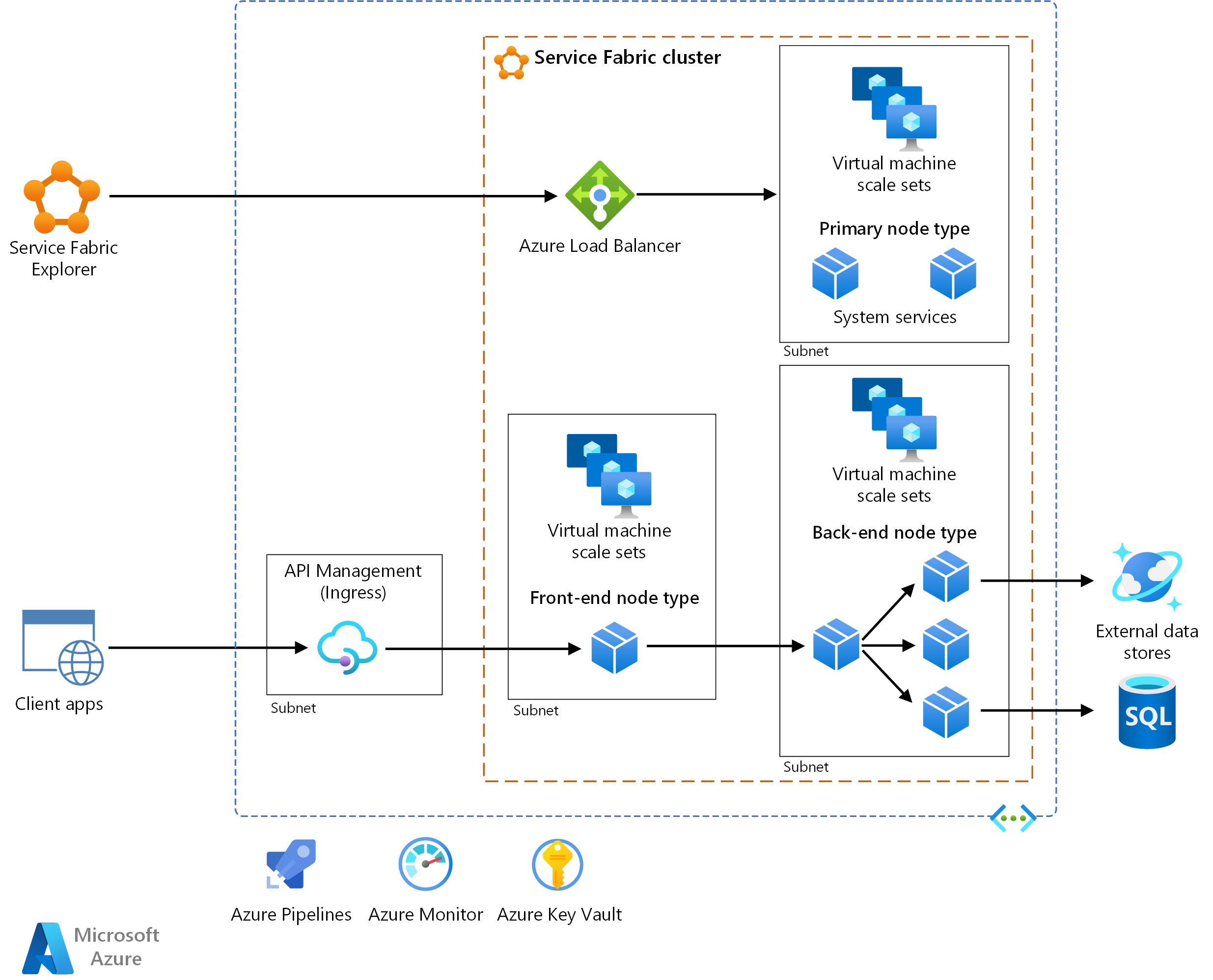
Tato referenční architektura ukazuje architekturu mikroslužeb nasazenou do Azure Service Fabric. Zobrazuje základní konfiguraci clusteru, která může být výchozím bodem pro většinu nasazení.
 Referenční implementace této architektury je k dispozici na GitHubu.
Referenční implementace této architektury je k dispozici na GitHubu.
Architektura
Stáhněte si soubor aplikace Visio s touto architekturou.
Poznámka:
Tento článek se zaměřuje na programovací model Reliable Services pro Service Fabric. Použití Service Fabric k nasazení a správě kontejnerů je nad rámec tohoto článku.
Workflow
Tato architektura se skládá z následujících součástí. Další termíny najdete v přehledu terminologie Service Fabric.
Cluster Service Fabric Cluster je sada virtuálních počítačů připojených k síti, do kterých nasazujete a spravujete mikroslužby.
Škálovací sady virtuálních počítačů Škálovací sady virtuálních počítačů umožňují vytvářet a spravovat skupinu identických virtuálních počítačů s vyrovnáváním zatížení a automatickým škálováním. Tyto výpočetní prostředky také poskytují domény selhání a upgradu.
Uzly. Uzly jsou virtuální počítače, které patří do clusteru Service Fabric.
Typy uzlů. Typ uzlu představuje škálovací sadu virtuálních počítačů, která nasadí kolekci uzlů. Cluster Service Fabric má alespoň jeden typ uzlu.
V clusteru, který má více typů uzlů, musí být deklarován primární typ uzlu. Primární typ uzlu v clusteru spouští systémové služby Service Fabric. Tyto služby poskytují funkce platformy Service Fabric. Primární typ uzlu funguje také jako počáteční uzly, což jsou uzly, které udržují dostupnost základního clusteru.
Nakonfigurujte další typy uzlů pro spouštění služeb.
Služby. Služba provádí samostatnou funkci, která se dá spustit a spustit nezávisle na jiných službách. Instance služeb se nasadí do uzlů v clusteru. Service Fabric má dvě varianty služeb:
- Bezstavová služba. Bezstavová služba ve službě neudržuje stav. Pokud je vyžadována trvalost stavu, zapíše se stav do externího úložiště, jako je například Azure Cosmos DB, a načte se do tohoto úložiště.
