ملف ثنائي
يدعم Databricks Runtime مصدر بيانات الملف الثنائي، والذي يقرأ الملفات الثنائية ويحول كل ملف إلى سجل واحد يحتوي على المحتوى الخام وبيانات التعريف للملف. ينتج مصدر بيانات الملف الثنائي DataFrame مع الأعمدة التالية وربما أعمدة القسم:
path (StringType): مسار الملف.modificationTime (TimestampType): وقت تعديل الملف. في بعض تطبيقات Hadoop FileSystem، قد تكون هذه المعلمة غير متوفرة وسيتم تعيين القيمة إلى قيمة افتراضية.length (LongType): طول الملف بالبايت.content (BinaryType): محتويات الملف.
لقراءة الملفات الثنائية، حدد مصدر format البيانات ك binaryFile.
الصور
توصي Databricks باستخدام مصدر بيانات الملف الثنائي لتحميل بيانات الصورة.
تدعم الدالة Databricks display عرض بيانات الصور التي تم تحميلها باستخدام مصدر البيانات الثنائي.
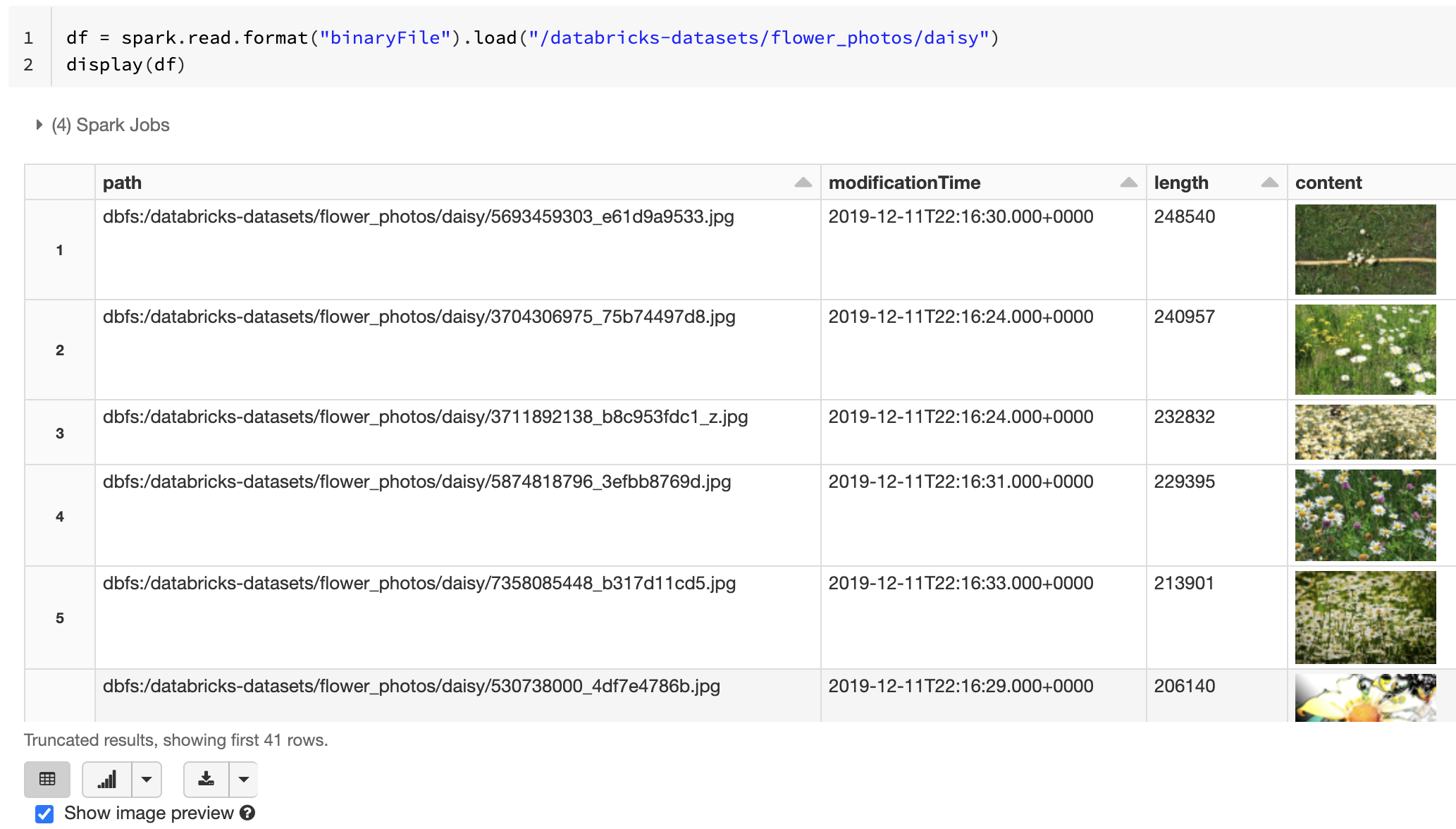
إذا كانت جميع الملفات المحملة تحتوي على اسم ملف مع ملحق صورة، يتم تمكين معاينة الصورة تلقائيا:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
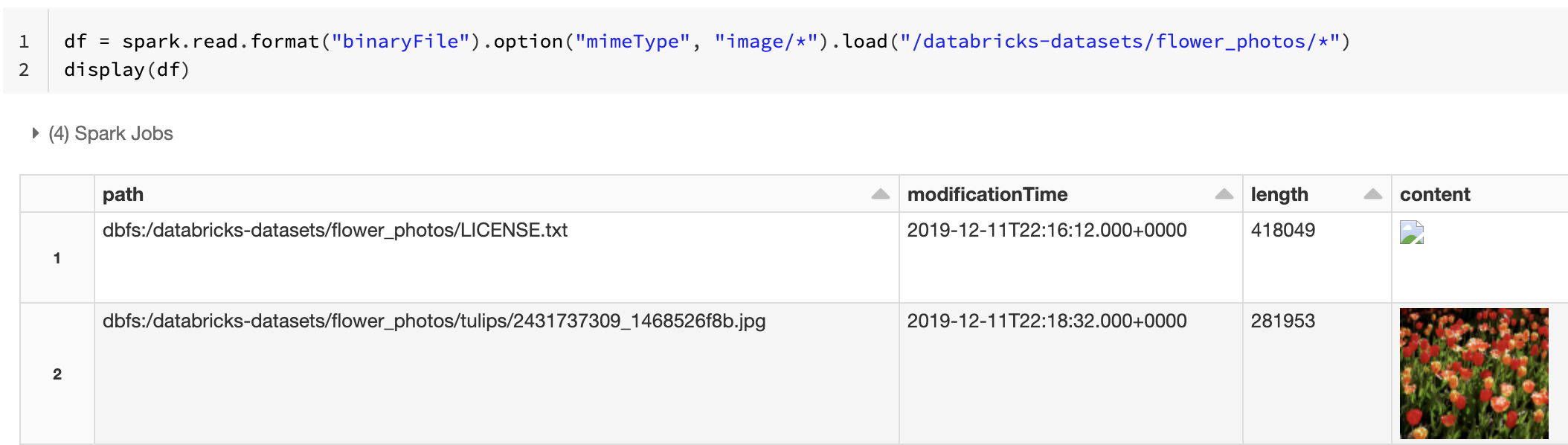
بدلا من ذلك، يمكنك فرض وظيفة معاينة الصورة باستخدام mimeType الخيار مع قيمة "image/*" سلسلة لإضافة تعليق توضيحي للعمود الثنائي. يتم فك ترميز الصور استنادا إلى معلومات التنسيق الخاصة بها في المحتوى الثنائي. أنواع الصور المدعومة هي bmpو gifjpegو و.png تظهر الملفات غير المدعومة كأيقونة صورة مقطوعة.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
راجع الحل المرجعي لتطبيقات الصور لسير العمل الموصى به لمعالجة بيانات الصورة.
الخيارات
لتحميل الملفات بمسارات مطابقة لنمط glob معين مع الحفاظ على سلوك اكتشاف القسم، يمكنك استخدام pathGlobFilter الخيار . تقرأ التعليمات البرمجية التالية جميع ملفات JPG من دليل الإدخال مع اكتشاف القسم:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
إذا كنت تريد تجاهل اكتشاف القسم والبحث عن الملفات بشكل متكرر ضمن دليل الإدخال، فاستخدم recursiveFileLookup الخيار . يبحث هذا الخيار من خلال الدلائل المتداخلة حتى إذا لم تتبع أسماؤها نظام تسمية قسم مثل date=2019-07-01.
تقرأ التعليمات البرمجية التالية جميع ملفات JPG بشكل متكرر من دليل الإدخال وتتجاهل اكتشاف القسم:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
توجد واجهات برمجة تطبيقات مماثلة ل Scala وJava وR.
إشعار
لتحسين أداء القراءة عند تحميل البيانات مرة أخرى، توصي Azure Databricks بإيقاف تشغيل الضغط عند حفظ البيانات المحملة من الملفات الثنائية:
spark.conf.set("spark.sql.parquet.compression.codec", "uncompressed")
df.write.format("delta").save("<path-to-table>")