Konfigurer arbejdsbelastninger i Power BI Premium-dataflow
Du kan oprette arbejdsbelastninger for dataflow i dit Power BI Premium-abonnement. Power BI bruger begrebet arbejdsbelastninger til at beskrive Premium-indhold. Arbejdsbelastninger omfatter datasæt, sideinddelte rapporter, dataflow og KUNSTIG INTELLIGENS. Med dataflowarbejdsbelastningen kan du bruge selvbetjent dataforberedelse af dataflow til at indtage, transformere, integrere og forbedre data. Power BI Premium-dataflow administreres på Administration-portalen.
I følgende afsnit beskrives det, hvordan du aktiverer dataflow i din organisation, hvordan du tilpasser deres indstillinger i din Premium-kapacitet og vejledning til almindelig brug.
Aktivering af dataflow i Power BI Premium
Det første krav til brug af dataflow i dit Power BI Premium-abonnement er at aktivere oprettelse og brug af dataflow for din organisation. På Administration-portalen skal du vælge Lejer Indstillinger og skifte skyderen under Indstillinger for dataflow til Aktiveret, som vist på følgende billede.

Når du har aktiveret arbejdsbelastningen for dataflow, konfigureres den med standardindstillinger. Det kan være en god idé at tilpasse disse indstillinger efter behov. Derefter beskriver vi, hvor disse indstillinger findes, beskriver hver enkelt og hjælper dig med at forstå, hvornår du måske vil ændre værdierne for at optimere ydeevnen for dit dataflow.
Finjustering af indstillinger for dataflow i Premium
Når dataflow er aktiveret, kan du bruge Administration-portalen til at ændre eller afgrænse, hvordan dataflow oprettes, og hvordan de bruger ressourcer i dit Power BI Premium-abonnement. Power BI Premium kræver ikke, at hukommelsesindstillingerne ændres. Hukommelse i Power BI Premium administreres automatisk af det underliggende system. I følgende trin kan du se, hvordan du justerer indstillingerne for dataflowet.
Vælg Lejerindstillinger på Administration-portalen for at få vist alle de kapaciteter, der er oprettet. Vælg en kapacitet for at administrere dens indstillinger.
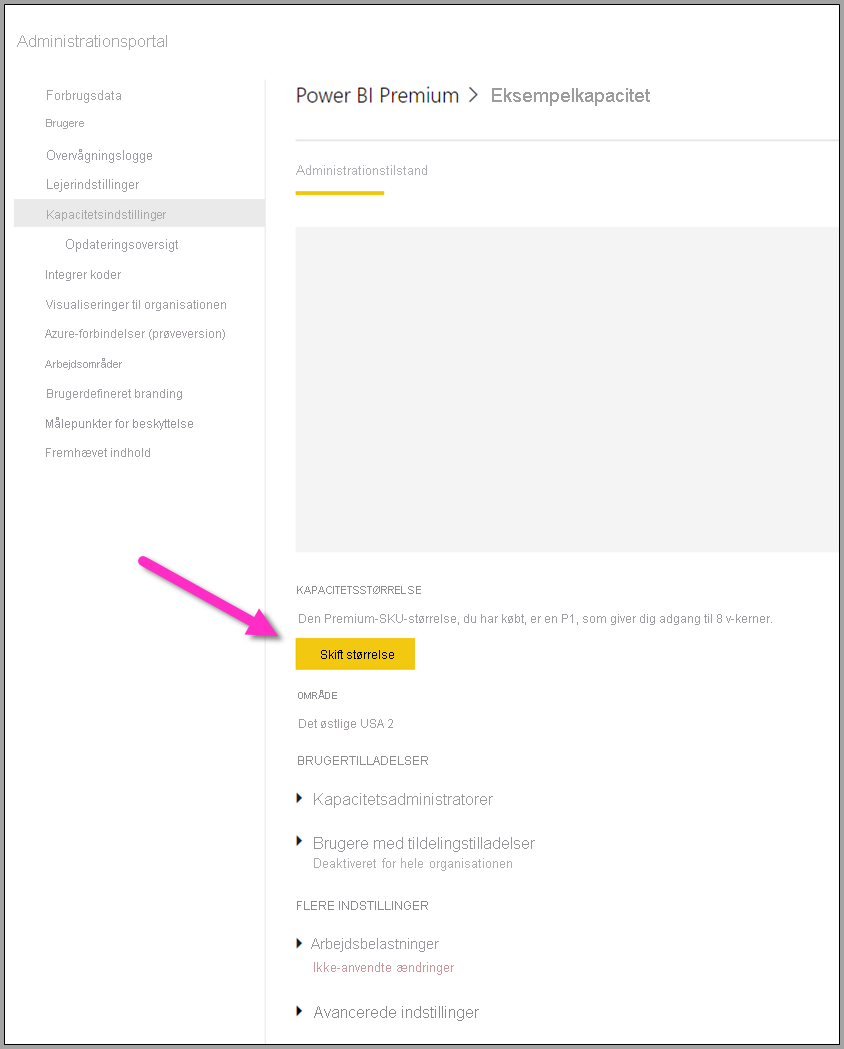
Din Power BI Premium-kapacitet afspejler de ressourcer, der er tilgængelige for dine dataflow. Du kan ændre kapacitetens størrelse ved at vælge knappen Skift størrelse , som vist på følgende billede.
Premium-kapacitets-SKU'er – opskaler hardwaren
Power BI Premium-arbejdsbelastninger bruger v-kerner til at håndtere hurtige forespørgsler på tværs af de forskellige arbejdsbelastningstyper. Kapaciteter og SKU'er indeholder et diagram, der illustrerer de aktuelle specifikationer på tværs af hvert af de tilgængelige tilbud på arbejdsbelastninger. Kapaciteter i A3 og nyere kan drage fordel af beregningsprogrammet, så når du vil bruge det forbedrede beregningsprogram, skal du starte der.
Forbedret beregningsprogram – en mulighed for at forbedre ydeevnen
Det forbedrede beregningsprogram er et program, der kan fremskynde dine forespørgsler. Power BI bruger et beregningsprogram til at behandle dine forespørgsler og opdateringshandlinger. Det forbedrede beregningsprogram er en forbedring i forhold til standardprogrammet og fungerer ved at indlæse data i en SQL Cache og bruger SQL til at fremskynde tabeltransformation, opdateringshandlinger og muliggøre DirectQuery-forbindelse. Hvis din forretningslogik tillader det, når den er konfigureret til Til eller Optimeret til beregnede enheder, bruger Power BI SQL til at fremskynde ydeevnen. Når programmet er slået til, får du også DirectQuery-forbindelse. Sørg for, at dit dataflowforbrug udnytter det forbedrede beregningsprogram korrekt. Brugerne kan konfigurere det forbedrede beregningsprogram, så det er slået til, optimeret eller slået fra pr. dataflow.
Bemærk
Det forbedrede beregningsprogram er endnu ikke tilgængeligt i alle områder.
Vejledning til almindelige scenarier
Dette afsnit indeholder en vejledning til almindelige scenarier, når du bruger arbejdsbelastninger i dataflow med Power BI Premium.
Langsomme opdateringstider
Langsomme opdateringstider er normalt et parallelitetsproblem. Du bør gennemse følgende indstillinger i rækkefølge:
Et vigtigt koncept for langsomme opdateringstider er arten af din dataforberedelse. Når du kan optimere dine langsomme opdateringstider ved at drage fordel af, at datakilden faktisk udfører forberedelse og udførelse af forespørgselslogik på forhånd, skal du gøre det. Når du specifikt bruger en relationsdatabase, f.eks. SQL som din kilde, skal du se, om den indledende forespørgsel kan køres på kilden, og bruge denne kildeforespørgsel til din indledende udtrækning af dataflow for datakilden. Hvis du ikke kan bruge en oprindelig forespørgsel i kildesystemet, skal du udføre handlinger, som dataflowprogrammet kan folde til datakilden.
Evaluer spredning af opdateringstider på den samme kapacitet. Opdateringshandlinger er en proces, der kræver betydelig beregning. Ved hjælp af vores restaurant analogi er spredning af opdateringstider beslægtet med at begrænse antallet af gæster i din restaurant. Ligesom restauranter planlægger gæster og planlægger kapacitet, vil du også overveje opdateringshandlinger i perioder, hvor forbruget ikke er helt på sit højeste. Dette kan gøre en stor del for at lette belastningen af kapaciteten.
Hvis trinnene i dette afsnit ikke giver den ønskede grad af parallelitet, kan du overveje at opgradere din kapacitet til en højere SKU. Følg derefter de forrige trin i denne rækkefølge igen.
Brug af beregningsprogrammet til at forbedre ydeevnen
Udfør følgende trin for at aktivere arbejdsbelastninger for at udløse beregningsprogrammet og altid forbedre ydeevnen:
For beregnede og sammenkædede objekter i det samme arbejdsområde:
I forbindelse med indtagelse skal du fokusere på at få dataene ind i lageret så hurtigt som muligt ved kun at bruge filtre, hvis de reducerer den overordnede størrelse af datasættet. Det er bedste praksis at holde din transformationslogik adskilt fra dette trin og give programmet mulighed for at fokusere på den indledende indsamling af ingredienser. Derefter skal du adskille din transformation og forretningslogik i et separat dataflow i det samme arbejdsområde ved hjælp af sammenkædede eller beregnede enheder. Gør det muligt for programmet at aktivere og fremskynde dine beregninger. Din logik skal forberedes separat, før den kan drage fordel af beregningsprogrammet.
Sørg for, at du udfører de handlinger, der foldes, f.eks. fletninger, joinforbindelser, konvertering og andre.
Oprettelse af dataflow inden for publicerede retningslinjer og begrænsninger.
Du kan også bruge DirectQuery.
Beregningsprogrammet er slået til, men ydeevnen er langsom
Udfør følgende trin, når du undersøger scenarier, hvor beregningsprogrammet er slået til, men hvor ydeevnen er langsommere:
Begræns beregnede og sammenkædede objekter, der findes på tværs af arbejdsområdet.
Når du udfører din indledende opdatering med beregningsprogrammet slået til, skrives data i søen og i cachen. Denne dobbelte skrivning betyder, at disse opdateringer vil være langsommere.
Hvis du har et dataflow, der linker til flere dataflow, skal du sørge for at planlægge opdateringer af kildedataflowene, så de ikke alle opdateres på samme tid.
Relateret indhold
Følgende artikler indeholder flere oplysninger om dataflow og Power BI:
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om