Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) hat viele Verwendungen: Standpunktanalyse, Textgegenstandserkennung, Sprachenerkennung, Schlüsselbegriffserkennung und Dokumentkategorisierung.
Insbesondere können Sie NLP für folgendes verwenden:
- Klassifizieren Sie Dokumente. Sie können z. B. Dokumente als vertraulich oder Spam kennzeichnen.
- Führen Sie nachfolgende Verarbeitung oder Suchen aus. Sie können die NLP-Ausgabe für diese Zwecke verwenden.
- Fassen Sie Text zusammen, indem Sie die Entitäten identifizieren, die im Dokument vorhanden sind.
- Markieren Sie Dokumente mit Schlüsselwörtern. Für die Schlüsselwörter kann NLP identifizierte Entitäten verwenden.
- Führen Sie die inhaltsbasierte Suche und Abruf aus. Das Tagging ermöglicht diese Funktionalität.
- Fassen Sie die wichtigen Themen eines Dokuments zusammen. NLP kann identifizierte Entitäten in Themen kombinieren.
- Kategorisieren Sie Dokumente für die Navigation. Für diesen Zweck verwendet NLP erkannte Themen.
- Zählen Sie verwandte Dokumente basierend auf einem ausgewählten Thema auf. Für diesen Zweck verwendet NLP erkannte Themen.
- Bewerten Sie Text für die Stimmung. Mithilfe dieser Funktionalität können Sie den positiven oder negativen Ton eines Dokuments bewerten.
Apache®, Apache Spark und das Flammenlogo sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den USA und/oder anderen Ländern. Die Verwendung dieser Markierungen impliziert kein Endorsement durch die Apache Software Foundation.
Mögliche Anwendungsfälle
Geschäftsszenarien, die von benutzerdefinierten NLP profitieren können, umfassen:
- Dokumentinformationen für handschriftliche oder maschinelle Dokumente in Finanzen, Gesundheit, Einzelhandel, Regierung und anderen Sektoren.
- Branchenagnostische NLP-Aufgaben für die Textverarbeitung, z. B. Name Entity Recognition (NER), Klassifizierung, Zusammenfassung und Beziehungsextraktion. Diese Aufgaben automatisieren den Prozess zum Abrufen, Identifizieren und Analysieren von Dokumentinformationen wie Text und unstrukturierten Daten. Beispiele für diese Aufgaben sind Risikoschichtmodelle, Ontologieklassifizierung und Einzelhandelszusammenfassungen.
- Informationsabruf und Wissensdiagrammerstellung für die semantische Suche. Diese Funktionalität ermöglicht es, medizinische Wissensdiagramme zu erstellen, die die Arzneimittelermittlung und klinische Studien unterstützen.
- Textübersetzung für Unterhaltungs-KI-Systeme in kundenbezogenen Anwendungen in Einzelhandels-, Finanz-, Reise- und anderen Branchen.
Apache Spark als angepasstes NLP-Framework
Apache Spark ist ein Framework für die Parallelverarbeitung, das In-Memory-Verarbeitung unterstützt, um die Leistung von Big Data-Analyseanwendungen zu steigern. Azure Synapse Analytics, Azure HDInsight und Azure Databricks bieten Zugriff auf Spark und nutzen ihre Verarbeitungsleistung.
Für angepasste NLP-Workloads dient Spark NLP als effizientes Framework für die Verarbeitung einer großen Textmenge. Diese Open-Source-NLP-Bibliothek bietet Python-, Java- und Scala-Bibliotheken, die die vollständige Funktionalität herkömmlicher NLP-Bibliotheken wie spaCy, NLTK, Stanford CoreNLP und Open NLP bieten. Spark NLP bietet auch Funktionen wie Rechtschreibprüfung, Stimmungsanalyse und Dokumentklassifizierung. Spark NLP verbessert die vorherigen Bemühungen, indem es die modernste Genauigkeit, Geschwindigkeit und Skalierbarkeit bietet.
