Tato referenční architektura ukazuje, jak provádět dávkové bodování s modely R pomocí služby Azure Batch. Azure Batch dobře funguje s vnitřně paralelními úlohami a zahrnuje plánování úloh a správu výpočetních prostředků. Dávkové odvozování (bodování) se běžně používá k segmentování zákazníků, prognózování prodeje, predikci chování zákazníků, predikci údržby nebo zlepšení kybernetického zabezpečení.
Stáhněte si soubor aplikace Visio s touto architekturou.
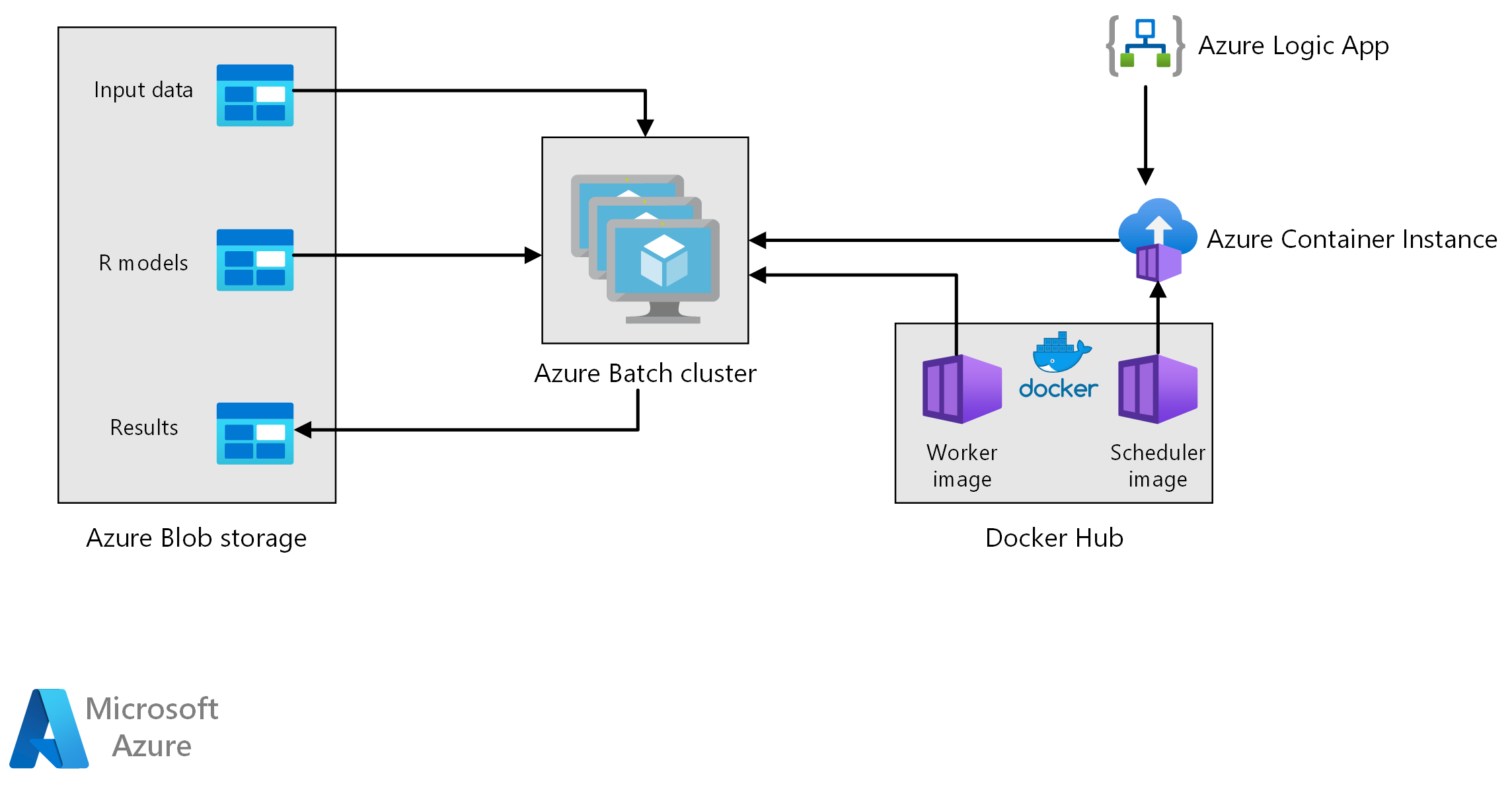
Workflow
Tato architektura se skládá z následujících komponent.
Azure Batch spouští úlohy generování prognóz paralelně na clusteru virtuálních počítačů. Předpovědi se provádějí pomocí předem natrénovaných modelů strojového učení implementovaných v R. Azure Batch může automaticky škálovat počet virtuálních počítačů na základě počtu úloh odeslaných do clusteru. Na každém uzlu se skript jazyka R spustí v kontejneru Dockeru, který vyhodnotí data a vygeneruje prognózy.
Azure Blob Storage ukládá vstupní data, předem natrénované modely strojového učení a výsledky prognózy. Poskytuje nákladově efektivní úložiště pro výkon, který tato úloha vyžaduje.
Azure Container Instances poskytuje bezserverové výpočetní prostředky na vyžádání. V tomto případě se instance kontejneru nasadí podle plánu, který aktivuje úlohy Batch, které vygenerují prognózy. Úlohy Batch se aktivují ze skriptu jazyka R pomocí balíčku doAzureParallel . Instance kontejneru se po dokončení úloh automaticky vypne.
Azure Logic Apps aktivuje celý pracovní postup nasazením instancí kontejneru podle plánu. Konektor Azure Container Instances v Logic Apps umožňuje nasazení instance na celou řadu aktivačních událostí.
Komponenty
Podrobnosti řešení
I když je následující scénář založený na prognózování prodeje maloobchodního obchodu, jeho architektura se dá zobecnit pro všechny scénáře vyžadující generování předpovědí ve větším měřítku pomocí modelů R. Referenční implementace pro tuto architekturu je k dispozici na GitHubu.
Potenciální případy použití
Řetězec supermarketu musí předpovědět prodej produktů v nadcházejícím čtvrtletí. Prognóza umožňuje společnosti lépe spravovat svůj dodavatelský řetězec a zajistit, aby dokázala splnit poptávku po produktech v každém obchodě. Společnost aktualizuje své prognózy každý týden, protože nová prodejní data z předchozího týdne budou k dispozici a strategie marketingu produktů pro příští čtvrtletí je nastavená. Quantile prognózy se generují k odhadu nejistoty jednotlivých prognóz prodeje.
Zpracování zahrnuje následující kroky:
Aplikace logiky Azure aktivuje proces generování prognóz jednou týdně.
Aplikace logiky spustí instanci kontejneru Azure Container Instance, která spouští kontejner Dockeru plánovače, který aktivuje úlohy vyhodnocování v clusteru Batch.
Úlohy vyhodnocování běží paralelně napříč uzly clusteru Batch. Každý uzel:
Načte image Dockeru pracovního procesu a spustí kontejner.
Čte vstupní data a předem natrénované modely R z úložiště objektů blob v Azure.
Vyhodnocí data, aby se vytvořily prognózy.
Zapíše výsledky prognózy do úložiště objektů blob.
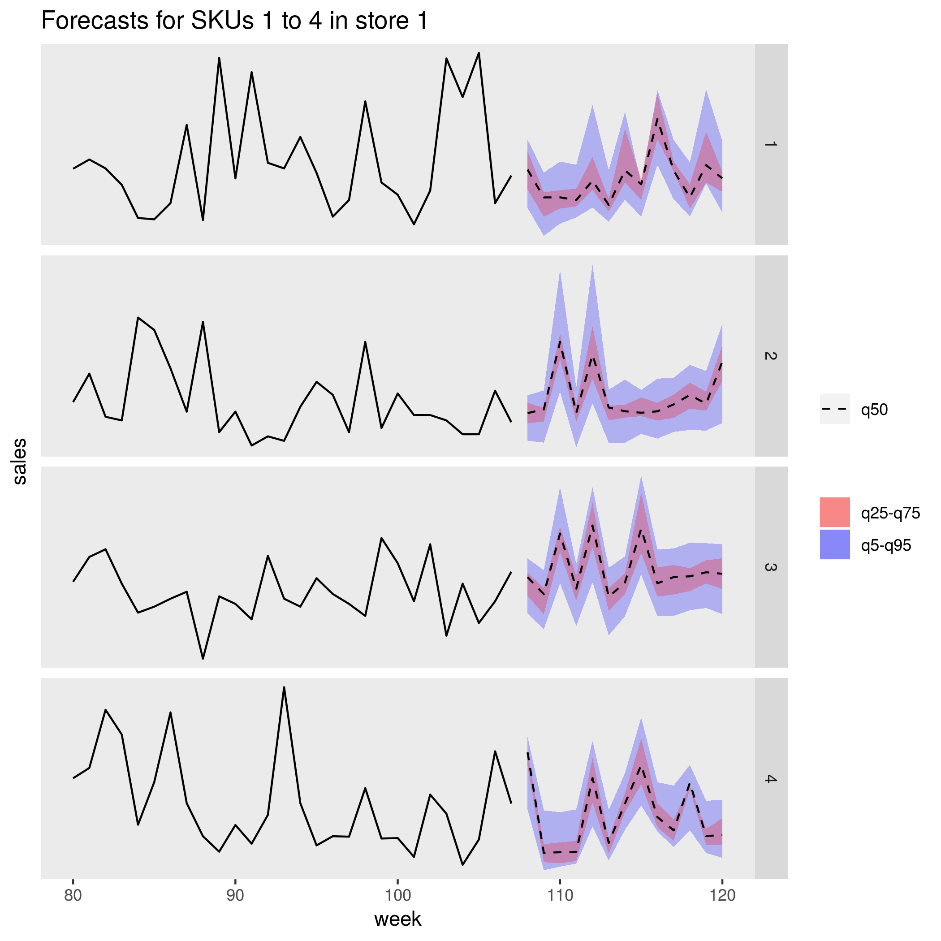
Následující obrázek znázorňuje předpokládané prodeje pro čtyři produkty (SKU) v jednom obchodě. Černá čára je historie prodeje, přerušovaná čára je mediánem (q50), růžová pruh představuje 25. a 75. percentil a modrý pruh představuje 50. a 95. percentil.
Důležité informace
Tyto aspekty implementují pilíře dobře architektuře Azure, což je sada hlavních principů, které je možné použít ke zlepšení kvality úlohy. Další informace naleznete v tématu Microsoft Azure Well-Architected Framework.
Výkon
Kontejnerizované nasazení
V této architektuře se všechny skripty R spouštějí v kontejnerech Dockeru . Použití kontejnerů zajišťuje, aby se skripty spouštěly v konzistentním prostředí pokaždé se stejnou verzí R a verzemi balíčků. Samostatné image Dockeru se používají pro plánovač a kontejnery pracovních procesů, protože každá z nich má jinou sadu závislostí balíčku R.
Azure Container Instances poskytuje bezserverové prostředí pro spuštění kontejneru plánovače. Kontejner plánovače spouští skript jazyka R, který aktivuje jednotlivé úlohy vyhodnocování spuštěné v clusteru Azure Batch.
Každý uzel clusteru Batch spouští pracovní kontejner, který spouští bodovací skript.
Paralelizace úlohy
Při dávkovém bodování dat pomocí modelů R zvažte, jak paralelizovat úlohu. Vstupní data musí být rozdělená na oddíly, aby bylo možné operaci bodování distribuovat napříč uzly clusteru. Vyzkoušejte různé přístupy, abyste zjistili nejlepší volbu pro distribuci úloh. V konkrétním případě zvažte:
- Kolik dat lze načíst a zpracovat v paměti jednoho uzlu.
- Režie při spouštění jednotlivých dávkových úloh.
- Režie při načítání modelů R
Ve scénáři použitém v tomto příkladu jsou objekty modelu velké a generování prognózy pro jednotlivé produkty trvá jen několik sekund. Z tohoto důvodu můžete seskupit produkty a spustit jednu úlohu Batch na uzel. Smyčka v rámci každé úlohy generuje prognózy pro produkty postupně. Tato metoda je nejúčinnější způsob, jak paralelizovat tuto konkrétní úlohu. Vyhne se režii při spouštění mnoha menších úloh Batch a opakovanému načítání modelů R.
Alternativním přístupem je aktivovat jednu úlohu Batch na produkt. Azure Batch automaticky vytvoří frontu úloh a odešle je, aby se spouštěly v clusteru, jakmile budou uzly k dispozici. Pomocí automatického škálování můžete upravit počet uzlů v clusteru v závislosti na počtu úloh. Tento přístup je užitečný, pokud dokončení každé operace vyhodnocování trvá poměrně dlouho, což zdůvodňuje režii při spuštění úloh a opětovném načtení objektů modelu. Tento přístup je také jednodušší implementovat a poskytuje flexibilitu při používání automatického škálování, což je důležité zvážit, pokud velikost celkové úlohy není předem známa.
Monitorování úloh Azure Batch
Monitorování a ukončení úloh Batch z podokna Úlohy účtu Batch na webu Azure Portal V podokně Fondy monitorujte dávkový cluster, včetně stavu jednotlivých uzlů.
Log with doAzureParallel
Balíček doAzureParallel automaticky shromažďuje protokoly všech stdout/stderr pro každou úlohu odeslanou ve službě Azure Batch. Tyto protokoly najdete v účtu úložiště vytvořeném při instalaci. Pokud je chcete zobrazit, použijte navigační nástroj úložiště, jako je Průzkumník služby Azure Storage nebo Azure Portal.
Pokud chcete rychle ladit úlohy Batch během vývoje, prohlédněte si protokoly v místní relaci jazyka R. Další informace najdete v tématu Konfigurace a odeslání trénovacích běhů.
Optimalizace nákladů
Optimalizace nákladů se zabývá způsoby, jak snížit zbytečné výdaje a zlepšit efektivitu provozu. Další informace najdete v tématu Přehled pilíře optimalizace nákladů.
Výpočetní prostředky používané v této referenční architektuře jsou nejnákladnější komponenty. V tomto scénáři se vytvoří cluster s pevnou velikostí vždy, když se úloha aktivuje, a po dokončení úlohy se vypne. Náklady se účtují jenom v době, kdy se uzly clusteru spouští, spouští nebo vypíná. Tento přístup je vhodný pro scénář, ve kterém výpočetní prostředky potřebné ke generování prognóz zůstávají relativně konstantní z úlohy do úlohy.
Ve scénářích, ve kterých není předem známo množství výpočetních prostředků potřebných k dokončení úlohy, může být vhodnější použít automatické škálování. Při tomto přístupu se velikost clusteru škáluje nahoru nebo dolů v závislosti na velikosti úlohy. Azure Batch podporuje řadu vzorců automatického škálování, které můžete nastavit při definování clusteru pomocí rozhraní API doAzureParallel .
V některých scénářích může být doba mezi úlohami příliš krátká, aby se cluster vypnul a spustil. V těchto případech ponechte cluster spuštěný mezi úlohami, pokud je to vhodné.
Azure Batch a doAzureParallel podporují použití virtuálních počítačů s nízkou prioritou. Tyto virtuální počítače mají významnou slevu, ale riskují, že jsou vhodné pro jiné úlohy s vyšší prioritou. Proto se pro kritické produkční úlohy nedoporučuje použití virtuálních počítačů s nízkou prioritou. Jsou ale užitečné pro experimentální nebo vývojové úlohy.
Nasazení tohoto scénáře
Pokud chcete tuto referenční architekturu nasadit, postupujte podle kroků popsaných v úložišti GitHub .
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Angus Taylor | Senior Datoví vědci
Pokud chcete zobrazit neveřejné profily LinkedIn, přihlaste se na LinkedIn.