Co je ML.NET a jak funguje?
ML.NET vám umožňuje přidat strojové učení do aplikací .NET v online nebo offline scénářích. Díky této funkci můžete automatické předpovědi provádět pomocí dat dostupných pro vaši aplikaci. Aplikace strojového učení využívají vzory v datech k vytváření předpovědí místo toho, aby bylo nutné explicitně naprogramovat.
Základem ML.NET je model strojového učení. Model určuje kroky potřebné k transformaci vstupních dat na predikci. Pomocí ML.NET můžete natrénovat vlastní model zadáním algoritmu nebo můžete importovat předem natrénované modely TensorFlow a ONNX.
Jakmile máte model, můžete ho přidat do aplikace, aby se předpovědi vytvořily.
ML.NET běží ve Windows, Linuxu a macOS pomocí .NET nebo Windows pomocí rozhraní .NET Framework. 64bitová verze je podporována na všech platformách. 32bitová verze je podporována ve Windows s výjimkou funkcí Souvisejících s TensorFlow, LightGBM a ONNX.
Následující tabulka uvádí příklady typu předpovědí, které můžete provést pomocí ML.NET.
| Typ předpovědi | Příklad |
|---|---|
| Klasifikace/kategorizace | Automaticky rozdělte zpětnou vazbu zákazníků do kladných a negativních kategorií. |
| Regrese / předpověď průběžných hodnot | Predikce ceny domů na základě velikosti a umístění |
| Detekce anomálií | Detekujte podvodné bankovní transakce. |
| Doporučení | Navrhněte produkty, které si online nakupující můžou chtít koupit na základě předchozích nákupů. |
| Časová řada/sekvenční data | Předpovídá počasí nebo prodej produktů. |
| Klasifikace obrázku | Kategorizovat patologie v lékařských obrázcích. |
| Klasifikace textu | Kategorizovat dokumenty na základě jejich obsahu. |
| Podobnost vět | Změřte, jak jsou podobné dvě věty. |
Hello ML.NET World
Kód v následujícím fragmentu kódu ukazuje nejjednodušší ML.NET aplikaci. Tento příklad vytvoří model lineární regrese, který předpovídá ceny domů pomocí dat o velikosti domu a cenách.
using System;
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
}
Pracovní postup kódu
Následující diagram představuje strukturu kódu aplikace a také iterativní proces vývoje modelu:
- Shromažďování a načítání trénovacích dat do objektu IDataView
- Určení kanálu operací pro extrakci funkcí a použití algoritmu strojového učení