- Stavová služba. Stav služby se uchovává v rámci samotné služby. Většina stavových služeb to implementuje prostřednictvím Reliable Collections v Service Fabric.
Service Fabric Explorer. Service Fabric Explorer je opensourcový nástroj pro kontrolu a správu clusterů Service Fabric.
Azure Pipelines. Azure Pipelines je součástí služby Azure DevOps Services a spouští automatizované sestavení, testy a nasazení. Můžete také použít řešení kontinuální integrace a průběžného doručování (CI/CD) třetích stran, jako je Jenkins.
Azure Monitor Azure Monitor shromažďuje a ukládá metriky a protokoly, včetně metrik platformy pro služby Azure v řešení a telemetrii aplikací. Tato data slouží k monitorování aplikace, nastavení výstrah a řídicích panelů a provádění analýzy původní příčiny selhání. Azure Monitor se integruje se Službou Service Fabric za účelem shromažďování metrik z kontrolerů, uzlů a kontejnerů spolu s protokoly kontejnerů a uzlů.
Azure Key Vault. Pomocí služby Key Vault můžete ukládat tajné kódy aplikací, které mikroslužby používají, například připojovací řetězec.
Azure API Management. V této architektuře funguje api Management jako brána rozhraní API, která přijímá požadavky od klientů a směruje je do vašich služeb.
Důležité informace
Tyto aspekty implementují pilíře dobře architektuře Azure, což je sada hlavních principů pro zlepšení kvality úlohy.
Aspekty návrhu
Tato referenční architektura se zaměřuje na architektury mikroslužeb. Mikroslužba je malá nezávislá jednotka kódu s verzí. Je zjistitelné prostřednictvím mechanismů zjišťování služeb a může komunikovat s dalšími službami přes rozhraní API. Každá služba je samostatná a měla by implementovat jednu obchodní schopnost. Další informace o tom, jak dekompilovat doménu aplikace do mikroslužeb, najdete v tématu Použití analýzy domény k modelování mikroslužeb.
Service Fabric poskytuje infrastrukturu pro efektivní sestavování, nasazování a upgrade mikroslužeb. Poskytuje také možnosti automatického škálování, správy stavu, monitorování stavu a restartování služeb v případě selhání.
Service Fabric se řídí aplikačním modelem, ve kterém je aplikace kolekcí mikroslužeb. Aplikace je popsaná v souboru manifestu aplikace. Tento soubor definuje typy služeb, které aplikace obsahuje, spolu s ukazateli na nezávislé balíčky služeb.
Balíček aplikace také obvykle obsahuje parametry, které slouží jako přepsání pro určitá nastavení, která služby používají. Každý balíček služby má soubor manifestu, který popisuje fyzické soubory a složky potřebné ke spuštění této služby, včetně binárních souborů, konfiguračních souborů a dat jen pro čtení. Služby a aplikace jsou nezávisle na verzích a upgradovatelné.
Volitelně může manifest aplikace popisovat služby, které se automaticky zřídí při vytvoření instance aplikace. Tyto služby se nazývají výchozí služby. V tomto případě manifest aplikace také popisuje, jak se mají tyto služby vytvořit. Tyto informace zahrnují název služby, počet instancí, zásady zabezpečení nebo izolace a omezení umístění.
Poznámka:
Pokud chcete řídit životnost služeb, nepoužívejte výchozí služby. Výchozí služby se vytvoří při vytváření aplikace a poběží tak dlouho, dokud je aplikace spuštěná.
Další informace najdete v tématu Chcete se o Service Fabric dozvědět víc?
Model balení aplikačních služeb
Tenet mikroslužeb spočívá v tom, že každou službu je možné nezávisle nasadit. Pokud v Service Fabric seskupíte všechny služby do jednoho balíčku aplikace a jedna služba se nepodaří upgradovat, celý upgrade aplikace se vrátí zpět. Toto vrácení zpět zabraňuje upgradu jiné služby.
Z tohoto důvodu v architektuře mikroslužeb doporučujeme používat více balíčků aplikací. Umístěte jeden nebo více úzce souvisejících typů služeb do jednoho typu aplikace. Pokud například váš tým zodpovídá za sadu služeb, které mají jeden z těchto atributů, vložte typy služeb do stejného typu aplikace:
- Běží po stejnou dobu a musí být aktualizovány současně.
- Mají stejný životní cyklus.
- Sdílejí prostředky, jako jsou závislosti nebo konfigurace.
Programovací modely Service Fabric
Když do aplikace Service Fabric přidáte mikroslužbu, rozhodněte se, jestli má stav nebo data, která musí být vysoce dostupná a spolehlivá. Pokud ano, může data ukládat externě nebo jsou data obsažená jako součást služby? Pokud nepotřebujete ukládat data nebo chcete data ukládat do externího úložiště, zvolte bezstavovou službu. Pokud platí některý z těchto příkazů, zvažte výběr stavové služby:
- V rámci služby chcete udržovat stav nebo data. Například potřebujete, aby se data nacházejí v paměti blízko kódu.
- Závislost na externím úložišti nemůžete tolerovat.
Pokud máte existující kód, který chcete spustit v Service Fabric, můžete ho spustit jako spustitelný soubor hosta: libovolný spustitelný soubor, který běží jako služba. Případně můžete spustitelný soubor zabalit do kontejneru, který má všechny závislosti, které potřebujete pro nasazení.
Service Fabric modeluje kontejnery i spustitelné soubory hosta jako bezstavové služby. Pokyny k výběru modelu najdete v tématu Přehled programovacího modelu Service Fabric.
