Tutorial: Index from multiple data sources using the .NET SDK
Azure AI Search can import, analyze, and index data from multiple data sources into a single consolidated search index.
This C# tutorial uses the Azure.Search.Documents client library in the Azure SDK for .NET to index sample hotel data from an Azure Cosmos DB instance, and merges that with hotel room details drawn from Azure Blob Storage documents. The result is a combined hotel search index containing hotel documents, with rooms as a complex data types.
In this tutorial, you'll perform the following tasks:
- Upload sample data and create data sources
- Identify the document key
- Define and create the index
- Index hotel data from Azure Cosmos DB
- Merge hotel room data from blob storage
If you don't have an Azure subscription, create a free account before you begin.
Overview
This tutorial uses Azure.Search.Documents to create and run multiple indexers. In this tutorial, you'll set up two Azure data sources so that you can configure an indexer that pulls from both to populate a single search index. The two data sets must have a value in common to support the merge. In this sample, that field is an ID. As long as there's a field in common to support the mapping, an indexer can merge data from disparate resources: structured data from Azure SQL, unstructured data from Blob storage, or any combination of supported data sources on Azure.
A finished version of the code in this tutorial can be found in the following project:
Prerequisites
- Azure Cosmos DB for NoSQL
- Azure Storage
- Visual Studio
- Azure AI Search (version 11.x) NuGet package
- Azure AI Search
Note
You can use a free search service for this tutorial. The free tier limits you to three indexes, three indexers, and three data sources. This tutorial creates one of each. Before starting, make sure you have room on your service to accept the new resources.
1 - Create services
This tutorial uses Azure AI Search for indexing and queries, Azure Cosmos DB for one data set, and Azure Blob Storage for the second data set.
If possible, create all services in the same region and resource group for proximity and manageability. In practice, your services can be in any region.
This sample uses two small sets of data that describe seven fictional hotels. One set describes the hotels themselves, and will be loaded into an Azure Cosmos DB database. The other set contains hotel room details, and is provided as seven separate JSON files to be uploaded into Azure Blob Storage.
Start with Azure Cosmos DB
Sign in to the Azure portal, and then navigate your Azure Cosmos DB account Overview page.
Select Data Explorer and then select New Database.
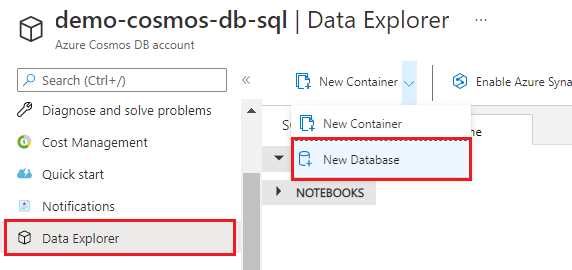
Enter the name hotel-rooms-db. Accept default values for the remaining settings.
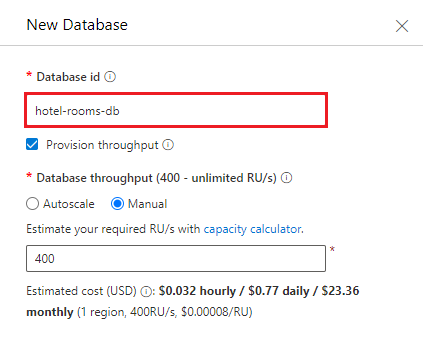
Create a new container. Use the existing database you just created. Enter hotels for the container name, and use /HotelId for the Partition key.
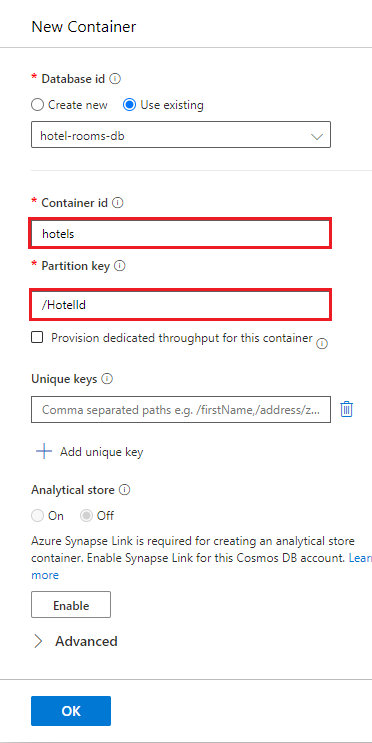
Select Items under hotels, and then select Upload Item on the command bar. Navigate to and then select the file cosmosdb/HotelsDataSubset_CosmosDb.json in the project folder.
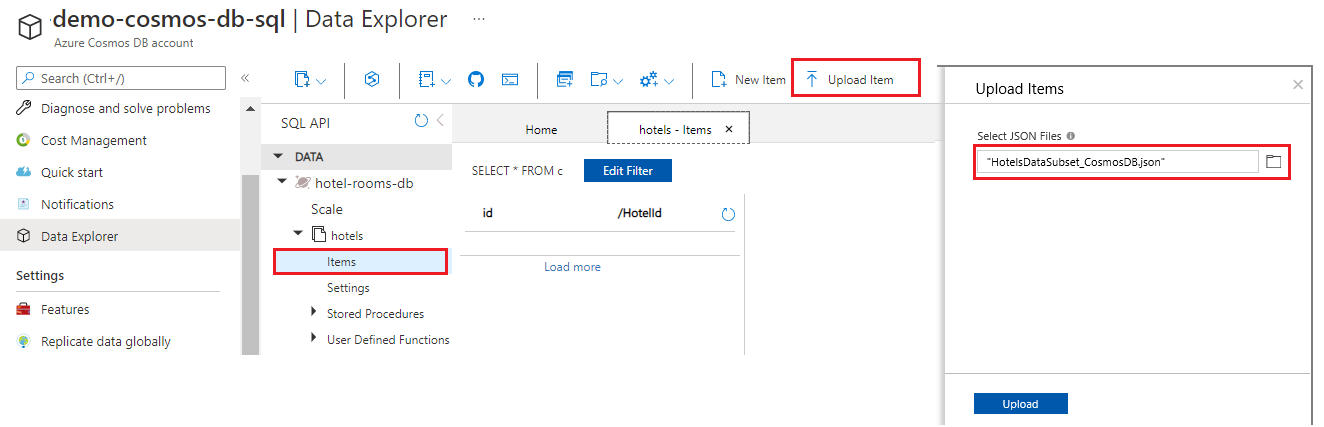
Use the Refresh button to refresh your view of the items in the hotels collection. You should see seven new database documents listed.
Copy a connection string from the Keys page into Notepad. You'll need this value for appsettings.json in a later step. If you didn't use the suggested database name "hotel-rooms-db", copy the database name as well.
Azure Blob Storage
Sign in to the Azure portal, navigate to your Azure storage account, select Blobs, and then select + Container.
Create a blob container named hotel-rooms to store the sample hotel room JSON files. You can set the Public Access Level to any of its valid values.
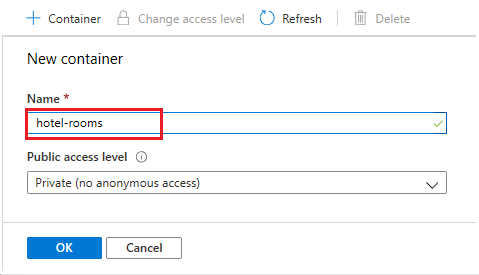
After the container is created, open it and select Upload on the command bar. Navigate to the folder containing the sample files. Select all of them and then select Upload.
Copy the storage account name and a connection string from the Access Keys page into Notepad. You'll need both values for appsettings.json in a later step.
Azure AI Search
The third component is Azure AI Search, which you can create in the portal or find an existing search service in your Azure resources.
Copy an admin api-key and URL for Azure AI Search
To authenticate to your search service, you'll need the service URL and an access key.
Sign in to the Azure portal, and in your search service Overview page, get the URL. An example endpoint might look like
https://mydemo.search.windows.net.In Settings > Keys, get an admin key for full rights on the service. There are two interchangeable admin keys, provided for business continuity in case you need to roll one over. You can use either the primary or secondary key on requests for adding, modifying, and deleting objects.
Having a valid key establishes trust, on a per request basis, between the application sending the request and the service that handles it.
2 - Set up your environment
Start Visual Studio and in the Tools menu, select NuGet Package Manager and then Manage NuGet Packages for Solution....
In the Browse tab, find and then install Azure.Search.Documents (version 11.0 or later).
Search for the Microsoft.Extensions.Configuration and Microsoft.Extensions.Configuration.Json NuGet packages and install them as well.
Open the solution file /v11/AzureSearchMultipleDataSources.sln.
In Solution Explorer, edit the appsettings.json file to add connection information.
{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
The first two entries are the URL and admin keys of a search service. Use the full endpoint, for example: https://mydemo.search.windows.net.
The next entries specify account names and connection string information for the Azure Blob Storage and Azure Cosmos DB data sources.
3 - Map key fields
Merging content requires that both data streams are targeting the same documents in the search index.
In Azure AI Search, the key field uniquely identifies each document. Every search index must have exactly one key field of type Edm.String. That key field must be present for each document in a data source that is added to the index. (In fact, it's the only required field.)
When indexing data from multiple data sources, make sure each incoming row or document contains a common document key to merge data from two physically distinct source documents into a new search document in the combined index.
It often requires some up-front planning to identify a meaningful document key for your index, and make sure it exists in both data sources. In this demo, the HotelId key for each hotel in Azure Cosmos DB is also present in the rooms JSON blobs in Blob storage.
Azure AI Search indexers can use field mappings to rename and even reformat data fields during the indexing process, so that source data can be directed to the correct index field. For example, in Azure Cosmos DB, the hotel identifier is called HotelId. But in the JSON blob files for the hotel rooms, the hotel identifier is named Id. The program handles this discrepancy by mapping the Id field from the blobs to the HotelId key field in the indexer.
Note
In most cases, auto-generated document keys, such as those created by default by some indexers, do not make good document keys for combined indexes. In general you will want to use a meaningful, unique key value that already exists in, or can be easily added to, your data sources.
4 - Explore the code
Once the data and configuration settings are in place, the sample program in /v11/AzureSearchMultipleDataSources.sln should be ready to build and run.
This simple C#/.NET console app performs the following tasks:
- Creates a new index based on the data structure of the C# Hotel class (which also references the Address and Room classes).
- Creates a new data source and an indexer that maps Azure Cosmos DB data to index fields. These are both objects in Azure AI Search.
- Runs the indexer to load Hotel data from Azure Cosmos DB.
- Creates a second data source and an indexer that maps JSON blob data to index fields.
- Runs the second indexer to load Rooms data from Blob storage.
Before running the program, take a minute to study the code and the index and indexer definitions for this sample. The relevant code is in two files:
- Hotel.cs contains the schema that defines the index
- Program.cs contains functions that create the Azure AI Search index, data sources, and indexers, and load the combined results into the index.
Create an index
This sample program uses CreateIndexAsync to define and create an Azure AI Search index. It takes advantage of the FieldBuilder class to generate an index structure from a C# data model class.
The data model is defined by the Hotel class, which also contains references to the Address and Room classes. The FieldBuilder drills down through multiple class definitions to generate a complex data structure for the index. Metadata tags are used to define the attributes of each field, such as whether it's searchable or sortable.
The program will delete any existing index of the same name before creating the new one, in case you want to run this example more than once.
The following snippets from the Hotel.cs file show single fields, followed by a reference to another data model class, Room[], which in turn is defined in Room.cs file (not shown).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
In the Program.cs file, a SearchIndex is defined with a name and a field collection generated by the FieldBuilder.Build method, and then created as follows:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Create Azure Cosmos DB data source and indexer
Next the main program includes logic to create the Azure Cosmos DB data source for the hotels data.
First it concatenates the Azure Cosmos DB database name to the connection string. Then it defines a SearchIndexerDataSourceConnection object.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
After the data source is created, the program sets up an Azure Cosmos DB indexer named hotel-rooms-cosmos-indexer.
The program will update any existing indexers with the same name, overwriting the existing indexer with the content of the above code. It also includes reset and run actions, in case you want to run this example more than once.
The following example defines a schedule for the indexer, so that it will run once per day. You can remove the schedule property from this call if you don't want the indexer to automatically run again in the future.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
This example includes a simple try-catch block to report any errors that might occur during execution.
After the Azure Cosmos DB indexer has run, the search index will contain a full set of sample hotel documents. However the rooms field for each hotel will be an empty array, since the Azure Cosmos DB data source omits room details. Next, the program will pull from Blob storage to load and merge the room data.
Create Blob storage data source and indexer
To get the room details, the program first sets up a Blob storage data source to reference a set of individual JSON blob files.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
After the data source is created, the program sets up a blob indexer named hotel-rooms-blob-indexer, as shown below.
The JSON blobs contain a key field named Id instead of HotelId. The code uses the FieldMapping class to tell the indexer to direct the Id field value to the HotelId document key in the index.
Blob storage indexers can use IndexingParameters to specify a parsing mode. You should set different parsing modes depending on whether blobs represent a single document, or multiple documents within the same blob. In this example, each blob represents a single JSON document, so the code uses the json parsing mode. For more information about indexer parsing parameters for JSON blobs, see Index JSON blobs.
This example defines a schedule for the indexer, so that it will run once per day. You can remove the schedule property from this call if you don't want the indexer to automatically run again in the future.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Because the index has already been populated with hotel data from the Azure Cosmos DB database, the blob indexer updates the existing documents in the index and adds the room details.
Note
If you have the same non-key fields in both of your data sources, and the data within those fields does not match, then the index will contain the values from whichever indexer ran most recently. In our example, both data sources contain a HotelName field. If for some reason the data in this field is different, for documents with the same key value, then the HotelName data from the data source that was indexed most recently will be the value stored in the index.
5 - Search
You can explore the populated search index after the program has run, using the Search explorer in the portal.
In Azure portal, open the search service Overview page, and find the hotel-rooms-sample index in the Indexes list.

Select on the hotel-rooms-sample index in the list. You'll see a Search Explorer interface for the index. Enter a query for a term like "Luxury". You should see at least one document in the results, and this document should show a list of room objects in its rooms array.
Reset and rerun
In the early experimental stages of development, the most practical approach for design iteration is to delete the objects from Azure AI Search and allow your code to rebuild them. Resource names are unique. Deleting an object lets you recreate it using the same name.
The sample code checks for existing objects and deletes or updates them so that you can rerun the program.
You can also use the portal to delete indexes, indexers, and data sources.
Clean up resources
When you're working in your own subscription, at the end of a project, it's a good idea to remove the resources that you no longer need. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
You can find and manage resources in the portal, using the All resources or Resource groups link in the left-navigation pane.
Next steps
Now that you're familiar with the concept of ingesting data from multiple sources, let's take a closer look at indexer configuration, starting with Azure Cosmos DB.
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om