البرنامج التعليمي: تطوير النموذج على محطة عمل سحابية
تعرف على كيفية تطوير برنامج نصي للتدريب باستخدام دفتر ملاحظات على محطة عمل Azure التعلم الآلي السحابية. يغطي هذا البرنامج التعليمي الأساسيات التي تحتاجها للبدء:
- إعداد وتكوين محطة عمل السحابة. يتم تشغيل محطة العمل السحابية الخاصة بك بواسطة مثيل حساب Azure التعلم الآلي، والذي تم تكوينه مسبقا مع بيئات لدعم احتياجات تطوير النموذج المختلفة.
- استخدم بيئات التطوير المستندة إلى السحابة.
- استخدم MLflow لتعقب مقاييس النموذج، كل ذلك من داخل دفتر ملاحظات.
المتطلبات الأساسية
لاستخدام Azure التعلم الآلي، ستحتاج أولا إلى مساحة عمل. إذا لم يكن لديك واحد، فأكمل إنشاء الموارد التي تحتاجها للبدء في إنشاء مساحة عمل ومعرفة المزيد حول استخدامها.
البدء بدفاتر الملاحظات
يعد قسم دفاتر الملاحظات في مساحة العمل الخاصة بك مكانا جيدا لبدء التعرف على التعلم الآلي Azure وقدراته. هنا يمكنك الاتصال بموارد الحوسبة، والعمل مع محطة طرفية، وتحرير وتشغيل Jupyter Notebooks والبرامج النصية.
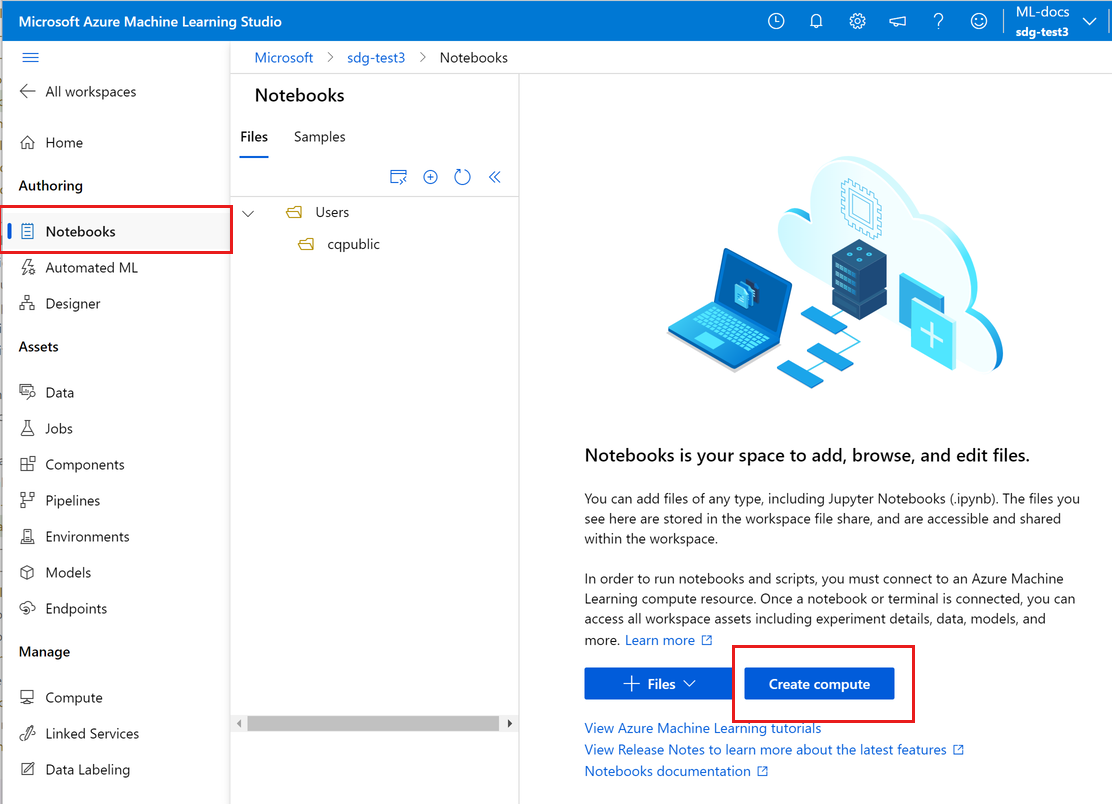
سجل الدخول إلى Azure Machine Learning Studio.
