ضبط المعلمة الفائقة لنموذج (v2)
ينطبق على: ملحق التعلم الآلي من Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق التعلم الآلي من Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
أتمتة ضبط المعلمة الفائقة الفعال باستخدام Azure التعلم الآلي SDK v2 وCLI v2 عن طريق نوع SweepJob.
- تحديد مساحة بحث المعلمة للإصدار التجريبي الخاص بك
- تحديد خوارزمية أخذ العينات لمهمة المسح الخاصة بك
- تحديد الهدف لتحسينه
- تحديد نهج الإنهاء المبكر للوظائف منخفضة الأداء
- تحديد حدود مهمة المسح
- بدء تجربة مع التكوين المحدد
- تصور مهام التدريب
- تحديد أفضل تكوين لنموذجك
ما المقصود بضبط المعلمة الفائقة؟
مقاييس المعلمة الفائقة هي معلمات قابلة للتعديل تتيح لك التحكم في عملية تدريب الطراز. على سبيل المثال، باستخدام الشبكات العصبية، يمكنك تحديد عدد الطبقات المخفية وعدد العقد في كل طبقة. يعتمد أداء النموذج بشكل كبير على المعلمة الفائقة.
ضبط فرطبارامتر، وتسمى أيضا التحسين المعلمة الفائقة، هو عملية العثور على تكوين الإفراط في عدادات النتائج في أفضل أداء. عادة ما تكون العملية مكلفة من الناحية المادية، وكذلك يدوية.
يتيح لك التعلم الآلي من Microsoft Azure أتمتة ضبط المعلمة الفائقة وتشغيل التجارب بالتوازي لتحسين مكافآت الفصائل.
تحديد المساحة المخصصة للبحث
قم بضبط المعلمات الفائقة عن طريق استكشاف نطاق القيم المحددة لكل المعلمة الفائقة.
يمكن أن تكون المعلمات الفائقة منفصلة أو مستمرة، ولها توزيع للقيم الموصوفة بواسطة تعبير المعلمة .
المعلمات الفائقة المنفصلة
تم تحديد Hypermeter المنفصلة كـ Choice بين القيم المنفصلة. Choice يمكن أن يكون:
- قيمة واحدة أو أكثر مفصولة بفاصلة
- كائن
range - أي كائن تعسفي
list
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
في هذه الحالة، batch_size واحدة من القيم [16، 32، 64، 128] و number_of_hidden_layers يأخذ واحدة من القيم [1، 2، 3، 4].
يمكن أيضًا تحديد Hypermeter المتقدمة التالية باستخدام التوزيع:
QUniform(min_value, max_value, q)- إرجاع قيمة مثل الجولة (موحد (min_value، max_value) / q) * qQLogUniform(min_value, max_value, q)- إرجاع قيمة مثل الجولة (exp (min_value، max_value)) / q) * qQNormal(mu, sigma, q)- إرجاع قيمة مثل round (عادي (mu، sigma) / q) * qQLogNormal(mu, sigma, q)- إرجاع قيمة مثل round (exp (Normal (mu، sigma)) / q) * q
المعلمات الفائقة المستمرة
يتم تحديد Hypermeter المستمرة كتوزيع على نطاق مستمر من القيم:
Uniform(min_value, max_value)- إرجاع قيمة موزعة بشكل موحد بين min_value و max_valueLogUniform(min_value, max_value)- إرجاع قيمة مرسومة وفقًا لـ EXP (موحد (min_value، max_value)) بحيث يتم توزيع اللوغاريتم على قيمة الإرجاع بشكل موحدNormal(mu, sigma)- إرجاع قيمة حقيقية يتم توزيعها عادةً مع متوسط MU و Signal SigmaLogNormal(mu, sigma)- إرجاع قيمة مرسومة وفقًا لـ EXP (عادي (MU، Sigma)) بحيث يتم توزيع اللوغاريتم على قيمة الإرجاع عادة
مثال على تعريف مساحة المعلمة:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
يحدد هذا الرمز مساحة بحث مع معلمتين - learning_rate و keep_probability. learning_rate لديه توزيع طبيعي مع متوسط القيمة 10 والانحراف المعياري 3. keep_probability لديه توزيع موحد بقيمة لا تقل عن 0.05 وقيمة أقصى قدرها 0.1.
