ما المقصود بـ Azure HDInsight؟
Azure HDInsight هي خدمة تحليلات مُدارة كاملة الطيف ومفتوحة المصدر في السحابة للمؤسسات. باستخدام HDInsight، يمكنك استخدام أطر عمل مفتوحة المصدر مثل Apache Spark وApache Hive و LLAP و Apache Kafka و Hadoop والمزيد في بيئة Azure الخاصة بك.
ما هو HDInsight وبنية تقنية Hadoop؟
Azure HDInsight هو نظام أساسي مدار للمجموعة يسهل تشغيل أطر عمل البيانات الضخمة مثل Apache Spark وApache Hive و LLAP وApache Kafka وApache Hadoop وغيرها في بيئة Azure الخاصة بك. تم تصميمه للتعامل مع كميات كبيرة من البيانات بسرعة وكفاءة عالية.
لماذا يجب أن أستخدم Azure HDInsight؟
| القدرة | الوصف |
|---|---|
| السحابة الأصلية | يمكنك Azure HDInsight من إنشاء مجموعات محسنة ل Spark والاستعلام التفاعلي (LLAP) وKafka وHBase و Hadoop على Azure. كما توفر HDInsight SLA شاملة لجميع أحمال عمل الإنتاج. |
| منخفضة التكلفة وقابلة للتوسع | تمكنك HDInsight من زيادة حجم أعباء العمل صعودًا أو لأسفل. يمكنك تقليل التكاليف من خلال إنشاء مجموعات عند الطلب والدفع فقط مقابل ما تستخدمه. يمكنك أيضًا إنشاء بنية أساسية للبيانات لتفعيل وظائفك. توفر الحوسبة ووحدات التخزين المنفصلة أداء ومرونة أفضل. |
| آمن ومتوافق | تمكنك HDInsight من حماية أصول بيانات المؤسسة باستخدام شبكة Azure الظاهرية والتشفير والتكامل مع معرف Microsoft Entra. كما يُلبي HDInsight معايير الامتثال الصناعة والحكومة الأكثر شعبية. |
| مراقبة | يدمج Azure HDInsight مع سجلات Azure Monitor لتوفير واجهة واحدة يمكنك من خلالها مراقبة جميع مجموعاتك. |
| التوافر العالمي | تتوفر HDInsight في مناطق أكثر من أي عرض آخر من تحليلات البيانات الضخمة. كما يتوفر Azure HDInsight في Azure Government وفي الصين وفي ألمانيا، ما يسمح لك بتلبية احتياجات مؤسستك في المجالات السيادية الرئيسية. |
| الإنتاجية | يتيح لك Azure HDInsight استخدام أدوات إنتاجية غنية لـ Hadoop وSpark مع بيئات التطوير المفضلة لديك. تتضمن بيئات التطوير هذه Visual Studio و VS Code و Eclipse و IntelliJ لدعم Scala و Python و Java و .NET. |
| إمكانية التوسعة | يمكنك توسيع مجموعات HDInsight مع المكونات المثبتة (Hue وPresto وما إلى ذلك) باستخدام إجراءات البرنامج النصي أو عن طريق إضافة عقد الحافة أو عن طريق التكامل مع التطبيقات الأخرى المعتمدة للبيانات الضخمة. يتيح HDInsight التكامل السلس مع حلول البيانات الضخمة الأكثر شيوعًا من خلال نشر بنقرة واحدة. |
ما المقصود بالبيانات الضخمة؟
يتم جمع البيانات الكبيرة في أحجام متزايدة، بسرعات أعلى، وفي مجموعة متنوعة من الأشكال أكثر من أي وقت مضى. قد تكون تاريخية (بمعنى مُخزنة) أو بالوقت الحقيقي (بمعنى مُتدفقة من المصدر). راجع سيناريوهات استخدام HDInsight للتعرف على حالات الاستخدام الأكثر شيوعا للبيانات الضخمة.