حدد مساحة العمل إذا لم تكن مفتوحة بالفعل.
في جزء التنقل الأيمن، حدد دفاتر الملاحظات.
إذا لم يكن لديك مثيل حساب، فسترى إنشاء حساب في منتصف الشاشة. حدد Create compute واملأ النموذج. يمكنك استخدام جميع الإعدادات الافتراضية. (إذا كان لديك بالفعل مثيل حساب، فسترى بدلا من ذلكالمحطة الطرفية في تلك البقعة. ستستخدم Terminal لاحقا في هذا البرنامج التعليمي.)
إعداد بيئة جديدة للنماذج الأولية (اختياري)
لتشغيل البرنامج النصي الخاص بك، تحتاج إلى العمل في بيئة تم تكوينها باستخدام التبعيات والمكتبات التي تتوقعها التعليمات البرمجية. يساعدك هذا القسم على إنشاء بيئة مصممة خصيصا للتعليمات البرمجية الخاصة بك. لإنشاء نواة Jupyter الجديدة التي يتصل بها دفتر الملاحظات، ستستخدم ملف YAML الذي يحدد التبعيات.
تحميل ملف.
يتم تخزين الملفات التي تقوم بتحميلها في مشاركة ملف Azure، ويتم تحميل هذه الملفات إلى كل مثيل حساب ومشاركتها داخل مساحة العمل.
- قم بتنزيل ملف بيئة conda هذا، workstation_env.yml إلى الكمبيوتر باستخدام الزر Download raw file في أعلى اليمين.
حدد إضافة ملفات، ثم حدد تحميل الملفات لتحميلها إلى مساحة العمل الخاصة بك.
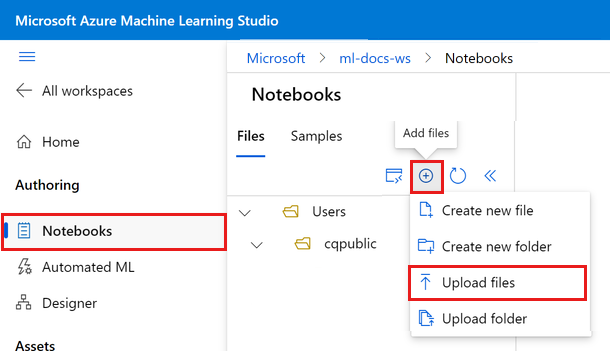
حدد استعراض وحدد ملف (ملفات).
حدد ملف workstation_env.yml الذي قمت بتنزيله.
حدد تحميل.
سترى ملف workstation_env.yml ضمن مجلد اسم المستخدم في علامة التبويب ملفات . حدد هذا الملف لمعاينته، وشاهد التبعيات التي يحددها. سترى محتويات مثل هذا:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibإنشاء نواة.
استخدم الآن Azure التعلم الآلي terminal لإنشاء نواة Jupyter جديدة، استنادا إلى ملف workstation_env.yml.
حدد Terminal لفتح نافذة terminal. يمكنك أيضا فتح المحطة الطرفية من شريط الأوامر الأيسر:
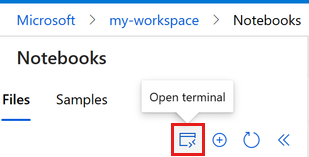
إذا تم إيقاف مثيل الحساب، فحدد Start compute وانتظر حتى يتم تشغيله.

بمجرد تشغيل الحساب، سترى رسالة ترحيب في المحطة الطرفية، ويمكنك بدء كتابة الأوامر.
عرض بيئات conda الحالية. يتم وضع علامة على البيئة النشطة ب *.
conda env listإذا قمت بإنشاء مجلد فرعي لهذا البرنامج التعليمي،
cdإلى هذا المجلد الآن.إنشاء البيئة استنادا إلى ملف conda المقدم. يستغرق بناء هذه البيئة بضع دقائق.
conda env create -f workstation_env.ymlتنشيط البيئة الجديدة.
conda activate workstation_envتحقق من أن البيئة الصحيحة نشطة، وابحث مرة أخرى عن البيئة التي تم وضع علامة عليها ب *.
conda env listإنشاء نواة Jupyter جديدة استنادا إلى بيئتك النشطة.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"أغلق نافذة المحطة الطرفية.

لديك الآن نواة جديدة. بعد ذلك، ستفتح دفتر ملاحظات وتستخدم هذا النواة.
إنشاء دفتر ملاحظات
حدد إضافة ملفات، واختر إنشاء ملف جديد.