- Trénování modelu voláním Fit() v kanálu
- Vyhodnocení modelu a iterace za účelem zlepšení
- Uložte model do binárního formátu pro použití v aplikaci.
- Načtení modelu zpět do objektu ITransformer
- Vytváření předpovědí voláním CreatePredictionEngine.Predict ()
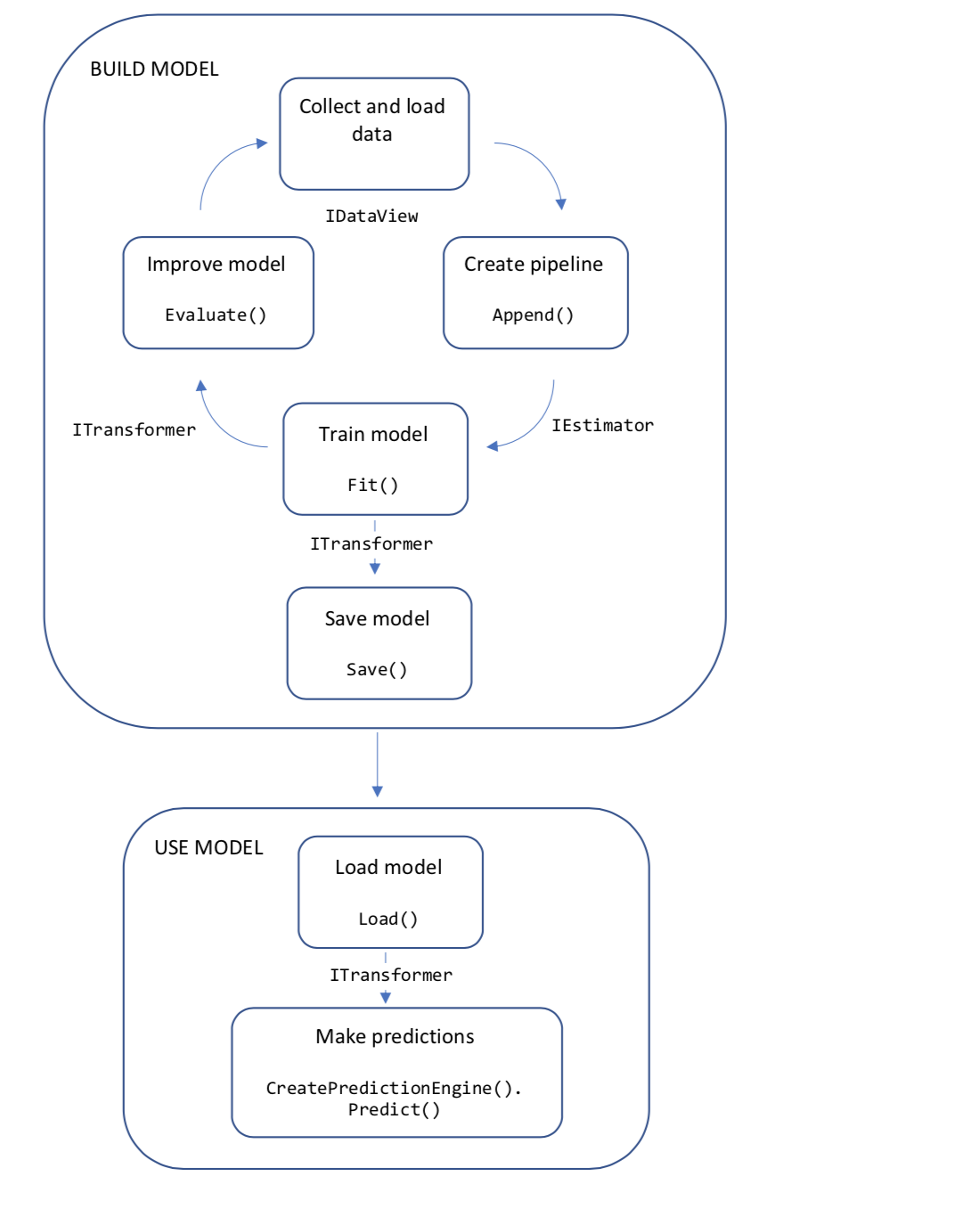
Pojďme se podrobněji podívat na tyto koncepty.
Model strojového učení
Model ML.NET je objekt, který obsahuje transformace, které se mají provést se vstupními daty, aby dorazily na predikovaný výstup.
Basic
Nejzákladnější model je dvourozměrná lineární regrese, kde jedno souvislé množství je úměrné druhému, stejně jako v příkladu ceny domu výše.

Model je jednoduše: $Price = b + Velikost * w$. Parametry $b$ a $w$ se odhadují přizpůsobením čáry na sadu párů (velikost, cena). Data použitá k vyhledání parametrů modelu se nazývají trénovací data. Vstupy modelu strojového učení se nazývají funkce. V tomto příkladu je $Size$ jedinou funkcí. Hodnoty základní pravdy používané k trénování modelu strojového učení se nazývají popisky. Tady jsou popisky hodnot $Price$ v trénovací sadě dat.
Složitější
Složitější model klasifikuje finanční transakce do kategorií pomocí popisu textu transakce.
Každý popis transakce je rozdělen do sady funkcí odebráním nadbytečných slov a znaků a počítáním kombinací slov a znaků. Sada funkcí se používá k trénování lineárního modelu na základě sady kategorií v trénovacích datech. Čím více se nový popis podobá těm, které jsou v trénovací sadě, tím pravděpodobnější je, že se přiřadí stejné kategorii.

Cenový model domu i model klasifikace textu jsou lineární modely. V závislosti na povaze dat a problému, který řešíte, můžete také použít modely rozhodovacího stromu , generalizované doplňkové modely a další. Další informace omodelch
Příprava dat
Ve většině případů nejsou data, která máte k dispozici, vhodná pro přímé použití k trénování modelu strojového učení. Nezpracovaná data je potřeba připravit nebo předzpracovat, aby bylo možné je použít k vyhledání parametrů modelu. Data může být potřeba převést z řetězcových hodnot na číselnou reprezentaci. Ve vstupních datech můžete mít redundantní informace. Možná budete muset snížit nebo rozšířit dimenze vstupních dat. Vaše data může být potřeba normalizovat nebo škálovat.
Kurzy ML.NET vás naučí různé kanály zpracování dat pro text, obrázek, číselná data a data časových řad používaná pro konkrétní úlohy strojového učení.
Jak připravit data , ukazuje, jak obecněji použít přípravu dat.
Dodatek ke všem dostupným transformacím najdete v části prostředky.
Vyhodnocení modelu
Jakmile model vytrénujete, jak dobře poznáte, že bude provádět budoucí předpovědi? S ML.NET můžete model vyhodnotit na základě některých nových testovacích dat.
Každý typ úlohy strojového učení obsahuje metriky, které slouží k vyhodnocení přesnosti a přesnosti modelu vůči testovací sadě dat.
V našem příkladu ceny domu jsme použili regresní úlohu. Pokud chcete model vyhodnotit, přidejte do původní ukázky následující kód.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
Metriky vyhodnocení vám říkají, že chyba je nízká a že korelace mezi predikovaným výstupem a výstupem testu je vysoká. To byla hračka! V reálných příkladech vyžaduje lepší ladění, aby bylo možné dosáhnout dobrých metrik modelu.
architektura ML.NET
Tato část popisuje architektonické vzory ML.NET. Pokud jste zkušený vývojář rozhraní .NET, některé z těchto vzorů budou pro vás známé a některé budou méně známé.
Aplikace ML.NET začíná objektem MLContext . Tento singleton objekt obsahuje katalogy. Katalog je továrna pro načítání a ukládání dat, transformace, trenéry a komponenty operací modelu. Každý objekt katalogu má metody pro vytvoření různých typů komponent.
| Úloha | Katalog |
|---|---|
| Načítání a ukládání dat | DataOperationsCatalog |
| Příprava dat | TransformsCatalog |
| Binární klasifikace | BinaryClassificationCatalog |
| Klasifikace s více třídami | MulticlassClassificationCatalog |
| Detekce anomálií | AnomalyDetectionCatalog |
| Clustering | ClusteringCatalog |
| Prognostika | ForecastingCatalog |
| Hodnocení | RankingCatalog |
| Regrese | RegressionCatalog |
| Doporučení | RecommendationCatalog |
| Časové řady | TimeSeriesCatalog |
| Využití modelu | ModelOperationsCatalog |
V každé z výše uvedených kategorií můžete přejít na metody vytváření. Pomocí sady Visual Studio se katalogy zobrazují prostřednictvím technologie IntelliSense.
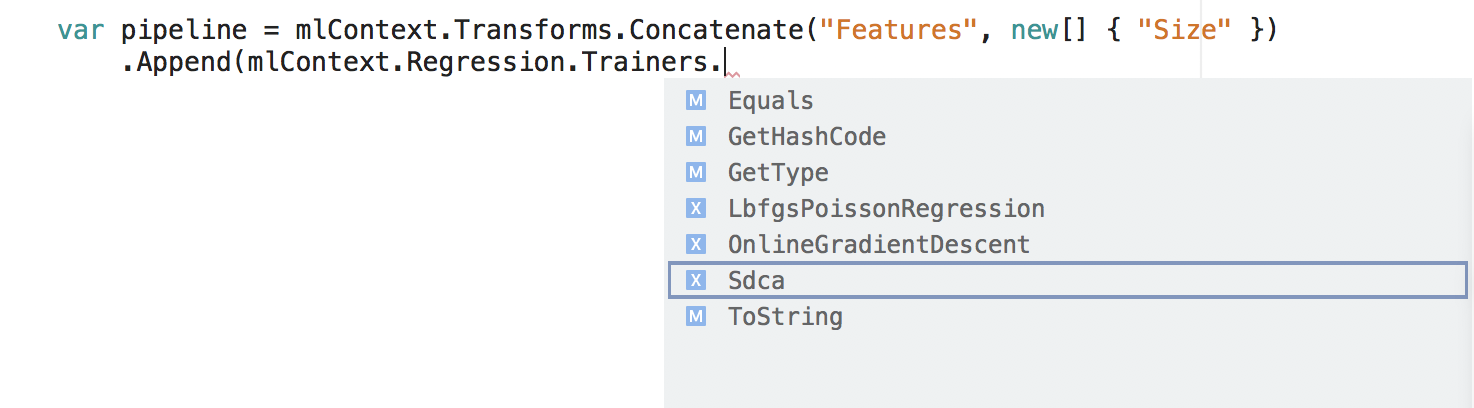
Sestavení kanálu
Uvnitř každého katalogu je sada rozšiřujících metod, které můžete použít k vytvoření trénovacího kanálu.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
V fragmentu kódu Concatenate jsou Sdca obě metody v katalogu. Každý z nich vytvoří objekt IEstimator , který je připojený k kanálu.
V tomto okamžiku se objekty vytvořily, ale nedošlo k žádnému spuštění.
Trénování modelu
Po vytvoření objektů v kanálu je možné data použít k trénování modelu.
var model = pipeline.Fit(trainingData);
Volání Fit() používá vstupní trénovací data k odhadu parametrů modelu. To se označuje jako trénování modelu. Nezapomeňte, že model lineární regrese zobrazený dříve měl dva parametry modelu: předsudky a hmotnost. Fit() Po volání jsou známy hodnoty parametrů. (Většinamodelůch
Další informace o trénování modelu najdete v tématu Postup trénování modelu.
Výsledný objekt modelu implementuje ITransformer rozhraní. To znamená, že model transformuje vstupní data na předpovědi.
IDataView predictions = model.Transform(inputData);
Použití modelu
Vstupní data můžete transformovat na předpovědi hromadně nebo jeden vstup najednou. Příklad ceny domu udělal obojí: hromadně pro účely vyhodnocení modelu a jeden po druhém k vytvoření nové předpovědi. Pojďme se podívat na vytváření jednoduchých předpovědí.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
Metoda CreatePredictionEngine() přebírá vstupní třídu a výstupní třídu. Názvy polí nebo atributy kódu určují názvy datových sloupců používaných při trénování a predikci modelu. Další informace najdete v tématu Vytváření předpovědí pomocí natrénovaného modelu.
Datové modely a schéma
Jádrem kanálu ML.NET strojového učení jsou objekty DataView .
Každá transformace v kanálu má vstupní schéma (názvy dat, typy a velikosti, které transformace očekává ve vstupu); a výstupní schéma (názvy dat, typy a velikosti, které transformace vytvoří po transformaci).
Pokud výstupní schéma z jedné transformace v kanálu neodpovídá vstupnímu schématu další transformace, ML.NET vyvolá výjimku.
Objekt zobrazení dat má sloupce a řádky. Každý sloupec má název a typ a délku. Například vstupní sloupce v příkladu ceny domu jsou Velikost a Cena. Jedná se o typ a jedná se o skalární množství, nikoli vektorové.

Všechny ML.NET algoritmy hledají vstupní sloupec, který je vektorem. Ve výchozím nastavení se tento vektorový sloupec nazývá Funkce. Proto příklad ceny domu zřetězený sloupec Velikost do nového sloupce s názvem Funkce.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
Všechny algoritmy také vytvářejí nové sloupce po provedení předpovědi. Pevné názvy těchto nových sloupců závisí na typu algoritmu strojového učení. U regresní úlohy se jeden z nových sloupců nazývá Skóre , jak je znázorněno v atributu dat o cenách.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
Další informace o výstupníchsloupcch Učení ch
Důležitou vlastností Objekty DataView je, že jsou vyhodnoceny lazily. Zobrazení dat se načítají a provozují pouze během trénování a vyhodnocování modelu a předpovědi dat. Při psaní a testování aplikace ML.NET můžete pomocí ladicího programu sady Visual Studio zobrazit náhled na libovolný objekt zobrazení dat voláním metody Preview .
var debug = testPriceDataView.Preview();
Proměnnou debug v ladicím programu můžete sledovat a zkoumat její obsah. Nepoužívejte v produkčním kódu metodu Preview, protože výrazně snižuje výkon.
Nasazení modelu
V reálných aplikacích se trénování a vyhodnocení modelu oddělí od předpovědi. Tyto dvě aktivity jsou ve skutečnosti často prováděny samostatnými týmy. Vývojový tým modelů může model uložit pro použití v prediktivní aplikaci.
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
Další kroky
Naučte se vytvářet aplikace pomocí různých úloh strojového učení s realističtějšími sadami dat v kurzech.
Podrobnější informace o konkrétních tématech najdete v průvodcích postupy.
Pokud máte super zájem, můžete se rovnou ponořit do referenční dokumentace k rozhraní API.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro