Kurz: Automatizovaná vizuální kontrola s využitím učení přenosu s využitím rozhraní API pro klasifikaci obrázků ML.NET
Naučte se vytrénovat vlastní model hlubokého učení pomocí transferového učení, předem vytrénovaného modelu TensorFlow a rozhraní API pro klasifikaci obrázků ML.NET Image Classification, aby se obrázky betonových povrchů klasifikovaly jako popraskané nebo nezalomené.
V tomto kurzu se naučíte:
- Pochopení problému
- Informace o rozhraní API pro klasifikaci obrázků ML.NET
- Vysvětlení předem vytrénovaného modelu
- Použití učení přenosu k trénování vlastního modelu klasifikace obrázků TensorFlow
- Klasifikace obrázků pomocí vlastního modelu
Požadavky
Přehled ukázky výuky pro klasifikaci přenosů obrázků
Tato ukázka je konzolová aplikace C# .NET Core, která klasifikuje obrázky pomocí předem vytrénovaného modelu TensorFlow pro hluboké učení. Kód pro tuto ukázku najdete v prohlížeči ukázek.
Pochopení problému
Klasifikace obrázků je problém počítačového zpracování obrazu. Klasifikace obrázků vezme obrázek jako vstup a zařadí ho do předepsané třídy. Modely klasifikace obrázků se běžně trénují pomocí hlubokého učení a neurálních sítí. Další informace najdete v tématu Hluboké učení vs. strojové učení .
Mezi scénáře, ve kterých je klasifikace obrázků užitečná, patří:
- Rozpoznávání obličeje
- Detekce emocí
- Lékařská diagnostika
- Detekce orientačních bodů
Tento kurz trénuje vlastní model klasifikace obrázků, který provádí automatickou vizuální kontrolu mostovek a identifikuje struktury poškozené prasklinami.
rozhraní API pro klasifikaci obrázků ML.NET
ML.NET poskytuje různé způsoby klasifikace obrázků. Tento kurz aplikuje výuku přenosu pomocí rozhraní API pro klasifikaci obrázků. Rozhraní API pro klasifikaci obrázků využívá TensorFlow.NET, nízkoúrovňovou knihovnu, která poskytuje vazby jazyka C# pro rozhraní API TensorFlow jazyka C++.
Co je transferové učení?
Transfer learning aplikuje znalosti získané při řešení jednoho problému na jiný související problém.
Trénování modelu hlubokého učení od nuly vyžaduje nastavení několika parametrů, velkého množství označených trénovacích dat a obrovského množství výpočetních prostředků (stovky hodin GPU). Použití předem vytrénovaného modelu spolu s převodem učení vám umožní sesunout proces trénování.
Proces trénování
Rozhraní API pro klasifikaci obrázků zahájí proces trénování načtením předem vytrénovaného modelu TensorFlow. Proces trénování se skládá ze dvou kroků:
- Fáze kritického bodu
- Fáze trénování
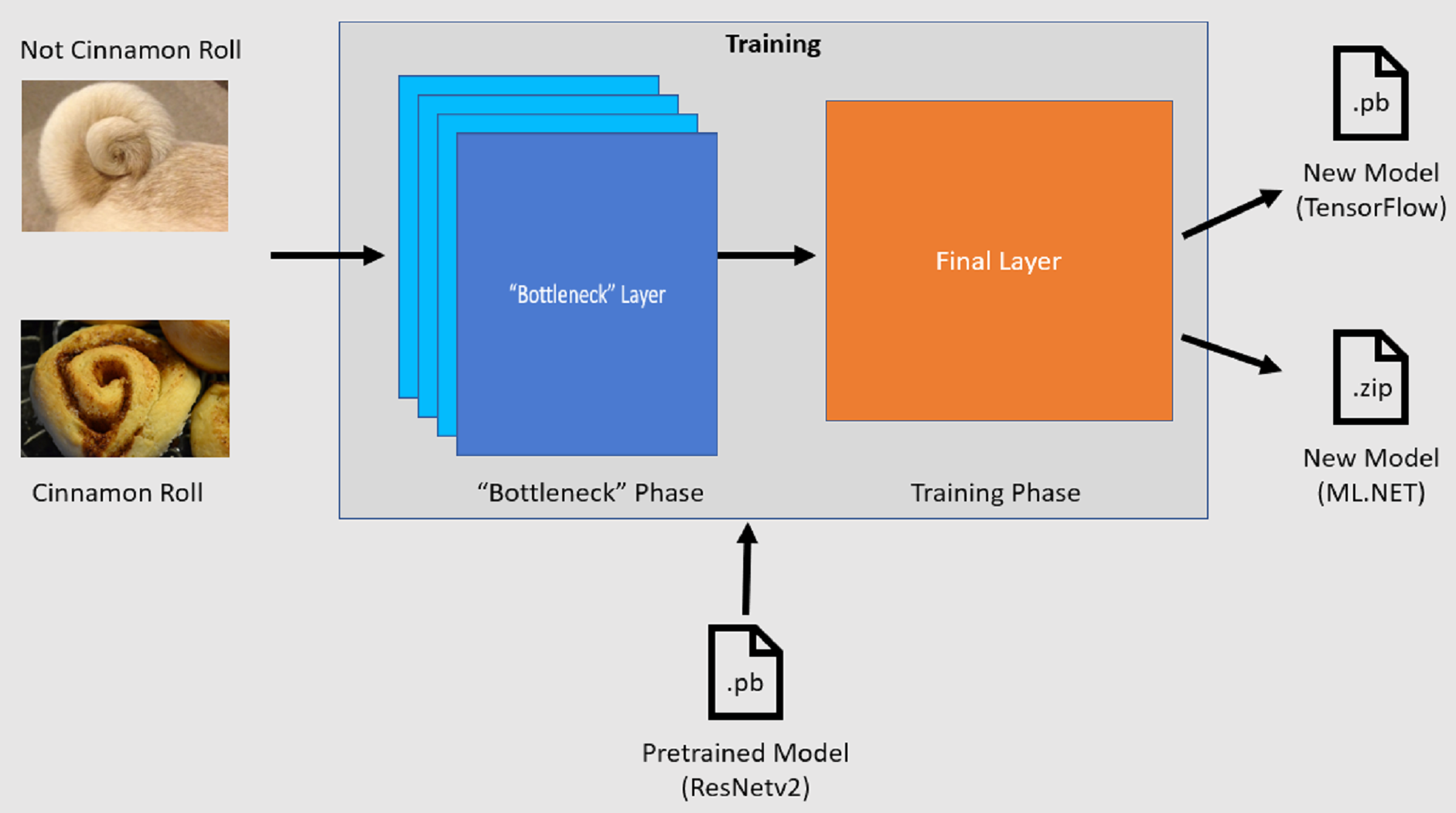
Fáze kritického bodu
Během kritické fáze se načte sada trénovacích obrázků a hodnoty pixelů se použijí jako vstup nebo funkce pro zamrzlé vrstvy předem natrénovaného modelu. Zamrzlé vrstvy zahrnují všechny vrstvy v neurální síti až do předposlední vrstvy, neformálně označované jako vrstva kritického bodu. Tyto vrstvy se označují jako zamrzlé, protože na těchto vrstvách nedojde k trénování a operace jsou průchozí. Právě v těchto zamrzlých vrstvách se počítají vzory nižší úrovně, které modelu pomáhají rozlišovat mezi různými třídami. Čím větší je počet vrstev, tím je tento krok výpočetně náročnější. Vzhledem k tomu, že se jedná o jednorázový výpočet, je možné výsledky uložit do mezipaměti a použít je v pozdějších spuštěních při experimentování s různými parametry.
Fáze trénování
Po výpočtu výstupních hodnot z fáze kritického bodu se použijí jako vstup k přetrénování poslední vrstvy modelu. Tento proces je iterativní a spouští se po dobu určenou parametry modelu. Během každého spuštění se vyhodnocují ztráty a přesnost. Poté se provedou příslušné úpravy pro vylepšení modelu s cílem minimalizovat ztrátu a maximalizovat přesnost. Po dokončení trénování jsou výstupem dva formáty modelu. Jedním z nich je .pb verze modelu a druhou je .zip ML.NET serializovaná verze modelu. Při práci v prostředích podporovaných ML.NET se doporučuje používat .zip verzi modelu. V prostředích, ve kterých se ML.NET nepodporuje, ale máte možnost použít .pb verzi.