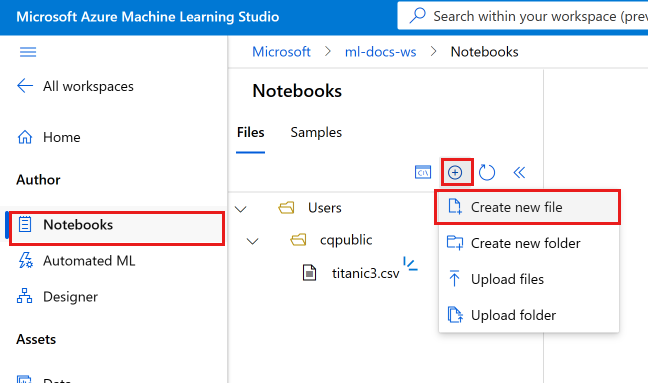
قم بتسمية دفتر الملاحظات الجديد develop-tutorial.ipynb (أو أدخل اسمك المفضل).
إذا تم إيقاف مثيل الحساب، فحدد Start compute وانتظر حتى يتم تشغيله.
سترى أن دفتر الملاحظات متصل بالنواة الافتراضية في أعلى اليمين. قم بالتبديل لاستخدام نواة Env لمحطة عمل البرنامج التعليمي إذا قمت بإنشاء النواة.
تطوير برنامج نصي للتدريب
في هذا القسم، يمكنك تطوير برنامج نصي لتدريب Python يتنبأ بالمدفوعات الافتراضية لبطاقة الائتمان، باستخدام مجموعات بيانات الاختبار والتدريب المعدة من مجموعة بيانات UCI.
تستخدم sklearn هذه التعليمة البرمجية للتدريب وMLflow لتسجيل المقاييس.
ابدأ بالتعليمات البرمجية التي تستورد الحزم والمكتبات التي ستستخدمها في البرنامج النصي للتدريب.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitبعد ذلك، قم بتحميل ومعالجة البيانات لهذه التجربة. في هذا البرنامج التعليمي، تقرأ البيانات من ملف على الإنترنت.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )الحصول على البيانات جاهزة للتدريب:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesأضف التعليمات البرمجية لبدء التسجيل التلقائي باستخدام
MLflow، بحيث يمكنك تتبع المقاييس والنتائج. مع الطبيعة التكرارية لتطوير النموذج،MLflowيساعدك على تسجيل معلمات النموذج ونتائجه. ارجع إلى هذه التشغيلات لمقارنة وفهم كيفية أداء النموذج الخاص بك. توفر السجلات أيضا سياقا عندما تكون مستعدا للانتقال من مرحلة التطوير إلى مرحلة التدريب على مهام سير العمل داخل Azure التعلم الآلي.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()تدريب نموذج.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()إشعار
يمكنك تجاهل تحذيرات mlflow. ستظل تحصل على جميع النتائج التي تحتاج إلى تعقبها.
تكرار
الآن بعد أن أصبحت لديك نتائج النموذج، قد ترغب في تغيير شيء ما والمحاولة مرة أخرى. على سبيل المثال، جرب تقنية مصنف مختلفة:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()إشعار
يمكنك تجاهل تحذيرات mlflow. ستظل تحصل على جميع النتائج التي تحتاج إلى تعقبها.
فحص النتائج
الآن بعد أن جربت نموذجين مختلفين، استخدم النتائج التي تم تعقبها MLFfow لتحديد النموذج الأفضل. يمكنك الرجوع إلى مقاييس مثل الدقة أو المؤشرات الأخرى الأكثر أهمية للسيناريوهات الخاصة بك. يمكنك التعمق في هذه النتائج بمزيد من التفصيل من خلال النظر في الوظائف التي تم إنشاؤها بواسطة MLflow.
في جزء التنقل الأيمن، حدد Jobs.
حدد الرابط الخاص ب Develop on cloud tutorial.
هناك مهمتان مختلفتان معروضتان، واحدة لكل نموذج من النماذج التي جربتها. يتم إنشاء هذه الأسماء تلقائيا. أثناء تمرير الماوس فوق اسم، استخدم أداة القلم الرصاص إلى جانب الاسم إذا كنت تريد إعادة تسميته.
حدد الارتباط للوظيفة الأولى. يظهر الاسم في الأعلى. يمكنك أيضا إعادة تسميته هنا باستخدام أداة القلم الرصاص.
تعرض الصفحة تفاصيل المهمة، مثل الخصائص والمخرجات والعلامات والمعلمات. ضمن Tags، سترى estimator_name، الذي يصف نوع النموذج.