بالنسبة إلى CLI، يمكنك استخدام مخطط YAML لمهمة المسح، لتحديد مساحة البحث في YAML الخاص بك:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
أخذ عينات من مساحة الفائقة
حدد طريقة أخذ عينات المعلمة لاستخدامها فوق مساحة المعلمة الفائقة. يدعم التعلم الآلي من Microsoft Azure الطرق التالية:
- أخذ العينات عشوائيًا
- أخذ العينات الشبكي
- أخذ العينات البايزياني
أخذ العينات عشوائيًا
يدعم أخذ العينات العشوائية Hypermeter المنفصلة والمستمرة. يقوم بعض المستخدمين بالبحث الأولي بأخذ عينات عشوائية ثم صقل مساحة البحث لتحسين النتائج. يقوم بعض المستخدمين بإجراء بحث أولي باستخدام عينات عشوائية ثم تحسين مساحة البحث لتحسين النتائج.
في أخذ العينات العشوائية، يتم تحديد قيم المعلمات الفائقة عشوائيًا من مساحة البحث المحددة. بعد تكوين مهمة الأمر، يمكنك استخدام معامل المسح لتعريف خوارزمية أخذ العينات.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol هو نوع من أخذ العينات العشوائية التي تدعمها أنواع مهام المسح. يمكنك استخدام sobol لإعادة إنتاج نتائجك باستخدام البذور وتغطية توزيع مساحة البحث بشكل متساوٍ.
لاستخدام sobol، استخدم فئة RandomParameterSampling لإضافة البذرة والقاعدة كما هو موضح في المثال أدناه.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
أخذ العينات الشبكي
يدعم أخذ العينات عبر الشبكة Hypermeter المنفصلة. استخدم أخذ العينات من الشبكة إذا كان بإمكانك وضع ميزانية للبحث الشامل في مساحة البحث. يدعم الإنهاء المبكر للوظائف منخفضة الأداء.
يقوم أخذ العينات الشبكية ببحث بسيط في الشبكة عبر جميع القيم الممكنة. لا يمكن استخدام أخذ العينات على شكل شبكة إلا مع choice معلمات تشعبية. على سبيل المثال، المساحة التالية بها ست عينات:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
أخذ العينات البايزياني
يعتمد أخذ العينات بايزي على خوارزمية التحسين البايزية. إنه يختار العينات بناءً على كيفية عمل العينات السابقة، بحيث تعمل العينات الجديدة على تحسين المقياس الأساسي.
يوصى بأخذ عينات بايز إذا كان لديك ميزانية كافية لاستكشاف مساحة المعامل الفائق. للحصول على أفضل النتائج، نوصي بحد أقصى لعدد الوظائف أكبر من أو يساوي 20 ضعف عدد المعلمات الفائقة التي يتم ضبطها.
عدد الوظائف المتزامنة له تأثير على فعالية عملية الضبط. قد يؤدي عدد أقل من الوظائف المتزامنة إلى تقارب أفضل للعينات، نظرًا لأن الدرجة الأصغر من التوازي تزيد من عدد الوظائف التي تستفيد من الوظائف المكتملة سابقًا.
لا يدعم أخذ العينات بايزي سوى التوزيعات choice و uniform و quniform عبر مساحة البحث.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
تحديد هدف المسح
حدد الهدف من مهمة المسح الخاصة بك عن طريق تحديد المقياس الأساسي و الهدف الذي تريد ضبط المعلمة الفائقة لتحسينه. يتم تقييم كل وظيفة تدريبية للمقياس الأساسي. تستخدم نهج الإنهاء المبكر المقياس الأساسي لتحديد الوظائف منخفضة الأداء.
primary_metric: يجب أن يتطابق اسم المقياس الأساسي تمامًا مع اسم المقياس المسجل بواسطة البرنامج النصي للتدريبgoal: يمكن أن يكون إماMaximizeأوMinimizeويحدد ما إذا كان المقياس الأساسي سيتم تكبيره أم تصغيره عند تقييم الوظائف.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
تحدد هذه القيمة الحد الأقصى من "الدقة".
مقاييس السجل لضبط المعلمة الفائقة
يجب أن يقوم البرنامج النصي للتدريب للنموذج الخاص بك بتسجيل المقياس الأساسي أثناء تدريب النموذج باستخدام نفس اسم المقياس المقابل بحيث يمكن لـ SweepJob الوصول إليه لضبط المعلمة الفائقة.
قم بتسجيل المقياس الأساسي في البرنامج النصي التدريبي الخاص بك باستخدام المقتطف النموذجي التالي:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
يحسب البرنامج النصي للتدريب val_accuracy ويسجله باعتباره "دقة" المقياس الأساسي. في كل مرة يتم فيها تسجيل المقياس، يتم استلامه بواسطة خدمة ضبط المعلمات الفائقة. الأمر متروك لك لتحديد مدى تكرار التقارير.
لمزيد من المعلومات حول قيم التسجيل لوظائف التدريب، راجع تمكين التسجيل في وظائف التدريب على التعلم الآلي من Microsoft Azure.
حدد سياسة الإنهاء المبكر
قم بإنهاء الوظائف ذات الأداء الضعيف تلقائيًا بسياسة الإنهاء المبكر. الإنهاء المبكر يحسن الكفاءة الحسابية.
يمكنك تكوين المعلمات التالية التي تتحكم في وقت تطبيق السياسة:
evaluation_interval: معدل تطبيق النهج. في كل مرة يسجل فيها البرنامج النصي للتدريب، يتم احتساب المقياس الأساسي كفاصل زمني واحد. سيتم تطبيقevaluation_intervalمن 1 النهج في كل مرة يُبلغ فيها البرنامج النصي للتدريب عن المقياس الأساسي. سيتم تطبيقevaluation_intervalمن 2 النهج في كل مرة. إذا لم يتم تحديده، يتم تعيينevaluation_intervalعلى 0 افتراضيًا.delay_evaluation: يؤخر أول تقييم للنهج لعدد محدد من الفواصل الزمنية. هذه معلمة اختيارية تتجنب الإنهاء المبكر لوظائف التدريب من خلال السماح بتشغيل جميع التكوينات لأقل عدد من الفواصل الزمنية. إذا تم تحديد ذلك، فإن النهج تطبق كل مضاعف لفترات التقييم التي تزيد عن أو تساوي التأخير في التقييم. إذا لم يتم تحديده، يتم تعيينdelay_evaluationعلى 0 افتراضيًا.
يدعم التعلم الآلي من Microsoft Azure نهج الإنهاء المبكر التالية:
نهج السارق المقنع
تستند سياسة ماكينة الحظ إلى عامل الركود / مقدار فترة الركود وفترة التقييم. تنهي سياسة ماكينة الحظ وظيفة عندما لا يكون المقياس الأساسي ضمن عامل فترة السماح المحدد / مقدار الركود للوظيفة الأكثر نجاحًا.
حدد معلمات التكوين على النحو المذكور أدناه:
slack_factorأوslack_amount: فترة السماح فيما يتعلق بأفضل أداء لتطبيق وظيفة التدريب.slack_factorتحديد فترة السماح باعتبارها نسبة.slack_amountتحديد فترة السماح باعتبارها مقدار مطلق، بدلا من نسبة.على سبيل المثال، راعِ نهج قطاع الطرق المطبق في الفاصل الزمني 10. افترض أن الوظيفة الأفضل أداءً في الفترة 10 التي أبلغت عن مقياس أساسي هي 0.8 بهدف تعظيم المقياس الأساسي. إذا حددت السياسة
slack_factorمن 0.2، فسيتم إنهاء أي وظائف تدريبية يكون أفضل مقياس لها في الفاصل 10 أقل من 0.66 (0.8 / (1+slack_factor)).evaluation_interval: (اختياري) تكرار تطبيق النهجdelay_evaluation: (اختياري) يؤخر تقييم النهج الأول لعدد محدد من الفواصل الزمنية
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
في هذا المثال، يتم تطبيق نهج الإنهاء المبكر في كل فاصل زمني عند الإبلاغ عن المقاييس، بدءا من الفاصل الزمني للتقييم 5. سيتم إنهاء أي وظائف يكون أفضل مقياس لها أقل من (1 / (1 + 0.1) أو 91٪ من أفضل الوظائف أداءً.
نهج توقف الوسط
الإيقاف الوسيط عبارة عن نهج إنهاء مبكر تستند إلى متوسطات التشغيل للمقاييس الأساسية التي تم الإبلاغ عنها بواسطة الوظائف. يحسب هذا النهج متوسطات التشغيل عبر جميع وظائف التدريب ويوقف الوظائف التي تكون قيمتها القياسية الأساسية أسوأ من متوسط المتوسطات.
يأخذ هذا النهج معلمات التكوين التالية:
evaluation_intervalتكرار تطبيق النهج (معلمة اختيارية).delay_evaluationتأخير تقييم النهج الأول لعدد محدد من الفواصل الزمنية (معلمة اختيارية).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
في هذا المثال، يتم تطبيق نهج الإنهاء المبكر في كل فاصل زمني بدءا من الفاصل الزمني للتقييم 5. يتم إيقاف الوظيفة في الفاصل الزمني 5 إذا كان أفضل مقياس أساسي لها أسوأ من متوسط المتوسطات الجارية عبر فواصل زمنية 1:5 عبر جميع وظائف التدريب.
نهج التحديد الاقتطاعي
يؤدي تحديد الاقتطاع إلى إلغاء نسبة مئوية من أقل المهام أداء في كل فاصل زمني للتقييم. تتم مقارنة الوظائف باستخدام المقياس الأساسي.
يأخذ هذا النهج معلمات التكوين التالية:
truncation_percentage: النسبة المئوية للوظائف الأقل أداء للإنهاء في كل فاصل زمني للتقييم. قيمة عدد صحيح بين 1 و 99.evaluation_interval: (اختياري) تكرار تطبيق النهجdelay_evaluation: (اختياري) يؤخر تقييم النهج الأول لعدد محدد من الفواصل الزمنيةexclude_finished_jobs: يحدد ما إذا كان سيتم استبعاد المهام النهائية عند تطبيق النهج
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
في هذا المثال، يتم تطبيق نهج الإنهاء المبكر في كل فاصل زمني بدءا من الفاصل الزمني للتقييم 5. تنتهي الوظيفة عند الفاصل 5 إذا كان أداؤها في الفترة 5 في أدنى 20٪ من أداء جميع الوظائف في الفاصل 5 وستستبعد الوظائف المنتهية عند تطبيق السياسة.
لا يوجد نهج إنهاء (افتراضي)
إذا لم يتم تحديد نهج، فإن خدمة ضبط المعلمات الفائقة ستسمح بتنفيذ جميع مهام التدريب حتى الاكتمال.
sweep_job.early_termination = None
اختيار نهج الإنهاء المبكر
- بالنسبة للنهج المحافظة التي توفر المدخرات دون إنهاء الوظائف الواعدة، فكر في نهج وقف متوسطة مع
evaluation_interval1 وdelay_evaluation5. هذه هي الإعدادات المحافظة التي يمكن أن توفر ما يقرب من 25٪-35٪ من المدخرات دون أي خسارة على المقياس الأساسي (استنادا إلى بيانات التقييم الخاصة بنا). - للحصول على التوفير أكثر عدوانية، استخدم "نهج قطاع الطرق" مع فترة سماح أصغر المسموح بها أو "نهج تحديد اقتطاع" مع نسبة اقتطاع أكبر.
تعيين حدود لمهمة المسح خاصتك
تحكم في ميزانية الموارد الخاصة بك عن طريق تعيين حدود لوظيفة المسح الخاصة بك.
max_total_trials: الحد الأقصى لعدد المهام التجريبية. يجب أن يكون عدد صحيح بين 1 و 1000.max_concurrent_trials: (اختياري) الحد الأقصى لعدد المهام التجريبية التي يمكن تشغيلها بشكل متزامن. إذا لم يتم تحديده، max_total_trials عدد الوظائف التي يتم تشغيلها بالتوازي. إذا تم تحديده، يجب أن يكون عددا صحيحا بين 1 و1000.timeout: الحد الأقصى للوقت بالثوان المسموح بتشغيل مهمة المسح بأكملها. وبمجرد الوصول إلى هذا الحد، سيقوم النظام بإلغاء مهمة المسح، بما في ذلك جميع إصداراته التجريبية.trial_timeout: الحد الأقصى للوقت بالثواني المسموح بتشغيل كل مهمة تجريبية. وبمجرد الوصول إلى هذا الحد، سيقوم النظام بإلغاء الإصدار التجريبي.
ملاحظة
إذا تم تحديد كل من max_total_trials والمهلة، تنتهي تجربة ضبط المعلمة الفائقة عند الوصول إلى أول هذين الحدين.
ملاحظة
يتم تحديد عدد الوظائف التجريبية المتزامنة على الموارد المتاحة في هدف الحوسبة المحدد. تأكد من أن الهدف الحسابي لديه الموارد المتاحة للتزامن المطلوب.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
تقوم هذه التعليمة البرمجية بتكوين تجربة ضبط المعلمات الفائقة لاستخدام 20 وظيفة تجريبية إجمالية كحد أقصى، وتشغيل أربع مهام تجريبية في كل مرة مع مهلة 1200 ثانية لوظيفة المسح بأكملها.
تكوين تجربة ضبط المعلمة الفائقة
من أجل تهيئة تجربة ضبط المعلمات الفائقة، قم بتوفير ما يلي:
- مساحة البحث عن المعلمات الفائقة المحددة
- خوارزمية أخذ العينات
- نهج الإنهاء المبكر
- هدفك
- حدود الموارد
- مهمة القيادة أو مكونها
- مهمة المسح
يمكن أن يقوم SweepJob بتشغيل عملية مسح للمعلمات الفائقة في الأمر أو مكون الأمر.
ملاحظة
يجب أن يحتوي هدف الحساب المستخدم في sweep_job على موارد كافية لتلبية مستوى التزامن الخاص بك. لمزيد من المعلومات حول حساب الأهداف، راجع حساب الأهداف .
قم بتكوين تجربة ضبط المعلمة الفائقة الخاصة بك:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
يتم استدعاء command_job كدالة حتى نتمكن من تطبيق تعبيرات المعامل على مدخلات المسح. يتم تكوين الوظيفة sweep بعد ذلك باستخدام trial و sampling-algorithm و objective و limits و compute. يتم أخذ مقتطف التعليمات البرمجية أعلاه من نموذج دفتر الملاحظات تشغيل مسح المعلمة الفائقة على Command أو CommandComponent. في هذا النموذج، سيتم ضبط المعلمات learning_rate و boosting. سيتم تحديد الإيقاف المبكر للوظائف من خلال MedianStoppingPolicy، والتي توقف وظيفة تكون قيمتها المقياس الأساسي أسوأ من متوسط المتوسطات عبر جميع وظائف التدريب. (راجع مرجع فئة MedianStoppingPolicy ).
لمعرفة كيفية تلقي قيم المعلمات وتحليلها وتمريرها إلى البرنامج النصي للتدريب لضبطها، ارجع إلى نموذج التعليمات البرمجية هذا
هام
تؤدي كل مهمة مسح للمعلمات الفائقة إلى إعادة التدريب من البداية، بما في ذلك إعادة بناء النموذج و جميع برامج تحميل البيانات . يمكنك تقليل هذه التكلفة إلى الحد الأدنى باستخدام البنية الأساسية لبرنامج ربط العمليات التجارية للتعلم الآلي من Microsoft Azure أو عملية يدوية للقيام بأكبر قدر ممكن من إعداد البيانات قبل مهام التدريب الخاصة بك.
إرسال تجربة ضبط المعلمة الفائقة
بعد تحديد تكوين ضبط المعلمة الفائقة، أرسل الوظيفة:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
تصور وظائف ضبط المعامل الفائق
يمكنك تصور جميع وظائف ضبط المعلمات الفائقة في استوديو التعلم الآلي من Microsoft Azure . لمزيد من المعلومات حول كيفية عرض تجربة في البوابة، راجع عرض سجلات الوظائف في الاستوديو .
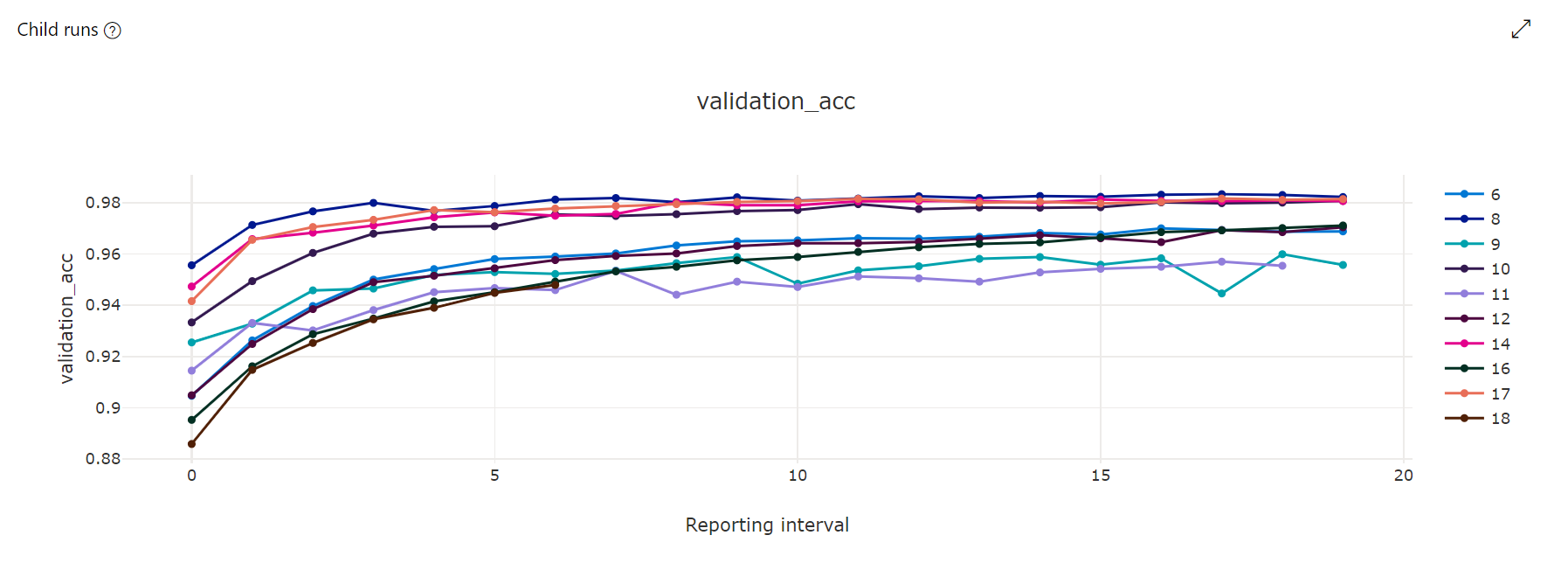
مخطط المقاييس : يتتبع هذا التمثيل البصري المقاييس التي تم تسجيلها لكل وظيفة فرعية من hyperdrive خلال مدة ضبط المعلمة الفائقة. يمثل كل سطر وظيفة فرعية، وتقيس كل نقطة قيمة المقياس الأساسية في ذلك التكرار لوقت التشغيل.
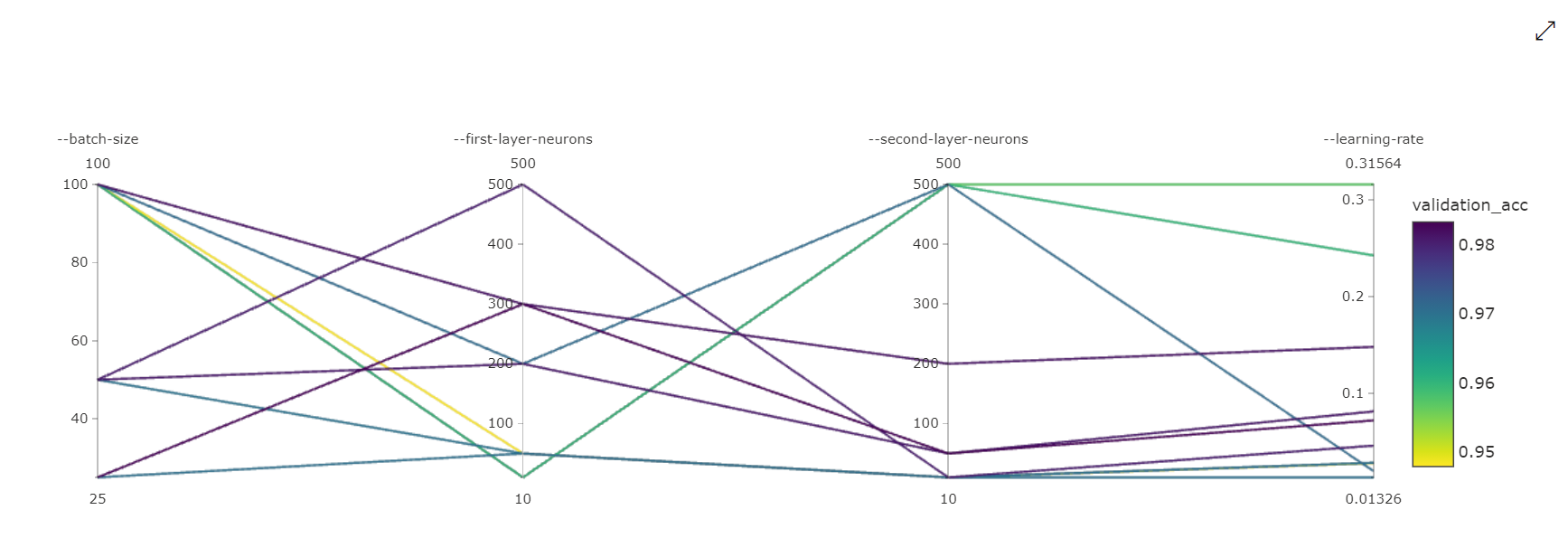
مخطط الإحداثيات المتوازية : يوضح هذا التمثيل المرئي الارتباط بين أداء المقياس الأساسي وقيم المعلمات الفائقة الفردية. يكون المخطط تفاعليًا عبر حركة المحاور (انقر واسحب بواسطة تسمية المحور)، وبتمييز القيم عبر محور واحد (انقر واسحب عموديًا على طول محور واحد لتمييز نطاق من القيم المطلوبة). يتضمن مخطط الإحداثيات المتوازية محورا في الجزء الموجود في أقصى اليمين من المخطط الذي يرسم أفضل قيمة قياس مطابقة للمثيلات الفائقة المعينة لمثيل الوظيفة هذا. يتم توفير هذا المحور من أجل عرض وسيلة إيضاح التدرج اللوني للمخطط على البيانات بطريقة أكثر قابلية للقراءة.
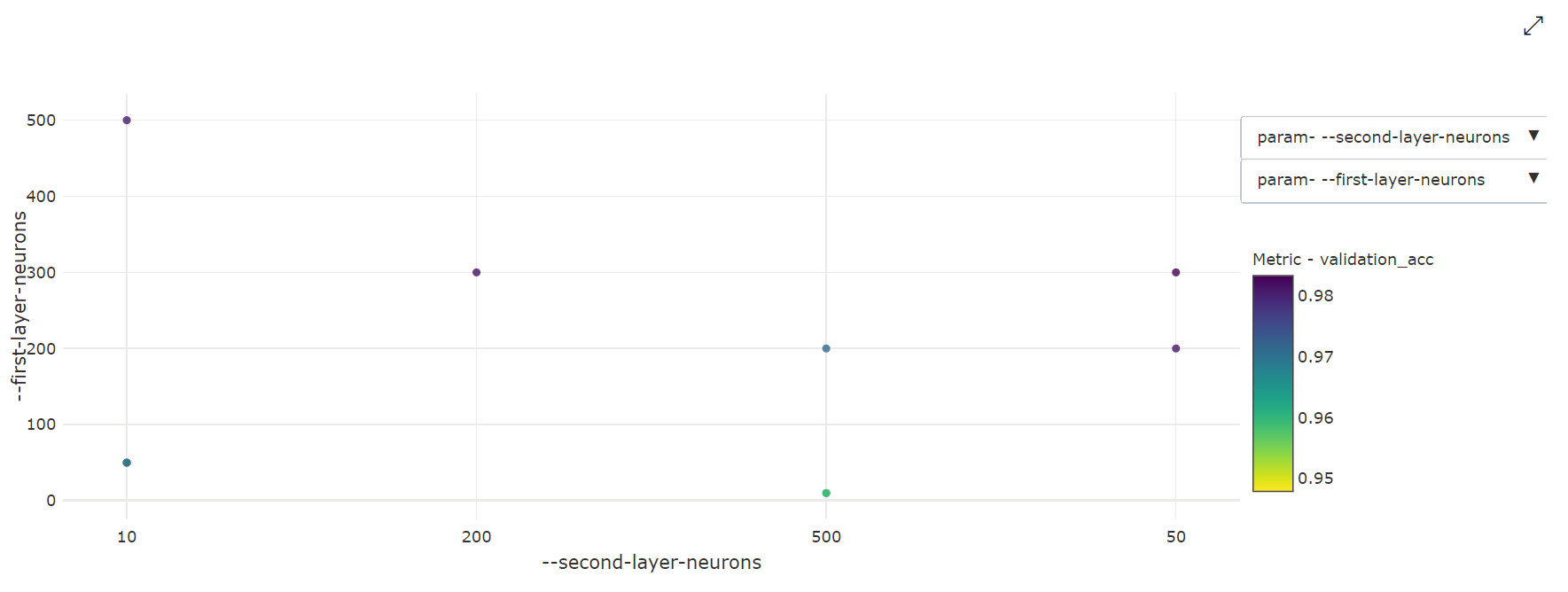
مخطط مبعثر ثنائي الأبعاد : يوضح هذا التمثيل المرئي الارتباط بين أي معلمتين فرديتين مع القيمة المترية الأساسية المرتبطة بهما.
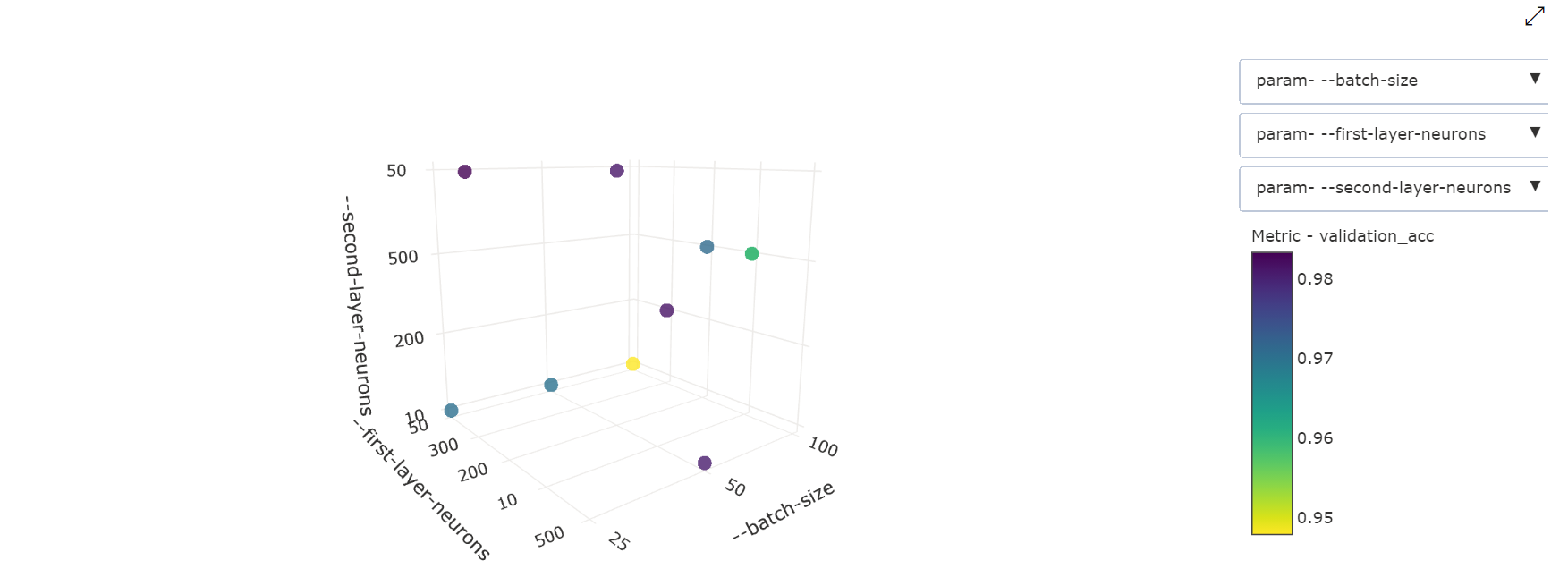
مخطط مبعثر ثلاثي الأبعاد : هذا التمثيل البصري هو نفسه ثنائي الأبعاد ولكنه يسمح بثلاثة أبعاد للمعلمات الفائقة للارتباط بقيمة المقياس الأساسي. يمكنك أيضًا النقر والسحب لإعادة توجيه المخطط لعرض الارتباطات المختلفة في مساحة ثلاثية الأبعاد.
البحث عن أفضل وظيفة تجريبية
بمجرد اكتمال جميع وظائف ضبط المعامل الفائقة، قم باسترداد أفضل مخرجات التجربة:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
يمكنك استخدام CLI لتنزيل جميع المخرجات الافتراضية والمسمية لأفضل وظيفة تجريبية وسجلات مهمة المسح.
az ml job download --name <sweep-job> --all
اختياريًا، لتنزيل أفضل إخراج تجريبي فقط
az ml job download --name <sweep-job> --output-name model