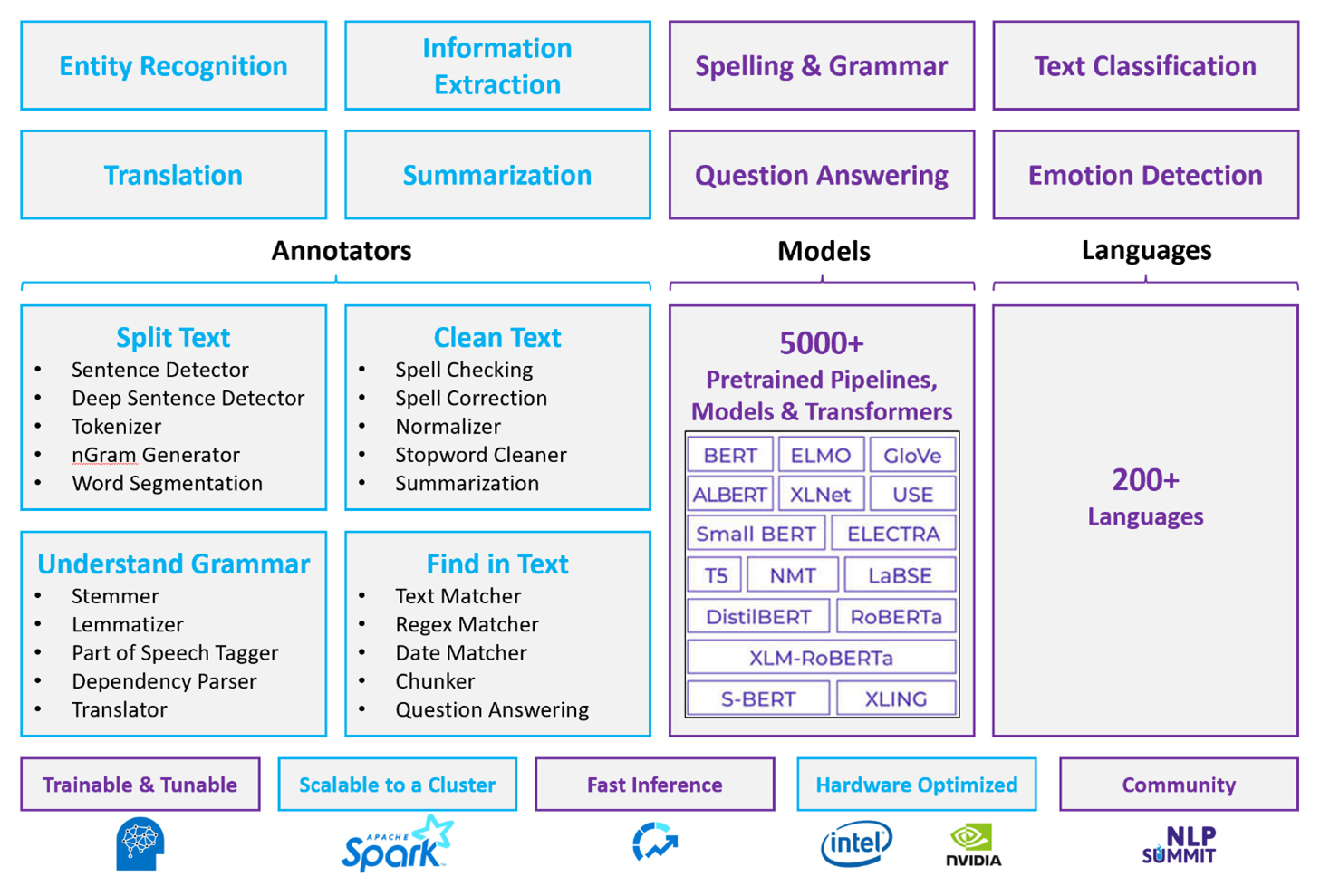
Aktuelle öffentliche Benchmarks zeigen Spark NLP als 38 und 80 Mal schneller als spaCy – mit vergleichbarer Genauigkeit für das Training benutzerdefinierter Modelle. Spark NLP ist die einzige Open-Source-Bibliothek, die einen verteilten Spark-Cluster verwenden kann. Spark NLP ist eine native Erweiterung von Spark ML, die direkt auf Datenframes funktioniert. Infolgedessen führt die Beschleunigungen bei einem Cluster zu einer anderen Reihenfolge der Leistungsgewinne. Da jede Spark NLP-Pipeline eine Spark ML Pipeline ist, eignet sich Spark NLP gut für die Erstellung einheitlicher NLP- und Machine Learning-Pipelines wie Dokumentklassifizierung, Risikovorhersage und Empfehlungspipelinen.
Neben hervorragender Leistung bietet Spark NLP auch modernste Genauigkeit für eine wachsende Anzahl von NLP-Aufgaben. Das Spark NLP-Team liest regelmäßig die neuesten relevanten akademischen Dokumente und implementiert modernste Modelle. In den letzten zwei bis drei Jahren haben die besten Modelle Deep Learning verwendet. Die Bibliothek verfügt über vordefinierte Deep Learning-Modelle für Zeichenentitätserkennung, Dokumentklassifizierung, Stimmungs- und Emotionserkennung und Satzerkennung. Die Bibliothek umfasst auch Dutzende von vorab trainierten Sprachmodellen, die Unterstützung für Wörter, Sätze und Dokumenteinbettungen enthalten.
Die Bibliothek verfügt über optimierte Builds für CPUs, GPUS und die neuesten Intel Xeon-Chips. Sie können Trainings- und Rückschlussprozesse skalieren, um Spark-Cluster zu nutzen. Diese Prozesse können in der Produktion auf allen beliebten Analyseplattformen ausgeführt werden.
Herausforderungen
- Die Verarbeitung einer Sammlung von Freiformulartextdokumenten erfordert eine erhebliche Menge an Berechnungsressourcen. Die Verarbeitung ist auch zeitintensiv. Solche Prozesse umfassen häufig GPU-Berechnungsbereitstellung.
- Ohne ein standardisiertes Dokumentformat kann es schwierig sein, durchweg genaue Ergebnisse zu erzielen, wenn Sie die Freitextverarbeitung zum Extrahieren bestimmter Fakten aus einem Dokument verwenden. Wenn Sie beispielsweise eine Textdarstellung einer Rechnung haben, kann es schwierig sein, einen Prozess zu erstellen, der Rechnungsnummer und -datum korrekt extrahiert, wenn Rechnungen von verschiedenen Lieferanten kommen.
Wichtige Auswahlkriterien
In Azure bieten Spark-Dienste wie Azure Databricks, Azure Synapse Analytics und Azure HDInsight NLP-Funktionen, wenn Sie sie mit Spark NLP verwenden. Azure Cognitive Services ist eine weitere Option für die NLP-Funktionalität. Um zu entscheiden, welche Dienste verwendet werden sollen, sollten Sie diese Fragen berücksichtigen:
Möchten Sie vorgefertigte oder vortrainierte Modelle verwenden? Wenn ja, sollten Sie die APIs verwenden, die Azure Cognitive Services bietet. Oder laden Sie Ihr Modell über Spark NLP herunter.
Müssen Sie benutzerdefinierte Modelle anhand eines großen Korpus mit Textdaten trainieren? Wenn ja, sollten Sie Azure Databricks, Azure Synapse Analytics oder Azure HDInsight mit Spark NLP verwenden.
Benötigen Sie spezielle NLP-Funktionen, z.B. Tokenisierung, Wortstammerkennung, Lemmatisierung und Vorkommenshäufigkeit/Inverse Dokumenthäufigkeit (Term Frequency/Inverse Document Frequency, TF/IDF)? Wenn ja, sollten Sie Azure Databricks, Azure Synapse Analytics oder Azure HDInsight mit Spark NLP verwenden. Oder verwenden Sie eine Open-Source-Softwarebibliothek in Ihrem gewählten Verarbeitungstool.
Benötigen Sie einfache, allgemeine NLP-Funktionen wie Entitäts- und Absichtsidentifizierung, Themenerkennung, Rechtschreibprüfung oder Standpunktanalyse? Wenn ja, sollten Sie die APIs verwenden, die Azure Cognitive Services bietet. Oder laden Sie Ihr Modell über Spark NLP herunter.
Funktionsmatrix
In den folgenden Tabellen sind die Hauptunterschiede in den Funktionen der NLP-Dienste zusammengefasst.
Allgemeine Funktionen
| Funktion | Spark-Dienst (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) mit Spark NLP | Azure Cognitive Services |
|---|---|---|
| Bereitstellung von vortrainierten Modellen als Dienst | Ja | Ja |
| REST-API | Ja | Ja |
| Programmierbarkeit | Python, Scala | Weitere Informationen zu unterstützten Sprachen finden Sie unter Weitere Ressourcen |
| Unterstützt die Verarbeitung von Big Datasets und großen Dokumenten | Ja | Nein |
NlP-Funktionen auf niedriger Ebene
| Funktion von Annotatoren | Spark-Dienst (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) mit Spark NLP | Azure Cognitive Services |
|---|---|---|
| Satzerkennung | Ja | Nein |
| Tiefe Satzerkennung | Ja | Ja |
| Tokenizer | Ja | Ja |
| N-Gramm-Generator | Ja | Nein |
| Wortsegmentierung | Ja | Ja |
| Wortstammerkennung | Ja | Nein |
| Lemmatisierung | Ja | Nein |
| Satzteilmarkierung | Ja | Nein |
| Abhängigkeitsparser | Ja | Nein |
| Sprachübersetzung | Ja | Nein |
| Stoppwortbereinigung | Ja | Nein |
| Rechtschreibkorrektur | Ja | Nein |
| Normalizer | Ja | Ja |
| Textabgleich | Ja | Nein |
| TF/IDF | Ja | Nein |
| Abgleich regulärer Ausdrücke | Ja | Eingebetteter Language Understanding Intelligent Service (LUIS). Wird nicht in Conversational Language Understanding (CLU), das LUIS ersetzt, unterstützt. |
| Datumsabgleich | Ja | Über DateTime-Erkennungen in LUIS und CLU möglich |
| Chunker | Ja | Nein |
NlP-Funktionen auf hoher Ebene
| Funktion | Spark-Dienst (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) mit Spark NLP | Azure Cognitive Services |
|---|---|---|
| Rechtschreibprüfung | Ja | Nein |
| Zusammenfassung | Ja | Ja |
| Fragen und Antworten | Ja | Ja |
| Stimmungserkennung | Ja | Ja |
| Emotionserkennung | Ja | Unterstützt Opinion Mining |
| Tokenklassifizierung | Ja | Ja, über benutzerdefinierte Modelle |
| Textklassifizierung | Ja | Ja, über benutzerdefinierte Modelle |
| Textdarstellung | Ja | Nein |
| NER | Ja | Ja – Textanalyse bietet einen Satz von NER und benutzerdefinierte Modelle sind in der Entitätserkennung |
| Entitätserkennung | Ja | Ja, über benutzerdefinierte Modelle |
| Spracherkennung | Ja | Ja |
| Unterstützt neben Englisch noch andere Sprachen | Ja, unterstützt mehr als 200 Sprachen | Ja, unterstützt mehr als 97 Sprachen |
Einrichten von Spark NLP in Azure
Um Spark NLP zu installieren, verwenden Sie den folgenden Code, ersetzen sie jedoch <version> durch die neueste Versionsnummer. Weitere Informationen finden Sie in der Spark NLP-Dokumentation.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Entwickeln von NLP-Pipelines
Für die Ausführungsreihenfolge einer NLP-Pipeline folgt Spark NLP demselben Entwicklungskonzept wie herkömmliche Spark ML Machine Learning-Modelle. Spark NLP wendet jedoch NLP-Techniken an.
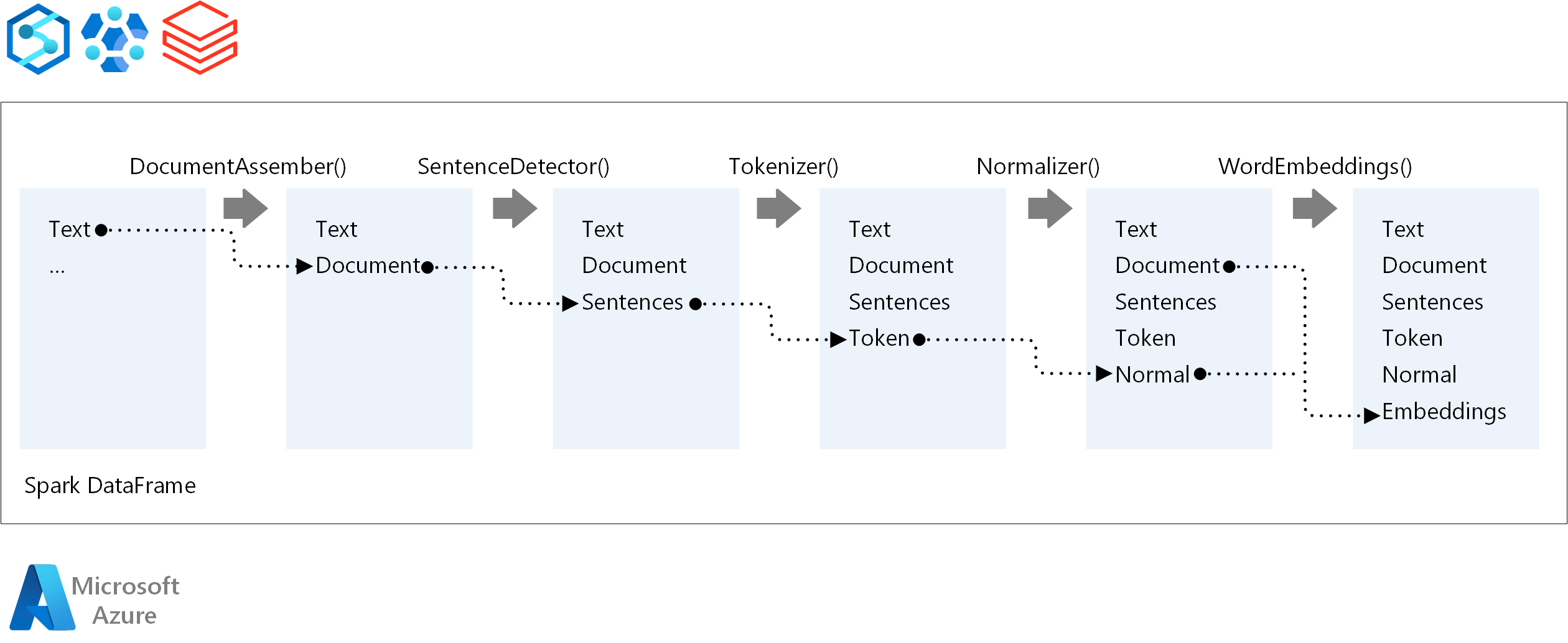
Die Kernkomponenten einer Spark NLP-Pipeline sind:
DocumentAssembler: Ein Transformator, der Daten vorbereitet, indem sie in ein Format geändert werden, das Spark NLP verarbeiten kann. Diese Phase ist der Einstiegspunkt für jede Spark NLP-Pipeline. DocumentAssembler kann entweder eine
String-Spalte oder einArray[String]lesen. Sie könnensetCleanupModeverwenden, um den Text vorab zu verarbeiten. Standardmäßig ist dieser Modus deaktiviert.SentenceDetector: Ein Annotator, der Satzgrenzen erkennt, indem er den angegebenen Ansatz verwendet. Dieser Annotator kann jeden extrahierten Satz in einem
Arrayzurückgeben. Er kann auch jeden Satz in einer anderen Zeile zurückgeben, wenn SieexplodeSentencesauf "true" festlegen.Tokenizer: Ein Annotator, der rohen Text in Token trennt, oder Einheiten wie Wörter, Zahlen und Symbole, und die Token in einer
TokenizedSentence-Struktur zurückgibt. Diese Klasse ist nicht angepasst. Wenn Sie einen Tokenizer anpassen, verwendet das interneRuleFactorydie Eingabekonfiguration zum Einrichten von Tokenisierungsregeln. Tokenizer verwendet offene Standards zum Identifizieren von Token. Wenn die Standardeinstellungen Ihre Anforderungen nicht erfüllen, können Sie Regeln hinzufügen, um Tokenizer anzupassen.Normalizer: Ein Annotator, der Token bereinigt. Normalizer erfordert Stämme. Normalizer verwendet reguläre Ausdrücke und ein Wörterbuch, um Text zu transformieren und schmutzige Zeichen zu entfernen.
WordEmbeddings: Nachschlageannotatoren, die Token zu Vektoren zuordnen. Sie können
setStoragePathverwenden, um ein benutzerdefiniertes Token-Nachschlagewörterbuch für Einbettungen angeben. Jede Zeile Ihres Wörterbuchs muss ein Token und seine Vektordarstellung enthalten – getrennt durch Leerzeichen. Wenn ein Token im Wörterbuch nicht gefunden wird, ist das Ergebnis ein Nullvektor derselben Dimension.
Spark NLP verwendet Spark MLlib-Pipelines, die MLflow nativ unterstützt. MLflow ist eine Open-Source-Plattform für den Machine-Learning-Lebenszyklus. Ihre Komponenten umfassen Folgendes:
- Mlflow-Nachverfolgung: Zeichnet Experimente auf und bietet eine Möglichkeit zum Abfragen von Ergebnissen.
- MLflow-Projekte: Ermöglicht die Ausführung von Data Science-Code auf jeder Plattform.
- MLflow-Modelle: Stellt Modelle für verschiedene Umgebungen bereit.
- Modellregistrierung: Verwaltet Modelle, die Sie in einem zentralen Repository speichern.
MLflow ist in Azure Databricks integriert. Sie können MLflow in jeder anderen Spark-basierten Umgebung installieren, um Ihre Experimente nachzuverfolgen und zu verwalten. Sie können auch die MLflow-Modellregistrierung verwenden, um Modelle für Produktionszwecke zur Verfügung zu stellen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Moritz Steller | Senior Cloud Solution Architect
- Zoiner Tejada | CEO und Architekt
Nächste Schritte
Spark NLP-Dokumentation:
Azure-Komponenten:
Lernressourcen:
Zugehörige Ressourcen
- Umfangreiche Verarbeitung von benutzerdefinierten natürlichen Sprachen in Azure
- Auswählen einer Microsoft Cognitive Services-Technologie
- Vergleich der Machine Learning-Produkte und Technologien von Microsoft
- MLflow und Azure Machine Learning
- KI-Anreicherung mit Bild- und natürlicher Sprachverarbeitung in Azure Cognitive Search
- Analysieren Sie Newsfeeds mit Quasi-Echtzeit-Analysen unter Verwendung von Bild- und natürlicher Sprachverarbeitung
- Vorschlagen von Inhaltstags mit Deep Learning und NLP