Zodpovídáte za údržbu prostředí, ve kterém běží spustitelný soubor hosta. Předpokládejme například, že spustitelný soubor hosta vyžaduje Python. Pokud spustitelný soubor není samostatně obsažený, musíte se ujistit, že je v prostředí předinstalovaná požadovaná verze Pythonu. Service Fabric nespravuje prostředí. Azure nabízí několik mechanismů pro nastavení prostředí, včetně vlastních imagí a rozšíření virtuálních počítačů.
Pokud chcete získat přístup ke spustitelnému souboru hosta prostřednictvím reverzního proxy serveru, ujistěte se, že jste do elementu Endpoint v manifestu služby spustitelného souboru hosta přidali UriScheme atribut.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Pokud má služba další trasy, zadejte trasy v hodnotě PathSuffix . Hodnota by neměla mít předponu ani příponu lomítkem (/). Dalším způsobem je přidat trasu do názvu služby.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Další informace naleznete v tématu:
Brána rozhraní API
Brána rozhraní API (příchozí přenos dat) se nachází mezi externími klienty a mikroslužbami. Funguje jako reverzní proxy server a směruje požadavky klientů na mikroslužby. Může také provádět průřezové úlohy, jako je ověřování, ukončení protokolu SSL a omezování rychlosti.
Pro většinu scénářů doporučujeme azure API Management, ale Traefik je oblíbenou opensourcovou alternativou. Obě technologie jsou integrované se Service Fabric.
API Management. Zveřejňuje veřejnou IP adresu a směruje provoz do vašich služeb. Běží ve vyhrazené podsíti ve stejné virtuální síti jako cluster Service Fabric.
Služba API Management má přístup ke službám v typu uzlu, který je vystavený prostřednictvím nástroje pro vyrovnávání zatížení s privátní IP adresou. Tato možnost je dostupná jenom na úrovních Premium a Developer služby API Management. Pro produkční úlohy použijte úroveň Premium. Informace o cenách jsou popsány v cenách služby API Management.
Další informace najdete v tématu Service Fabric s přehledem služby Azure API Management.
Traefik. Podporuje funkce, jako je směrování, trasování, protokoly a metriky. Traefik běží v clusteru Service Fabric jako bezstavová služba. Správu verzí služby je možné podporovat směrováním.
Informace o tom, jak nastavit Traefik pro příchozí přenos dat služby a jako reverzní proxy server v rámci clusteru, najdete na webu Traefik zprostředkovatele Azure Service Fabric. Další informace o používání traefiku se Service Fabric najdete v blogovém příspěvku Intelligent Routing on Service Fabric with Traefik.
Traefik na rozdíl od služby Azure API Management nemá funkce pro překlad oddílu stavové služby (s více než jedním oddílem), do kterého se požadavek směruje. Další informace najdete v tématu Přidání matcheru pro dělení služeb.
Mezi další možnosti správy rozhraní API patří Aplikace Azure Gateway a Azure Front Door. Tyto služby můžete používat ve spojení se službou API Management k provádění úloh, jako je směrování, ukončení protokolu SSL a brána firewall.
Komunikace mezi službami
Pokud chcete usnadnit komunikaci mezi službami, zvažte následující doporučení:
Komunikační protokol. V architektuře mikroslužeb musí služby vzájemně komunikovat s minimálním párovým spojením za běhu. Aby bylo možné povolit komunikaci nezávislou na jazyce, je HTTP oborovým standardem s širokou škálou nástrojů a serverů HTTP, které jsou dostupné v různých jazycích. Service Fabric podporuje všechny tyto nástroje a servery.
U většiny úloh doporučujeme místo vzdálené komunikace služby, která je integrovaná do Service Fabric, používat protokol HTTP.
Zjišťování služeb. Pro komunikaci s jinými službami v clusteru musí klientská služba přeložit aktuální umístění cílové služby. Ve službě Service Fabric se služby můžou přesouvat mezi uzly a dynamicky se měnit koncové body služby.
Abyste se vyhnuli připojení k zastaralým koncovým bodům, můžete pomocí služby pojmenování ve službě Service Fabric načíst aktualizované informace o koncovém bodu. Service Fabric ale také poskytuje integrovanou službu reverzního proxy serveru , která abstrahuje službu pojmenování. Tuto možnost doporučujeme pro zjišťování služeb jako směrný plán pro většinu scénářů, protože je jednodušší používat a výsledkem je jednodušší kód.
Mezi další možnosti komunikace mezi službami patří:
- Traefik pro pokročilé směrování.
- DNS pro scénáře kompatibility, kdy služba očekává použití DNS.
- ServicePartitionClient TCommunicationClient<> třída, která ukládá koncové body služby do mezipaměti. Může umožnit lepší výkon, protože volání procházejí přímo mezi službami bez zprostředkovatelů nebo vlastních protokolů.
Škálovatelnost
Service Fabric podporuje škálování těchto entit clusteru:
- Škálování počtu uzlů pro každý typ uzlu
- Škálování služeb
Tato část se zaměřuje na automatické škálování. V situacích, kdy je to vhodné, můžete ručně škálovat. Například ruční zásah může být nutný k nastavení počtu instancí.
Počáteční konfigurace clusteru pro škálovatelnost
Při vytváření clusteru Service Fabric zřiďte typy uzlů na základě potřeb zabezpečení a škálovatelnosti. Každý typ uzlu se mapuje na škálovací sadu virtuálních počítačů a dá se škálovat nezávisle.
- Vytvořte typ uzlu pro každou skupinu služeb, které mají různé požadavky na škálovatelnost nebo prostředky. Začněte zřízením typu uzlu (který se stane primárním typem uzlu) pro systémové služby Service Fabric. Vytvořte samostatné typy uzlů pro spouštění veřejných nebo front-endových služeb. Podle potřeby vytvořte další typy uzlů pro back-end a privátní nebo izolované služby. Určete omezení umístění tak, aby byly služby nasazeny pouze do zamýšlených typů uzlů.
- Zadejte úroveň stálosti pro každý typ uzlu. Úroveň stálosti představuje schopnost Service Fabric ovlivnit operace aktualizace a údržby ve škálovacích sadách virtuálních počítačů. Pro produkční úlohy zvolte úroveň silver nebo vyšší stálost. Informace o jednotlivých úrovních najdete v tématu Vlastnosti stálosti clusteru.
- Pokud používáte úroveň bronzové odolnosti, některé operace vyžadují ruční kroky. Typy uzlů s bronzovou úrovní odolnosti vyžadují další kroky během horizontálního snížení kapacity. Další informace o operacích škálování najdete v této příručce.
Škálování uzlů
Service Fabric podporuje automatické škálování pro horizontální navýšení kapacity a horizontální navýšení kapacity. Každý typ uzlu můžete nakonfigurovat pro automatické škálování nezávisle.
Každý typ uzlu může mít maximálně 100 uzlů. Začněte menší sadou uzlů a v závislosti na zatížení přidejte další uzly. Pokud v typu uzlu potřebujete více než 100 uzlů, budete muset přidat další typy uzlů. Podrobnosti najdete v tématu Aspekty plánování kapacity clusteru Service Fabric. Škálovací sada virtuálních počítačů se okamžitě neškálí, proto při nastavování pravidel automatického škálování zvažte tento faktor.
Pokud chcete podporovat automatické škálování, nakonfigurujte typ uzlu tak, aby měl úroveň stálosti Silver nebo Gold. Tato konfigurace zajišťuje, že škálování je zpožděné, dokud Service Fabric nedokončí opětovné přidělení služeb. Také zajišťuje, aby škálovací sady virtuálních počítačů informovaly Service Fabric, že se virtuální počítače odeberou, nejen dočasně.
Další informace o škálování na úrovni uzlu nebo clusteru najdete v tématu Škálování clusterů Azure Service Fabric.
Škálování služeb
Bezstavové a stavové služby používají různé přístupy ke škálování.
Pro bezstavovou službu (automatické škálování):
- Použijte trigger průměrného zatížení oddílu. Tento trigger určuje, kdy se služba škáluje nebo odsadí, na základě prahové hodnoty zatížení, která je zadaná v zásadách škálování. Můžete také nastavit, jak často se trigger kontroluje. Viz Trigger průměrného zatížení oddílů se škálováním na základě instance. Tento přístup umožňuje vertikálně navýšit kapacitu až na počet dostupných uzlů.
- V manifestu služby nastavte
InstanceCounthodnotu -1, která service Fabric říká, aby spustila instanci služby na každém uzlu. Tento přístup umožňuje službě dynamicky škálovat při škálování clusteru. S tím, jak se počet uzlů v clusteru změní, Service Fabric automaticky vytvoří a odstraní instance služby, které se mají shodovat.
Poznámka:
V některých případech můžete chtít službu škálovat ručně. Pokud máte například službu, která čte ze služby Azure Event Hubs, můžete chtít, aby vyhrazená instance četla z každého oddílu centra událostí. Tímto způsobem se můžete vyhnout souběžnému přístupu k oddílu.
U stavové služby se škálování řídí počtem oddílů, velikostí každého oddílu a počtem oddílů nebo replik spuštěných na počítači:
Pokud vytváříte dělené služby, ujistěte se, že každý uzel získá odpovídající repliky pro rovnoměrnou distribuci úlohy, aniž by to způsobilo kolize prostředků. Pokud přidáte další uzly, Service Fabric distribuuje úlohy do nových počítačů ve výchozím nastavení. Pokud je například 5 uzlů a 10 oddílů, Service Fabric ve výchozím nastavení umístí na každý uzel dvě primární repliky. Pokud škálujete uzly na více instancí, můžete dosáhnout vyššího výkonu, protože práce se rovnoměrně distribuuje mezi více prostředků.
Informace o scénářích, které tuto strategii využívají, najdete v tématu Škálování v Service Fabric.
Přidávání nebo odebírání oddílů není dobře podporované. Další možností, která se běžně používá ke škálování, je dynamické vytváření nebo odstraňování služeb nebo celých instancí aplikace. Příklad tohoto modelu je popsaný ve škálování vytvořením nebo odebráním nových pojmenovaných služeb.
Další informace naleznete v tématu:
- Horizontální navýšení nebo snížení kapacity clusteru Service Fabric pomocí pravidel automatického škálování nebo ručně
- Programové škálování clusteru Service Fabric
- Horizontální navýšení kapacity clusteru Service Fabric přidáním škálovací sady virtuálních počítačů
Vyrovnávání zatížení s využitím metrik
V závislosti na způsobu návrhu oddílu můžete mít uzly s replikami, které získají větší provoz než ostatní. Pokud se chcete této situaci vyhnout, rozdělte stav služby tak, aby se distribuoval napříč všemi oddíly. Použijte schéma dělení rozsahu s dobrým hashovacím algoritmem. Viz Začínáme s dělením.
Service Fabric používá metriky k tomu, aby věděla, jak umístit a vyvážit služby v rámci clusteru. Můžete zadat výchozí zatížení pro každou metriku přidruženou ke službě při vytváření této služby. Service Fabric pak vezme toto zatížení v úvahu při umísťování služby nebo pokaždé, když se služba musí přesunout (například během upgradů), aby se uzly v clusteru vyrovnaly.
Počáteční zadané výchozí zatížení služby se po celou dobu životnosti služby nezmění. Pokud chcete zachytit měnící se metriky pro službu, doporučujeme službu monitorovat a pak nahlásit zatížení dynamicky. Tento přístup umožňuje Službě Service Fabric upravit přidělení na základě ohlášeného zatížení v daném okamžiku. K vytváření vlastních metrik použijte metodu IServicePartition.ReportLoad . Další informace naleznete v tématu Dynamické načítání.
Dostupnost
Umístěte služby do jiného typu uzlu, než je primární typ uzlu. Systémové služby Service Fabric se vždy nasazují do primárního typu uzlu. Pokud jsou vaše služby nasazené do primárního typu uzlu, můžou soutěžit se systémovými službami pro prostředky (a narušovat je). Pokud se očekává, že typ uzlu bude hostovat stavové služby, ujistěte se, že existuje alespoň pět instancí uzlů a že vyberete úroveň Stálost silver nebo Gold.
Zvažte omezení prostředků vašich služeb. Viz mechanismus zásad správného řízení prostředků.
Tady jsou běžné aspekty:
- Nekombinujte služby, které jsou řízeny prostředky, a služby, které nejsou prostředky řízené stejným typem uzlu. Neřídící služby můžou spotřebovávat příliš mnoho prostředků a ovlivnit řízené služby. Zadejte omezení umístění, abyste měli jistotu, že se tyto typy služeb nespustí na stejné sadě uzlů. (Toto je příklad Vzor přepíná hlavy.)
- Zadejte jádra procesoru a paměť, které se mají rezervovat pro instanci služby. Informace o používání a omezeních zásad správného řízení prostředků najdete v tématu Zásady správného řízení prostředků.
Abyste se vyhnuli jedinému bodu selhání (SPOF), ujistěte se, že je počet cílových instancí nebo replik služby větší než jeden. Největší číslo, které můžete použít jako instanci služby nebo počet replik, se rovná počtu uzlů, které službu omezují.
Ujistěte se, že každá stavová služba má aspoň dvě aktivní sekundární repliky. Pro produkční úlohy doporučujeme pět replik.
Další informace najdete v tématu Dostupnost služeb Service Fabric.
Zabezpečení
Zabezpečení poskytuje záruky proti záměrným útokům a zneužití cenných dat a systémů. Další informace najdete v tématu Přehled pilíře zabezpečení.
Tady je několik klíčových bodů zabezpečení vaší aplikace v Service Fabric.
Virtuální síť
Zvažte definování hranic podsítí pro každou škálovací sadu virtuálních počítačů za účelem řízení toku komunikace. Každý typ uzlu má vlastní škálovací sadu virtuálních počítačů v podsíti ve virtuální síti clusteru Service Fabric. Do podsítí můžete přidat skupiny zabezpečení sítě (NSG), které povolí nebo zamítnou síťový provoz. Například u front-endových a back-endových typů uzlů můžete do back-endové podsítě přidat skupinu zabezpečení sítě a přijímat příchozí provoz jenom z front-endové podsítě.
Pokud voláte externí služby Azure z clusteru, použijte koncové body služeb virtuální sítě, pokud ji služba Azure podporuje. Použití koncového bodu služby zabezpečuje službu pouze pro virtuální síť clusteru.
Pokud například k ukládání dat používáte Službu Azure Cosmos DB, nakonfigurujte účet služby Azure Cosmos DB s koncovým bodem služby tak, aby umožňoval přístup pouze z konkrétní podsítě. Viz Přístup k prostředkům Azure Cosmos DB z virtuálních sítí.
Koncové body a komunikace mezi službami
Nevytvávejte nezabezpečený cluster Service Fabric. Pokud cluster zveřejňuje koncové body správy pro veřejný internet, můžou se k němu anonymní uživatelé připojit. Nezabezpečené clustery nejsou podporovány pro produkční úlohy. Viz scénáře zabezpečení clusteru Service Fabric.
Pomoc se zabezpečením komunikace mezi službami:
- Zvažte povolení koncových bodů HTTPS ve webových službách ASP.NET Core nebo Java.
- Vytvořte zabezpečené připojení mezi reverzním proxy serverem a službami. Podrobnosti najdete v tématu Připojení k zabezpečené službě.
Pokud používáte bránu rozhraní API, můžete přesměrovat ověřování na bránu. Ujistěte se, že jednotlivé služby nejsou dostupné přímo (bez brány rozhraní API), pokud není k ověření zpráv zavedeno další zabezpečení.
Nezpřístupňujte reverzní proxy Service Fabric veřejně. Tím způsobíte, že všechny služby, které zpřístupňují koncové body HTTP, budou adresovatelné mimo cluster. To způsobí ohrožení zabezpečení a potenciálně zbytečně zpřístupní další informace mimo cluster. Pokud chcete přistupovat ke službě veřejně, použijte bránu rozhraní API. Část Brána rozhraní API dále v tomto článku uvádí některé možnosti.
Vzdálená plocha je užitečná pro diagnostiku a řešení potíží, ale nezapomeňte ji zavřít. Ponechání otevřeného otvoru způsobí bezpečnostní díru.
Tajné kódy a certifikáty
Ukládejte tajné kódy, jako jsou připojovací řetězec do úložišť dat, v trezoru klíčů. Trezor klíčů musí být ve stejné oblasti jako škálovací sada virtuálních počítačů. Použití trezoru klíčů:
Ověřte přístup služby k trezoru klíčů.
Povolte spravovanou identitu ve škálovací sadě virtuálních počítačů, která je hostitelem služby.
Ukládejte tajné kódy do trezoru klíčů.
Přidejte tajné kódy ve formátu, který lze přeložit do páru klíč/hodnota. Například použijte
CosmosDB--AuthKey. Při sestavení konfigurace se dvojitá pomlčka (--) převede na dvojtečku (:).Získejte přístup k těmto tajným kódům ve vaší službě.
Přidejte do aplikace identifikátor URI trezoru klíčů Nastavení.json. Ve vaší službě přidejte zprostředkovatele konfigurace, který čte z trezoru klíčů, sestaví konfiguraci a přistupuje k tajnému kódu z sestavené konfigurace.
Tady je příklad, ve kterém služba Pracovního postupu ukládá tajný kód do trezoru klíčů ve formátu CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Pokud chcete získat přístup k tajnému kódu, zadejte název tajného kódu v předdefinované konfiguraci.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Nepoužívejte klientské certifikáty pro přístup k Service Fabric Exploreru. Místo toho použijte ID Microsoft Entra. Podívejte se na služby Azure, které podporují ověřování Microsoft Entra.