أنواع الكتلة في HDInsight
يتضمن HDInsight أنواع كتلة محددة وقدرات تخصيص الكتلة، مثل القدرة على إضافة المكونات والأدوات المساعدة واللغات. HDInsight يقدم أنواع الكتلة التالية:
| نوع شبكة نظام المجموعة | الوصف | بدء الاستخدام |
|---|---|---|
| Apache Hadoop | إطار عمل يستخدم HDFS وإدارة موارد YARN ونموذج برمجة MapReduce بسيط لمعالجة وتحليل البيانات الدفعية بالتوازي. | إنشاء مجموعة Apache Hadoop |
| Apache Spark | إطار عمل معالجة متوازٍ مفتوح المصدر يدعم المعالجة داخل الذاكرة لتعزيز أداء تطبيقات تحليل البيانات الضخمة. راجع ما هو Apache Spark في HDInsight؟. | إنشاء نظام مجموعة Apache Spark |
| Apache HBase | قاعدة بيانات NoSQL المبنية على Hadoop التي توفر الوصول العشوائي والاتساق القوي لكميات كبيرة من البيانات غير منظمة البنية وشبه منظمة البنية-- التي من المحتمل أن تصل إلى مليارات الصفوف أضعاف ملايين الأعمدة. راجع ما هو HBase على HDInsight؟ | إنشاء مجموعة Apache HBase |
| Apache Interactive Query | التخزين المؤقت في الذاكرة لاستعلامات Hive التفاعلية والسريعة. راجع استخدام الاستعلام التفاعلي في HDInsight. | إنشاء مجموعة Interactive Query |
| Apache Kafka | يتم استخدام نظام أساسي مفتوح المصدر لإنشاء مسارات البيانات المتدفقة والتطبيقات. كما يوفر Kafka وظيفة قائمة الرسائل التي تسمح لك بنشر تدفقات البيانات والاشتراك فيها. راجع مقدمة إلى Apache Kafka على HDInsight. | إنشاء نظام مجموعة Apache Kafka |
سيناريوهات لاستخدام HDInsight
يمكن استخدام Azure HDInsight لمجموعة متنوعة من السيناريوهات في معالجة البيانات الضخمة. يمكن أن تكون بيانات تاريخية (البيانات التي تم جمعها وتخزينها بالفعل) أو بيانات في الوقت الفعلي (البيانات التي يتم بثها مباشرة من المصدر). ويمكن تلخيص سيناريوهات معالجة هذه البيانات في الفئات التالية:
معالجة الدفعات (ETL)
استخراج وتحويل وتحميل (ETL) هي عملية حيث يتم استخراج بيانات غير منظم أو منظم من مصادر بيانات غير متجانسة. ثم يتم تحويلها إلى تنسيق منظم وتحميلها في مخزن البيانات. يمكنك استخدام البيانات المحولة لعلوم البيانات أو تخزين البيانات.
تخزين البيانات
يمكنك استخدام HDInsight لإجراء استعلامات تفاعلية في مقاييس petabyte على البيانات المنظمة أو غير المنظمة بأي تنسيق. يمكنك أيضًا إنشاء نماذج تربطها بأدوات BI.
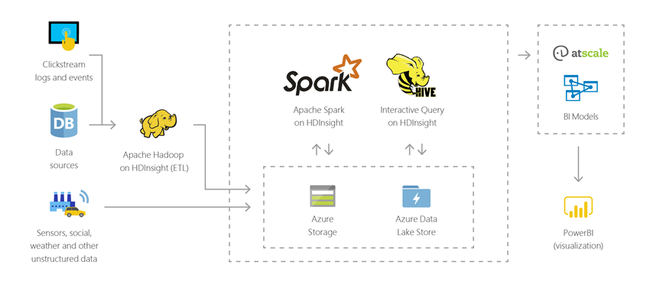
إنترنت الأشياء (IoT)
يمكنك استخدام HDInsight لمعالجة البيانات المتدفقة التي يتم تلقيها في الوقت الفعلي من أنواع مختلفة من الأجهزة. لمزيد من المعلومات، اقرأ منشور المدونة هذا من Azure الذي يعلن عن المعاينة العامة ل Apache Kafka على HDInsight باستخدام أقراص Azure المدارة.
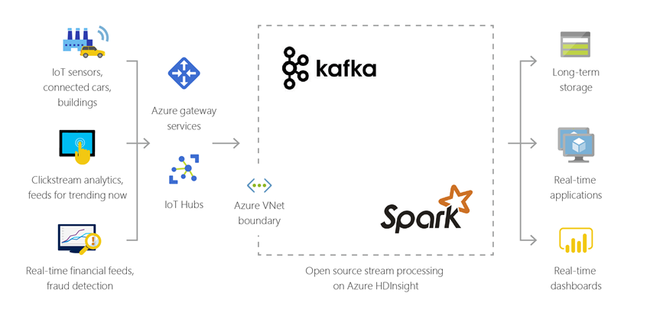
مختلط
يمكنك استخدام HDInsight لتوسيع البنية التحتية الحالية للبيانات الضخمة في الموقع إلى Azure لتطبيق قدرات التحليلات المتقدمة للسحابة.

مكونات مفتوحة المصدر في HDInsight
يمكنك Azure HDInsight من إنشاء مجموعات ذات أطر عمل مفتوحة المصدر مثل Spark وHive و LLAP و Kafka و Hadoop و HBase. بشكل افتراضي، تتضمن هذه المجموعات مكونات مختلفة مفتوحة المصدر مثل Apache Ambari وAvro وApache Hive 3 وHCatalog وApache Hadoop MapReduce وApache Hadoop YARN وApache Phoenix وApache Pig وApache Sqoop وApache Tez وApache Oozie وApache ZooKeeper.
لغات البرمجة في HDInsight
تدعم مجموعات HDInsight، بما في ذلك Spark وHBase وKafka وHadoop وغيرها، العديد من لغات البرمجة. لا يتم تثبيت بعض لغات البرمجة بشكل افتراضي. بالنسبة إلى المكتبات أو الوحدات النمطية أو الحزم غير المثبتة بشكل افتراضي، استخدم إجراء البرنامج النصي لتثبيت المكون.
| لغة البرمجة | المعلومات |
|---|---|
| دعم لغة البرمجة الافتراضية | بشكل افتراضي، تدعم مجموعات HDInsight:
|
| لغات الجهاز الافتراضي لـ Java (JVM) | يمكن تشغيل العديد من اللغات الأخرى غير Java على جهاز Java الافتراضي (JVM). ومع ذلك، إذا قمت بتشغيل بعض هذه اللغات، قد تحتاج إلى تثبيت المزيد من المكونات على نظام المجموعة. يتم دعم اللغات التالية المستندة إلى JVM على مجموعات HDInsight:
|
| لغات محددة لـ Hadoop | تدعم مجموعات HDInsight اللغات التالية الخاصة بتكدس تقنية Hadoop:
|
أدوات التطوير لـ HDInsight
يمكنك استخدام أدوات تطوير HDInsight، بما في ذلك IntelliJ وEclipse وVisual Studio Code وVisual Studio، لكتابة استعلام بيانات HDInsight ومهمة وإرسالها مع التكامل السلس مع Azure.
- مجموعة أدوات Azure ل IntelliJ 10
- مجموعة أدوات Azure ل Eclipse 6
- أدوات Azure HDInsight ل VS Code 13
- أدوات مستودع بيانات Azure ل Visual Studio 9
ذكاء الأعمال على HDInsight
أدوات ذكاء الأعمال المألوفة (BI) تقوم باسترداد البيانات التي تم دمجها مع HDInsight وتحليلها وإعداد التقارير عنها باستخدام الوظيفة الإضافية Power Query أو Microsoft Hive ODBC Driver:
Apache Spark BI باستخدام أدوات تصور البيانات مع Azure HDInsight
تصور بيانات Apache Hive باستخدام Microsoft Power BI في Azure HDInsight
تصور بيانات Interactive Query Hive باستخدام Power BI في Azure HDInsight
الاتصال Excel إلى Apache Hadoop باستخدام Power Query (يتطلب Windows)
الاتصال Excel إلى Apache Hadoop باستخدام برنامج تشغيل Microsoft Hive ODBC (يتطلب Windows)
موقع بيانات الإقامة المُتاحة في المنطقة
لا تقوم Spark و Hadoop و LLAP بتخزين بيانات العملاء، لذلك تفي هذه الخدمات تلقائيا بمتطلبات موقع البيانات في المنطقة المحددة في مركز التوثيق.
Kafka وHBase لا تخزين بيانات العملاء. يتم تخزين هذه البيانات تلقائيا بواسطة Kafka وHBase في منطقة واحدة، لذلك تفي هذه الخدمة بمتطلبات موقع البيانات داخل المنطقة المحددة في مركز التوثيق.
أدوات ذكاء الأعمال المألوفة (BI) استرداد وتحليل والإبلاغ عن البيانات التي يتم دمجها مع HDInsight باستخدام الوظيفة الإضافية Power Query أو Microsoft Hive ODBC Driver.