حدد علامة التبويب Metrics لعرض المقاييس التي تم تسجيلها بواسطة
MLflow. (توقع أن تختلف نتائجك، لأن لديك مجموعة تدريب مختلفة.)
حدد علامة التبويب الصور لعرض الصور التي تم إنشاؤها بواسطة
MLflow.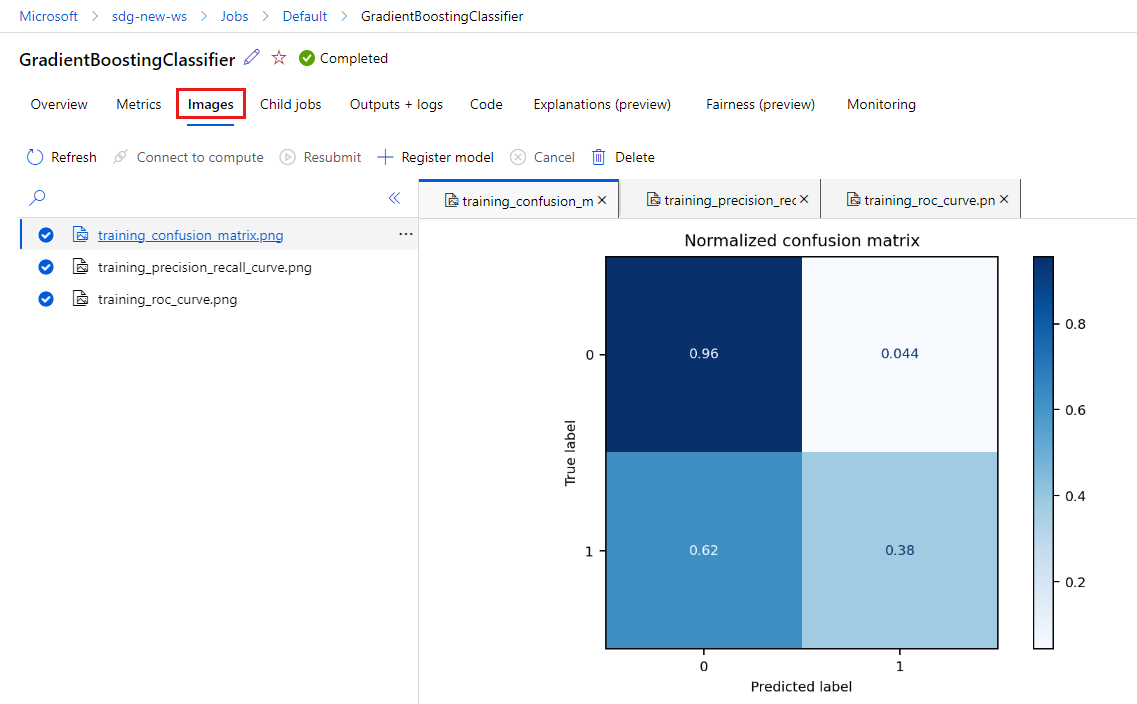
عد وراجع المقاييس والصور للنموذج الآخر.
إنشاء برنامج نصي Python
الآن قم بإنشاء برنامج نصي Python من دفتر الملاحظات الخاص بك لتدريب النموذج.
في شريط أدوات دفتر الملاحظات، حدد القائمة.
حدد تصدير ك> Python.
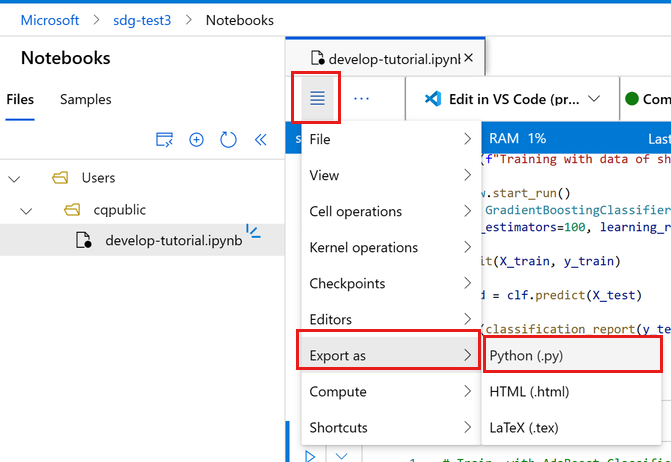
قم بتسمية الملف train.py.
ابحث من خلال هذا الملف واحذف التعليمات البرمجية التي لا تريدها في البرنامج النصي للتدريب. على سبيل المثال، احتفظ بالتعليمات البرمجية للنموذج الذي ترغب في استخدامه، واحذف التعليمات البرمجية للنموذج الذي لا تريده.
- تأكد من الاحتفاظ بالتعليمات البرمجية التي تبدأ التسجيل التلقائي (
mlflow.sklearn.autolog()). - قد ترغب في حذف التعليقات التي تم إنشاؤها تلقائيا وإضافة المزيد من تعليقاتك الخاصة.
- عند تشغيل البرنامج النصي Python بشكل تفاعلي (في محطة طرفية أو دفتر ملاحظات)، يمكنك الاحتفاظ بالخط الذي يعرف اسم التجربة (
mlflow.set_experiment("Develop on cloud tutorial")). أو حتى أعطه اسما مختلفا لرؤيتها كإدخل مختلف في قسم الوظائف . ولكن عند إعداد البرنامج النصي لوظيفة تدريب، لن يعمل هذا السطر ويجب حذفه - يتضمن تعريف الوظيفة اسم التجربة. - عند تدريب نموذج واحد، فإن خطوط بدء التشغيل وإنهاءه (
mlflow.start_run()وmlflow.end_run()) ليست ضرورية أيضا (لن يكون لها أي تأثير)، ولكن يمكن تركها إذا كنت ترغب في ذلك.
- تأكد من الاحتفاظ بالتعليمات البرمجية التي تبدأ التسجيل التلقائي (
عند الانتهاء من عمليات التحرير، احفظ الملف.
لديك الآن برنامج نصي Python لاستخدامه لتدريب النموذج المفضل لديك.
تشغيل برنامج Python النصي
في الوقت الحالي، تقوم بتشغيل هذه التعليمات البرمجية على مثيل الحساب الخاص بك، وهي بيئة تطوير Azure التعلم الآلي. البرنامج التعليمي: تدريب نموذج يوضح لك كيفية تشغيل برنامج نصي للتدريب بطريقة أكثر قابلية للتطوير على موارد حساب أكثر قوة.
على اليسار، حدد فتح المحطة الطرفية لفتح نافذة طرفية.
عرض بيئات conda الحالية. يتم وضع علامة على البيئة النشطة ب *.
conda env listإذا قمت بإنشاء نواة جديدة، فنشطها الآن:
conda activate workstation_envإذا قمت بإنشاء مجلد فرعي لهذا البرنامج التعليمي،
cdإلى هذا المجلد الآن.تشغيل البرنامج النصي للتدريب الخاص بك.
python train.py
إشعار
يمكنك تجاهل تحذيرات mlflow. ستظل تحصل على جميع المقاييس والصور من التسجيل التلقائي.
فحص نتائج البرنامج النصي
ارجع إلى Jobs للاطلاع على نتائج البرنامج النصي للتدريب. ضع في اعتبارك أن بيانات التدريب تتغير مع كل تقسيم، لذلك تختلف النتائج بين عمليات التشغيل أيضا.
تنظيف الموارد
إذا كنت تخطط للمتابعة الآن إلى البرامج التعليمية الأخرى، فانتقل إلى الخطوات التالية.
إيقاف حساب مثيل
إذا كنت لن تستخدمه الآن، فأوقف مثيل الحساب:
- في الاستوديو، في منطقة التنقل اليسرى، حدد Compute.
- في علامات التبويب العليا، حدد "Compute instances"
- حدد "compute instance" في القائمة.
- في شريط الأدوات العلوي، حدد "Stop".
حذف كافة الموارد
هام
يمكن استخدام الموارد التي قمت بإنشائها كمتطلبات أساسية لبرامج تعليمية أخرى في Azure ومقالات إرشادية.
إذا كنت لا تخطط لاستخدام الموارد التي أنشأتها، فاحذفها، حتى لا تتحمل أي رسوم:
من مدخل Microsoft Azure، حدد Resource groups من أقصى الجانب الأيمن.
من القائمة، حدد مجموعة الموارد التي أنشأتها.
حدد Delete resource group.
