Nápady na řešení
Tento článek je myšlenkou řešení. Pokud chcete, abychom obsah rozšířili o další informace, jako jsou potenciální případy použití, alternativní služby, aspekty implementace nebo pokyny k cenám, dejte nám vědět tím, že nám poskytnete zpětnou vazbu k GitHubu.
Tento příklad popisuje, jak provádět přírůstkové načítání v kanálu extrakce, načítání a transformace (ELT). K automatizaci kanálu ELT používá Azure Data Factory. Kanál přírůstkově přesune nejnovější data OLTP z místní databáze SQL Serveru do Azure Synapse. Transakční data se transformují na tabulkový model pro analýzu.
Architektura

Stáhněte si soubor aplikace Visio s touto architekturou.
Tato architektura vychází z architektury, která se zobrazuje v Enterprise BI s Azure Synapse, ale přidává některé funkce, které jsou důležité pro scénáře podnikových datových skladů.
- Automatizace kanálu pomocí služby Data Factory
- Přírůstkové načítání
- Integrace více zdrojů dat
- Načítání binárních dat, jako jsou geoprostorová data a obrázky
Workflow
Architektura se skládá z následujících služeb a komponent.
Zdroje dat
Místní SQL Server. Zdrojová data se nacházejí v místní databázi SQL Serveru. Simulace místního prostředí Ukázková databáze OLTP Wide World Importers se používá jako zdrojová databáze.
Externí data. Běžným scénářem datových skladů je integrace více zdrojů dat. Tato referenční architektura načte externí datovou sadu, která obsahuje populace měst podle roku, a integruje ji s daty z databáze OLTP. Tato data můžete použít pro přehledy, například: "Odpovídá růst prodeje v jednotlivých oblastech nebo překračuje růst populace?".
Příjem dat a úložiště dat
Blob Storage. Úložiště objektů blob se používá jako pracovní oblast pro zdrojová data před načtením do Azure Synapse.
Azure Synapse. Azure Synapse je distribuovaný systém navržený k provádění analýz velkých dat. Podporuje výkonné paralelní zpracování umožňující provádět vysoce výkonné analýzy.
Azure Data Factory. Data Factory je spravovaná služba, která orchestruje a automatizuje přesun a transformaci dat. V této architektuře koordinuje různé fáze procesu ELT.
Analýza a vytváření sestav
Azure Analysis Services. Analysis Services je plně spravovaná služba, která poskytuje možnosti modelování dat. Sémantický model se načte do služby Analysis Services.
Power BI. Power BI je sada nástrojů pro obchodní analýzy, které analyzují data pro obchodní přehledy. V této architektuře dotazuje sémantický model uložený ve službě Analysis Services.
Ověřování
Microsoft Entra ID (Microsoft Entra ID) ověřuje uživatele, kteří se připojují k serveru Analysis Services prostřednictvím Power BI.
Data Factory může k ověření ve službě Azure Synapse použít také MICROSOFT Entra ID pomocí instančního objektu nebo identity spravované služby (MSI).
Komponenty
- Azure Blob Storage
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Podrobnosti scénáře
Datový kanál
Kanál ve službě Azure Data Factory je logické seskupení aktivit používaných ke koordinaci úlohy – v tomto případě načítání a transformace dat do Azure Synapse.
Tato referenční architektura definuje nadřazený kanál, který spouští posloupnost podřízených kanálů. Každý podřízený kanál načte data do jedné nebo více tabulek datového skladu.

Doporučení
Přírůstkové načítání
Když spustíte automatizovaný proces ETL nebo ELT, je nejúčinnější načíst pouze data, která se od předchozího spuštění změnila. Tomu se říká přírůstkové načtení, nikoli úplné načtení, které načte všechna data. Pokud chcete provést přírůstkové načítání, potřebujete způsob, jak zjistit, která data se změnila. Nejběžnějším přístupem je použití hodnoty horní značky, což znamená sledování nejnovější hodnoty některého sloupce ve zdrojové tabulce, a to buď sloupce datetime, nebo jedinečného celočíselného sloupce.
