إعداد توفر عالي في SUSE باستخدام جهاز تسييج
في هذه المقالة، سنتناول الخطوات اللازمة لإعداد التوفر العالي (HA) في مثيلات HANA الكبيرة على نظام التشغيل SUSE باستخدام جهاز تسييج.
ملاحظة
يتم اشتقاق هذا الدليل من اختبار الإعداد بنجاح في بيئة مثيلات Microsoft HANA الكبيرة. لا يدعم فريق إدارة خدمات Microsoft لمثيلات HANA الكبيرة نظام التشغيل. لاستكشاف الأخطاء وإصلاحها أو توضيح طبقة نظام التشغيل، اتصل بـ SUSE.
يقوم فريق إدارة خدمات Microsoft بإعداد جهاز تسييج ودعمه بالكامل. يمكن أن يساعد في استكشاف مشكلات جهاز تسييج وإصلاحها.
المتطلبات الأساسية
لإعداد توفر عالي باستخدام مجموعات SUSE، تحتاج إلى:
- توفير مثيلات HANA الكبيرة.
- تثبيت نظام التشغيل وتسجيله باستخدام أحدث التصحيحات.
- توصيل بخوادم مثيلات HANA الكبيرة بخادم SMT للحصول على التصحيحات والحزم.
- إعداد بروتوكول وقت الشبكة (خادم وقت NTP).
- قراءة وفهم أحدث وثائق SUSE حول إعداد HA.
تفاصيل الإعداد
يستخدم هذا الدليل الإعداد التالي:
- نظام التشغيل: SLES 12 SP1 لـSAP
- مثيلات HANA الكبيرة: 2xS192 (أربعة مآخذ، 2 تيرابايت)
- إصدار HANA: HANA 2.0 SP1
- أسماء الخوادم: sapprdhdb95 (node1) وsapprdhdb96 (node2)
- جهاز تسييج: يستند إلى بروتوكول iSCSI
- NTP على إحدى عقد مثيل HANA الكبير
عند إعداد مثيلات HANA الكبيرة مع النسخ المتماثل لنظام HANA يمكنك مطالبة فريق إدارة خدمة Microsoft بإعداد جهاز التسييج. قم بذلك في وقت التوفير.
إذا كنت عميلًا حاليًا تم توفير مثيلات HANA الكبيرة لك بالفعل، فلا يزال بإمكانك إعداد جهاز تسييج. قم بتوفير المعلومات التالية لفريق إدارة خدمات Microsoft في نموذج طلب الخدمة (SRF). يمكنك الحصول على SRF من خلال مدير الحساب الفني أو جهة اتصال Microsoft الخاصة بك لإعداد مثيل HANA الكبير.
- اسم الخادم وعنوان IP للخادم (على سبيل المثال، myhanaserver1 و 10.35.0.1)
- الموقع (على سبيل المثال، شرق الولايات المتحدة)
- اسم العميل (على سبيل المثال، Microsoft)
- معرف نظام HANA (SID) (على سبيل المثال، H11)
بعد تكوين جهاز التسييج، سيزودك فريق إدارة خدمات Microsoft باسم SBD وعنوان IP الخاص بوحدة تخزين iSCSI. يمكنك استخدام هذه المعلومات لتكوين إعداد جهاز التسييج.
اتبع الخطوات الواردة في الأقسام التالية لإعداد HA باستخدام جهاز التسييج.
التعرف على جهاز SBD
ملاحظة
ينطبق هذا القسم فقط على العملاء الحاليين. إذا كنت عميلا جديدا، فسيعطيك فريق إدارة خدمات Microsoft اسم جهاز SBD، لذا تخطى هذا القسم.
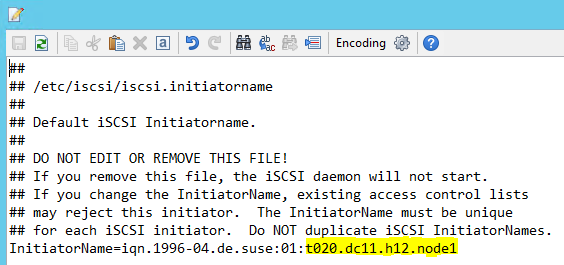
قم بتعديل / etc/iscsi/initiatorname.isci إلى:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>توفر إدارة خدمات Microsoft هذه السلسلة. قم بتعديل الملف على كلتا العقدتين. ومع ذلك، يختلف رقم العقدة في كل عقدة.
قم بتعديل / etc/iscsi/iscsid.conf عن طريق الإعداد
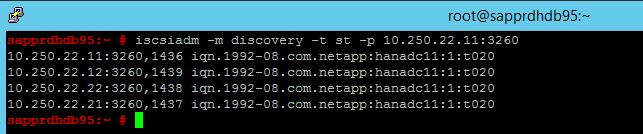
node.session.timeo.replacement_timeout=5وnode.startup = automatic. قم بتعديل الملف على كلتا العقدتين.قم بتشغيل أمر الاكتشاف التالي على كلتا العقدتين.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260تظهر النتائج أربع جلسات.
قم بتشغيل الأمر التالي على كلتا العقدتين لتسجيل الدخول إلى جهاز iSCSI.
iscsiadm -m node -lتظهر النتائج أربع جلسات.

استخدم الأمر التالي لتشغيل البرنامج النصي لإعادة الفحص rescan-scsi-bus.sh. يعرض هذا البرنامج النصي الأقراص الجديدة التي تم إنشاؤها لك. قم بتشغيله على كلتا العقدتين.
rescan-scsi-bus.shيجب أن تظهر النتائج رقم LUN أكبر من الصفر (على سبيل المثال: 1 و 2 وما إلى ذلك).

للحصول على اسم الجهاز، قم بتشغيل الأمر التالي على كلتا العقدتين.
fdisk –lفي النتائج، اختر الجهاز بحجم 178 ميجابت.

تهيئة جهاز SBD
استخدم الأمر التالي لتهيئة جهاز SBD على كلتا العقدتين.
sbd -d <SBD Device Name> create
استخدم الأمر التالي على كلتا العقدتين للتحقق مما تمت كتابته على الجهاز.
sbd -d <SBD Device Name> dump
تكوين مجموعة SUSE HA
استخدم الأمر التالي للتحقق مما إذا كانت ha_sles وأنماط SAPHanaSR-doc مثبتة على كلتا العقدتين. إذا لم تكن مثبتة، فقم بتثبيتها.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
قم بإعداد نظام المجموعة باستخدام الأمر
ha-cluster-initأو معالج yast2. في هذا المثال، نستخدم معالج yast2. قم بهذه الخطوة فقط على العقدة الأساسية.انتقل إلى yast2>High Availability>Cluster.
في مربع الحوار الذي يظهر حول تثبيت حزمة الصقر، حدد إلغاء لأن حزمة halk2 مثبتة بالفعل.
في مربع الحوار الذي يظهر حول المتابعة، حدد متابعة.
القيمة المتوقعة هي عدد العقد المنتشرة (في هذه الحالة، 2). حدد "Next".
أضف أسماء العقد، ثم حدد إضافة ملفات مقترحة.

حدد تشغيل csync2.
حدد إنشاء مفاتيح مشتركة مسبقًا.
في الرسالة المنبثقة التي تظهر، حدد موافق.