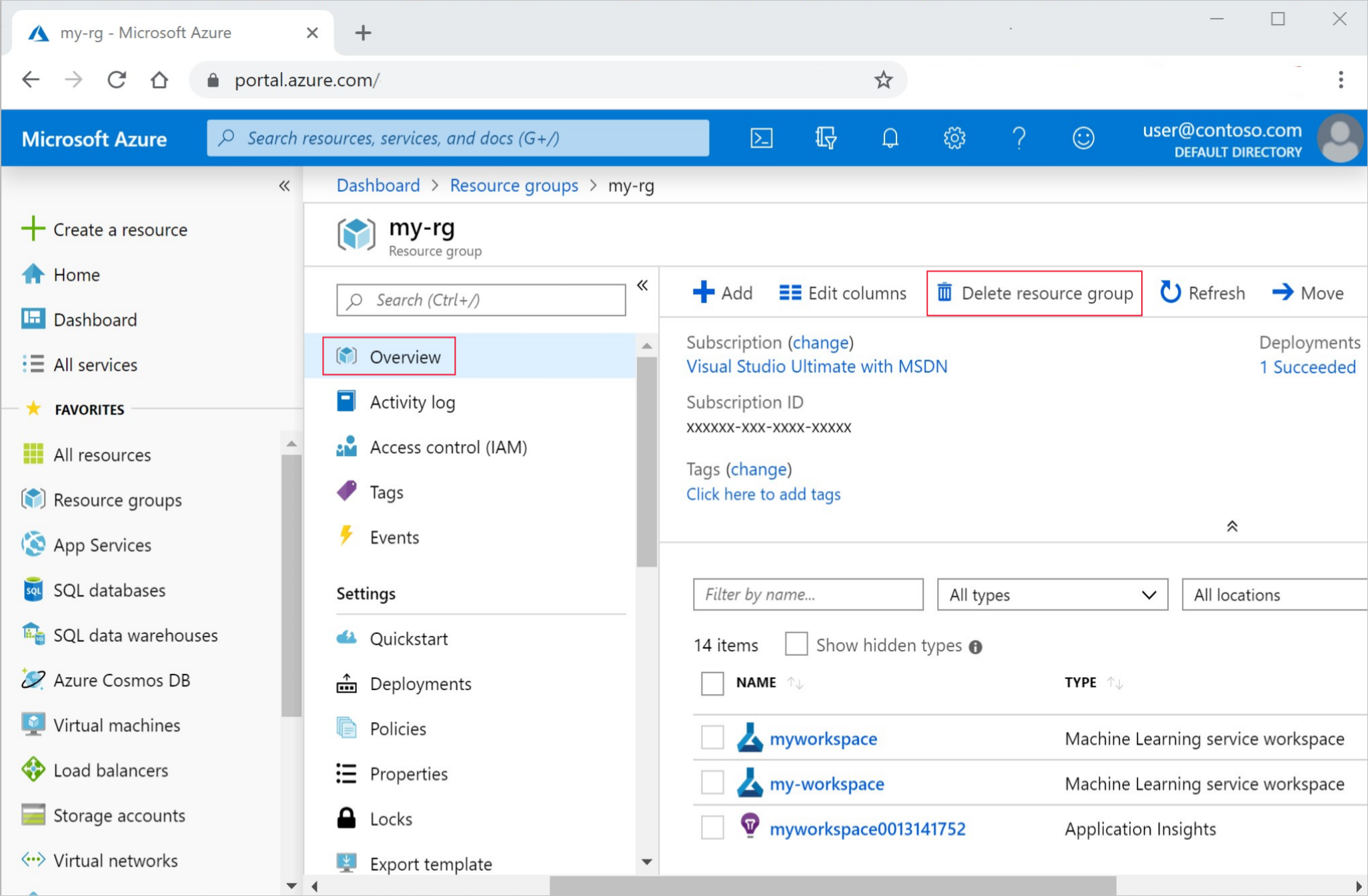
أدخل اسم مجموعة الموارد. ثم حدد حذف.
الخطوات التالية
تعلم المزيد عن:
- من البيانات الاصطناعية إلى النماذج في MLflow
- استخدام Git مع Azure التعلم الآلي
- تشغيل دفاتر ملاحظات Jupyter في مساحة العمل الخاصة بك
- العمل مع محطة طرفية لمثيل الحوسبة في مساحة العمل الخاصة بك
- إدارة جلسات عمل المحطة الطرفية ودفتر الملاحظات
أظهر لك هذا البرنامج التعليمي الخطوات المبكرة لإنشاء نموذج، والنماذج الأولية على نفس الجهاز حيث توجد التعليمات البرمجية. لتدريب الإنتاج الخاص بك، تعرف على كيفية استخدام هذا البرنامج النصي للتدريب على موارد الحوسبة عن بعد الأكثر قوة: