In vielen umfangreichen Lösungen werden Daten in Partitionen aufgeteilt, die getrennt verwaltet werden können und auf die separat zugegriffen werden kann. Partitionierung kann die Skalierbarkeit verbessern, Konflikte reduzieren und die Leistung optimieren. Sie kann auch einen Mechanismus für das Unterteilen von Daten nach Verwendungsmuster bereitstellen. Beispielsweise können Sie ältere Daten in kostengünstigeren Datenspeichern archivieren.
Die Partitionierungsstrategie muss jedoch sorgfältig ausgewählt werden, um die Vorteile zu maximieren und gleichzeitig nachteilige Auswirkungen zu minimieren.
Hinweis
In diesem Artikel steht der Begriff Partitionierung für den Prozess der physischen Unterteilung von Daten in separate Datenspeicher. Dies ist nicht dasselbe wie die SQL Server-Tabellenpartitionierung.
Gründe für Datenpartitionierung
Verbesserung der Skalierbarkeit. Beim zentralen Hochskalieren eines einzelnen Datenbanksystems wird schließlich ein physisches Hardwarelimit erreicht. Wenn Sie Daten auf mehrere Partitionen aufteilen, die jeweils auf einem separaten Server gehostet werden, können Sie das System fast unbegrenzt horizontal hochskalieren.
Verbessern der Leistung: Zugriffe auf Daten in jeder Partition finden über eine kleinere Datenmenge statt. Bei ordnungsgemäßer Durchführung kann Partitionierung Ihr System effizienter gestalten. Vorgänge, die mehr als eine Partition betreffen, können parallel ausgeführt werden.
Verbesserung der Sicherheit In einigen Fällen können Sie sensible und nicht sensible Daten in verschiedene Partitionen unterteilen und auf die vertraulichen Daten andere Sicherheitsmaßnahmen anwenden.
Bereitstellen von Flexibilität bei Vorgängen. Partitionieren bietet viele Möglichkeiten für die Feinabstimmung von Vorgängen, das Maximieren administrativer Effizienz und die Minimierung von Kosten. Sie können beispielsweise basierend auf der Wichtigkeit der Daten in jeder Partition unterschiedliche Strategien für die Verwaltung, Überwachung, Sicherung und Wiederherstellung sowie für andere administrative Aufgaben definieren.
Übereinstimmung der Daten mit dem Anwendungsmuster Mithilfe der Partitionierung kann jede Partition basierend auf den Kosten und integrierten Funktionen, die dieser Datenspeicher bietet, auf einer anderen Art von Datenspeicher bereitgestellt werden. Umfangreiche binäre Daten können beispielsweise in einem Blobspeicher gespeichert werden, strukturiertere Daten dagegen in einer Dokumentendatenbank. Weitere Informationen finden Sie unter Auswählen des richtigen Datenspeichers.
Verbesserung der Verfügbarkeit Das Aufteilen von Daten über mehrere Server hinweg vermeidet eine einzelne Fehlerquelle. Wenn eine Instanz ausfällt, sind nur die Daten in dieser Partition nicht verfügbar. Vorgänge auf anderen Partitionen können fortgesetzt werden. Für verwaltete PaaS-Datenspeicher ist dieser Aspekt weniger relevant, da diese Dienste mit integrierter Redundanz vorgesehen sind.
Entwerfen von Partitionen
Es gibt drei typische Strategien zum Partitionieren von Daten:
Horizontale Partitionierung (häufig als Sharding bezeichnet). Bei dieser Strategie stellt jede Partition einen separaten Datenspeicher dar, wobei jedoch alle Partitionen das gleiche Schema aufweisen. Jede Partition ist als ein Shard bekannt und enthält eine bestimmte Teilmenge der Daten, z.B. alle Bestellungen für einen bestimmten Satz von Kunden.
Vertikale Partitionierung. Bei dieser Strategie enthält jede Partition eine Teilmenge der Felder für Elemente im Datenspeicher. Die Felder werden gemäß ihrem Verwendungsmuster unterteilt. Beispielsweise können häufig verwendete Felder in einer vertikalen Partition und weniger häufig verwendete Felder in einer anderen Partition platziert werden.
Funktionale Partitionierung. Bei dieser Strategie werden Daten nach der Art und Weise aggregiert, in der sie im System von jedem begrenzten Kontext verwendet werden. Beispiel: Ein E-Commerce-System kann Rechnungsdaten in einer Partition und Daten zum Produktbestand in einer anderen speichern.
Diese Strategien können kombiniert werden, und es empfiehlt sich, sie alle beim Entwurf eines Partitionierungsschemas zu berücksichtigen. Beispielsweise könnten Sie Daten in Shards unterteilen und dann die Daten mittels vertikaler Partitionierung innerhalb der einzelnen Shards weiter unterteilen.
Horizontale Partitionierung (Sharding)
Abbildung 1 zeigt horizontale Partitionierung oder Sharding. In diesem Beispiel werden Warenbestandsdaten basierend auf dem Produktschlüssel in Shards unterteilt. Jedes Shard enthält die Daten für einen zusammenhängenden Bereich von Shard-Schlüsseln (A-G und H-Z) in alphabetischer Anordnung. Durch Sharding wird die Last auf mehrere Computer verteilt, was Konflikte reduziert und die Leistung verbessert.
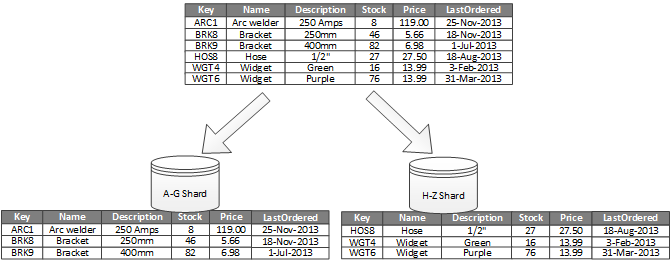
Abbildung 1: Horizontale Partitionierung (Sharding) von Daten auf Grundlage eines Partitionsschlüssels.
Der wichtigste Faktor ist die Wahl des Shardschlüssels. Es kann schwierig sein, den Schlüssel zu ändern, nachdem das System in Betrieb ist. Der Schlüssel muss sicherstellen, dass Daten auf eine Weise partitioniert werden, die die Workload möglichst gleichmäßig über die Shards hinweg verteilt.
Die Shards müssen nicht dieselbe Größe aufweisen. Es ist wichtiger, die Anzahl der Anforderungen auszugleichen. Einige Shards sind möglicherweise sehr groß, aber es gibt nur eine geringe Anzahl von Zugriffsvorgängen für jedes Element. Andere Shards können kleiner sein, aber es wird viel häufiger auf jedes Element zugegriffen. Außerdem ist es wichtig sicherzustellen, dass kein einzelner Shard die Skalierungsgrenzen (im Hinblick auf Kapazität und Verarbeitungsressourcen) des Datenspeichers überschreitet.
Vermeiden Sie das Erstellen von „heißen“ Partitionen, die möglicherweise die Leistung und Verfügbarkeit beeinträchtigen. Beispielsweise führt die Verwendung des Anfangsbuchstabens des Kundennamens zu einer ungleichmäßigen Verteilung, da einige Buchstaben häufiger vorkommen. Verwenden Sie stattdessen einen Hash aus einer Kunden-ID, um Daten gleichmäßiger auf die Partitionen zu verteilen.
Wählen Sie einen Shardschlüssel, der die Notwendigkeit minimiert, zu einem späteren Zeitpunkt große Shards aufteilen, kleinere Shards in größeren Partitionen zusammenfügen oder das Schema ändern zu müssen. Diese Vorgänge können sehr zeitaufwendig sein und erfordern es möglicherweise, während der Ausführung einen oder mehrere Shards offline zu schalten.
Wenn Shards repliziert werden, ist es eventuell möglich, einige der Replikate online zu halten, während andere Replikate geteilt, zusammengeführt oder neu konfiguriert werden. Das System muss jedoch möglicherweise die Vorgänge begrenzen, die für die Daten während die Neukonfiguration ausgeführt werden können. Beispielsweise können die Daten in den Replikaten als schreibgeschützt markiert werden, um Inkonsistenzen der Daten zu verhindern.
Weitere Informationen zur horizontalen Partitionierung finden Sie unter Sharding-Muster.
Vertikale Partitionierung
Die häufigste Verwendung für die vertikale Partitionierung ist, die E/A und die Leistungskosten zu reduzieren, die mit dem Abrufen von Elementen verknüpft sind, auf die häufig zugegriffen wird. Abbildung 2 zeigt ein Beispiel für die vertikale Partitionierung. In diesem Beispiel sind verschiedene Eigenschaften eines Elements in verschiedenen Partitionen gespeichert. Eine Partition enthält Daten, auf die häufiger zugegriffen wird, einschließlich Name, Beschreibung und Preisinformationen für Produkte. Eine andere Partition enthält Bestandsdaten: die Bestandsmenge und das Datum der letzten Bestellung.
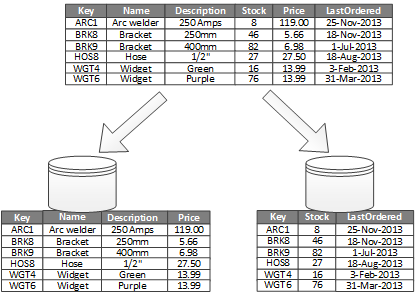
Abbildung 2: Vertikale Partitionierung von Daten nach Verwendungsmuster.
In diesem Beispiel fragt die Anwendung regelmäßig den Produktnamen, die Beschreibung und den Preis ab, wenn Kunden Produktdetails angezeigt werden. Bestandsmenge und Datum der letzten Bestellung werden in einer getrennten Partition gespeichert, da diese beiden Elemente häufig zusammen verwendet werden.
Weitere Vorteile der vertikalen Partitionierung:
Daten, die sich relativ langsam bewegen (Produktname, Beschreibung und Preis), können von den dynamischeren Daten (Lagerbestand und Datum der letzten Bestellung) getrennt werden. Daten, die sich langsam bewegen, eignen sich gut für die Zwischenspeicherung im Arbeitsspeicher durch eine Anwendung.
Vertrauliche Daten können in einer separaten Partition mit zusätzlichen Sicherheitsmaßnahmen gespeichert werden.
Eine vertikale Partitionierung kann die erforderlichen gleichzeitigen Zugriffe verringern.
Vertikale Partitionierung findet auf der Entitätsebene in einem Datenspeicher statt, wobei eine Entität teilweise normalisiert wird, um sie von einem breiten Element in einen Satz schmaler Elemente aufzuschlüsseln. Es eignet sich ideal für spaltenorientierte Datenspeicher wie z. B. HBase und Cassandra. Wenn es unwahrscheinlich ist, dass sich Daten in einer Auflistung von Spalten ändern, können Sie auch in Betracht ziehen, Spaltenspeicher im SQL Server zu nutzen.
Funktionale Partitionierung
Wenn ein gebundener Kontext für jeden bestimmten Geschäftsbereich identifiziert werden kann, ist die funktionale Partitionierung eine Möglichkeit zur Verbesserung der Isolation und Datenzugriffsleistung. Darüber hinaus wird die funktionale Partitionierung häufig verwendet, um Lese/Schreibdaten von schreibgeschützten Daten zu trennen. Abbildung 3 zeigt eine Übersicht einer funktionalen Partitionierung, in der Bestandsdaten von Kundendaten getrennt werden.
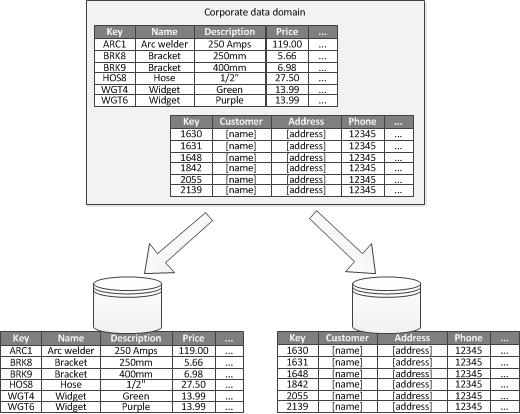
Abbildung 3: Funktionale Datenpartitionierung nach begrenztem Kontext oder Unterdomäne.
Diese Partitionierungsstrategie kann helfen, Datenzugriffskonflikte über verschiedene Teile eines Systems hinweg zu reduzieren.
Entwerfen von Partitionen für Skalierbarkeit
Es ist wichtig, die Größe und Workload für jede Partition zu berücksichtigen und auszubalancieren, um die Daten so zu verteilen, dass eine maximale Skalierbarkeit erreicht wird. Allerdings müssen Sie die Daten auch so partitionieren, dass nicht die Skalierungsgrenzen des Speicherplatzes der einzelnen Partitionen überschritten werden.
Gehen Sie beim Entwerfen von Partitionen für maximale Skalierbarkeit folgendermaßen vor:
- Analysieren Sie die Anwendung, um die Datenzugriffsmuster zu verstehen, wie z. B. die Größe des Resultsets jeder Abfrage, die Häufigkeit des Zugriffs, die inhärente Latenz und die serverseitige Anforderungen an die Rechenleistung. In vielen Fällen werden einige Hauptentitäten den Großteil der Verarbeitungsressourcen anfordern.
