محتويات كل إصدار من إصدارات وقت التشغيل، راجع ملاحظات الإصدار.
تعيين إصدار وقت التشغيل
يتم إصدار إصدارات وقت تشغيل Databricks بشكل منتظم:
- يتم تمثيل إصدارات الدعم طويل الأجل بواسطة مؤهل LTS (على سبيل المثال، 3.5 LTS). لكل إصدار رئيسي، نعلن عن إصدار ميزة "أساسي"، والذي نقدم له ثلاث سنوات كاملة من الدعم. راجع دورات حياة دعم وقت تشغيل Databricks لمزيد من المعلومات.
- يتم تمثيل الإصدارات الرئيسية بزيادة إلى رقم الإصدار الذي يسبق الفاصلة العشرية (الانتقال من 3.5 إلى 4.0، على سبيل المثال). يتم إصدارها عند وجود تغييرات رئيسية، قد لا يكون بعضها متوافقا مع الإصدارات السابقة.
- يتم تمثيل إصدارات الميزات بزيادة إلى رقم الإصدار الذي يتبع الفاصلة العشرية (الانتقال من 3.4 إلى 3.5، على سبيل المثال). يتضمن كل إصدار رئيسي إصدارات ميزات متعددة. تتوافق إصدارات الميزات دائما مع الإصدارات السابقة ضمن إصدارها الرئيسي.