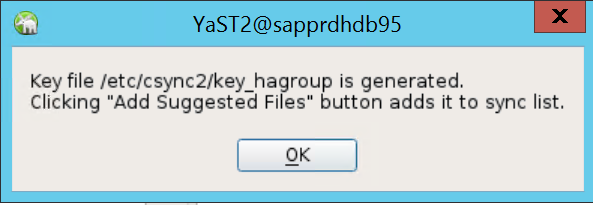
يتم إجراء المصادقة باستخدام عناوين IP والمفاتيح المشتركة مسبقًا في Csync2. يتم إنشاء ملف المفتاح باستخدام
csync2 -k /etc/csync2/key_hagroup.انسخ الملف key_hagroup يدويًا إلى كافة أعضاء المجموعة بعد إنشائه. تأكد من نسخ الملف من node1 إلى node2. ثم حدد «Next».
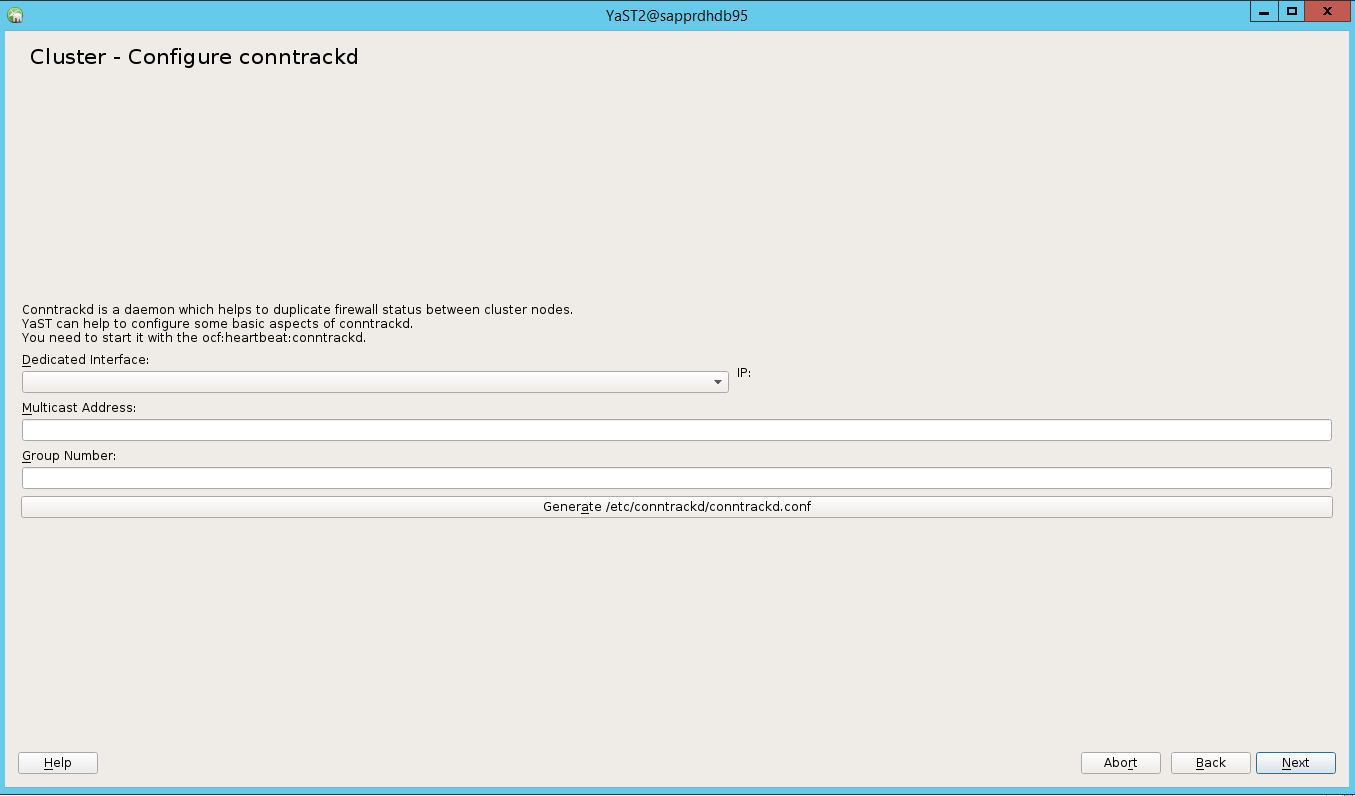
في الخيار الافتراضي، التمهيدمتوقف عن العمل. قم بتغييره إلى تشغيل بحيث يتم تشغيل خدمة جهاز تنظيم ضربات القلب عند التمهيد. يمكنك الاختيار بناءً على متطلبات الإعداد الخاصة بك.

حدد التالي، ويكتمل تكوين المجموعة.
إعداد مراقبة softdog
أضف السطر التالي إلى / etc/init.d/boot.local على كلتا العقدتين.
modprobe softdog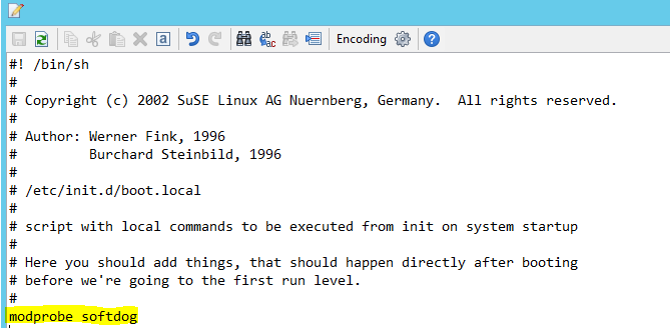
استخدم الأمر التالي لتحديث الملف / etc/sysconfig/sbd على كلتا العقدتين.
SBD_DEVICE="<SBD Device Name>"
قم بتحميل وحدة kernel النمطية على كلتا العقدتين عن طريق تشغيل الأمر التالي.
modprobe softdog
استخدم الأمر التالي للتأكد من تشغيل softdog على كلتا العقدتين.
lsmod | grep dog
استخدم الأمر التالي لبدء تشغيل جهاز SBD على كلتا العقدتين.
/usr/share/sbd/sbd.sh start
استخدم الأمر التالي لاختبار التطبيق الخفي SBD على كلتا العقدتين.
sbd -d <SBD Device Name> listتظهر النتائج إدخالين بعد التكوين على كلتا العقدتين.

أرسل رسالة الاختبار التالية إلى إحدى العقد.
sbd -d <SBD Device Name> message <node2> <message>في العقدة الثانية (node2)، استخدم الأمر التالي للتحقق من حالة الرسالة.
sbd -d <SBD Device Name> list
لاعتماد تكوين SBD، قم بتحديث الملف / etc/sysconfig/sbd على النحو التالي في كلتا العقدتين.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""استخدم الأمر التالي لبدء تشغيل خدمة جهاز تنظيم ضربات القلب على العقدة الأساسية (node1).
systemctl start pacemaker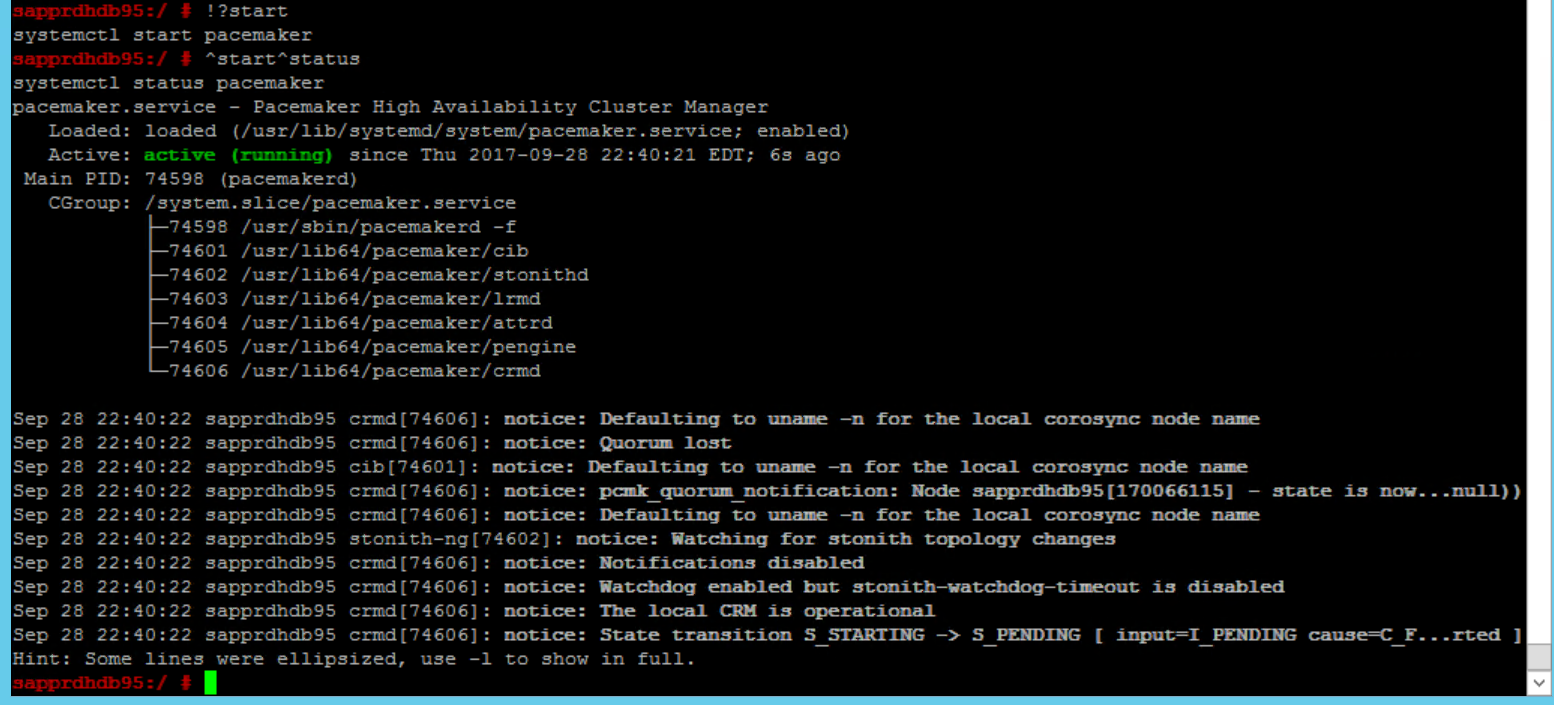
في حالة فشل خدمة جهاز تنظيم ضربات القلب، راجع القسم السيناريو 5: فشل خدمة جهاز تنظيم ضربات القلب لاحقًا في هذه المقالة.
ضم العقدة إلى المجموعة
قم بتشغيل الأمر التالي على node2 للسماح لهذه العقدة بالانضمام إلى المجموعة.
ha-cluster-join
إذا تلقيت خطأ أثناء الانضمام إلى المجموعة، فراجع القسم السيناريو 6: يتعذر على Node2 الانضمام إلى المجموعة لاحقًا في هذه المقالة.
التحقق من صحة نظام المجموعة
استخدم الأوامر التالية للتحقق من المجموعة وبدء تشغيلها اختياريًا لأول مرة على كلتا العقدتين.
systemctl status pacemaker systemctl start pacemaker
قم بتشغيل الأمر التالي للتأكد من أن كلتا العقدتين متصلتين بالإنترنت. يمكنك تشغيله على أي من عقد المجموعة.
crm_mon
يمكنك أيضا تسجيل الدخول إلى hawk للتحقق من حالة المجموعة:
https://\<node IP>:7630. المستخدم الافتراضي هو hacluster، وكلمة المرور هي linux. إذا لزم الأمر، يمكنك تغيير كلمة المرور باستخدام الأمرpasswd.
تكوين خصائص المجموعة ومواردها
يصف هذا القسم الخطوات اللازمة لتكوين موارد المجموعة. في هذا المثال، يمكنك إعداد الموارد التالية. يمكنك تكوين الباقي (إذا لزم الأمر) بالرجوع إلى دليل SUSE HA.
- مجموعة أجهزة نظام تمهيد تشغيل الكمبيوتر
- جهاز تسييج
- عنوان IP الظاهري
قم بإجراء التكوين على العقدة الأساسية فقط.
قم بإنشاء ملف تمهيد المجموعة وتكوينه عن طريق إضافة النص التالي.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"استخدم الأمر التالي لإضافة التكوين إلى المجموعة.
crm configure load update crm-bs.txt
قم بتكوين جهاز التسييج عن طريق إضافة المورد وإنشاء الملف وإضافة نص كما يلي.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"استخدم الأمر التالي لإضافة التكوين إلى المجموعة.
crm configure load update crm-sbd.txtأضف عنوان IP الظاهري للمورد عن طريق إنشاء الملف وإضافة النص التالي.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"استخدم الأمر التالي لإضافة التكوين إلى المجموعة.
crm configure load update crm-vip.txtاستخدم الأمر
crm_monللتحقق من صحة الموارد.تظهر النتائج الموردين.

يمكنك أيضا التحقق من الحالة على https://<عنوان IP للعقدة>:7630/cib/live/state.
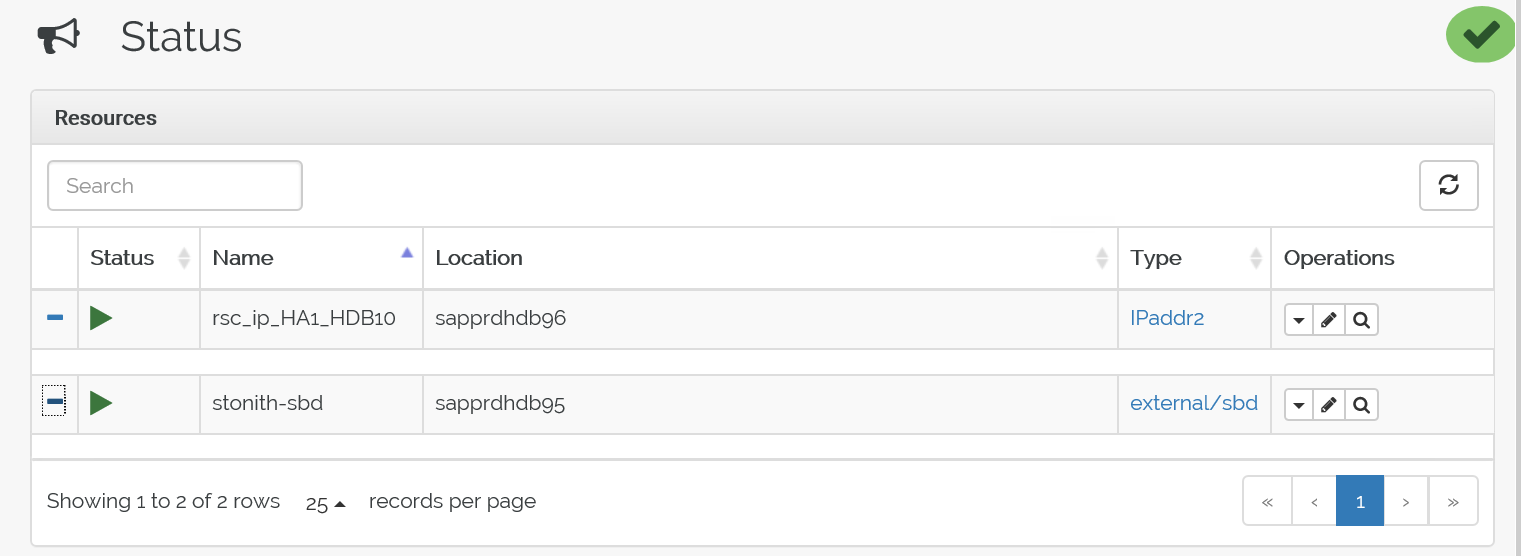
اختبار عملية تجاوز الفشل
لاختبار عملية تجاوز الفشل، استخدم الأمر التالي لإيقاف خدمة جهاز تنظيم ضربات القلب على node1.
Service pacemaker stopيتم تجاوز فشل الموارد إلى node2.
أوقف خدمة منظم ضربات القلب على node2، ويتم تجاوز فشل الموارد إلى node1.
إليك الحالة قبل تجاوز الفشل:
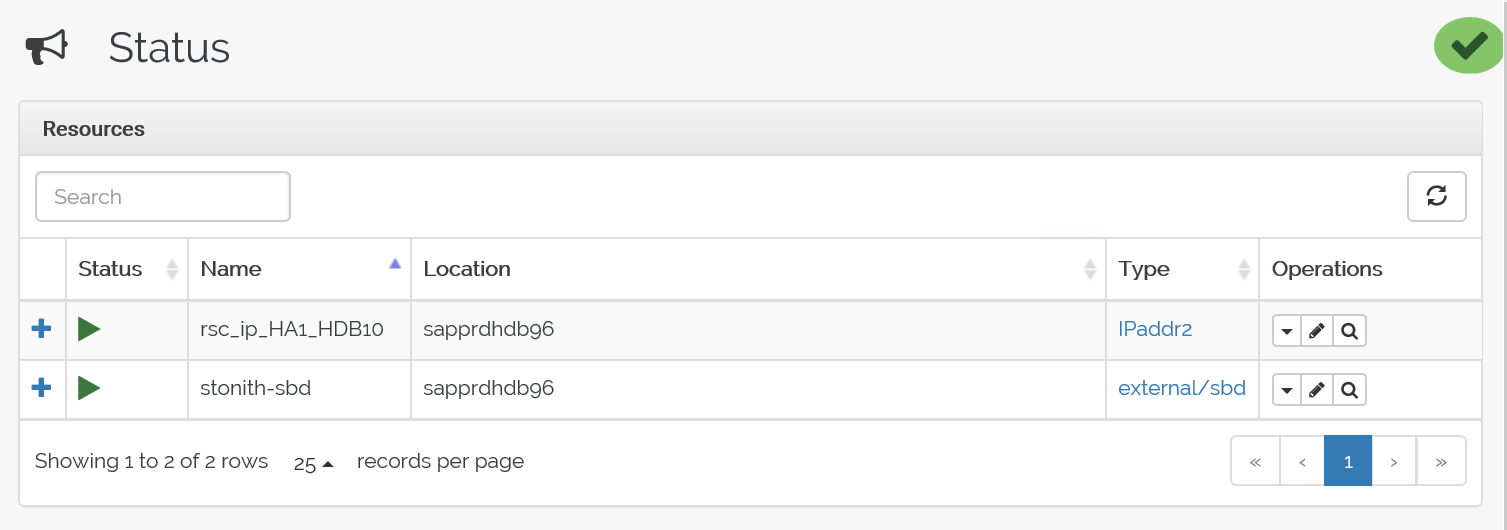
إليك الحالة بعد تجاوز الفشل:


استكشاف الأخطاء وإصلاحها
يصف هذا القسم سيناريوهات الفشل التي قد تواجهها أثناء الإعداد.
السيناريو 1: عقدة نظام المجموعة غير متصلة بالإنترنت
إذا لم تظهر أي من العقد عبر الإنترنت في "إدارة نظام المجموعة"، فيمكنك تجربة هذا الإجراء لإحضارها عبر الإنترنت.
استخدم الأمر التالي لبدء تشغيل خدمة iSCSI.
service iscsid startاستخدم الأمر التالي لتسجيل الدخول إلى عقدة iSCSI هذه.
iscsiadm -m node -lيبدو الإخراج المتوقع مثل:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
السيناريو 2: لا يعرض Yast2 طريقة العرض الرسومية
يتم استخدام الشاشة الرسومية yast2 لإعداد مجموعة التوفر العالي في هذه المقالة. إذا لم يتم فتح yast2 باستخدام النافذة الرسومية كما هو موضح، وطرح خطأ Qt، فاتبع الخطوات التالية لتثبيت الحزم المطلوبة. إذا تم فتحه باستخدام النافذة الرسومية، فيمكنك تخطي الخطوات.
فيما يلي مثال على خطأ Qt:

وفيما يلي مثال على الإخراج المتوقع:
تأكد من تسجيل الدخول كـ "جذر" للمستخدم وإعداد SMT لتنزيل الحزم وتثبيتها.