Vysvětlení předem vytrénovaného modelu
Předtrénovaný model použitý v tomto kurzu je variantou 101 vrstvy modelu Zbytková síť (ResNet) verze 2. Původní model je vytrénovaný tak, aby klasifikoval obrázky do tisíců kategorií. Model vezme jako vstup obrázek o velikosti 224 x 224 a vypíše pravděpodobnosti třídy pro každou z tříd, na které je trénován. Část tohoto modelu slouží k trénování nového modelu pomocí vlastních obrázků k vytváření predikcí mezi dvěma třídami.
Vytvoření konzolové aplikace
Teď, když máte obecné znalosti o transferovém učení a rozhraní API pro klasifikaci obrázků, je čas sestavit aplikaci.
Vytvořte konzolovou aplikaci jazyka C# s názvem "DeepLearning_ImageClassification_Binary". Klikněte na tlačítko Další .
Jako architekturu, kterou chcete použít, zvolte .NET 6. Klikněte na tlačítko Vytvořit.
Nainstalujte balíček NuGet Microsoft.ML :
Poznámka
Tato ukázka používá nejnovější stabilní verzi uvedených balíčků NuGet, pokud není uvedeno jinak.
- V Průzkumník řešení klikněte pravým tlačítkem na projekt a vyberte Spravovat balíčky NuGet.
- Jako zdroj balíčku zvolte "nuget.org".
- Vyberte kartu Procházet.
- Zaškrtněte políčko Zahrnout předběžné verze .
- Vyhledejte Microsoft.ML.
- Vyberte tlačítko Nainstalovat .
- V dialogovém okně Náhled změn vyberte tlačítko OK a pak v dialogovém okně Přijetí licence vyberte tlačítko Souhlasím, pokud souhlasíte s licenčními podmínkami pro uvedené balíčky.
- Opakujte tento postup pro balíčky NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist verze 2.3.1 a Microsoft.ML.ImageAnalytics .
Příprava a pochopení dat
Poznámka
Datové sady pro tento kurz jsou od Maguire, Marc; Dorafshan, Sattar; a Thomas, Robert J., "SDNET2018: A concrete crack image dataset for machine learning applications" (2018). Projděte si všechny datové sady. Dokument 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 je datová sada obrázků, která obsahuje poznámky pro prasklé a nepopraskané betonové konstrukce (mostovky, stěny a chodníky).

Data jsou uspořádaná do tří podadresářů:
- D obsahuje obrázky mostovek.
- P obsahuje obrázky chodníků.
- W obsahuje obrázky zdí.
Každý z těchto podadresářů obsahuje dva další podadresáře s předponou:
- C je předpona používaná pro prasklé povrchy.
- U je předpona používaná pro nezkrácené povrchy.
V tomto kurzu se používají pouze obrázky mostovek.
- Stáhněte si datovou sadu a rozbalte ji.
- Vytvořte v projektu adresář s názvem "assets" pro uložení souborů datové sady.
- Zkopírujte podadresáře CD a UD z nedávno rozbaleného adresáře do adresáře assets .
Vytvoření vstupních a výstupních tříd
Otevřete soubor Program.cs a nahraďte existující
usingpříkazy v horní části souboru následujícím kódem:using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;ProgramPod třídou v souboru Program.cs vytvořte třídu s názvemImageData. Tato třída se používá k reprezentaci původně načtených dat.class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageDataobsahuje následující vlastnosti:ImagePathje plně kvalifikovaná cesta, ve které je uložená image.Labelje kategorie, do které obrázek patří. Jedná se o hodnotu, kterou je potřeba předpovědět.
Vytvoření tříd pro vstupní a výstupní data
ImageDataPod třídou definujte schéma vstupních dat v nové třídě s názvemModelInput.class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInputobsahuje následující vlastnosti:Imagebyte[]je reprezentace obrázku. Model očekává, že data obrázku budou pro trénování tohoto typu.LabelAsKeyje číselná reprezentaceLabel.ImagePathje plně kvalifikovaná cesta, ve které je uložená image.Labelje kategorie, do které obrázek patří. Jedná se o hodnotu, kterou je potřeba předpovědět.
