Data acquisition and understanding stage of the Team Data Science Process lifecycle
This article outlines the goals, tasks, and deliverables associated with the data acquisition and understanding stage of the Team Data Science Process (TDSP). This process provides a recommended lifecycle that your team can use to structure your data science projects. The lifecycle outlines the major stages that your team performs, often iteratively:
- Business understanding
- Data acquisition and understanding
- Modeling
- Deployment
- Customer acceptance
Here's a visual representation of the TDSP lifecycle:
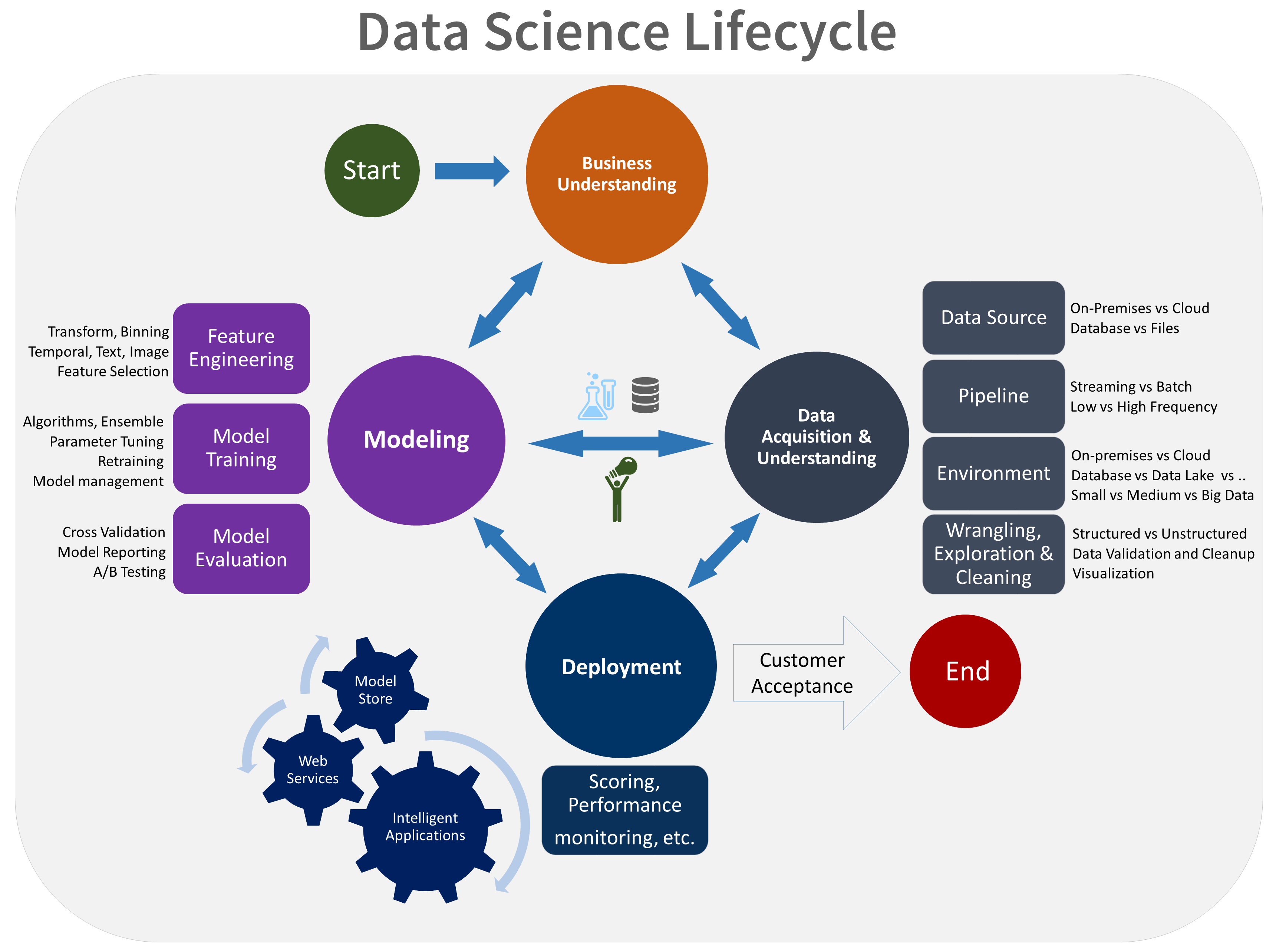
Goals
The goals of the data acquisition and understanding stage are to:
Produce a clean, high-quality dataset that clearly relates to the target variables. Locate the dataset in the appropriate analytics environment so your team is ready for the modeling stage.
Develop a solution architecture of the data pipeline that refreshes and scores the data regularly.
How to complete the tasks
The data acquisition and understanding stage has three main tasks:
Ingest data into the target analytic environment.
Explore data to determine if the data can answer the question.
Set up a data pipeline to score new or regularly refreshed data.
Ingest data
Set up a process to move data from the source locations to the target locations where you run analytics operations, like training and predictions.
Explore data
Before you train your models, you need to develop a sound understanding of the data. Real-world datasets are often noisy, are missing values, or have a host of other discrepancies. You can use data summarization and visualization to audit the quality of your data and gather information for processing the data before it's ready for modeling. This process is often iterative. For guidance on cleaning the data, see Tasks to prepare data for enhanced machine learning.
After you're satisfied with the quality of the cleansed data, the next step is to better understand the patterns in the data. This data analysis helps you choose and develop an appropriate predictive model for your target. Determine how much the data corresponds to the target. Then decide whether your team has sufficient data to move forward with the next modeling steps. Again, this process is often iterative. You might need to find new data sources with more accurate or more relevant data to adjust the dataset initially identified in the previous stage.
Set up a data pipeline
In addition to ingesting and cleaning data, you typically need to set up a process to score new data or refresh the data regularly as part of an ongoing learning process. You can use a data pipeline or workflow to score data. We recommend a pipeline that uses Azure Data Factory.
In this stage, you develop a solution architecture of the data pipeline. You create the pipeline in parallel with the next stage of the data science project. Depending on your business needs and the constraints of your existing systems into which this solution is being integrated, the pipeline can be:
- Batch-based
- Streaming or real time
- Hybrid
Integrate with MLflow
During the data understanding phase, you can use MLflow's experiment tracking to track and document various data preprocessing strategies and exploratory data analysis.
Artifacts
In this stage, your team delivers:
A data quality report that includes data summaries, the relationships between each attribute and target, the variable ranking, and more.
A solution architecture, such as a diagram or description of your data pipeline that your team uses to run predictions on new data. This diagram also contains the pipeline to retrain your model based on new data. When you use the TDSP directory structure template, store the document in the project directory.
A checkpoint decision. Before you begin full-feature engineering and model building, you can reevaluate the project to determine whether the value expected is sufficient to continue pursuing it. You might, for example, be ready to proceed, need to collect more data, or abandon the project if you can't find data that answers the questions.
Peer-reviewed literature
Researchers publish studies about the TDSP in peer-reviewed literature. The citations provide an opportunity to investigate other applications or similar ideas to the TDSP, including the data acquisition and understanding lifecycle stage.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Mark Tabladillo | Senior Cloud Solution Architect
To see non-public LinkedIn profiles, sign in to LinkedIn.
Related resources
These articles describe the other stages of the TDSP lifecycle:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for