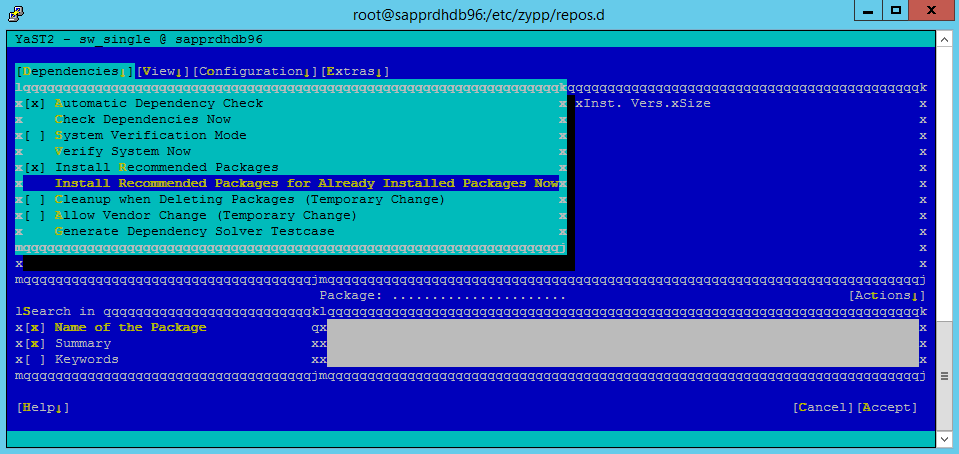
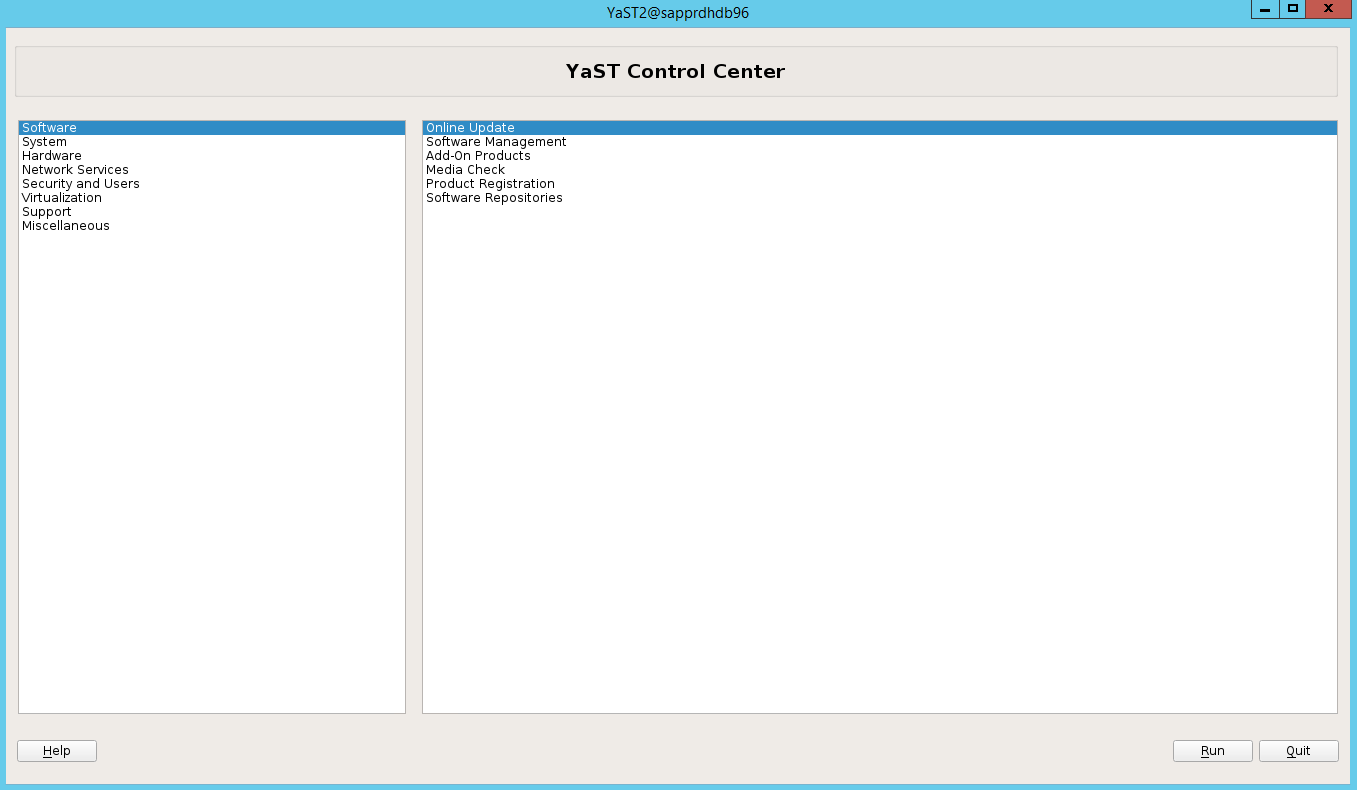
انتقل إلى yast>Software>إدارة البرامج>التبعيات، ثم حدد تثبيت الحزم المُوصى بها.
ملاحظة
قم بتنفيذ الخطوات على كلتا العقدتين، بحيث يمكنك الوصول إلى طريقة العرض الرسومية yast2 من كلتا العقدتين.
تعرض لقطة الشاشة التالية الشاشة المتوقعة.
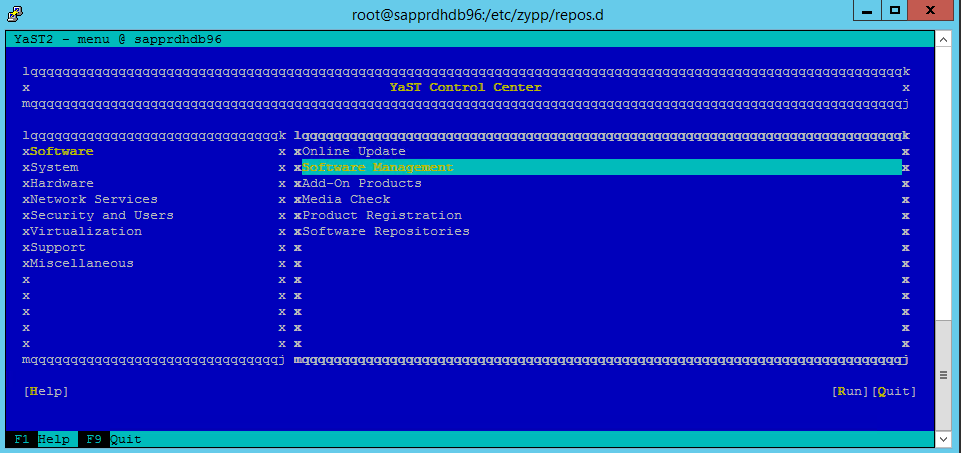
ضمن التبعيات، حدد تثبيت الحزم الموصى بها.
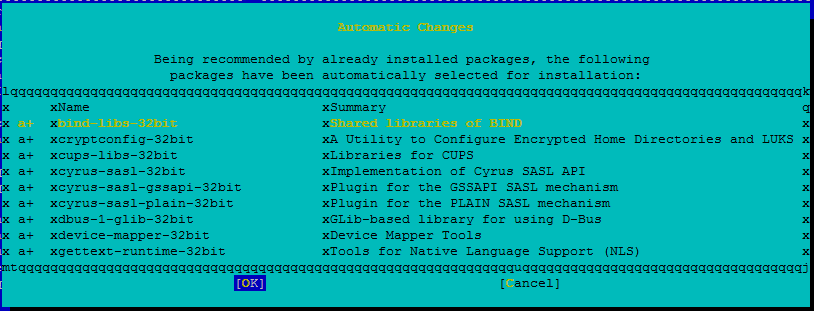
راجع التغييرات وحدد موافق.
يستمر تثبيت الحزمة.
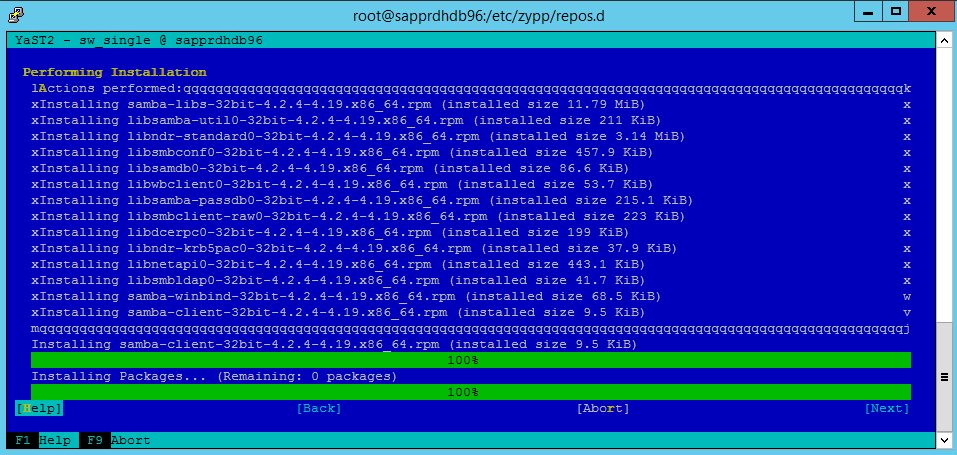
حدد "Next".
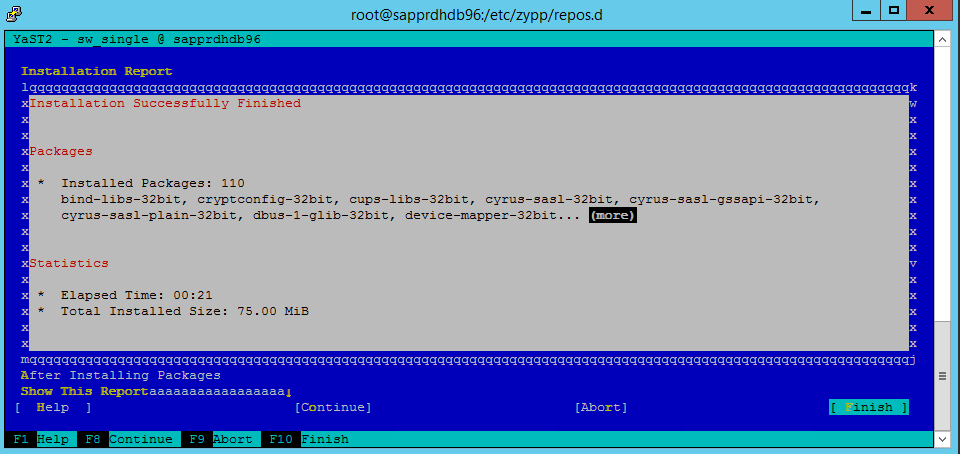
عند ظهور شاشة انتهى التثبيت بنجاح، حدد إنهاء.
استخدم الأوامر التالية لتثبيت حزمتي libqt4 وlibyui-qt.
zypper -n install libqt4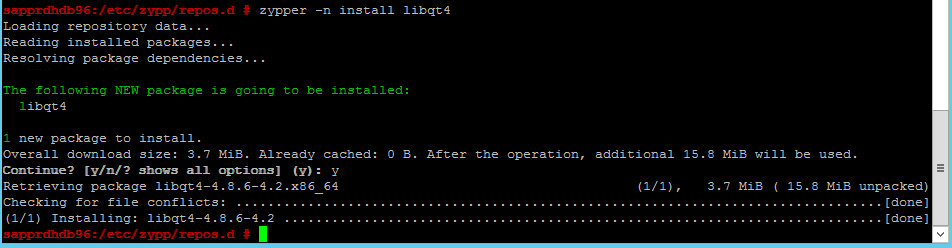
zypper -n install libyui-qt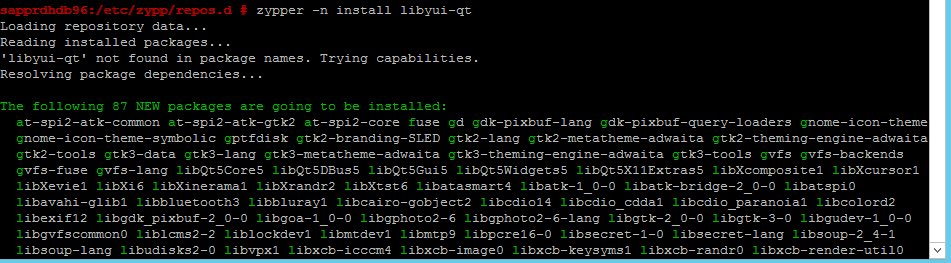

يمكن لـ Yast2 الآن فتح طريقة العرض الرسومية.
السيناريو 3: لا يعرض Yast2 خيار التوفر العالي
لكي يكون خيار التوفر العالي مرئيًا في مركز التحكم بـyast2، تحتاج إلى تثبيت الحزم الأخرى.
انتقل إلى Yast2>Software>إدارة البرامج. ثم حدد تحديث البرامج>عبر الإنترنت.
حدد أنماطًا للعناصر التالية. ثم حدد قبول.
- قاعدة خادم SAP Hana
- C / C ++ المترجم والأدوات
- توفّر عالٍ
- قاعدة خادم تطبيق SAP
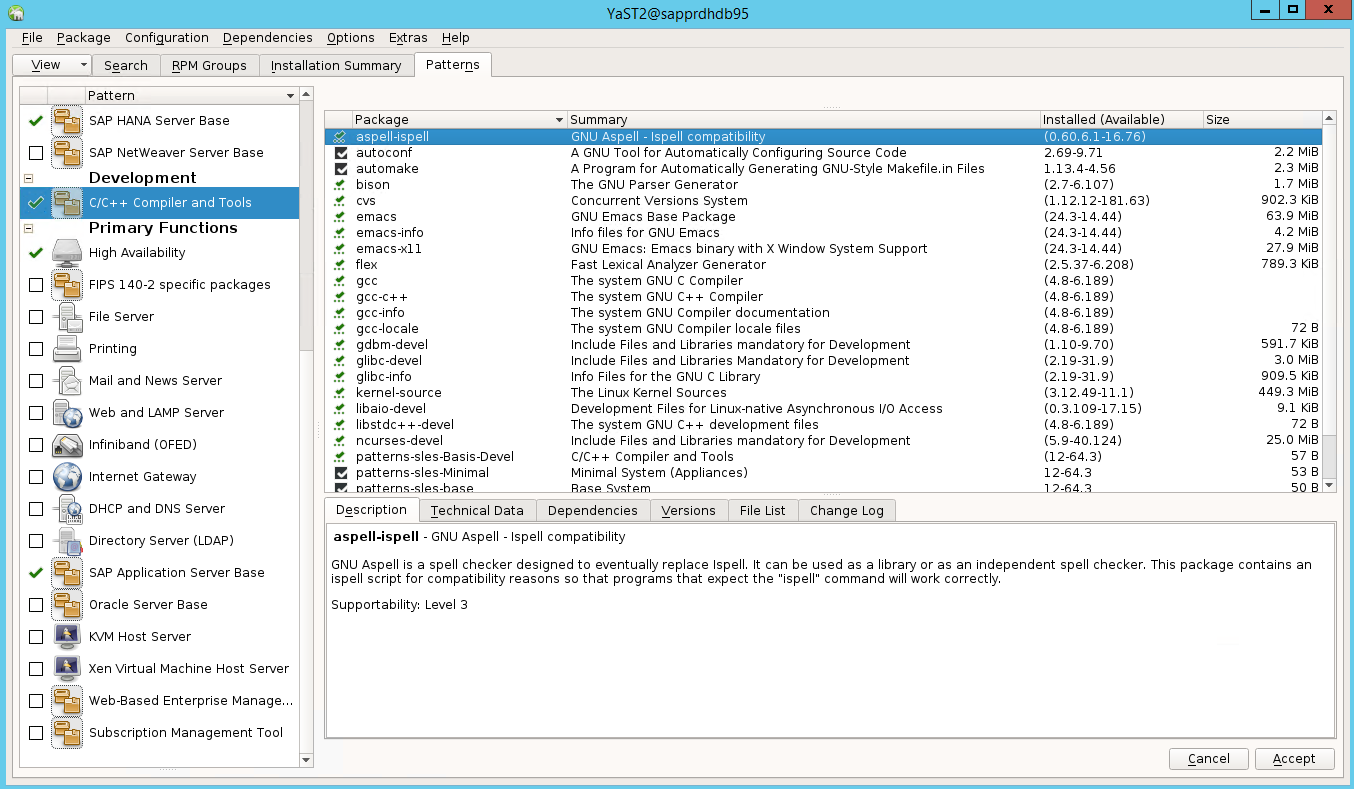
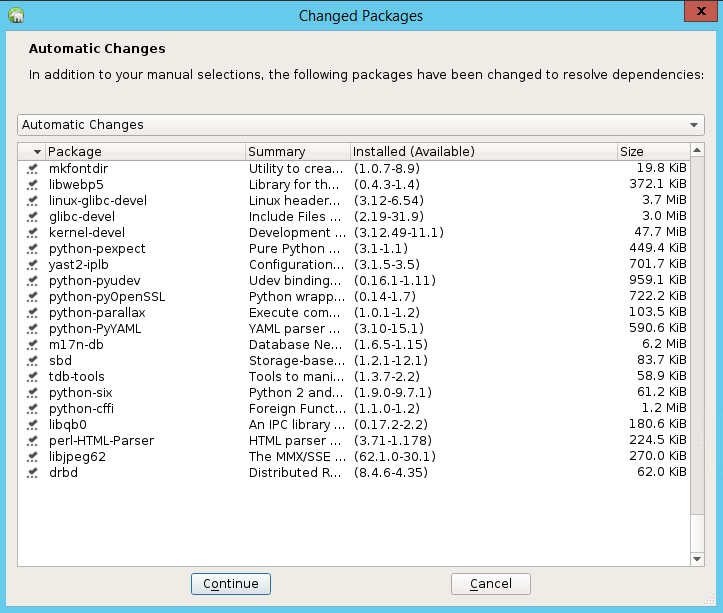
في قائمة الحزم التي تم تغييرها لحل التبعيات، حدد متابعة.
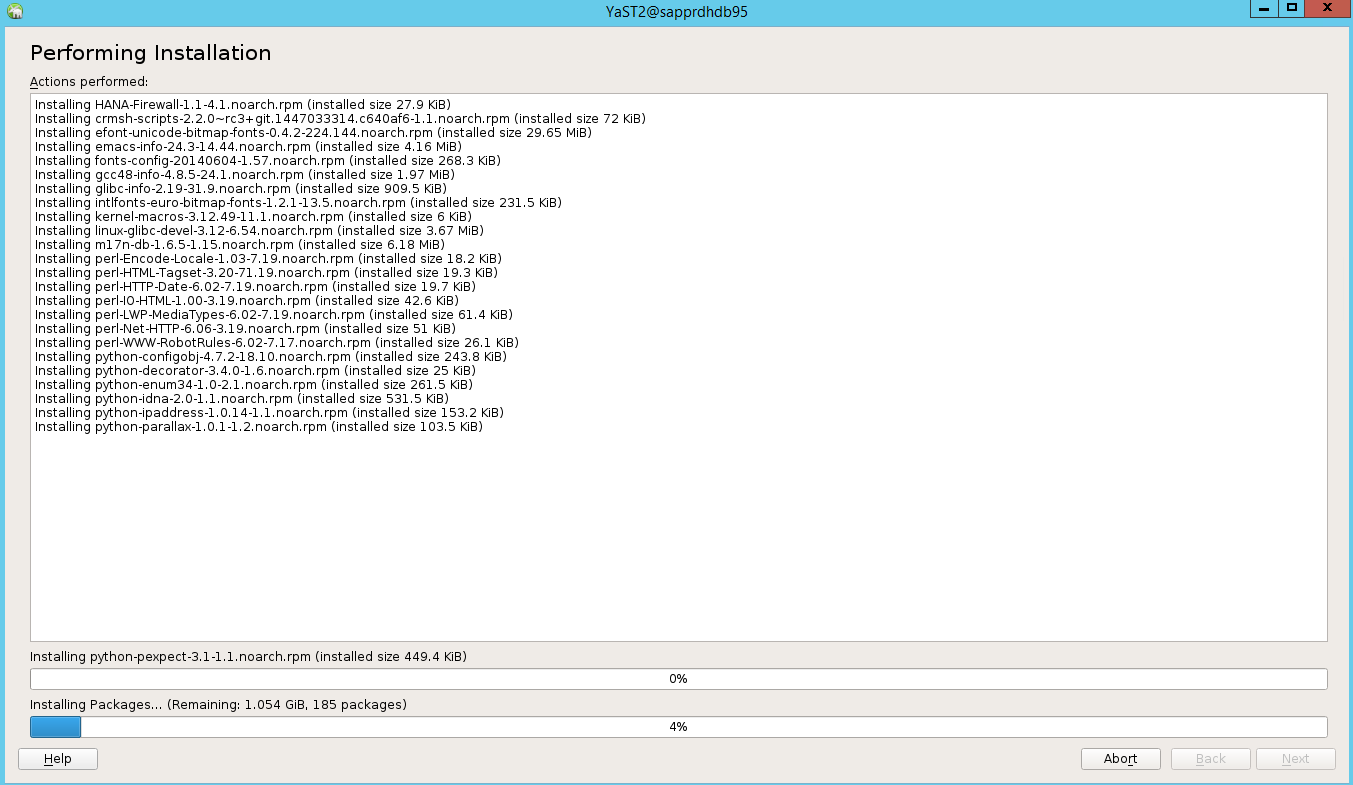
في صفحة حالة تنفيذ التثبيت، حدد التالي.
عند اكتمال التثبيت، يظهر تقرير التثبيت. اختر إنهاء.
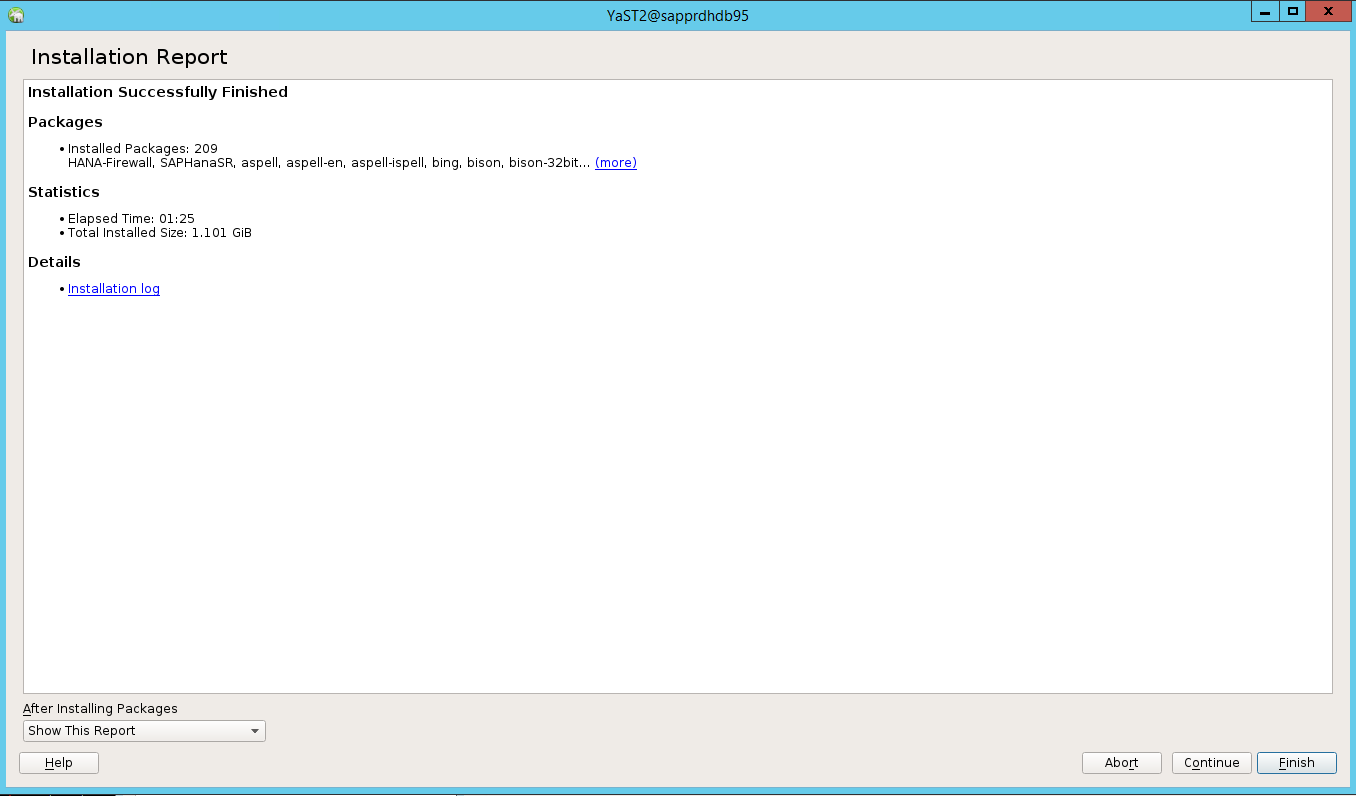
السيناريو 4: فشل تثبيت HANA مع خطأ في تجميعات gcc
في حالة فشل تثبيت HANA، قد تظهر لك رسالة الخطأ التالية.

لحل المشكلة، قم بتثبيت مكتبتي libgcc_sl وlibstdc++6 كما هو موضح في لقطة الشاشة التالية.
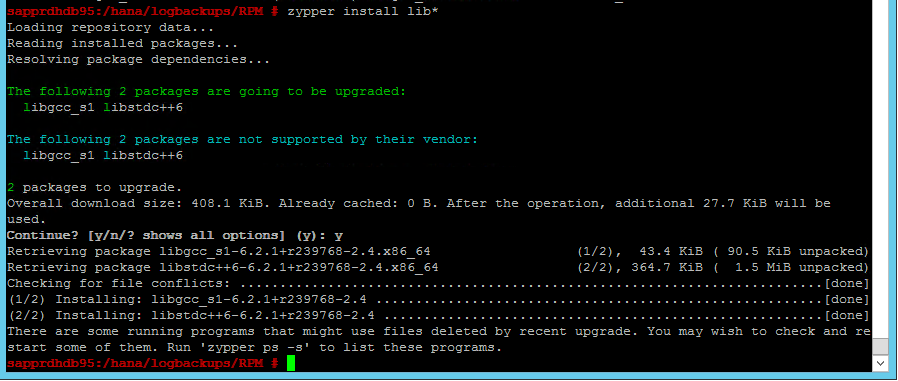
السيناريو 5: فشل خدمة جهاز تنظيم ضربات القلب
تظهر المعلومات التالية إذا تعذر بدء تشغيل خدمة جهاز تنظيم ضربات القلب.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
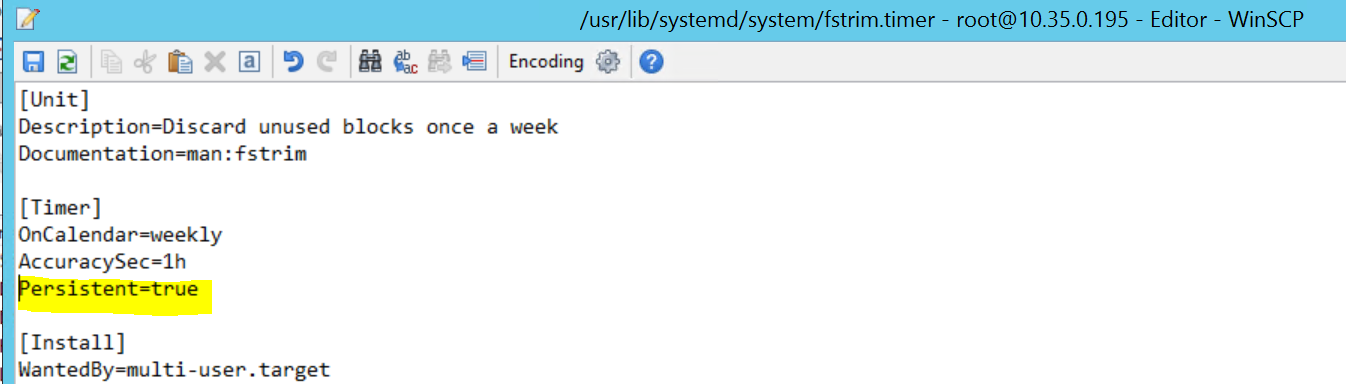
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
لإصلاح الأمر، احذف السطر التالي من الملف / usr/lib/systemd/system/fstrim.timer:
Persistent=true
السيناريو 6: يتعذر على Node2 الانضمام إلى المجموعة
يظهر الخطأ التالي إذا كانت هناك مشكلة في ضم node2 إلى المجموعة الموجودة من خلال الأمر ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>
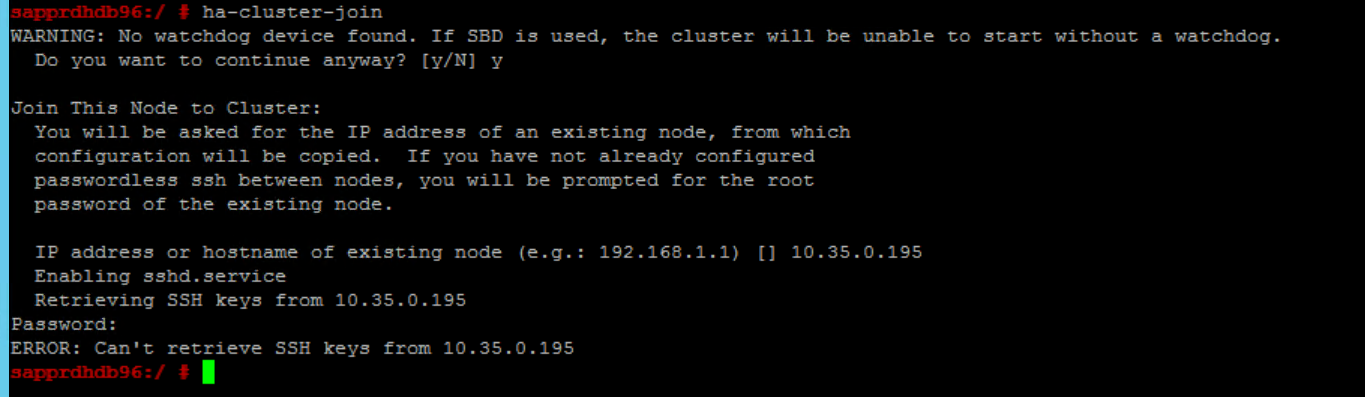
لإصلاح الأمر:
قم بتشغيل الأوامر التالية على كلتا العقدتين.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

تأكد من إضافة node2 إلى المجموعة.

الخطوات التالية
يمكنك العثور على مزيد من المعلومات حول إعداد SUSE HA في المقالات التالية:
- سيناريو الأداء المحسن لـ SAP HANA SR (موقع SUSE)
- التسييج وأجهزة التسييج (موقع SUSE على الويب)
- كن مستعدا لاستخدام مجموعة أجهزة تنظيم ضربات القلب لـ SAP Hana - الجزء 1: الأساسيات (مدونة SAP)
- كن مستعدا لاستخدام مجموعة أجهزة تنظيم ضربات القلب SAP Hana - الجزء 2: فشل كلتا العقدتين (مدونة SAP)
- النسخ الاحتياطي لنظام التشغيل واستعادته