Nepoužívejte certifikáty podepsané svým držitelem pro produkční prostředí.
Ochrana neaktivních uložených dat
Pokud jste datové disky připojili ke škálovacím sadám virtuálních počítačů clusteru Service Fabric a služby na tyto disky ukládají data, musíte disky zašifrovat. Další informace najdete v tématu Šifrování operačního systému a připojených datových disků ve škálovací sadě virtuálních počítačů pomocí Azure PowerShellu (Preview).
Další informace o zabezpečení Service Fabric najdete tady:
- Přehled zabezpečení Azure Service Fabric
- Osvědčené postupy zabezpečení Azure Service Fabric
- Kontrolní seznam zabezpečení Azure Service Fabric
Odolnost
Aby se aplikace mohla zotavit z selhání a zachovat plně funkční stav, musí implementovat určité vzorce odolnosti. Tady jsou některé běžné vzory:
- Opakování: Zpracování chyb, u kterých očekáváte, že budou přechodné, například prostředky, které jsou dočasně nedostupné.
- Jistič: Řešení chyb, které můžou trvat déle, než se opraví.
- Bulkhead: Izolace prostředků pro každou službu.
Tato referenční implementace používá Polly, opensourcovou možnost, k implementaci všech těchto vzorů.
Sledování
Než prozkoumáte možnosti monitorování, doporučujeme přečíst si tento článek o diagnostice běžných scénářů pomocí Service Fabric. Data monitorování si můžete představit v těchto sadách:
- Metriky a protokoly aplikací
- Data o stavu a událostech Service Fabric
- Metriky a protokoly infrastruktury
- Metriky a protokoly pro závislé služby
Toto jsou dvě hlavní možnosti analýzy těchto dat:
- Application Insights
- Log Analytics
Azure Monitor můžete použít k nastavení řídicích panelů pro monitorování a odesílání upozornění operátorům. Některé monitorovací nástroje třetích stran jsou také integrované s Service Fabric, například Dynatrace. Podrobnosti najdete v tématu o monitorovacích partnerech Azure Service Fabric.
Metriky a protokoly aplikací
Telemetrie aplikací poskytuje data, která vám můžou pomoct monitorovat stav vaší služby a identifikovat problémy. Přidání trasování a událostí ve službě:
- Pokud vyvíjíte službu pomocí ASP.NET Core, použijte Microsoft.Extensions.Logging . Pro jiné architektury použijte knihovnu protokolování podle vašeho výběru, například Serilog.
- Přidejte vlastní instrumentaci pomocí třídy TelemetryClient v sadě SDK a zobrazte data v Přehledy aplikace. Viz Přidání vlastní instrumentace do aplikace.
- Protokolování událostí trasování událostí pro Windows (ETW) pomocí EventSource. Tato možnost je ve výchozím nastavení dostupná v řešení Service Fabric sady Visual Studio.
Aplikační Přehledy poskytuje mnoho předdefinovaných telemetrických dat: požadavky, trasování, události, výjimky, metriky, závislosti. Pokud vaše služba zveřejňuje koncové body HTTP, povolte aplikační Přehledy voláním UseApplicationInsights metody rozšíření pro Microsoft.AspNetCore.Hosting.IWebHostBuilder. Informace o instrumentaci služby pro Přehledy aplikací najdete v těchto článcích:
- Kurz: Monitorování a diagnostika aplikace ASP.NET Core ve službě Service Fabric pomocí aplikačních Přehledy
- Application Insights pro ASP.NET Core
- Application Přehledy .NET SDK
- Sada Application Přehledy SDK pro Service Fabric
Pokud chcete zobrazit trasování a protokoly událostí, použijte k strukturovanému protokolování Přehledy aplikace. Nakonfigurujte aplikační Přehledy pomocí instrumentačního klíče voláním AddApplicationInsights metody rozšíření. V tomto příkladu se instrumentační klíč uloží jako tajný klíč v trezoru klíčů.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Pokud vaše služba nezpřístupňuje koncové body HTTP, musíte napsat vlastní rozšíření, které odesílá trasování do aplikace Přehledy. Příklad najdete ve službě Workflow v referenční implementaci.
ASP.NET služby Core používají pro protokolování aplikace rozhraní ILogger. Pokud chcete tyto protokoly aplikací zpřístupnit ve službě Azure Monitor, odešlete ILogger události do Přehledy aplikace. Aplikační Přehledy může do událostí přidat vlastnosti ILogger korelace, což je užitečné pro vizualizaci distribuovaného trasování.
Další informace naleznete v tématu:
Data o stavu a událostech Service Fabric
Telemetrie Service Fabric zahrnuje metriky stavu a události týkající se provozu a výkonu clusteru Service Fabric a jejích entit: uzly, aplikace, služby, oddíly a repliky. Data o stavu a událostech můžou pocházet z:
EventStore. Tato stavová systémová služba shromažďuje události související s clusterem a jejími entitami. Service Fabric používá EventStore k zápisu událostí Service Fabric k poskytování informací o clusteru pro aktualizace stavu, řešení potíží a monitorování. EventStore může také korelovat události z různých entit v daném okamžiku za účelem identifikace problémů v clusteru. Služba tyto události zveřejňuje prostřednictvím rozhraní REST API.
Informace o dotazování rozhraní EventStore API naleznete v tématu Dotazování rozhraní EventStore API pro události clusteru. Události z EventStore v Log Analytics můžete zobrazit konfigurací clusteru s rozšířením Azure Diagnostics pro Windows (WAD).
HealthStore. Tato stavová služba poskytuje snímek aktuálního stavu clusteru. Agreguje všechna data o stavu hlášená entitami v hierarchii. Data se vizualizují v Service Fabric Exploreru. HealthStore také monitoruje upgrady aplikací. Dotazy na stav můžete použít v PowerShellu, aplikaci .NET nebo rozhraní REST API. Viz Úvod do monitorování stavu Service Fabric.
Vlastní sestavy o stavu Zvažte implementaci interních sledovacích služeb, které můžou pravidelně hlásit vlastní data o stavu, jako jsou chybné stavy spuštěných služeb. Sestavy stavu si můžete přečíst v Service Fabric Exploreru.
Metriky a protokoly infrastruktury
Metriky infrastruktury vám pomůžou porozumět přidělování prostředků v clusteru. Tady jsou hlavní možnosti shromažďování těchto informací:
- WAD. Shromážděte protokoly a metriky na úrovni uzlu ve Windows. WAD můžete použít tak, že nakonfigurujete rozšíření virtuálních počítačů IaaSDiagnostics v libovolné škálovací sadě virtuálních počítačů, která je namapovaná na typ uzlu pro shromažďování diagnostických událostí. Tyto události můžou zahrnovat protokoly událostí Windows, čítače výkonu, systém trasování událostí pro Windows a operační události a vlastní protokoly.
- Agent Log Analytics Nakonfigurujte rozšíření virtuálního počítače MicrosoftMonitoringAgent tak, aby do Log Analytics odesílaly protokoly událostí Windows, čítače výkonu a vlastní protokoly.
V typech metrik shromážděných pomocí předchozích mechanismů, jako jsou čítače výkonu, se některé překrývají. Pokud se překrývají, doporučujeme použít agenta Log Analytics. Vzhledem k tomu, že agent Log Analytics nepoužívá úložiště Azure, je latence nízká. Čítače výkonu v IaaSDiagnostics se také nedají snadno do Log Analytics pouštět.
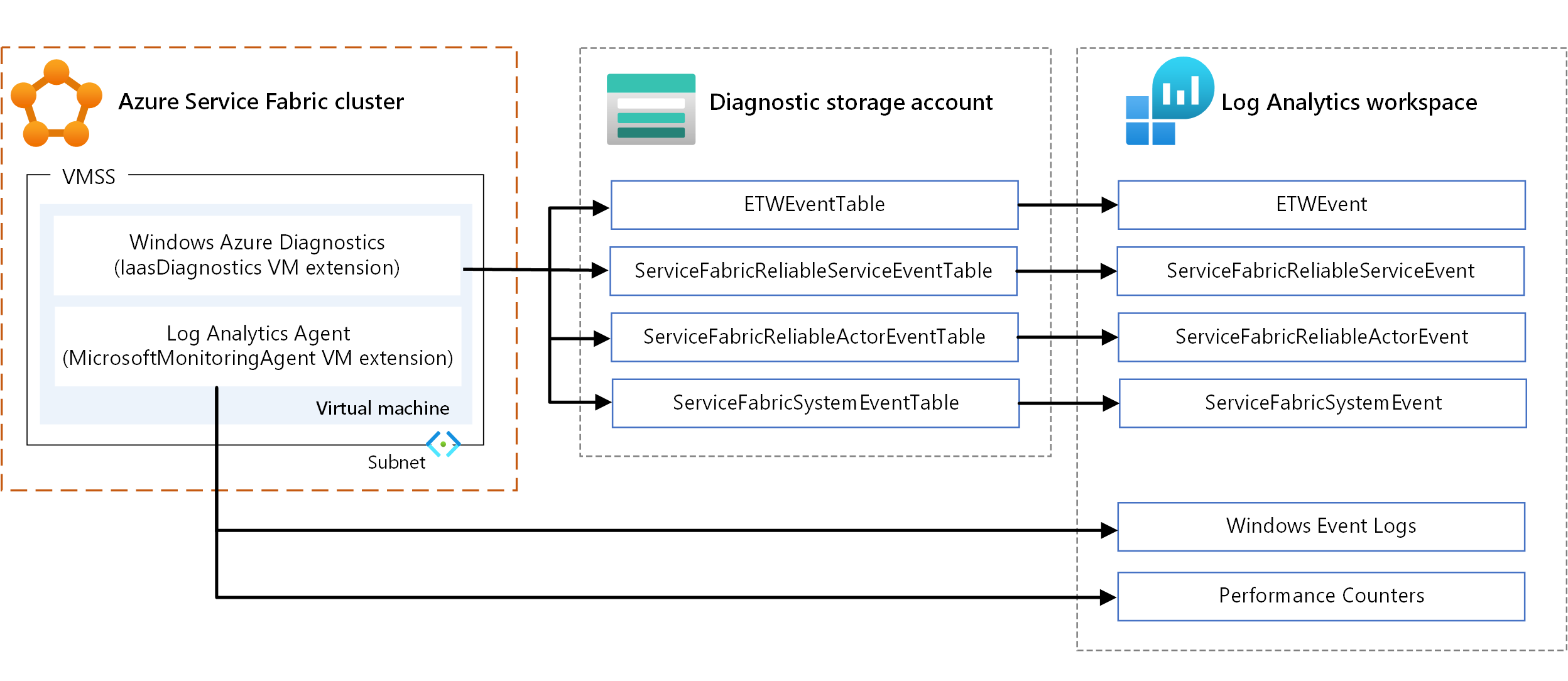
Informace o používání rozšíření virtuálních počítačů najdete v tématu Rozšíření a funkce virtuálních počítačů Azure.
Pokud chcete zobrazit data, nakonfigurujte Log Analytics tak, aby zobrazovala data shromážděná prostřednictvím WAD. Informace o tom, jak nakonfigurovat Log Analytics pro čtení událostí z účtu úložiště, najdete v tématu Nastavení Log Analytics pro cluster.
Můžete také zobrazit protokoly výkonu a telemetrická data související s clusterem Service Fabric, úlohami, síťovým provozem, čekajícími aktualizacemi a dalšími informacemi. Viz Monitorování výkonu pomocí Log Analytics.
