Vytvoření aplikací Apache Spark pro cluster HDInsight pomocí sady Azure Toolkit for IntelliJ
Tento článek ukazuje, jak vyvíjet aplikace Apache Spark ve službě Azure HDInsight pomocí modulu plug-in sady Azure Toolkit pro integrované vývojové prostředí IntelliJ. Azure HDInsight je spravovaná opensourcová analytická služba v cloudu. Tato služba umožňuje používat opensourcové architektury, jako jsou Hadoop, Apache Spark, Apache Hive a Apache Kafka.
Modul plug-in Azure Toolkit můžete použít několika způsoby:
- Vývoj a odeslání aplikace Scala Spark do clusteru HDInsight Spark
- Získejte přístup k prostředkům clusteru Azure HDInsight Spark.
- Vyvíjejte a spouštějte aplikaci Scala Spark místně.
V tomto článku získáte informace o těchto tématech:
- Použití modulu plug-in Azure Toolkit for IntelliJ
- Vývoj aplikací Apache Spark
- Odeslání aplikace do clusteru Azure HDInsight
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight. Podporují se pouze clustery HDInsight ve veřejném cloudu, zatímco jiné zabezpečené typy cloudu (např. cloudy státní správy) nejsou podporované.
Oracle Java Development Kit. Tento článek používá Javu verze 8.0.202.
IntelliJ IDEA Tento článek používá IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Viz Instalace sady Azure Toolkit for IntelliJ.
Instalace modulu plug-in Scala pro IntelliJ IDEA
Postup instalace modulu plug-in Scala:
Otevřete IntelliJ IDEA.
Na úvodní obrazovce přejděte na Konfigurovat>moduly plug-in a otevřete okno Moduly plug-in.
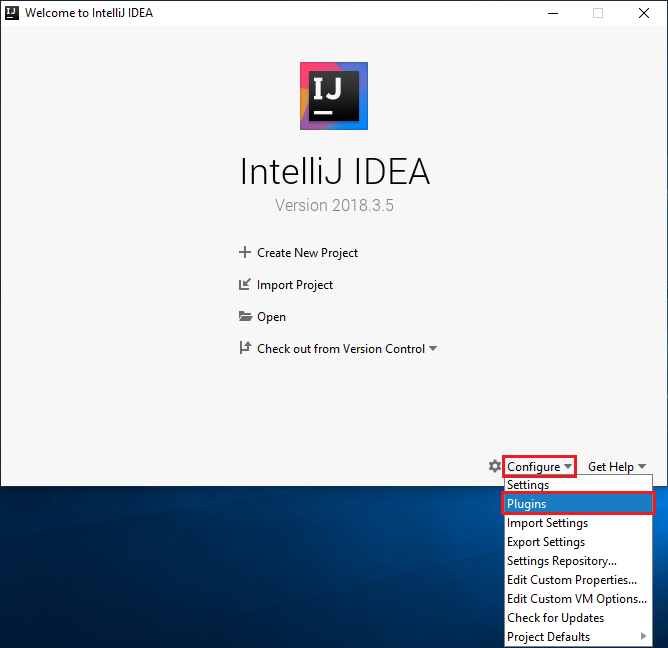
Vyberte Nainstalovat pro modul plug-in Scala, který je doporučený v novém okně.
Po úspěšné instalaci modulu plug-in je potřeba restartovat integrované vývojové prostředí (IDE).
Vytvoření aplikace Spark Scala pro cluster HDInsight Spark
Spusťte IntelliJ IDEA a výběrem možnosti Vytvořit nový projekt otevřete okno Nový projekt.
V levém podokně vyberte Azure Spark/HDInsight .
V hlavním okně vyberte Spark Project (Scala ).
V rozevíracím seznamu Nástroje sestavení vyberte jednu z následujících možností:
Podpora Průvodce vytvořením projektu Maven pro Scala
SBT pro správu závislostí a sestavování pro projekt Scala.
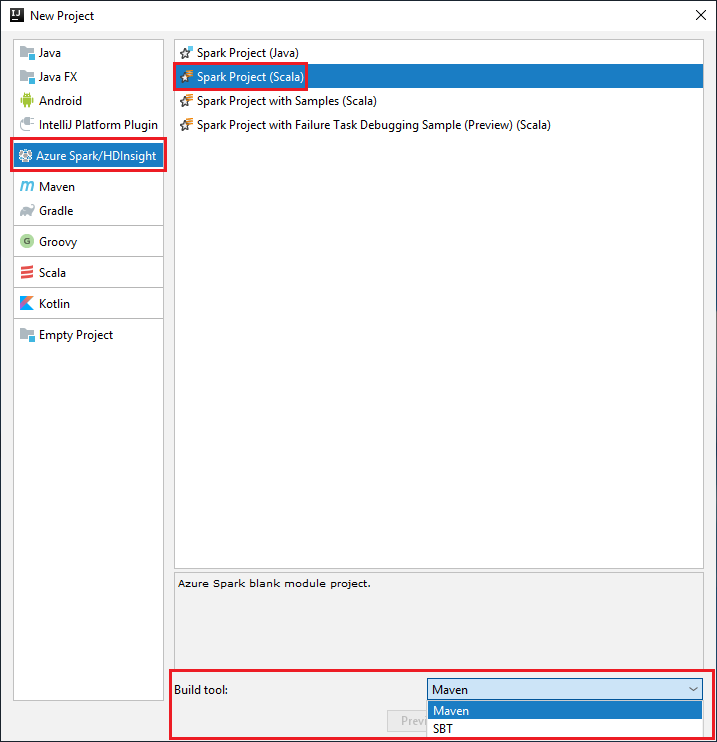
Vyberte Další.
V okně Nový projekt zadejte následující informace:
Vlastnost Popis Název projektu Zadejte název. Tento článek používá myApp.Umístění projektu Zadejte umístění pro uložení projektu. Project SDK Toto pole může být prázdné při prvním použití funkce IDEA. Vyberte Nový... a přejděte na sadu JDK. Verze Sparku Průvodce vytvořením integruje správnou verzi sady Spark SDK a Scala SDK. Pokud je verze clusteru Spark nižší než 2.0, vyberte Spark 1.x. V opačném případě vyberte Spark 2.x. V tomto příkladu se používá Spark 2.3.0 (Scala 2.11.8). 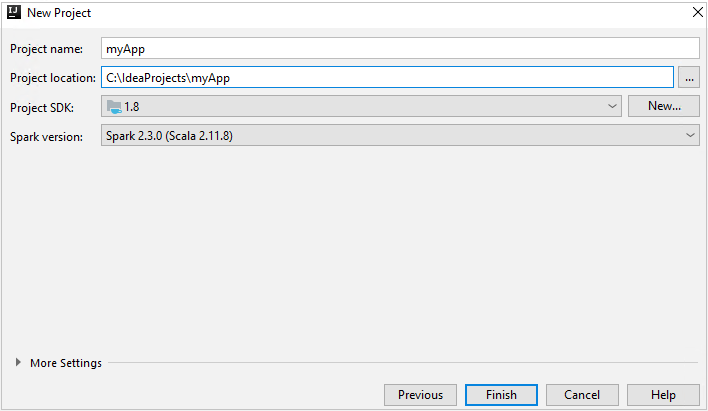
Vyberte Dokončit. Než bude projekt dostupný, může to trvat několik minut.
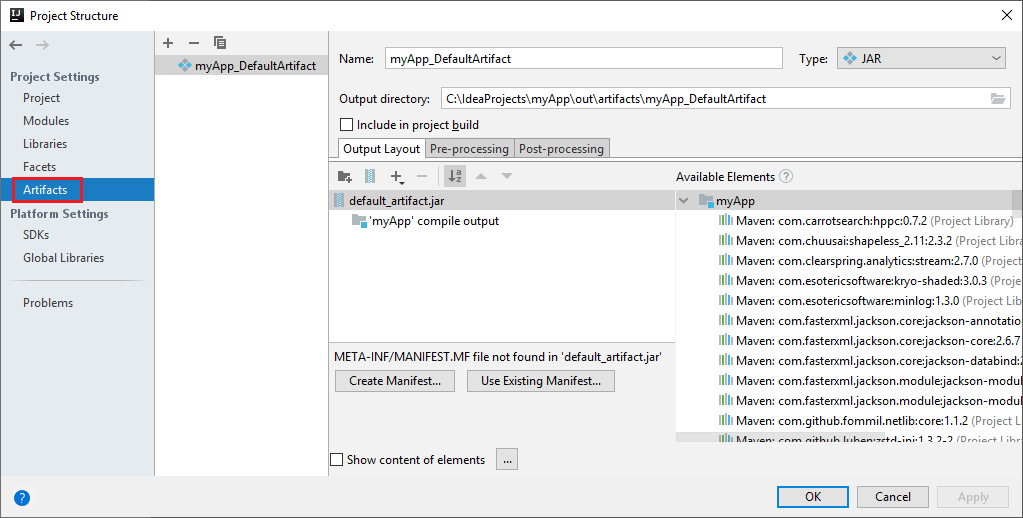
Projekt Spark automaticky vytvoří artefakt za vás. Pokud chcete zobrazit artefakt, postupujte takto:
a. V řádku nabídek přejděte do struktury projektu souborů>....
b. V okně Struktura projektu vyberte Artefakty.
c. Po zobrazení artefaktu vyberte Zrušit .
Přidejte zdrojový kód aplikace pomocí následujícího postupu:
a. V Projectu přejděte na hlavní>scalu myApp>src.>
b. Klikněte pravým tlačítkem myši na scala a přejděte na novou>třídu Scala.

c. V dialogovém okně Vytvořit novou třídu Scala zadejte název, vyberte v rozevíracím seznamu Druh objekt a pak vyberte OK.

d. Soubor myApp.scala se pak otevře v hlavním zobrazení. Nahraďte výchozí kód následujícím kódem:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Kód načte data z HVAC.csv (k dispozici ve všech clusterech HDInsight Spark), načte řádky, které mají v souboru CSV jenom jednu číslici, a zapíše výstup do
/HVACOutvýchozího kontejneru úložiště clusteru.
Připojení ke clusteru HDInsight
Uživatel se může přihlásit k předplatnému Azure nebo propojit cluster HDInsight. Pro připojení ke clusteru HDInsight použijte přihlašovací údaje a heslo nebo přihlašovací údaje připojené k doméně Ambari.
Přihlaste se ke svému předplatnému Azure.
V řádku nabídek přejděte do Průzkumníka Windows>Azure Nástroje pro zobrazení.>

V Azure Exploreru klikněte pravým tlačítkem na uzel Azure a pak vyberte Přihlásit se.
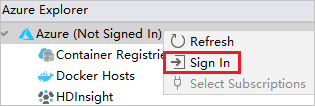
V dialogovém okně Azure Sign In (Přihlášení k Azure) zvolte Device Login (Přihlášení zařízení) a pak vyberte Sign in (Přihlásit se).

V dialogovém okně Azure Device Login (Přihlášení zařízení Azure) klikněte na Copy&Open (Kopírovat&otevřít).
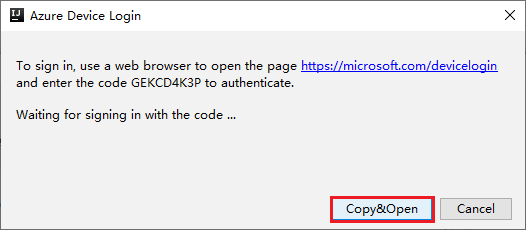
V rozhraní prohlížeče vložte kód a klepněte na tlačítko Další.
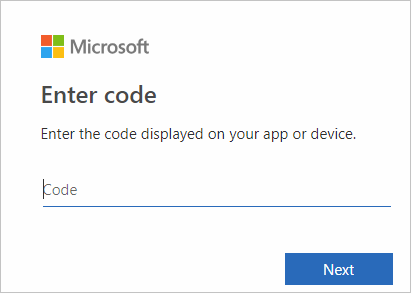
Zadejte své přihlašovací údaje Azure a zavřete prohlížeč.
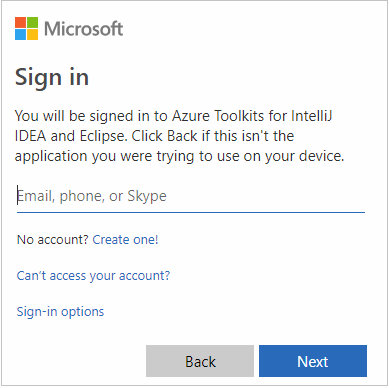
Po přihlášení se v dialogovém okně Vybrat předplatná zobrazí seznam všech předplatných Azure přidružených k přihlašovacím údajům. Vyberte své předplatné a pak vyberte tlačítko Vybrat .
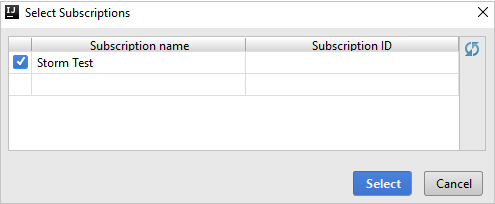
V Průzkumníku Azure rozbalte HDInsight a zobrazte clustery HDInsight Spark, které jsou ve vašich předplatných.
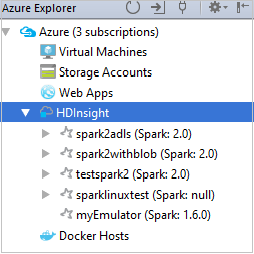
Pokud chcete zobrazit prostředky (například účty úložiště), které jsou přidružené ke clusteru, můžete dále rozšířit uzel názvu clusteru.
Propojení clusteru
Cluster HDInsight můžete propojit pomocí spravovaného uživatelského jména Apache Ambari. Podobně můžete pro cluster HDInsight připojený k doméně propojit pomocí domény a uživatelského jména, například user1@contoso.com. Můžete také propojit cluster Služby Livy.
V řádku nabídek přejděte do Průzkumníka Windows>Azure Nástroje pro zobrazení.>
V Azure Exploreru klikněte pravým tlačítkem na uzel HDInsight a pak vyberte Propojit cluster.
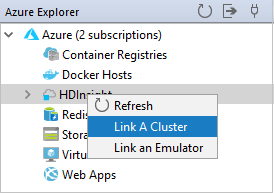
Dostupné možnosti v okně Propojit cluster A se budou lišit v závislosti na tom, jakou hodnotu vyberete z rozevíracího seznamu Typ prostředku propojení. Zadejte hodnoty a pak vyberte OK.
HDInsight Cluster
Vlastnost Hodnota Typ prostředku propojení V rozevíracím seznamu vyberte cluster HDInsight. Název nebo adresa URL clusteru Zadejte název clusteru. Typ ověřování Ponechat jako základní ověřování Uživatelské jméno Zadejte uživatelské jméno clusteru, výchozí hodnota je správce. Heslo Zadejte heslo pro uživatelské jméno. 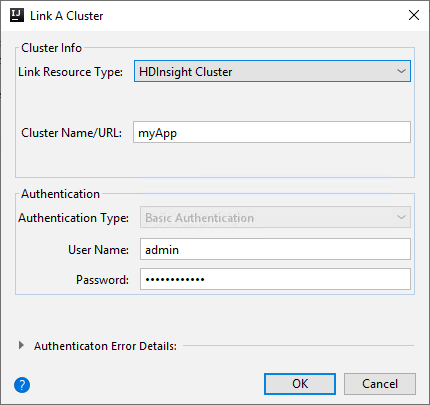
Livy Service
Vlastnost Hodnota Typ prostředku propojení V rozevíracím seznamu vyberte Službu Livy. Koncový bod Livy Zadejte koncový bod Livy. Název clusteru Zadejte název clusteru. Koncový bod Yarn Nepovinné. Typ ověřování Ponechat jako základní ověřování Uživatelské jméno Zadejte uživatelské jméno clusteru, výchozí hodnota je správce. Heslo Zadejte heslo pro uživatelské jméno. 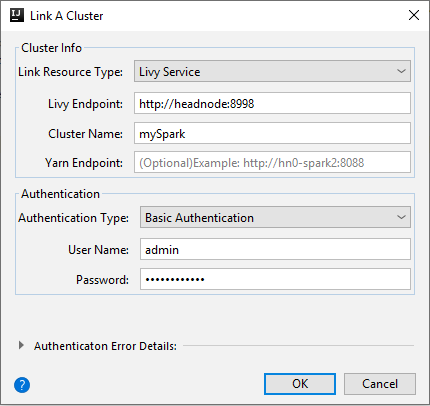
Propojený cluster můžete zobrazit z uzlu HDInsight .
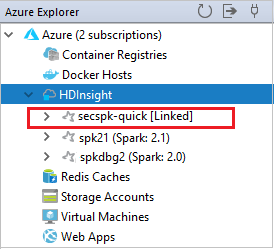
Cluster můžete také odpojit od Azure Exploreru.
Spuštění aplikace Spark Scala v clusteru HDInsight Spark
Po vytvoření aplikace Scala ji můžete odeslat do clusteru.
V Projectu přejděte na hlavní>scalu>myApp> src.> Klikněte pravým tlačítkem myši na myApp a vyberte Odeslat aplikaci Sparku (Pravděpodobně se nachází v dolní části seznamu).
V dialogovém okně Odeslat aplikaci Spark vyberte 1. Spark ve službě HDInsight.
V okně Upravit konfiguraci zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Clustery Spark (jenom Linux) Vyberte cluster HDInsight Spark, na kterém chcete aplikaci spustit. Výběr artefaktu k odeslání Ponechte výchozí nastavení. Název hlavní třídy Výchozí hodnota je hlavní třída z vybraného souboru. Třídu můžete změnit tak, že vyberete tři tečky(...) a zvolíte jinou třídu. Konfigurace úloh Můžete změnit výchozí klíče a nebo hodnoty. Další informace najdete v tématu Apache Livy REST API. Argumenty příkazového řádku V případě potřeby můžete zadat argumenty oddělené mezerou pro hlavní třídu. Odkazované soubory Jar a odkazované soubory Pokud existuje, můžete zadat cesty pro odkazované soubory Jar a soubory. Můžete také procházet soubory ve virtuálním systému souborů Azure, který aktuálně podporuje pouze cluster ADLS Gen2. Další informace: Konfigurace Apache Sparku. Viz také Postup nahrání prostředků do clusteru. Úložiště pro nahrání úlohy Rozbalením zobrazíte další možnosti. Typ úložiště V rozevíracím seznamu vyberte Použít objekt blob Azure. Účet úložiště Zadejte svůj účet úložiště. Klíč úložiště Zadejte svůj klíč úložiště. Kontejner úložiště Po zadání účtu úložiště a klíče úložiště vyberte kontejner úložiště z rozevíracího seznamu. 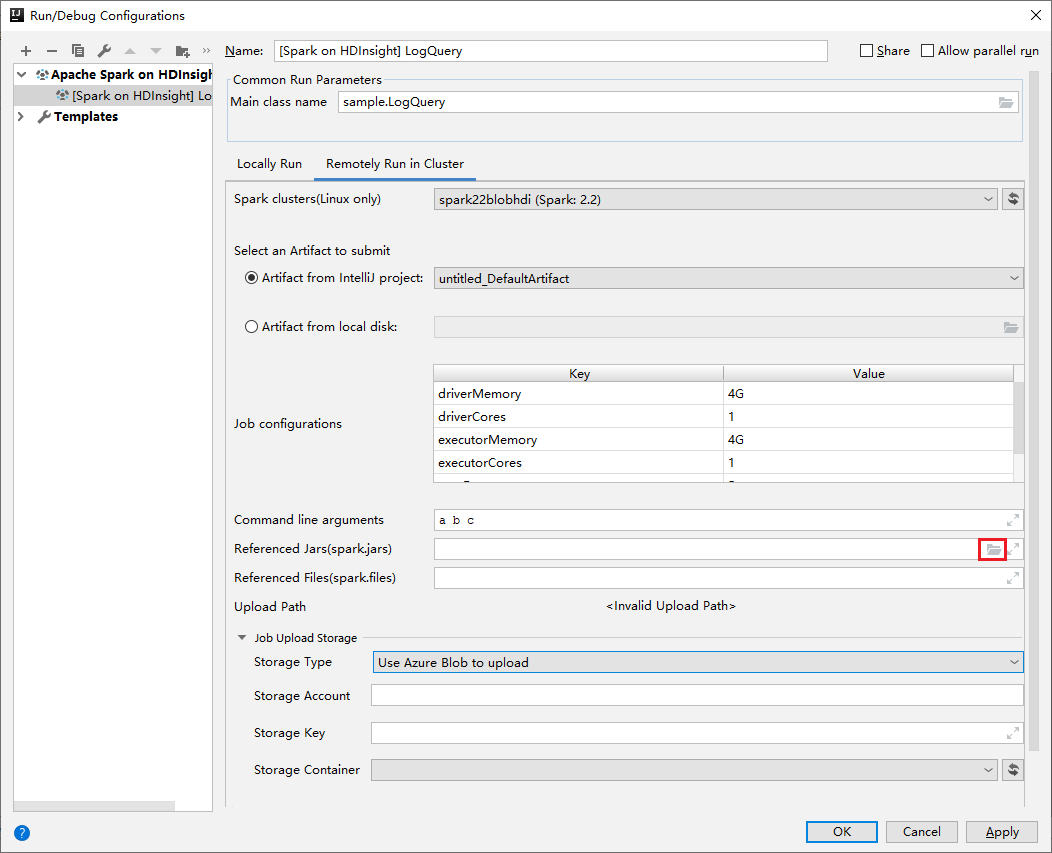
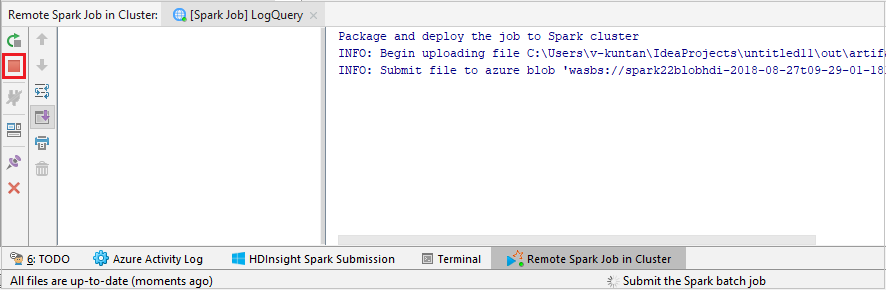
Vyberte SparkJobRun a odešlete projekt do vybraného clusteru. Vzdálená úloha Sparku na kartě Cluster zobrazuje průběh provádění úlohy v dolní části. Aplikaci můžete zastavit kliknutím na červené tlačítko.
Místní nebo vzdálené ladění aplikací Apache Spark v clusteru HDInsight
Doporučujeme také další způsob odeslání aplikace Spark do clusteru. Můžete to provést nastavením parametrů v integrovaném vývojovém prostředí IDE pro spuštění /ladění. Viz Ladění aplikací Apache Spark místně nebo vzdáleně v clusteru HDInsight pomocí sady Azure Toolkit for IntelliJ prostřednictvím SSH.
Přístup ke clusterům HDInsight Spark a jejich správa pomocí sady Azure Toolkit for IntelliJ
Různé operace můžete provádět pomocí sady Azure Toolkit for IntelliJ. Většina operací se spouští z Azure Exploreru. V řádku nabídek přejděte do Průzkumníka Windows>Azure Nástroje pro zobrazení.>
Přístup k zobrazení úlohy
V Azure Exploreru přejděte do SLUŽBY HDInsight><Vaše úlohy clusteru.>>
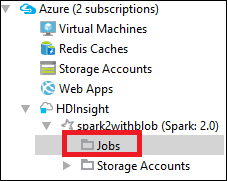
V pravém podokně se na kartě Zobrazení úloh Sparku zobrazí všechny aplikace spuštěné v clusteru. Vyberte název aplikace, pro kterou chcete zobrazit další podrobnosti.
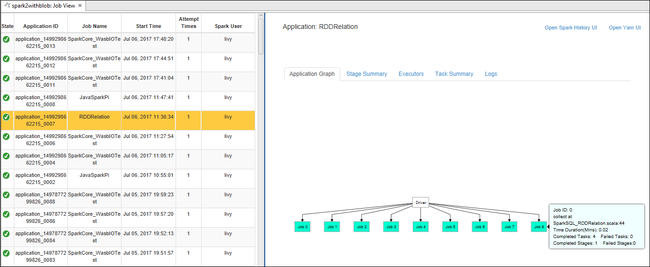
Pokud chcete zobrazit základní informace o spuštěné úloze, najeďte myší na graf úlohy. Pokud chcete zobrazit graf fází a informace, které každá úloha generuje, vyberte uzel v grafu úlohy.
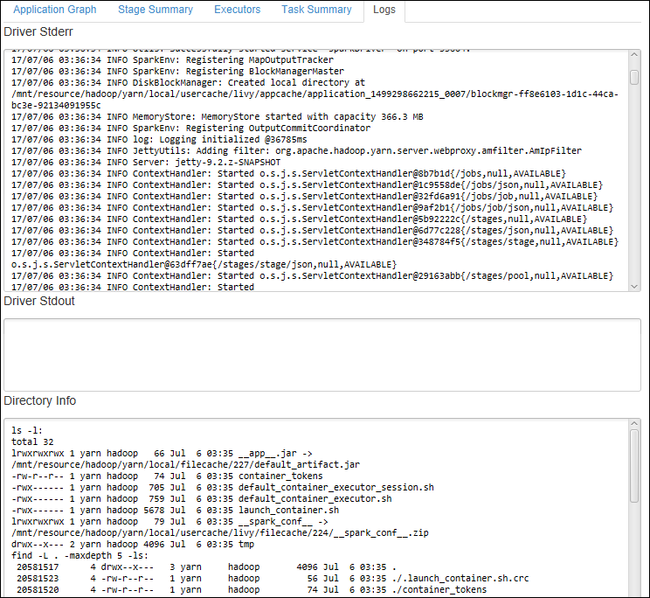
Pokud chcete zobrazit často používané protokoly, například Driver Stderr, Driver Stdout a Directory Info, vyberte kartu Protokol .
Můžete zobrazit uživatelské rozhraní historie Sparku a uživatelské rozhraní YARN (na úrovni aplikace). Vyberte odkaz v horní části okna.
Přístup k serveru historie Sparku
V Průzkumníku Azure rozbalte HDInsight, klikněte pravým tlačítkem na název clusteru Spark a pak vyberte Otevřít uživatelské rozhraní historie Sparku.
Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru, které jste zadali při nastavování clusteru.
Na řídicím panelu serveru historie Sparku můžete pomocí názvu aplikace vyhledat aplikaci, kterou jste právě dokončili. V předchozím kódu nastavíte název aplikace pomocí .
val conf = new SparkConf().setAppName("myApp")Název vaší aplikace Spark je myApp.
Spuštění portálu Ambari
V Průzkumníku Azure rozbalte HDInsight, klikněte pravým tlačítkem na název clusteru Spark a pak vyberte Otevřít portál pro správu clusteru (Ambari).
Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru. Tyto přihlašovací údaje jste zadali během procesu nastavení clusteru.
Správa předplatných Azure
Sada Azure Toolkit for IntelliJ standardně uvádí clustery Spark ze všech vašich předplatných Azure. V případě potřeby můžete zadat předplatná, ke kterým chcete získat přístup.
V Azure Exploreru klikněte pravým tlačítkem na kořenový uzel Azure a pak vyberte Vybrat předplatná.
V okně Vybrat předplatná zrušte zaškrtnutí políček vedle předplatných, ke kterým nechcete přistupovat, a pak vyberte Zavřít.
Konzola Sparku
Můžete spustit místní konzolu Sparku (Scala) nebo spustit konzolu interaktivní relace Spark Livy (Scala).
Místní konzola Sparku (Scala)
Ujistěte se, že jste splnili požadavky na WINUTILS.EXE.
Na řádku nabídek přejděte na Příkaz Spustit>konfiguraci úprav....
V okně Konfigurace spuštění/ladění přejděte v levém podokně na Apache Spark ve službě HDInsight>[Spark ve službě HDInsight] myApp.
V hlavním okně vyberte
Locally Runkartu.Zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Hlavní třída úlohy Výchozí hodnota je hlavní třída z vybraného souboru. Třídu můžete změnit tak, že vyberete tři tečky(...) a zvolíte jinou třídu. Proměnné prostředí Ujistěte se, že je správná hodnota pro HADOOP_HOME. WINUTILS.exe umístění Ujistěte se, že je cesta správná. 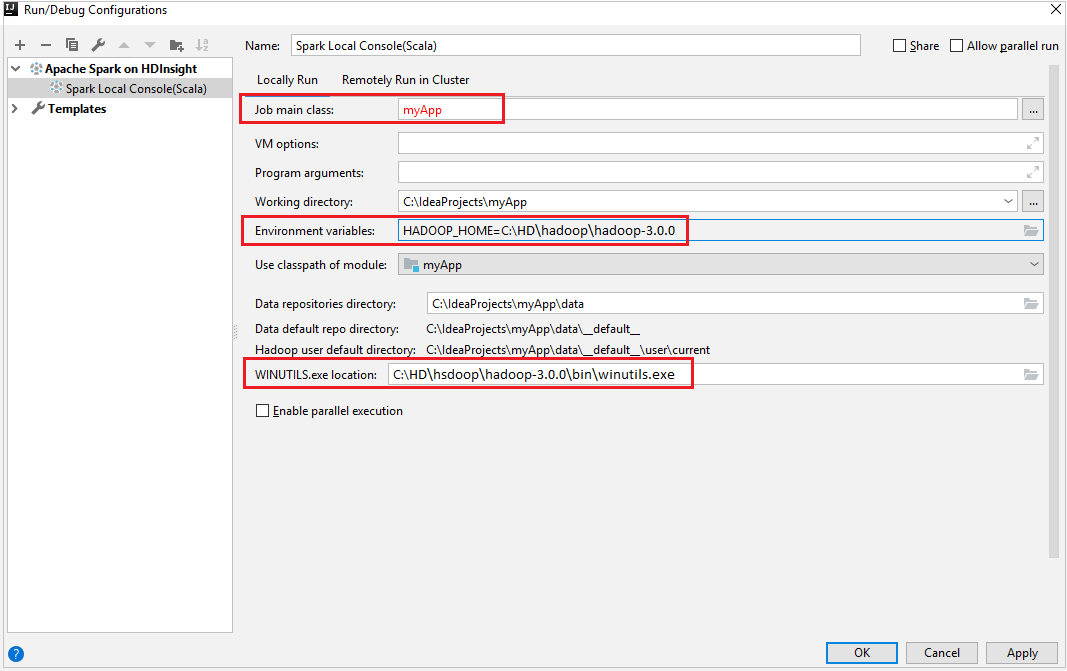
V Projectu přejděte na hlavní>scalu>myApp> src.>
Na řádku nabídek přejděte do konzoly>Nástroje>Sparku, na kterých běží místní konzola Sparku (Scala).
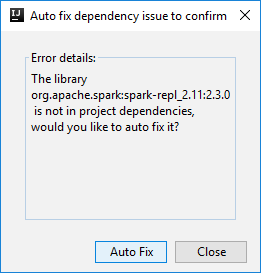
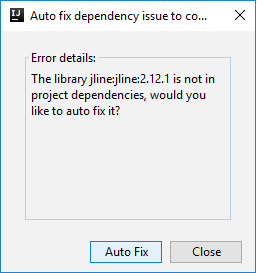
Pak se můžou zobrazit dvě dialogová okna s dotazem, jestli chcete automaticky opravit závislosti. Pokud ano, vyberte Automatická oprava.
Konzola by měla vypadat podobně jako na následujícím obrázku. V okně konzoly zadejte
sc.appNamea stiskněte ctrl+Enter. Zobrazí se výsledek. Místní konzolu můžete ukončit kliknutím na červené tlačítko.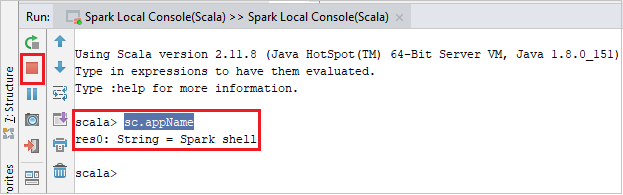
Konzola interaktivní relace Spark Livy (Scala)
Na řádku nabídek přejděte na Příkaz Spustit>konfiguraci úprav....
V okně Konfigurace spuštění/ladění přejděte v levém podokně na Apache Spark ve službě HDInsight>[Spark ve službě HDInsight] myApp.
V hlavním okně vyberte
Remotely Run in Clusterkartu.Zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Clustery Spark (jenom Linux) Vyberte cluster HDInsight Spark, na kterém chcete aplikaci spustit. Název hlavní třídy Výchozí hodnota je hlavní třída z vybraného souboru. Třídu můžete změnit tak, že vyberete tři tečky(...) a zvolíte jinou třídu. 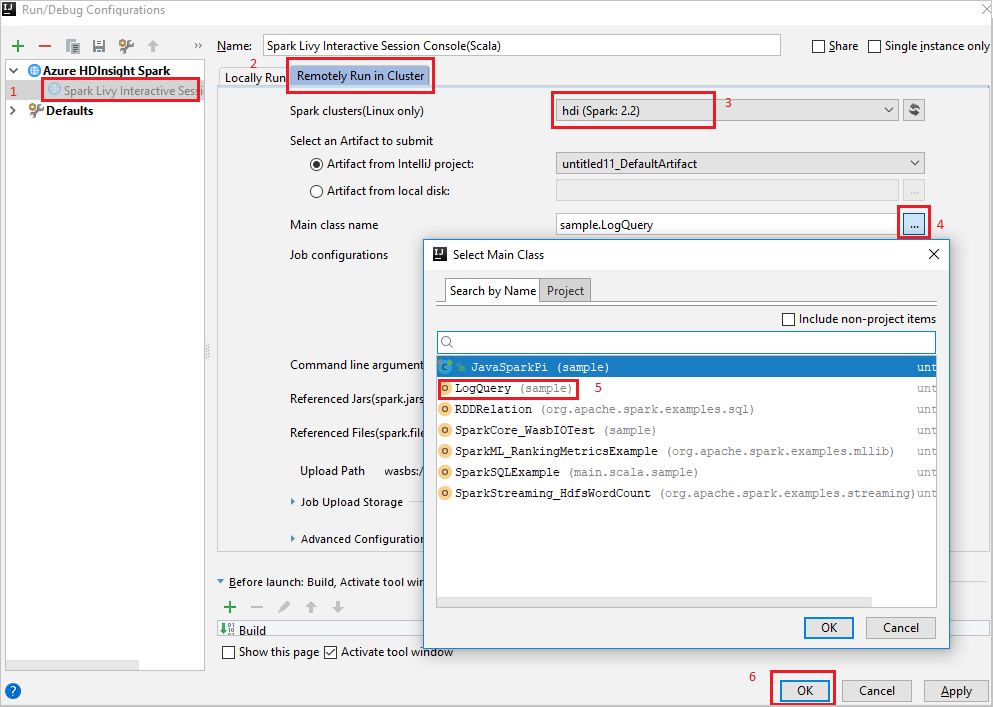
V Projectu přejděte na hlavní>scalu>myApp> src.>
Na řádku nabídek přejděte do konzoly Sparku>pro spuštění konzoly>Spark Livy Interactive Session Console(Scala).
Konzola by měla vypadat podobně jako na následujícím obrázku. V okně konzoly zadejte
sc.appNamea stiskněte ctrl+Enter. Zobrazí se výsledek. Místní konzolu můžete ukončit kliknutím na červené tlačítko.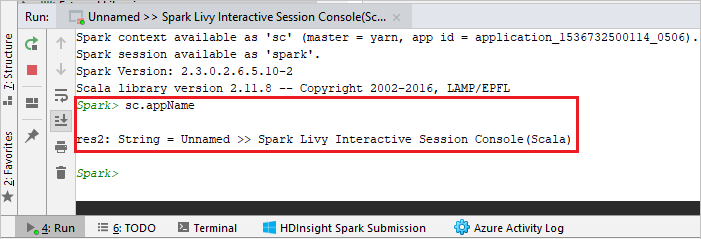
Odeslání výběru do konzoly Sparku
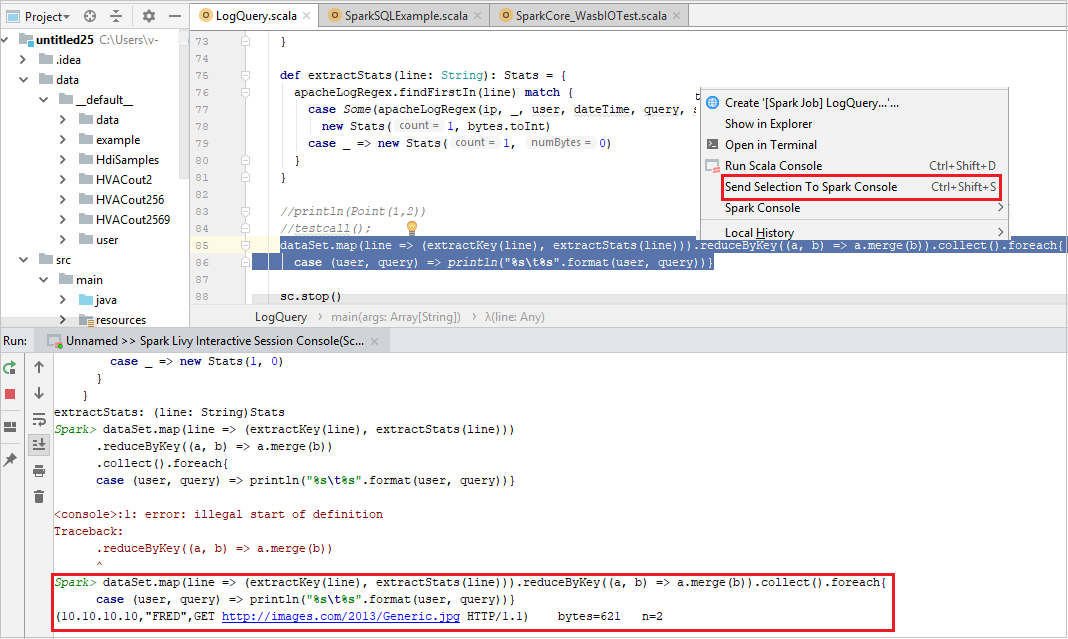
Je vhodné předpovědět výsledek skriptu odesláním kódu do místní konzoly nebo konzoly Livy Interactive Session Console(Scala). V souboru Scala můžete zvýraznit nějaký kód a potom kliknout pravým tlačítkem myši na odeslat výběr do konzoly Sparku. Vybraný kód se odešle do konzoly. Výsledek se zobrazí za kódem v konzole. Konzola zkontroluje chyby, pokud existují.
Integrace se zprostředkovatelem identit HDInsight (HIB)
Připojení do clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB)
Pokud se chcete připojit ke clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB), můžete se přihlásit k předplatnému Azure podle normálních kroků. Po přihlášení se v Azure Exploreru zobrazí seznam clusterů. Další pokyny najdete v tématu Připojení ke clusteru HDInsight.
Spuštění aplikace Spark Scala v clusteru HDInsight ESP s zprostředkovatelem ID (HIB)
Úlohu můžete odeslat do clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB). Další pokyny najdete v tématu Spuštění aplikace Spark Scala v clusteru HDInsight Spark.
Potřebné soubory nahrajeme do složky s názvem vašeho přihlašovacího účtu a v konfiguračním souboru uvidíte cestu k nahrání.

Konzola Spark v clusteru HDInsight ESP s zprostředkovatelem ID (HIB)
Můžete spustit místní konzolu Sparku (Scala) nebo spustit Konzolu interaktivní relace Spark Livy (Scala) v clusteru HDInsight ESP s zprostředkovatelem ID (HIB). Další pokyny najdete v konzole Sparku.
Poznámka:
V případě clusteru HDInsight ESP s zprostředkovatelem ID (HIB) se v současné době nepodporuje propojení clusteru a vzdálené ladění aplikací Apache Spark.
Role jen pro čtení
Když uživatelé odešlou úlohu do clusteru s oprávněním role jen pro čtení, vyžaduje se přihlašovací údaje Ambari.
Propojení clusteru z místní nabídky
Přihlaste se pomocí účtu role jen pro čtení.
V Azure Exploreru rozbalte HDInsight a zobrazte clustery HDInsight, které jsou ve vašem předplatném. Clustery označené jako Role:Reader mají pouze oprávnění role jen pro čtení.
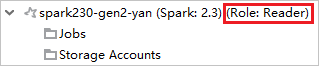
Klikněte pravým tlačítkem na cluster s oprávněním jen pro čtení. Vyberte Propojit tento cluster z místní nabídky pro propojení clusteru. Zadejte uživatelské jméno a heslo Ambari.
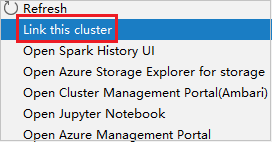
Pokud je cluster úspěšně propojený, služba HDInsight se aktualizuje. Fáze clusteru se propojila.
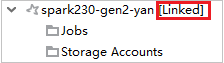
Propojení clusteru rozbalením uzlu Úlohy
Klikněte na uzel Úlohy , zobrazí se okno Odepření přístupu k úloze clusteru.
Kliknutím na Propojit tento cluster propojte cluster.

Propojení clusteru z okna Konfigurace spuštění/ladění
Vytvořte konfiguraci SLUŽBY HDInsight. Pak vyberte Vzdálené spuštění v clusteru.
Vyberte cluster, který má oprávnění role jen pro čtenáře pro clustery Spark (jenom Linux). Zobrazí se zpráva upozornění. Můžete kliknout na Propojit tento cluster a propojit cluster.
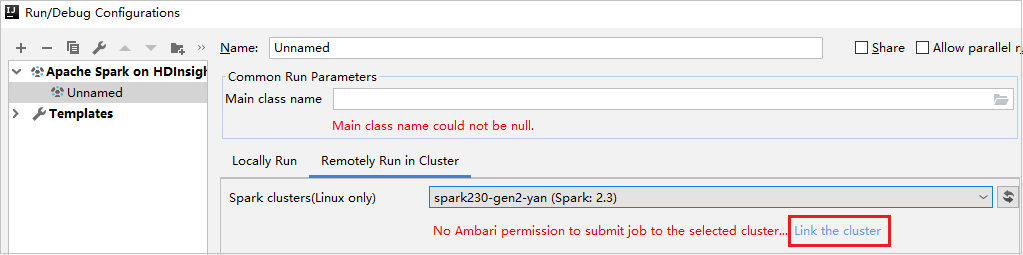
Zobrazení účtů úložiště
U clusterů s oprávněním role jen pro čtení klikněte na uzel Účty úložiště, zobrazí se okno Odepření přístupu k úložišti. Kliknutím na otevřít Průzkumník služby Azure Storage můžete otevřít Průzkumník služby Storage.
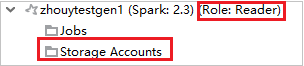

U propojených clusterů klikněte na uzel Účty úložiště, zobrazí se okno Odepření přístupu k úložišti. Kliknutím na Otevřít Azure Storage můžete otevřít Průzkumník služby Storage.

Převod existujících aplikací IntelliJ IDEA na použití sady Azure Toolkit for IntelliJ
Existující aplikace Spark Scala, které jste vytvořili v IntelliJ IDEA, můžete převést tak, aby byly kompatibilní se sadou Azure Toolkit for IntelliJ. Pak můžete pomocí modulu plug-in odeslat aplikace do clusteru HDInsight Spark.
Pro existující aplikaci Spark Scala, která byla vytvořena prostřednictvím IntelliJ IDEA, otevřete přidružený
.imlsoubor.Na kořenové úrovni je element modulu podobný následujícímu textu:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Upravte prvek, který chcete přidat
UniqueKey="HDInsightTool", aby prvek modulu vypadal jako následující text:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Uložte změny. Vaše aplikace by teď měla být kompatibilní se sadou Azure Toolkit for IntelliJ. Můžete ho otestovat tak, že v Projectu kliknete pravým tlačítkem na název projektu. V místní nabídce je teď možnost Odeslat aplikaci Sparku do HDInsightu.
Vyčištění prostředků
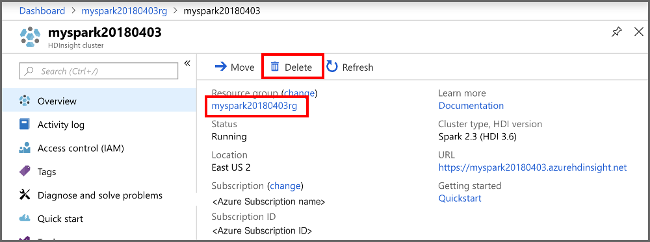
Pokud nebudete tuto aplikaci dál používat, odstraňte cluster, který jste vytvořili, pomocí následujícího postupu:
Přihlaste se k portálu Azure.
Do vyhledávacího pole v horní části zadejte HDInsight.
V části Služby vyberte clustery HDInsight.
V seznamu clusterů HDInsight, které se zobrazí, vyberte ... vedle clusteru, který jste vytvořili pro tento článek.
Vyberte Odstranit. Vyberte Ano.
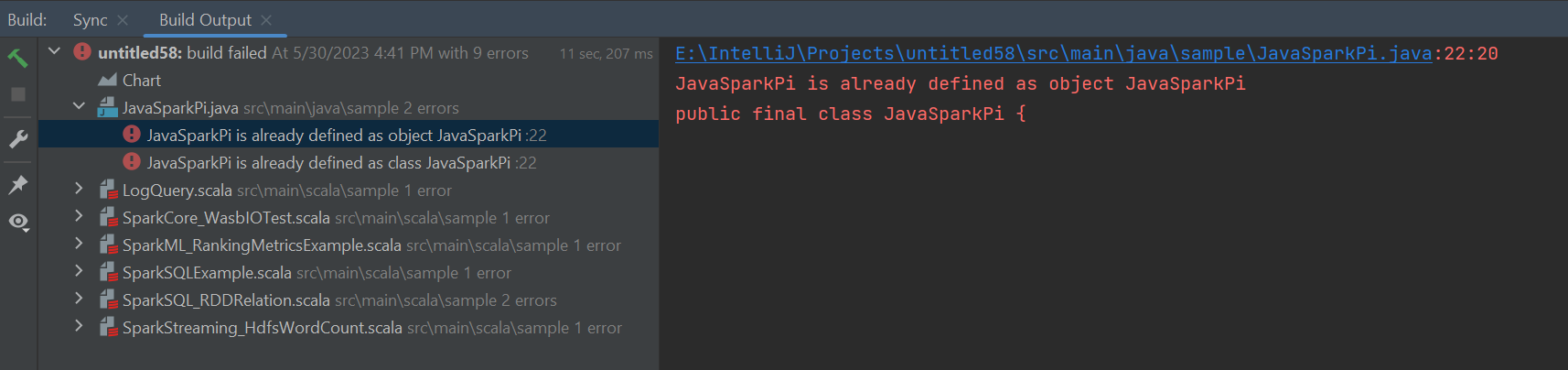
Chyby a řešení
Pokud se zobrazí chyby selhání sestavení, označte složku src jako zdroje následujícím způsobem:
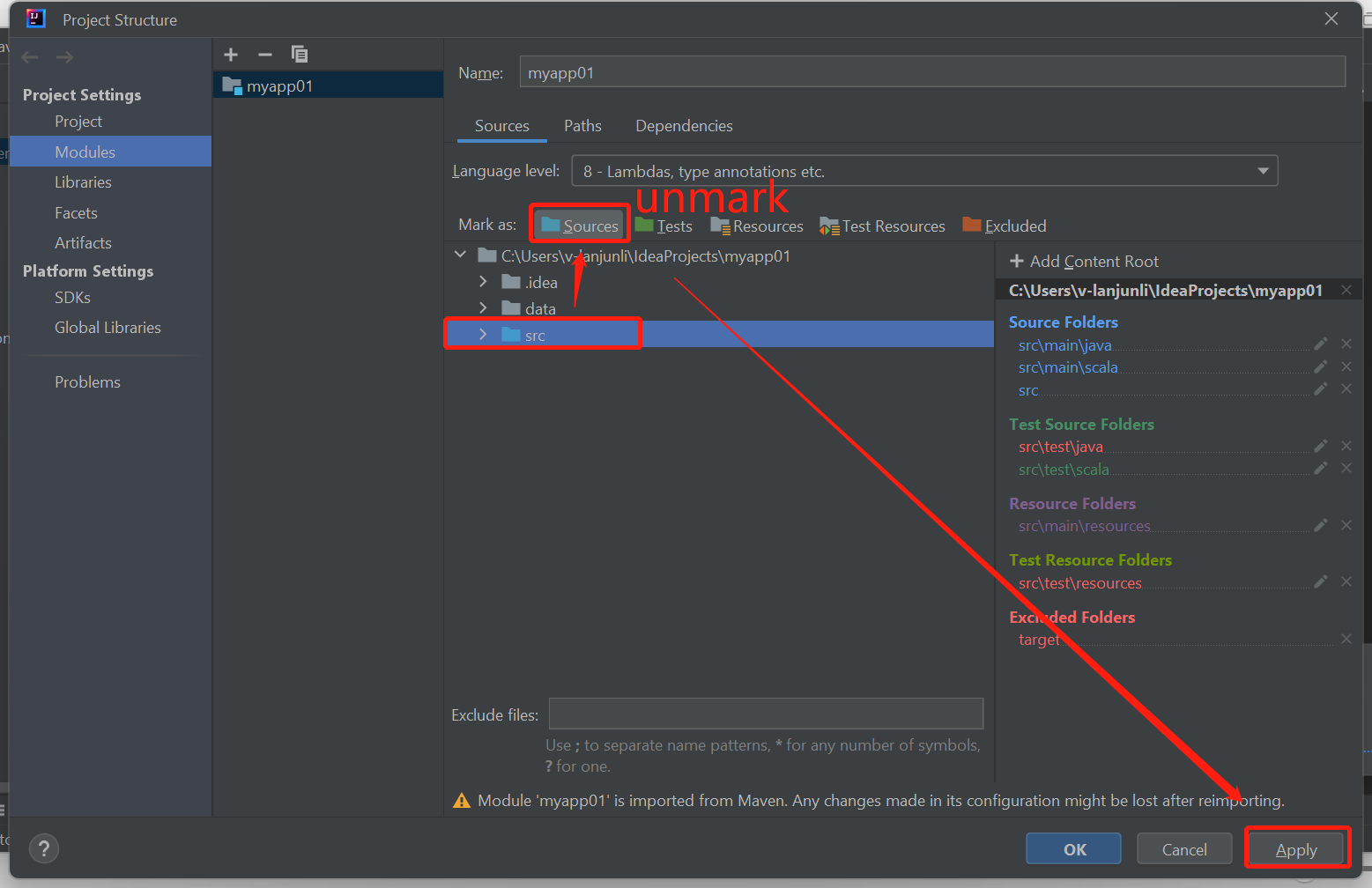
Pokud chcete tento problém vyřešit, zrušte označení složky src jako zdroje :
Přejděte na Soubor a vyberte strukturu projektu.
Vyberte moduly v Nastavení projektu.
Vyberte soubor src a zrušte označení jako zdroje.
Kliknutím na tlačítko Použít a kliknutím na tlačítko OK zavřete dialogové okno.
Další kroky
V tomto článku jste se dozvěděli, jak pomocí modulu plug-in Azure Toolkit for IntelliJ vyvíjet aplikace Apache Spark napsané v jazyce Scala. Pak je odeslal do clusteru HDInsight Spark přímo z integrovaného vývojového prostředí (IDE) IntelliJ. V dalším článku se dozvíte, jak se data zaregistrovaná v Apache Sparku dají načíst do analytického nástroje BI, jako je Power BI.