Slouží pouze
ImagekLabelAsKeytrénování modelu a vytváření předpovědí. VlastnostiImagePathaLabelse uchovávají pro usnadnění přístupu k názvu a kategorii původního souboru obrázku.Potom pod
ModelInputtřídou definujte schéma výstupních dat v nové třídě s názvemModelOutput.class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutputobsahuje následující vlastnosti:ImagePathje plně kvalifikovaná cesta, ve které je uložená image.Labelje původní kategorie, do které obrázek patří. Jedná se o hodnotu, kterou je potřeba předpovědět.PredictedLabelje hodnota předpovězená modelem.
Podobně jako u
ModelInput, se k předpovědím vyžaduje pouzePredictedLabelhodnota , protože obsahuje predikci provedenou modelem. VlastnostiImagePathaLabelse uchovávají pro usnadnění přístupu k názvu a kategorii původního souboru obrázku.
Vytvoření adresáře pracovního prostoru
Pokud se trénovací a ověřovací data nemění často, je vhodné ukládat vypočítané hodnoty kritických bodů do mezipaměti pro další běhy.
- V projektu vytvořte nový adresář s názvem pracovní prostor pro ukládání vypočítaných kritických bodů a
.pbverze modelu.
Definování cest a inicializace proměnných
Pod příkazy using definujte umístění prostředků, vypočítané hodnoty kritických bodů a
.pbverzi modelu.var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");Inicializuje proměnnou
mlContexts novou instancí MLContext.MLContext mlContext = new MLContext();Třída MLContext je výchozím bodem pro všechny operace ML.NET a inicializace mlContext vytvoří nové ML.NET prostředí, které lze sdílet napříč objekty pracovního postupu vytváření modelu. Koncepčně
DbContextje to podobné jako v Entity Frameworku.
Načtení dat
Vytvoření metody nástroje pro načítání dat
Obrázky jsou uložené ve dvou podadresářích. Před načtením dat je potřeba je naformátovat do seznamu ImageData objektů. Uděláte to tak, že vytvoříte metodu LoadImagesFromDirectory .
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
Do souboru
LoadImagesFromDirectorypřidejte následující kód pro získání všech cest k souborům z podadresářů:var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);Pak pomocí příkazu iterujte jednotlivé soubory
foreach.foreach (var file in files) { }Uvnitř příkazu
foreachzkontrolujte, jestli jsou podporované přípony souborů. Rozhraní API pro klasifikaci obrázků podporuje formáty JPEG a PNG.if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;Pak získejte popisek souboru.
useFolderNameAsLabelPokud je parametr nastavený natruehodnotu , použije se jako popisek nadřazený adresář, ve kterém je soubor uložen. V opačném případě očekává, že popisek bude předponou názvu souboru nebo samotného názvu souboru.var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }Nakonec vytvořte novou instanci objektu
ModelInput.yield return new ImageData() { ImagePath = file, Label = label };
Příprava dat
Voláním
LoadImagesFromDirectorymetody nástroje získáte seznam obrázků používaných pro trénování po inicializacimlContextproměnné.IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);Potom pomocí metody načtěte obrázky do
IDataViewobjektuLoadFromEnumerable.IDataView imageData = mlContext.Data.LoadFromEnumerable(images);Data se načtou v pořadí, v jakém byla načtena z adresářů. Pokud chcete data vyvážit, zamícháte je pomocí
ShuffleRowsmetody .IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);Modely strojového učení očekávají, že vstup bude v číselném formátu. Proto je potřeba před trénováním provést určité předběžné zpracování dat. Vytvořte objekt
EstimatorChainsložený zMapValueToKeytransformací aLoadRawImageBytes. TransformaceMapValueToKeypřevezme hodnotu kategorie veLabelsloupci, převede ji na číselnouKeyTypehodnotu a uloží ji do nového sloupce s názvemLabelAsKey. NástrojLoadImagespřevezme hodnoty zeImagePathsloupce spolu s parametremimageFoldera načte obrázky pro trénování.var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));Použijte metodu
Fitk použití dat na metodupreprocessingPipelineEstimatorChainnásledovanou metodouTransform, která vrátíIDataViewhodnotu obsahující předem zpracovaná data.IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);K trénování modelu je důležité mít trénovací datovou sadu i ověřovací datovou sadu. Model se trénuje na trénovací sadě. Jak dobře se predikce u neviděných dat měří výkonem proti ověřovací sadě. Na základě výsledků tohoto výkonu model provádí úpravy toho, co se naučil ve snaze zlepšit. Ověřovací sada může pocházet buď z rozdělení původní datové sady, nebo z jiného zdroje, který už byl pro tento účel vyhrazen. V tomto případě se předem zpracovaná datová sada rozdělí na trénovací, ověřovací a testovací sady.
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);Výše uvedená ukázka kódu provádí dvě rozdělení. Nejprve se předem zpracovaná data rozdělí a 70 % se použije pro trénování, zatímco zbývajících 30 % se použije k ověření. Pak se 30% ověřovací sada dále rozdělí na ověřovací a testovací sady, kde se 90 % použije k ověření a 10 % pro testování.
Způsob, jak přemýšlet o účelu těchto datových oddílů, je provedení zkoušky. Při studiu na zkoušku si projdete poznámky, knihy nebo jiné zdroje, abyste získali přehled o konceptech, které jsou na zkoušce. K tomu slouží vlaková sada. Pak můžete absolvovat napodobenou zkoušku, abyste ověřili své znalosti. Tady se hodí ověřovací sada. Před provedením skutečné zkoušky chcete zkontrolovat, jestli máte přehled o konceptech. Na základě těchto výsledků si povšimnete, co jste udělali špatně nebo čemu jste dobře nerozuměli, a při kontrole skutečné zkoušky zapracujete změny. Nakonec složíte zkoušku. K tomuto slouží testovací sada. Nikdy jste neviděli otázky, které jsou na zkoušce, a teď použijete to, co jste se naučili z trénování a ověření, k tomu, abyste své znalosti použili k danému úkolu.
Přiřaďte oddílům jejich odpovídající hodnoty pro trénování, ověřování a testování dat.
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
Definování trénovacího kanálu
Trénování modelu se skládá z několika kroků. Nejprve se k trénování modelu použije rozhraní API pro klasifikaci obrázků. Potom se kódované popisky ve PredictedLabel sloupci pomocí transformace převedou zpět na původní hodnotu MapKeyToValue kategorií.
Vytvořte novou proměnnou pro uložení sady povinných a volitelných parametrů pro ImageClassificationTrainer.
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };Má ImageClassificationTrainer několik volitelných parametrů:
FeatureColumnNameje sloupec, který se používá jako vstup pro model.LabelColumnNameje sloupec pro hodnotu, kterou chcete předpovědět.ValidationSetje obsahujícíIDataViewověřovací data.Archdefinuje, kterou z předtrénovaných architektur modelů použít. V tomto kurzu se používá varianta 101 vrstvy modelu ResNetv2.MetricsCallbackvytvoří vazbu funkce pro sledování průběhu trénování.TestOnTrainSetříká modelu, aby změřil výkon trénovací sady, pokud není k dispozici žádná ověřovací sada.ReuseTrainSetBottleneckCachedValuesřekne modelu, jestli se mají při dalších spuštěních použít hodnoty uložené v mezipaměti z fáze kritického bodu. Fáze kritického bodu je jednorázový průchozí výpočet, který je výpočetně náročný při prvním provedení. Pokud se trénovací data nezmění a chcete experimentovat s použitím jiného počtu epoch nebo velikosti dávky, použití hodnot uložených v mezipaměti výrazně zkrátí dobu potřebnou k trénování modelu.ReuseValidationSetBottleneckCachedValuesje podobnýReuseTrainSetBottleneckCachedValuesjenom jako v tomto případě pro ověřovací datovou sadu.WorkspacePathdefinuje adresář, do kterého se mají ukládat hodnoty vypočítaných kritických bodů a.pbverze modelu.
EstimatorChainDefinujte trénovací kanál, který se skládá zmapLabelEstimatorImageClassificationTrainera .var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));K trénování modelu použijte metodu
Fit.ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Použití modelu
Teď, když jste model vytrénovali, je čas ho použít ke klasifikaci obrázků.
Vytvořte novou metodu nástroje s názvem OutputPrediction pro zobrazení informací o predikci v konzole nástroje.
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Klasifikace jednoho obrázku
Vytvořte novou metodu s názvem
ClassifySingleImagepro vytvoření a výstup jedné předpovědi obrázku.void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Vytvořte
PredictionEngineuvnitřClassifySingleImagemetody. Jedná sePredictionEngineo rozhraní API pro pohodlí, které umožňuje předat a pak provést predikci na jedné instanci dat.PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);Pokud chcete získat přístup k jedné
ModelInputinstanci, převeďte ji naIEnumerabledataIDataViewCreateEnumerablepomocí metody a pak získejte první pozorování.ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();Ke klasifikaci obrázku
Predictpoužijte metodu .ModelOutput prediction = predictionEngine.Predict(image);Vypíšete predikci do konzoly
OutputPredictionpomocí metody .Console.WriteLine("Classifying single image"); OutputPrediction(prediction);Voláním metody pomocí testovací sady obrázků zavolejte
ClassifySingleImagemetodu nížeFit.ClassifySingleImage(mlContext, testSet, trainedModel);
Klasifikace více obrázků
Pod metodu přidejte novou metodu
ClassifySingleImages názvemClassifyImages, která vytvoří a vypíše více předpovědí obrázků.void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Pomocí
IDataViewmetody vytvořte objekt obsahující predikceTransform. Do metody přidejte následující kódClassifyImages.IDataView predictionData = trainedModel.Transform(data);Pokud chcete iterovat předpovědi, převeďte metodu na
predictionDataIDataViewmetoduIEnumerableCreateEnumerablea pak získejte prvních 10 pozorování.IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);Iterujte a vypíšete původní a předpovězené popisky pro předpovědi.
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }Nakonec zavolejte
ClassifyImagespod metodouClassifySingleImage()pomocí testovací sady obrázků.ClassifyImages(mlContext, testSet, trainedModel);
Spuštění aplikace
Spusťte svou konzolovou aplikaci. Výstup by měl být podobný následujícímu. Může se zobrazit upozornění nebo zpracování zpráv, ale tyto zprávy byly z následujících výsledků pro přehlednost odebrány. Pro stručnost byl výstup zhuštěný.
Fáze kritického bodu
Pro název obrázku se nevytiskne žádná hodnota, protože obrázky jsou načteny jako obrázek, byte[] a proto neexistuje žádný název obrázku, který by se měl zobrazit.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fáze trénování
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Klasifikace výstupu obrázků
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Při kontrole 7001-220.jpg obrázku můžete vidět, že ve skutečnosti není prasklý.

Gratulujeme! Teď jste úspěšně vytvořili model hlubokého učení pro klasifikaci obrázků.
Vylepšení modelu
Pokud nejste spokojení s výsledky modelu, můžete se pokusit zlepšit jeho výkon vyzkoušením některých z následujících přístupů:
- Více dat: Čím více příkladů se model učí, tím lépe funguje. Stáhněte si úplnou datovou sadu SDNET2018 a použijte ji k tréningu.
- Rozšíření dat: Běžnou technikou pro zpestření dat je zvětšení dat pořízením obrázku a použitím různých transformací (otočení, překlopení, posun, oříznutí). Tím přidáte pestřejší příklady, ze které se má model učit.
- Trénování po delší dobu: Čím déle trénujete, tím více bude model vyladěný. Zvýšení počtu epoch může zlepšit výkon modelu.
- Experimentujte s hyperparametry: Kromě parametrů použitých v tomto kurzu je možné vyladit i další parametry, aby se potenciálně zlepšil výkon. Změna rychlosti učení, která určuje velikost aktualizací modelu po každé epoše, může zvýšit výkon.
- Použijte jinou architekturu modelu: V závislosti na tom, jak vaše data vypadají, se model, který se může nejlépe naučit jeho funkce, se může lišit. Pokud nejste spokojení s výkonem modelu, zkuste změnit architekturu.
Další kroky
V tomto kurzu jste se dozvěděli, jak vytvořit vlastní model hlubokého učení pomocí transferového učení, předem vytrénovaného modelu klasifikace obrázků TensorFlow a rozhraní API pro klasifikaci ML.NET image classification pro klasifikaci obrázků z betonových povrchů jako prasklé nebo nezalomené.
Další informace najdete v dalším kurzu.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro