إنشاء أصول البيانات وإدارتها
ينطبق على: ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
توضح هذه المقالة كيفية إنشاء أصول البيانات وإدارتها في Azure التعلم الآلي.
يمكن أن تساعد أصول البيانات عندما تحتاج إلى هذه الإمكانات:
- تعيين الإصدار: تدعم أصول البيانات تعيين إصدار البيانات.
- إمكانية إعادة الإنتاج: بمجرد إنشاء إصدار أصل بيانات، يكون غير قابل للتغيير. لا يمكن تعديله أو حذفه. لذلك، يمكن إعادة إنتاج مهام التدريب أو المسارات التي تستهلك أصل البيانات.
- إمكانية التدقيق: نظرا لأن إصدار أصل البيانات غير قابل للتغيير، يمكنك تعقب إصدارات الأصول، ومن قام بتحديث إصدار، ومتى حدثت تحديثات الإصدار.
- دورة حياة البيانات: بالنسبة لأي أصل بيانات معين، يمكنك عرض المهام أو المسارات التي تستهلك البيانات.
- سهولة الاستخدام: يشبه أصل بيانات التعلم الآلي من Azure الإشارات المرجعية لمستعرض الويب (المفضلة). بدلا من تذكر مسارات التخزين الطويلة (URIs) التي تشير إلى بياناتك المستخدمة بشكل متكرر على Azure Storage، يمكنك إنشاء إصدار أصل بيانات ثم الوصول إلى هذا الإصدار من الأصل باسم مألوف (على سبيل المثال:
azureml:<my_data_asset_name>:<version>).
تلميح
للوصول إلى بياناتك في جلسة عمل تفاعلية (على سبيل المثال، دفتر ملاحظات) أو وظيفة، لا يطلب منك أولا إنشاء أصل بيانات. يمكنك استخدام معرفات URI لمخزن البيانات للوصول إلى البيانات. توفر عناوين URL لمخزن البيانات طريقة بسيطة للوصول إلى البيانات لأولئك الذين بدأوا في التعلم الآلي من Azure.
المتطلبات الأساسية
لإنشاء أصول البيانات والعمل باستخدامها، فأنت تحتاج إلى:
اشتراك Azure. في حال لم يكن لديك اشتراك، أنشئ حسابًا مجانيًا قبل البدء. جرّب الإصدار المجاني أو المدفوع من «التعلم الآلي» من Azure.
مساحة عمل للتعلم الآلي من Microsoft Azure. إنشاء موارد مساحة العمل.
تم تثبيت Azure التعلم الآلي CLI/SDK.
إنشاء أصول البيانات
عند إنشاء أصل البيانات الخاص بك، تحتاج إلى تعيين نوع أصل البيانات. يدعم Azure التعلم الآلي ثلاثة أنواع من أصول البيانات:
| النوع | API | سيناريوهات متعارف عليه |
|---|---|---|
| ملف الرجوع إلى ملف واحد |
uri_file |
قراءة ملف واحد على Azure Storage (يمكن أن يكون للملف أي تنسيق). |
| المجلد الرجوع إلى مجلد |
uri_folder |
اقرأ مجلد ملفات parquet/CSV في Pandas/Spark. قراءة البيانات غير المنظمة (الصور والنص والصوت وما إلى ذلك) الموجودة في مجلد. |
| الجدول الرجوع إلى جدول بيانات |
mltable |
لديك مخطط معقد يخضع للتغييرات المتكررة، أو تحتاج إلى مجموعة فرعية من البيانات الجدولية الكبيرة. AutoML مع الجداول. قراءة البيانات غير المنظمة (الصور والنص والصوت وما إلى ذلك) البيانات التي تنتشر عبر مواقع تخزين متعددة . |
إشعار
الرجاء عدم استخدام خطوط جديدة مضمنة في ملفات csv إلا إذا قمت بتسجيل البيانات ك MLTable. قد تتسبب الخطوط الجديدة المضمنة في ملفات csv في عدم محاذاة قيم الحقول عند قراءة البيانات. يحتوي MLTable على هذه المعلمة support_multi_lineفي read_delimited التحويل لتفسير فواصل الأسطر المقتبسة كسجل واحد.
عند استهلاك أصل البيانات في مهمة Azure التعلم الآلي، يمكنك إما تحميل الأصل أو تنزيله إلى عقدة (عقد) الحوسبة. لمزيد من المعلومات، يرجى قراءة الأوضاع.
أيضا، يجب تحديد معلمة path تشير إلى موقع أصل البيانات. تتضمن المسارات المدعومة ما يلي:
| Location | الأمثلة |
|---|---|
| مسار على الكمبيوتر المحلي | ./home/username/data/my_data |
| مسار على مخزن البيانات | azureml://datastores/<data_store_name>/paths/<path> |
| مسار على خادم http(s) عام | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| مسار على Azure Storage | (كائن ثنائي كبير الحجم) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
إشعار
عند إنشاء أصل بيانات من مسار محلي، سيتم تحميله تلقائيا إلى مخزن بيانات Azure التعلم الآلي السحابي الافتراضي.
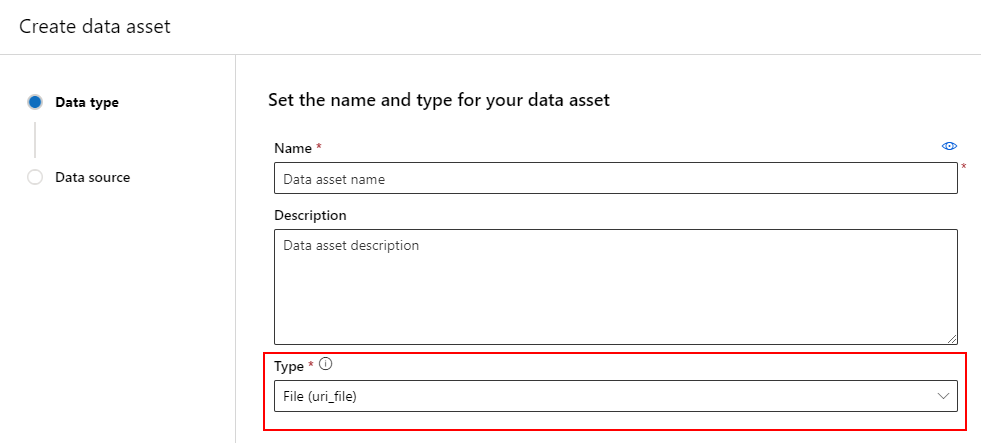
إنشاء أصل بيانات: نوع الملف
يشير أصل البيانات الذي هو نوع ملف (uri_file) إلى ملف واحد على التخزين (على سبيل المثال، ملف CSV). يمكنك إنشاء أصل بيانات مكتوب بواسطة ملف باستخدام:
إنشاء ملف YAML ونسخ ولصق التعليمات البرمجية التالية. يجب تحديث <> العناصر النائبة باسم أصل البيانات والإصدار والوصف والمسار إلى ملف واحد على موقع معتمد.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
بعد ذلك، قم بتنفيذ الأمر التالي في CLI (تحديث <filename> العنصر النائب إلى اسم ملف YAML):
az ml data create -f <filename>.yml

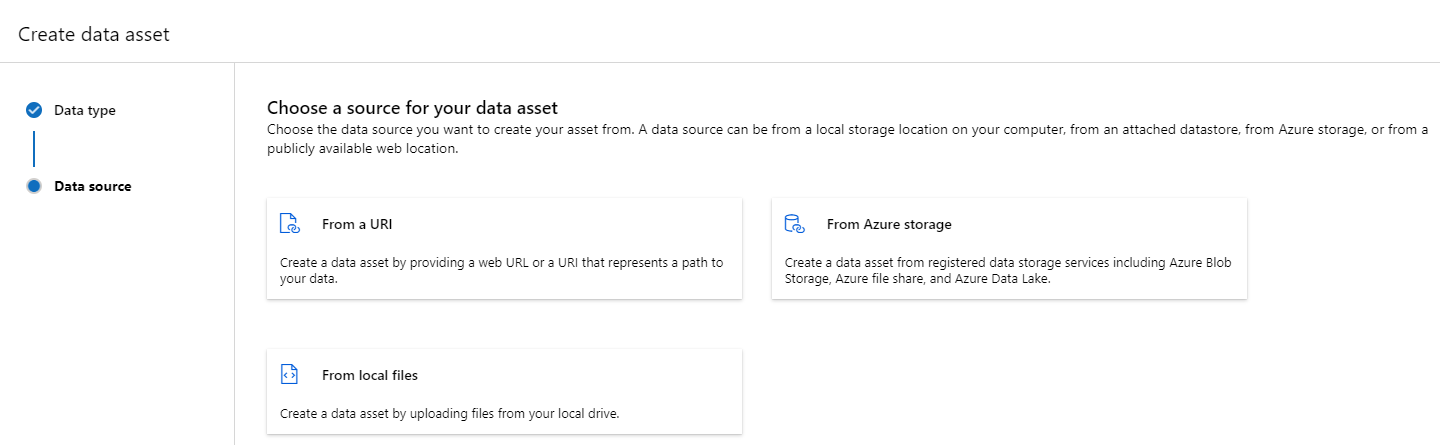
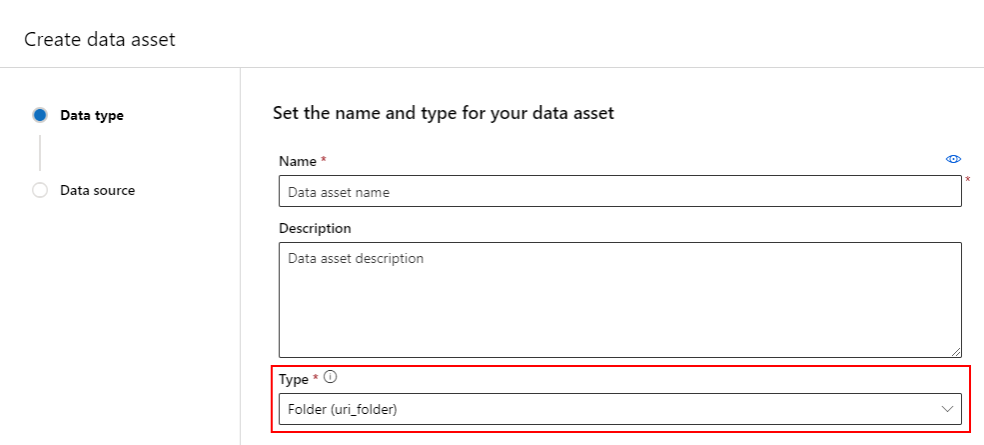
إنشاء أصل بيانات: نوع المجلد
أصل البيانات الذي هو نوع مجلد (uri_folder) هو أصل يشير إلى مجلد على التخزين (على سبيل المثال، مجلد يحتوي على عدة مجلدات فرعية من الصور). يمكنك إنشاء أصل بيانات مكتوب بواسطة مجلد باستخدام:
إنشاء ملف YAML ونسخ ولصق التعليمات البرمجية التالية. تحتاج إلى تحديث <> العناصر النائبة باسم أصل البيانات والإصدار والوصف والمسار إلى مجلد في موقع مدعوم.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
بعد ذلك، قم بتنفيذ الأمر التالي في CLI (تحديث <filename> العنصر النائب إلى اسم الملف إلى اسم ملف YAML):
az ml data create -f <filename>.yml
إنشاء أصل بيانات: نوع الجدول
تحتوي جداول Azure التعلم الآلي (MLTable) على وظائف غنية، مغطى بمزيد من التفصيل في العمل مع الجداول في Azure التعلم الآلي. بدلا من تكرار هذه الوثائق هنا، نقدم مثالا على إنشاء أصل بيانات مكتوب بالجدول، باستخدام بيانات Titanic الموجودة على حساب Azure Blob Storage المتاح للجمهور.
أولا، إنشاء دليل جديد يسمى البيانات، وإنشاء ملف يسمى MLTable:
mkdir data
touch MLTable
بعد ذلك، انسخ والصق YAML التالي في ملف MLTable الذي أنشأته في الخطوة السابقة:
تنبيه
لا تقم بإعادة MLTable تسمية الملف إلى MLTable.yaml أو MLTable.yml. يتوقع التعلم الآلي من Azure وجود MLTable ملف.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
بعد ذلك، قم بتنفيذ الأمر التالي في CLI. تأكد من تحديث العناصر النائبة <> باسم أصل البيانات وقيم الإصدار.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
هام
path يجب أن يكون مجلدايحتوي على ملف صالحMLTable.
إنشاء أصول البيانات من مخرجات الوظائف
يمكنك إنشاء أصل بيانات من مهمة Azure التعلم الآلي عن طريق تعيين المعلمة name في الإخراج. في هذا المثال، يمكنك إرسال مهمة تنسخ البيانات من مخزن كائن ثنائي كبير الحجم عام إلى Azure الافتراضي التعلم الآلي Datastore وتنشئ أصل بيانات يسمى job_output_titanic_asset.
إنشاء ملف YAML لمواصفات الوظيفة (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: azureml:wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
بعد ذلك، أرسل المهمة باستخدام CLI:
az ml job create --file <file-name>.yml
قم بإدارة أصول البيانات
حذف أصل بيانات
هام
حسب التصميم، لا يتم دعم حذف أصول البيانات.
إذا سمح التعلم الآلي من Azure بحذف أصول البيانات، فسيكون له التأثيرات السلبية التالية:
- ستفشل مهام الإنتاج التي تستهلك أصول البيانات التي تم حذفها لاحقا.
- سيصبح من الصعب إعادة إنتاج تجربة التعلم الآلي.
- قد تنقطع دورة حياة الوظيفة، لأنه سيصبح من المستحيل عرض إصدار أصل البيانات المحذوف.
- لن تتمكن من التتبع والتدقيق بشكل صحيح، نظرا لأن الإصدارات قد تكون مفقودة.
لذلك، يوفر عدم قابلية تغيير أصول البيانات مستوى من الحماية عند العمل في فريق يقوم بإنشاء أحمال عمل الإنتاج.
عندما يتم إنشاء أصل بيانات عن طريق الخطأ - على سبيل المثال، باسم أو نوع أو مسار غير صحيح - يقدم Azure التعلم الآلي حلولا للتعامل مع الموقف دون العواقب السلبية للحذف:
| أريد حذف أصل البيانات هذا لأن... | الحل |
|---|---|
| الاسم غير صحيح | أرشفة أصل البيانات |
| لم يعد الفريق يستخدم أصل البيانات | أرشفة أصل البيانات |
| إنها تشوش قائمة أصول البيانات | أرشفة أصل البيانات |
| المسار غير صحيح | إنشاء إصدار جديد من أصل البيانات (نفس الاسم) بالمسار الصحيح. لمزيد من المعلومات، اقرأ إنشاء أصول البيانات. |
| له نوع غير صحيح | حاليا، لا يسمح Azure التعلم الآلي بإنشاء إصدار جديد بنوع مختلف مقارنة بالإصدار الأولي. (1) أرشفة أصل البيانات (2) إنشاء أصل بيانات جديد باسم مختلف بالنوع الصحيح. |
أرشفة أصل بيانات
تقوم أرشفة أصل بيانات بإخفائه افتراضيا من استعلامات القائمة (على سبيل المثال، في CLI az ml data list) وإدراج أصول البيانات في واجهة مستخدم Studio. لا يزال بإمكانك الاستمرار في الرجوع إلى أصل بيانات مؤرشف واستخدامه في مهام سير العمل. يمكنك أرشفة إما:
- جميع إصدارات أصل البيانات تحت اسم معين، أو
- إصدار أصل بيانات محدد
أرشفة جميع إصدارات أصل البيانات
لأرشفة جميع إصدارات أصل البيانات تحت اسم معين، استخدم:
تنفيذ الأمر التالي (تحديث <> العنصر النائب باسم أصل البيانات):
az ml data archive --name <NAME OF DATA ASSET>

أرشفة إصدار أصل بيانات محدد
لأرشفة إصدار أصل بيانات معين، استخدم:
تنفيذ الأمر التالي (تحديث <> العناصر النائبة باسم أصل البيانات والإصدار):
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
استعادة أصل بيانات مؤرشف
يمكنك استعادة أصل بيانات مؤرشف. إذا تم أرشفة جميع إصدارات أصل البيانات، فلا يمكنك استعادة الإصدارات الفردية من أصل البيانات - يجب استعادة جميع الإصدارات.
استعادة جميع إصدارات أصل البيانات
لاستعادة جميع إصدارات أصل البيانات تحت اسم معين، استخدم:
تنفيذ الأمر التالي (تحديث <> العنصر النائب باسم أصل البيانات):
az ml data restore --name <NAME OF DATA ASSET>


استعادة إصدار أصل بيانات محدد
هام
إذا تم أرشفة جميع إصدارات أصول البيانات، فلا يمكنك استعادة إصدارات فردية من أصل البيانات - يجب استعادة جميع الإصدارات.
لاستعادة إصدار أصل بيانات معين، استخدم:
تنفيذ الأمر التالي (تحديث <> العناصر النائبة باسم أصل البيانات والإصدار):
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
دورة حياة البيانات
يتم فهم دورة حياة البيانات على نطاق واسع على أنها دورة الحياة التي تمتد عبر أصل البيانات، وحيث تنتقل بمرور الوقت عبر التخزين. تستخدمه أنواع مختلفة من السيناريوهات ذات المظهر الخلفي، على سبيل المثال استكشاف الأخطاء وإصلاحها، وتتبع الأسباب الجذرية في مسارات التعلم الآلي، وتصحيح الأخطاء. كما تستخدم سيناريوهات تحليل جودة البيانات والامتثال و"ماذا لو" دورة حياة البيانات. يتم تمثيل دورة حياة البيانات بشكل مرئي لإظهار نقل البيانات من المصدر إلى الوجهة، بالإضافة إلى تغطية تحويلات البيانات. نظرا لتعقيد معظم بيئات بيانات المؤسسة، يمكن أن تصبح طرق العرض هذه صعبة الفهم دون دمج أو إخفاء نقاط البيانات الطرفية.
في Azure التعلم الآلي Pipeline، تظهر أصول البيانات أصل البيانات وكيفية معالجة البيانات، على سبيل المثال:
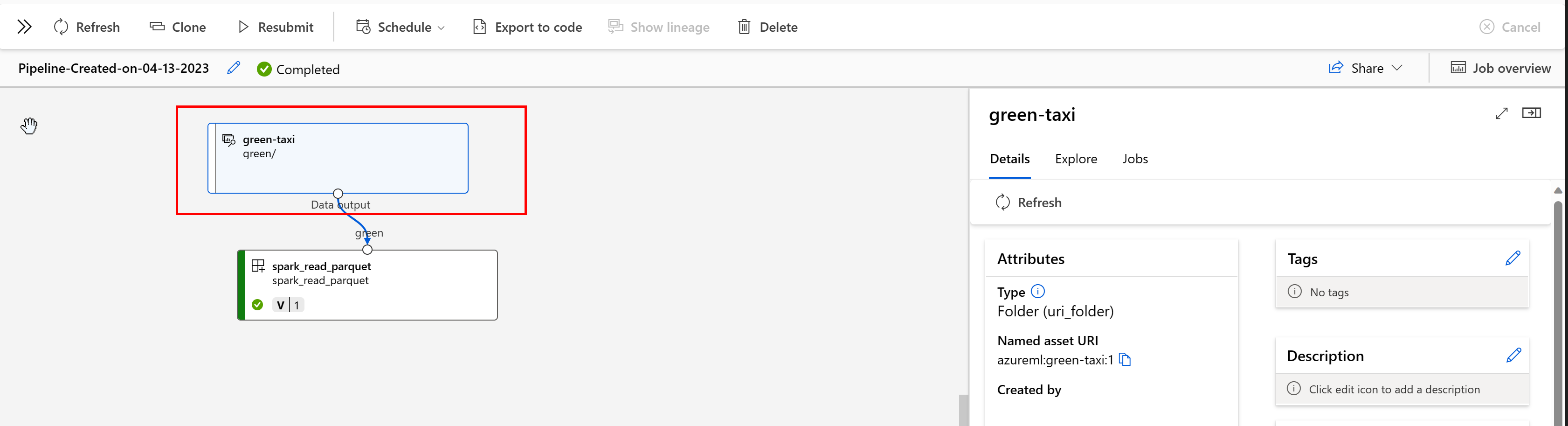
يمكنك عرض المهام التي تستهلك أصل البيانات في واجهة مستخدم Studio. أولا، حدد البيانات من القائمة اليسرى، ثم حدد اسم أصل البيانات. يمكنك مشاهدة المهام التي تستهلك أصل البيانات:

تسهل طريقة عرض الوظائف في أصول البيانات العثور على حالات فشل الوظيفة والقيام بتحليل سبب المسار في مسارات التعلم الآلي وتصحيح الأخطاء.
وضع علامات على أصول البيانات
تدعم أصول البيانات وضع العلامات، وهي بيانات تعريف إضافية يتم تطبيقها على أصل البيانات في شكل زوج قيم المفاتيح. يوفر وضع علامات على البيانات العديد من الفوائد:
- وصف جودة البيانات. على سبيل المثال، إذا كانت مؤسستك تستخدم بنية مستودع ميدالية، يمكنك وضع علامة على الأصول باستخدام
medallion:bronze(raw)medallion:silverو(تم التحقق من صحتها) وmedallion:gold(تم إثراؤها). - يوفر البحث الفعال وتصفية البيانات، للمساعدة في اكتشاف البيانات.
- يساعد على تحديد البيانات الشخصية الحساسة، لإدارة الوصول إلى البيانات والتحكم فيها بشكل صحيح. على سبيل المثال،
sensitivity:PII/sensitivity:nonPII. - تحديد ما إذا كانت البيانات معتمدة من تدقيق الذكاء الاصطناعي مسؤول (RAI). على سبيل المثال،
RAI_audit:approved/RAI_audit:todo.
يمكنك إضافة علامات إلى أصول البيانات كجزء من تدفق إنشائها، أو يمكنك إضافة علامات إلى أصول البيانات الموجودة. يعرض هذا القسم كليهما.
إضافة علامات كجزء من تدفق إنشاء أصول البيانات
إنشاء ملف YAML، ونسخ ولصق التعليمات البرمجية التالية. يجب تحديث <> العناصر النائبة باسم أصل البيانات والإصدار والوصف والعلامات (أزواج قيم المفاتيح) والمسار إلى ملف واحد على موقع معتمد.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
بعد ذلك، قم بتنفيذ الأمر التالي في CLI (تحديث <filename> العنصر النائب إلى اسم ملف YAML):
az ml data create -f <filename>.yml
إضافة علامات إلى أصل بيانات موجود
نفذ الأمر التالي في Azure CLI، وقم بتحديث <> العناصر النائبة باسم أصل البيانات والإصدار وزوج قيمة المفتاح للعلامة.
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

أفضل ممارسات تعيين الإصدار
عادة ما تنظم عمليات ETL بنية المجلد على تخزين Azure حسب الوقت، على سبيل المثال:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
يسمح لك الجمع بين المجلدات المنظمة للوقت/الإصدار وجداول Azure التعلم الآلي (MLTable) بإنشاء مجموعات بيانات تم إصدارها. لإظهار كيفية تحقيق البيانات التي تم إصدارها باستخدام Azure التعلم الآلي Tables، نستخدم مثالا افتراضيا. لنفترض أن لديك عملية تقوم بتحميل صور الكاميرا إلى تخزين Azure Blob كل أسبوع، في البنية التالية:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
إشعار
بينما نوضح كيفية إصدار بيانات الصورة (jpeg)، يمكن تطبيق نفس المنهجية على أي نوع ملف (على سبيل المثال، Parquet، CSV).
باستخدام Azure التعلم الآلي Tables (mltable)، يمكنك إنشاء جدول المسارات التي تتضمن البيانات حتى نهاية الأسبوع الأول من عام 2023، ثم إنشاء أصل بيانات:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
في نهاية الأسبوع التالي، قامت ETL بتحديث البيانات لتضمين المزيد من البيانات:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
يستمر الإصدار الأول (20230108) في تحميل/تنزيل الملفات فقط من year=2022/week=52 ولأن year=2023/week=1 المسارات معلنة في MLTable الملف. وهذا يضمن إمكانية إعادة إنتاج تجاربك. لإنشاء إصدار جديد من أصل البيانات الذي يتضمن year=2023/week2، يمكنك استخدام:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
لديك الآن إصداران من البيانات، حيث يتوافق اسم الإصدار مع تاريخ تحميل الصور إلى التخزين:
- 20230108: الصور حتى 2023-يناير-08.
- 20230115: الصور حتى 2023-يناير-15.
في كلتا الحالتين، يقوم MLTable بإنشاء جدول مسارات يتضمن فقط الصور حتى تلك التواريخ.
في مهمة Azure التعلم الآلي يمكنك تحميل أو تنزيل هذه المسارات في MLTable الذي تم إصداره إلى هدف الحساب الخاص بك باستخدام الأوضاع eval_download أوeval_mount:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
إشعار
الأوضاع eval_mount و eval_download فريدة من نوعها ل MLTable. في هذه الحالة، تقوم إمكانية وقت تشغيل بيانات AzureML بتقييم MLTable الملف وإدخال المسارات على هدف الحساب.