Řešení Service Map v Log Analytics poskytuje informace o topologii clusteru (to znamená procesy spuštěné v jednotlivých uzlech). Odešlete data v účtu úložiště do Přehledy aplikace. Při načítání dat do aplikace Přehledy může dojít ke zpoždění. Pokud chcete zobrazit data v reálném čase, zvažte konfiguraci služby Event Hubs pomocí jímek a kanálů. Další informace najdete v tématu Agregace a shromažďování událostí pomocí WAD.
Metriky závislé služby
- Mapa aplikace v aplikaci Přehledy poskytuje topologii aplikace pomocí volání závislostí HTTP provedených mezi službami s nainstalovanou sadou Application Přehledy SDK.
- Service Map v Log Analytics poskytuje informace o příchozím a odchozím provozu z externích služeb a do externích služeb. Service Map se integruje s jinými řešeními, jako jsou aktualizace nebo zabezpečení.
- Vlastní watchdogs můžou hlásit chybové stavy u externích služeb. Služba může například poskytnout zprávu o stavu chyby, pokud nemá přístup k externí službě nebo úložišti dat (Azure Cosmos DB).
Distribuované trasování
V architektuře mikroslužeb se k dokončení úlohy často účastní několik služeb. Telemetrie z každé z těchto služeb koreluje prostřednictvím kontextových polí (jako je ID operace a ID požadavku) v distribuovaném trasování.
Pomocí mapy aplikace v Přehledy aplikace můžete vytvořit zobrazení distribuovaných logických operací a vizualizovat celý graf služby vaší aplikace. K korelaci telemetrie na straně serveru můžete také použít diagnostiku transakcí v aplikačním Přehledy. Další informace naleznete v tématu Unified cross-component transaction diagnostics.
Je také důležité korelovat úlohy, které se odesílají asynchronně pomocí fronty. Podrobnosti o odesílání telemetrie korelace ve zprávě fronty najdete v tématu Instrumentace fronty.
Další informace naleznete v tématu:
Výstrahy a řídicí panely
Aplikace Přehledy a Log Analytics podporují rozsáhlý dotazovací jazyk (dotazovací jazyk Kusto), který umožňuje načíst a analyzovat data protokolu. Pomocí dotazů můžete vytvářet datové sady a vizualizovat je na řídicích panelech diagnostiky.
Pomocí upozornění služby Azure Monitor můžete upozornit správce systému, když dojde k určitým podmínkám v konkrétních prostředcích. Oznámení může být například e-mail, funkce Azure nebo webhook. Další informace najdete v tématu Upozornění ve službě Azure Monitor.
Pravidla upozornění prohledávání protokolů umožňují v pravidelných intervalech definovat a spouštět dotaz Kusto na pracovní prostor služby Log Analytics. Pokud výsledek dotazu odpovídá určité podmínce, vytvoří se upozornění.
Optimalizace nákladů
K odhadu nákladů použijte cenovou kalkulačku Azure. Další aspekty jsou popsané v pilíři optimalizace nákladů v architektuře Microsoft Azure Well-Architected Framework.
Tady je několik bodů, které je potřeba zvážit u některých služeb používaných v této architektuře.
Azure Service Fabric
Účtují se vám poplatky za výpočetní instance, úložiště, síťové prostředky a IP adresy, které zvolíte při vytváření clusteru Service Fabric. Za Service Fabric se účtují poplatky za nasazení.
Škálovací sady virtuálních počítačů
V této architektuře se mikroslužby nasazují do uzlů, které jsou škálovací sady virtuálních počítačů. Účtují se vám poplatky za virtuální počítače Azure nasazené v rámci clusteru a základních prostředků infrastruktury, jako jsou úložiště a sítě. Za samotné škálovací sady virtuálních počítačů se neúčtují žádné přírůstkové poplatky.
Azure API Management
Azure API Management je brána pro směrování požadavků z klientů do služeb v clusteru.
K dispozici jsou různé cenové možnosti. Možnost Consumption se účtuje na základě plateb za použití a zahrnuje komponentu brány. Na základě vaší úlohy zvolte možnost popsanou v cenách služby API Management.
Application Insights
Application Přehledy můžete použít ke shromažďování telemetrie pro všechny služby a k zobrazení trasování a protokolů událostí strukturovaným způsobem. Ceny pro Přehledy aplikací je model průběžných plateb založený na ingestované objemu dat a možnostech uchovávání dat. Další informace najdete v tématu Správa využití a nákladů pro Přehledy aplikace.
Azure Monitor
Pro Azure Monitor Log Analytics se vám účtují poplatky za příjem a uchovávání dat. Další informace najdete v tématu o cenách služby Azure Monitor.
Azure Key Vault
Pomocí služby Azure Key Vault uložíte instrumentační klíč pro aplikaci Přehledy jako tajný klíč. Azure nabízí Key Vault ve dvou úrovních služby. Pokud nepotřebujete klíče chráněné modulem HSM, zvolte úroveň Standard. Informace o funkcích v jednotlivých úrovních najdete v tématu Ceny služby Key Vault.
Služby Azure DevOps
Tato referenční architektura používá azure Pipelines k nasazení. Služba Azure Pipelines umožňuje bezplatnou úlohu hostované Microsoftem s 1 800 minutami za měsíc pro CI/CD a jednu úlohu v místním prostředí s neomezeným počtem minut za měsíc. Za další úlohy se účtují poplatky. Další informace najdete v tématu Azure DevOps Services – ceny.
Důležité informace o DevOps v architektuře mikroslužeb najdete v tématu CI/CD pro mikroslužby.
Informace o nasazení aplikace kontejneru s CI/CD do clusteru Service Fabric najdete v tomto kurzu.
Nasazení tohoto scénáře
Pokud chcete nasadit referenční implementaci pro tuto architekturu, postupujte podle kroků v úložišti GitHub.
Další kroky
- Školení: Úvod do Azure Service Fabric
- Přehled Azure Service Fabric
- Dokumentace ke službě API Management
- Co je Azure Pipelines?