Počínaje SQL Serverem 2016 můžete používat dočasné tabulky. Jedná se o tabulky se systémovou verzí, které udržují úplnou historii změn dat. Databázový stroj automaticky zaznamenává historii každé změny v samostatné tabulce historie. Historická data můžete dotazovat přidáním klauzule FOR SYSTEM_TIME do dotazu. Databázový stroj interně dotazuje tabulku historie, ale to je pro aplikaci transparentní.
Poznámka:
Pro starší verze SQL Serveru můžete použít funkci Change Data Capture (CDC). Tento přístup je méně pohodlný než dočasné tabulky, protože musíte dotazovat samostatnou tabulku změn a změny se sledují pořadovým číslem protokolu, nikoli časovým razítkem.
Dočasné tabulky jsou užitečné pro data dimenzí, která se můžou v průběhu času měnit. Tabulky faktů obvykle představují neměnnou transakci, jako je prodej, v takovém případě zachování historie systémových verzí nedává smysl. Místo toho transakce obvykle mají sloupec, který představuje datum transakce, které lze použít jako hodnotu meze. Například v databázi OLTP Wide World Importers mají LastEditedWhen tabulky Sales.Invoices a Sales.InvoiceLines pole, které má výchozí hodnotu sysdatetime().
Tady je obecný tok kanálu ELT:
Pro každou tabulku ve zdrojové databázi sledujte čas ukončení poslední úlohy ELT. Tyto informace uložte do datového skladu. (Při počátečním nastavení jsou všechny časy nastavené na 1-1-1900.)
Během kroku exportu dat se jako parametr předává sada uložených procedur ve zdrojové databázi jako parametr. Tyto uložené procedury se dotazují na všechny záznamy, které byly změněny nebo vytvořeny po uplynutí doby ukončení. Pro tabulku
LastEditedWhenfaktů Sales se použije sloupec. Pro data dimenzí se používají dočasné tabulky s verzí systému.Po dokončení migrace dat aktualizujte tabulku, ve které jsou uloženy časy ukončení.
Je také užitečné zaznamenat rodokmen pro každé spuštění ELT. U daného záznamu rodokmen tento záznam přidruží ke spuštění ELT, které vytvořila data. Pro každé spuštění ETL se pro každou tabulku vytvoří nový záznam rodokmenu, který zobrazuje počáteční a koncové časy načítání. Klíče rodokmenu pro každý záznam jsou uloženy v tabulkách dimenzí a faktů.
Po načtení nové dávky dat do skladu aktualizujte tabulkový model Analysis Services. Podívejte se na asynchronní aktualizaci pomocí rozhraní REST API.
Čištění dat
Čištění dat by mělo být součástí procesu ELT. V této referenční architektuře je jedním ze zdrojů chybných dat tabulka obyvatel měst, kde některá města mají nulový počet obyvatel, třeba proto, že nebyla k dispozici žádná data. Během zpracování kanál ELT odebere tato města z tabulky obyvatel města. Čištění dat u pracovních tabulek místo externích tabulek.
Externí zdroje dat
Datové sklady často konsolidují data z více zdrojů. Například externí zdroj dat, který obsahuje demografické údaje. Tato datová sada je dostupná v úložišti objektů blob v Azure jako součást ukázky WorldWideImportersDW .
Azure Data Factory může kopírovat přímo z úložiště objektů blob pomocí konektoru úložiště objektů blob. Konektor ale vyžaduje připojovací řetězec nebo sdílený přístupový podpis, takže ho nejde použít ke kopírování objektu blob s veřejným přístupem pro čtení. Jako alternativní řešení můžete pomocí PolyBase vytvořit externí tabulku přes úložiště objektů blob a pak zkopírovat externí tabulky do Azure Synapse.
Zpracování velkých binárních dat
Například ve zdrojové databázi má tabulka Město sloupec Umístění, který obsahuje zeměpisný prostorový datový typ. Azure Synapse nativně nepodporuje zeměpisný typ, takže toto pole se během načítání převede na varbinární typ. (Viz Alternativní řešení pro nepodporované datové typy.)
PolyBase však podporuje maximální velikost varbinary(8000)sloupce , což znamená, že některá data mohou být zkrácena. Alternativním řešením tohoto problému je rozdělení dat do bloků dat během exportu a následné opětovné sestavení bloků dat následujícím způsobem:
Vytvořte dočasnou pracovní tabulku pro sloupec Umístění.
Pro každé město rozdělte data o poloze na 8 000 bajtů, což má za následek 1 až N řádků pro každé město.
Pokud chcete znovu sestavit bloky dat, pomocí operátoru T-SQL PIVOT převeďte řádky na sloupce a pak zřetězení hodnot sloupců pro každé město.
Problémem je, že každé město bude rozděleno do jiného počtu řádků v závislosti na velikosti zeměpisných dat. Aby operátor PIVOT fungoval, musí mít každé město stejný počet řádků. Aby to fungovalo, provede dotaz T-SQL některé triky, které vyřadí řádky s prázdnými hodnotami, aby každé město za kontingenčním grafem získalo stejný počet sloupců. Výsledný dotaz je mnohem rychlejší než procházení řádků po jednom.
Stejný přístup se používá pro data obrázků.
Pomalu se měnící dimenze
Data dimenzí jsou relativně statická, ale můžou se změnit. Například produkt může být znovu přiřazen k jiné kategorii produktu. Existuje několik přístupů ke zpracování pomalu se měnících dimenzí. Běžnou technikou s názvem Type 2 je přidání nového záznamu při každé změně dimenze.
Aby bylo možné implementovat přístup typu 2, tabulky dimenzí potřebují další sloupce, které určují efektivní rozsah kalendářních dat pro daný záznam. Primární klíče ze zdrojové databáze se také duplikují, takže tabulka dimenzí musí mít umělý primární klíč.
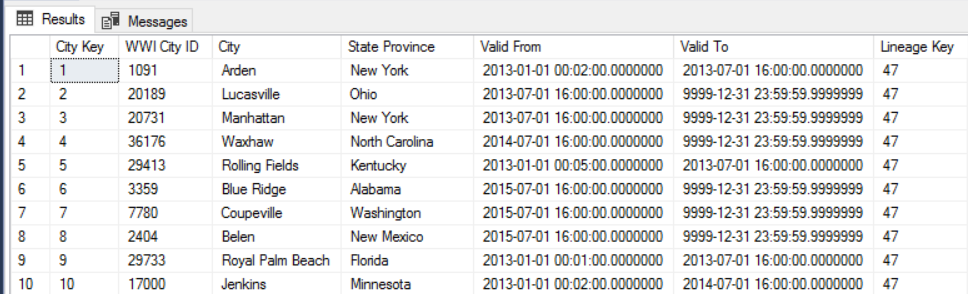
Například následující obrázek znázorňuje tabulku Dimension.City. Sloupec WWI City ID je primární klíč ze zdrojové databáze. Sloupec City Key je umělý klíč vygenerovaný během kanálu ETL. Všimněte si také, že tabulka obsahuje Valid From a Valid To sloupce, které definují oblast, kdy byl každý řádek platný. Aktuální hodnoty mají Valid To hodnotu 9999-12-31.
Výhodou tohoto přístupu je, že zachovává historická data, která mohou být cenná pro analýzu. To ale také znamená, že pro stejnou entitu bude existovat více řádků. Tady jsou například záznamy odpovídající WWI City ID = 28561:
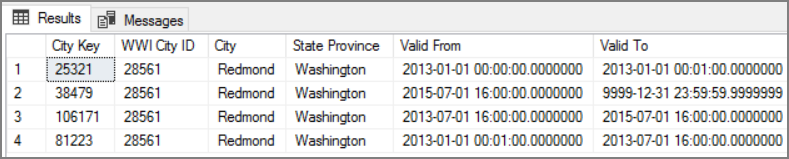
Pro každou faktu Sales (Prodej) chcete tento fakt přidružit k jednomu řádku v tabulce dimenze Města odpovídající datu faktury.
Důležité informace
Tyto aspekty implementují pilíře dobře architektuře Azure, což je sada hlavních principů, které je možné použít ke zlepšení kvality úlohy. Další informace naleznete v tématu Microsoft Azure Well-Architected Framework.
Zabezpečení
Zabezpečení poskytuje záruky proti záměrným útokům a zneužití cenných dat a systémů. Další informace najdete v tématu Přehled pilíře zabezpečení.
K dalšímu zabezpečení můžete použít koncové body služby virtuální sítě k zabezpečení prostředků služeb Azure pouze pro vaši virtuální síť. Tím se plně odebere veřejný přístup k internetu k těmto prostředkům, což umožňuje provoz jenom z vaší virtuální sítě.
Pomocí tohoto přístupu vytvoříte virtuální síť v Azure a pak vytvoříte koncové body privátní služby pro služby Azure. Tyto služby jsou pak omezeny na provoz z této virtuální sítě. Můžete k nim také přistupovat z místní sítě prostřednictvím brány.
Mějte na paměti následující omezení:
Pokud jsou pro Azure Storage povolené koncové body služby, PolyBase nemůže kopírovat data ze služby Storage do Azure Synapse. K tomuto problému dochází ke zmírnění tohoto problému. Další informace najdete v tématu Dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure.
Pokud chcete přesunout data z místního prostředí do Azure Storage, budete muset povolit veřejné IP adresy z místního prostředí nebo ExpressRoute. Podrobnosti najdete v tématu Zabezpečení služeb Azure s virtuálními sítěmi.
Pokud chcete službě Analysis Services povolit čtení dat z Azure Synapse, nasaďte virtuální počítač s Windows do virtuální sítě, která obsahuje koncový bod služby Azure Synapse. Nainstalujte na tento virtuální počítač místní bránu dat Azure. Pak připojte službu Azure Analysis Service k bráně dat.
DevOps
Vytvořte samostatné skupiny prostředků pro produkční, vývojové a testovací prostředí. Samostatné skupiny prostředků usnadňují správu nasazení, odstraňování testovacích nasazení a přiřazování přístupových práv.
Každou úlohu umístěte do samostatné šablony nasazení a uložte prostředky do systémů správy zdrojového kódu. Šablony můžete nasadit společně nebo jednotlivě jako součást procesu CI/CD, což usnadňuje proces automatizace.
V této architektuře existují tři hlavní úlohy:
- Server datového skladu, Analysis Services a související prostředky.
- Azure Data Factory.
- Scénář simulovaný v místním prostředí do cloudu.
Každá úloha má vlastní šablonu nasazení.
Server datového skladu se nastavuje a konfiguruje pomocí příkazů Azure CLI, které se řídí imperativním přístupem k postupům IaC. Zvažte použití skriptů nasazení a jejich integraci do procesu automatizace.
Zvažte přípravu úloh. Nasaďte je do různých fází a před přechodem na další fázi spusťte kontroly ověřování v každé fázi. Díky tomu můžete odesílat aktualizace do produkčních prostředí vysoce kontrolovaným způsobem a minimalizovat neočekávané problémy s nasazením. Pro aktualizaci živých produkčních prostředí používejte strategie nasazení blue-green a kanárských verzí .
Máte dobrou strategii vrácení zpět pro zpracování neúspěšných nasazení. Můžete například automaticky nasadit dřívější úspěšné nasazení z historie nasazení. Viz parametr příznaku --rollback-on-error v Azure CLI.
Azure Monitor je doporučená možnost analýzy výkonu datového skladu a celé analytické platformy Azure pro integrované prostředí monitorování. Azure Synapse Analytics poskytuje prostředí pro monitorování na webu Azure Portal a zobrazuje přehledy úloh datového skladu. Azure Portal je doporučeným nástrojem při monitorování datového skladu, protože poskytuje konfigurovatelná období uchovávání, upozornění, doporučení a přizpůsobitelné grafy a řídicí panely pro metriky a protokoly.
Další informace najdete v části DevOps v architektuře Microsoft Azure Well-Architected Framework.
Optimalizace nákladů
Optimalizace nákladů se zabývá způsoby, jak snížit zbytečné výdaje a zlepšit efektivitu provozu. Další informace najdete v tématu Přehled pilíře optimalizace nákladů.
K odhadu nákladů použijte cenovou kalkulačku Azure. Tady je několik důležitých informací o službách používaných v této referenční architektuře.
Azure Data Factory
Azure Data Factory automatizuje kanál ELT. Kanál přesune data z místní databáze SQL Serveru do Azure Synapse. Data se pak transformují na tabulkový model pro analýzu. V tomto scénáři začínají ceny od 0,001 USD aktivit za měsíc, která zahrnuje spuštění aktivit, triggerů a ladění. Tato cena je základní poplatek pouze pro orchestraci. Také se vám účtují aktivity provádění, jako je kopírování dat, vyhledávání a externí aktivity. Každá aktivita je individuálně cenná. Poplatky se vám účtují také za kanály bez přidružených triggerů nebo spuštění v rámci měsíce. Všechny aktivity jsou hodnoceny podle minuty a zaokrouhleny nahoru.
Příklad analýzy nákladů
Představte si případ použití, kdy existují dvě aktivity vyhledávání ze dvou různých zdrojů. Jedna trvá 1 minutu a 2 sekundy (zaokrouhluje se nahoru na 2 minuty) a druhá trvá 1 minutu, což vede k celkovému času 3 minut. Jedna aktivita kopírování dat trvá 10 minut. Jedna aktivita uložené procedury trvá 2 minuty. Celková aktivita běží po dobu 4 minut. Náklady se počítají takto:
Spuštění aktivit: 4 * $ 0,001 = $0,004
Vyhledávání: 3 * (0,005 USD / 60) = 0,00025 Kč
Uložená procedura: 2 * ($0.00025 / 60) = $0,000008
Kopírování dat: 10 × (0,25 USD / 60) * 4 jednotka integrace dat (DIU) = 0,167 USD
- Celkové náklady na spuštění kanálu: 0,17 USD.
- Spusťte jednou za den po dobu 30 dnů: 5,1 usd měsíčně.
- Spuštění jednou za den za 100 tabulek za 30 dní: 510 USD
Každá aktivita má přidružené náklady. Seznamte se s cenovým modelem a pomocí cenové kalkulačky ADF získáte řešení optimalizované nejen pro výkon, ale také náklady. Spravujte náklady spuštěním, zastavením, pozastavením a škálováním služeb.
Azure Synapse
Azure Synapse je ideální pro náročné úlohy s vyšším výkonem dotazů a potřebami škálovatelnosti výpočetních prostředků. Můžete zvolit model průběžných plateb nebo použít rezervované plány jednoho roku (37% úspory) nebo 3 roky (65% úspory).
Úložiště dat se účtuje zvlášť. Další služby, jako je zotavení po havárii a detekce hrozeb, se také účtují samostatně.
Další informace najdete v tématu Azure Synapse – ceny.
Analysis Services
Ceny služby Azure Analysis Services závisí na úrovni. Referenční implementace této architektury používá úroveň Developer , která se doporučuje pro scénáře vyhodnocení, vývoje a testování. Mezi další úrovně patří úroveň Basic, která se doporučuje pro malé produkční prostředí, úroveň Standard pro klíčové produkční aplikace. Další informace najdete v části Správná úroveň, když ji potřebujete.
Při pozastavení instance se neúčtují žádné poplatky.
Další informace najdete v tématu o cenách služby Azure Analysis Services.
Blob Storage
Zvažte použití funkce rezervované kapacity služby Azure Storage, abyste snížili náklady na úložiště. S tímto modelem získáte slevu, pokud se můžete zavázat k rezervaci pro pevnou kapacitu úložiště po dobu jednoho nebo tří let. Další informace najdete v tématu Optimalizace nákladů na úložiště objektů blob s rezervovanou kapacitou.
Další informace najdete v části Náklady v architektuře Microsoft Azure Well-Architected Framework.
Další kroky
- Úvod do Azure Synapse Analytics
- Začínáme s Azure Synapse Analytics
- Úvod do služby Azure Data Factory
- Co je Azure Data Factory?
- Kurzy ke službě Azure Data Factory
Související prostředky
Můžete se podívat na následující ukázkové scénáře Azure, které demonstrují konkrétní řešení pomocí některých stejných technologií: