البرنامج التعليمي: تحميل البيانات وتشغيل الاستعلامات على نظام مجموعة Apache Spark في Azure HDInsight
ستتعلم في هذا البرنامج التعليمي طريقة إنشاء إطار بيانات من ملف csv، وكذلك طريقة تشغيل استعلامات Spark SQL التفاعلية اعتماداً على مجموعة Apache Spark في Azure HDInsight. في Spark، يعتبر إطار البيانات بمثابة مجموعة موزعة من البيانات المنظمة في أعمدة مسمّاة. يعد Dataframe من منظور المفهوم مكافئاً لجدول في قاعدة بيانات العلاقات أو إطار بيانات في R/Python.
في هذا البرنامج التعليمي، تتعلم كيفية:
- إنشاء إطار بيانات من ملف csv
- تشغيل الاستعلامات في إطار البيانات
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. راجع إنشاء مجموعة Apache Spark .
إنشاء تطبيق دفتر الملاحظات Jupyter Notebook
يعتبر Jupyter Notebook في واقع الأمر إطاراً لتدوين الملاحظات التفاعلية التي تدعم مختلف لغات البرمجة. يسمح لك دفتر الملاحظات بالتفاعل مع بياناتك، والجمع بين التعليمات البرمجية ونص تخفيض السعر وإجراء تصورات بسيطة.
عدّل عنوان URL
https://SPARKCLUSTER.azurehdinsight.net/jupyterعن طريق استبدالSPARKCLUSTERباسم مجموعة Spark خاصتك. ثم أدخل عنوان URL المحرر في متصفح الويب. في حالة المطالبة بإدخال بيانات تسجيل الدخول في شبكة نظام المجموعة لشبكة نظام المجموعة.من صفحة ويب Jupyter، بالنسبة لمجموعات Spark 2.4، حدد New>PySpark لإنشاء دفتر ملاحظات. بالنسبة لإصدار Spark 3.1، حدد New>PySpark3 بدلاً من ذلك لإنشاء دفتر ملاحظات لأن PySpark kernel لم يعد متاحاً في Spark 3.1.
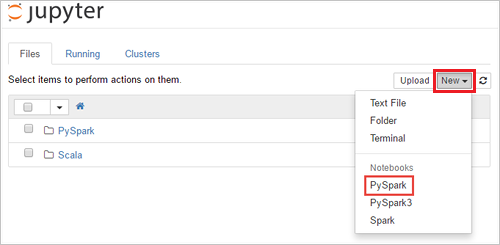
ويتم إنشاء دفتر ملاحظات جديد وفتحه بدون عنوان (
Untitled.ipynb).إشعار
باستخدام PySpark أو PySpark3 kernel لإنشاء دفتر ملاحظات، يتم إنشاء جلسة
sparkتلقائياً لك عند تشغيل خلية التعليمة البرمجية الأولى. ولن تكون بحاجة صراحة إلى إنشاء الجلسة.
إنشاء إطار بيانات من ملف csv
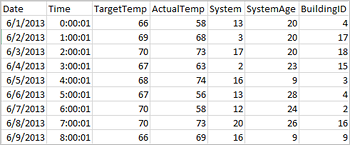
يمكن للتطبيقات إنشاء إطارات بيانات مباشرة من الملفات أو المجلدات على التخزين البعيد مثل Azure Storage أو Azure Data Lake Storage؛ من جدول Hive؛ أو من مصادر بيانات أخرى يدعمها Spark، مثل Azure Cosmos DB وAzure SQL DB وDW وما إلى ذلك. وتُظهر لقطة الشاشة التالية لقطة لملف HVAC.csv المستخدم في هذا البرنامج التعليمي. ويتم إرفاق ملف بتنسيق csv مع جميع مجموعات HDInsight Spark. وتقوم البيانات بجمع التغيرات الطارئة في درجات الحرارة لبعض المباني.
قم بلصق التعليمة البرمجية التالية في خلية فارغة من Jupyter Notebook، ثم اضغط على SHIFT + ENTER لتشغيل التعليمات البرمجية. وتستورد التعليمة البرمجية الأنواع المطلوبة لهذا السيناريو:
from pyspark.sql import * from pyspark.sql.types import *وعند تشغيل استعلام تفاعلي في Jupyter، تعرض نافذة متصفح الويب أو التسمية التوضيحية لعلامة التبويب الحالة (مشغول) إلى جانب عنوان دفتر الملاحظات. وستتمكن بعدها برؤية دائرة صلبة بجوار نص PySpark في الزاوية العلوية اليمنى. بعد اكتمال المهمة، يتم تغييره إلى دائرة فارغة.
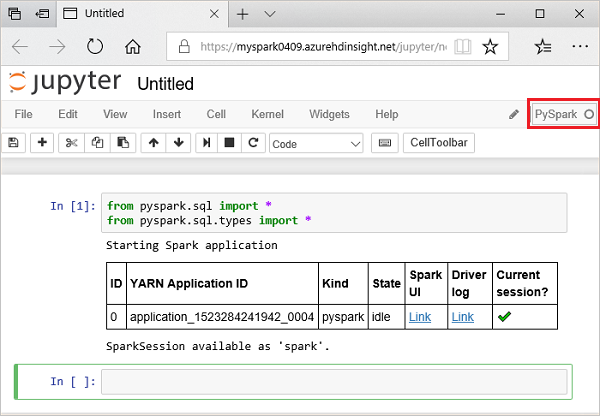
لاحظ أن معرف الجلسة سيعود مرة ثانية. ومن خلال الصورة الواردة أعلاه سترى أن معرف الجلسة هو 0. وفي حالة رغبتك في تحقيق ذلك، ستتمكن من استرداد تفاصيل الجلسة بالانتقال إلى
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsحيث CLUSTERNAME هو اسم مجموعة Spark والمعرف هو رقم معرف الجلسة.احرص على تشغيل التعليمات البرمجية التالية لإنشاء إطار بيانات وجدول مؤقت ( hvac ) عن طريق تشغيل التعليمات البرمجية التالية.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
تشغيل الاستعلامات في إطار البيانات
بمجرد إنشاء الجدول، يمكنك تشغيل الاستعلام التفاعلي على البيانات.
تشغيل الرمز التالي في خلية فارغة من المفكرة:
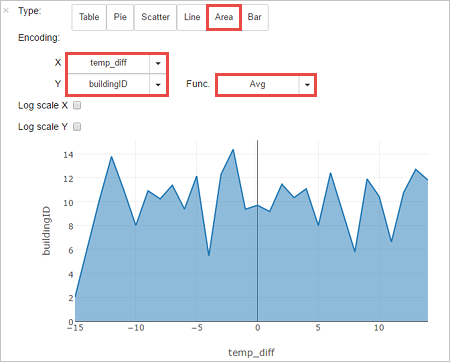
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"يتم عرض المخرجات الجدولية التالية.

يمكنك أيضًا مشاهدة النتائج في المؤثرات البصرية الأخرى أيضًا. لمشاهدة الرسم البياني للمساحة الخاصة بنفس المخرجات، حدد Area، ومن ثم عيّن القيم الأخرى على النحو المبين.
من شريط قائمة دفتر الملاحظات، انتقل إلى File > Save and Checkpoint .
في حالة قيامك بالاطلاع على البرنامج التعليمي التالي في الوقت الحالية، فاحرص على ترك دفتر الملاحظات مفتوحاً. إذا لم يكن الأمر كذلك، فاحرص على إغلاق دفتر الملاحظات لتحرير موارد المجموعة، فمن شريط قائمة دفتر الملاحظات، فانتقل إلى File>Close and Halt.
تنظيف الموارد
باستخدام HDInsight، سيتم تخزين بياناتك وأجهزة Jupyter Notebooks في Azure Storage أو Azure Data Lake Storage، بحيث يمكنك حذف مجموعة في حالة عدم الاستخدام بطريقة آمنة. يتم محاسبتك أيضاً على نظام مجموعة HDInsight، حتى عندما لا تكون قيد الاستخدام. نظراً لأن رسوم نظام المجموعة تزيد عدة مرات عن رسوم التخزين، فمن المنطقي اقتصادياً حذف أنظمة المجموعات عندما لا تكون قيد الاستخدام. وقد ترغب في الاحتفاظ بالمجموعة إذا كنت تخطط للعمل على البرنامج التعليمي التالي على الفور.
افتح المجموعة في مدخل Microsoft Azure، وحدد Delete .
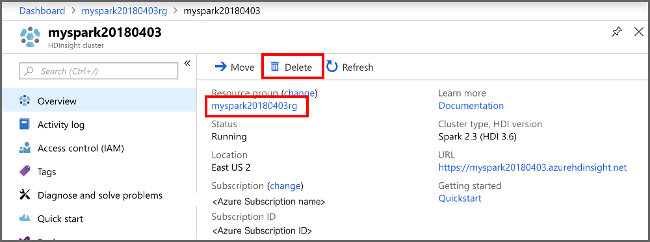
يمكنك أيضًا تحديد اسم مجموعة الموارد لفتح صفحة مجموعة الموارد، ثم حدد حذف مجموعة الموارد. وعن طريق حذف مجموعة الموارد، يمكنك حذف كل من مجموعة HDInsight Spark وحساب التخزين الافتراضي.
الخطوات التالية
تعلمت في هذا البرنامج التعليمي طريقة إنشاء إطار بيانات من ملف csv K وكذلك تشغيل استعلامات Spark SQL التفاعلية اعتماداً على مجموعة Apache Spark في Azure HDInsight. انتقل إلى المقالة التالية لمعرفة طريقة التمكن منسحب البيانات التي قمت بتسجيلها في Apache Spark في أداة تحليلات BI، مثل Power BI.