- Verwenden Sie diese Analyse, um die aktuellen und zukünftigen Skalierbarkeitsziele wie z. B. die Größe der Daten und die Workload festzulegen. Anschließend verteilen Sie die Daten auf die Partitionen, um das Skalierbarkeitsziel zu erreichen. Für horizontale Partitionierung ist die Auswahl des richtigen Shardschlüssels wichtig, um sicherzustellen, dass die Verteilung gleichmäßig erfolgt ist. Weitere Informationen finden Sie unter Sharding-Muster.
- Stellen Sie sicher, dass jede Partition über genügend Ressourcen verfügt, um den Anforderungen an die Skalierbarkeit im Hinblick auf die Größe der Daten und den Durchsatz zu entsprechen. Je nach Datenspeicher gibt es möglicherweise ein Grenzwert für die Menge an Speicherplatz, Verarbeitungsleistung oder Netzwerkbandbreite pro Partition. Wenn die Anforderungen diese Grenzwerte wahrscheinlich überschreiten werden, müssen Sie Ihre Partitionierungsstrategie u. U. verfeinern oder Daten noch weiter aufteilen, möglicherweise durch Kombinieren von zwei oder mehr Strategien.
- Überwachen Sie das System, um sicherzustellen, dass Daten wie erwartet verteilt werden und die Partitionen die Last verarbeiten können. Die tatsächliche Nutzung stimmt nicht immer damit überein, was eine Analyse vorhersagt. In einem solchen Fall ist es möglich, die Partitionen neu auszurichten, oder einige Teile des Systems anderweitig umzugestalten, um die erforderliche Balance zu erzielen.
Einige Cloudumgebungen ordnen Ressourcen gemäß Infrastrukturgrenzen zu. Stellen Sie sicher, dass die Limits der von Ihnen ausgewählten Infrastrukturgrenze hinsichtlich Datenspeicherung, Verarbeitungsleistung und Bandbreite ausreichend Platz für das erwartete Wachstum der Datenmenge bieten.
Beispiel: Wenn Sie Azure-Tabellenspeicher verwenden, ist die Menge von Anforderungen, die von einer einzelnen Partition in einem bestimmten Zeitraum verarbeitet werden können, begrenzt. (Weitere Informationen finden Sie unter Skalierbarkeits- und Leistungsziele für Azure Storage.) Ein ausgelasteter Shard erfordert möglicherweise mehr Ressourcen als eine einzelne Partition verarbeiten kann. In diesem Fall muss der Shard womöglich neu partitioniert werden, um die Last zu verteilen. Wenn die Gesamtgröße oder der Gesamtdurchsatz dieser Tabellen die Kapazität eines Speicherkontos überschreitet, müssen Sie u.U. zusätzliche Speicherkonten erstellen und die Tabellen auf diese Konten verteilen.
Entwerfen von Partitionen für die Abfrageleistung
Die Abfrageleistung kann oft mit kleineren Datensätzen und der parallelen Ausführung von Abfragen erhöht werden. Jede Partition sollte einen kleinen Anteil des gesamten Datasets enthalten. Diese Reduzierung des Volumens kann die Leistung von Abfragen verbessern. Allerdings ist das Partitionieren keine Alternative zum angemessenen Entwerfen und Konfigurieren einer Datenbank. Stellen Sie z.B. sicher, dass Sie über die erforderlichen Indizes verfügen.
Gehen Sie beim Entwerfen von Partitionen für maximale Abfrageleistung folgendermaßen vor:
Überprüfen Sie die Anwendungsanforderungen und Leistung:
- Bestimmen Sie die kritischen Anfragen, die stets schnell ausgeführt werden müssen, anhand von Unternehmensanforderungen.
- Überwachen Sie das System, um Abfragen zu identifizieren, die nur langsam durchgeführt werden.
- Ermitteln Sie, welche Abfragen am häufigsten ausgeführt werden. Selbst wenn eine einzelne Abfrage nur minimale Kosten verursacht, kann der kumulative Ressourcenverbrauch erheblich sein.
Partitionieren Sie die Daten, die für eine geringe Leistung verantwortlich sind:
- Beschränken Sie die Größe der einzelnen Partitionen, sodass die Abfrageantwortzeit innerhalb des Ziels liegt.
- Wenn Sie horizontale Partitionierung verwenden, entwerfen Sie den Shardschlüssel so, dass die Anwendung problemlos die richtige Partition auswählen kann. Dies verhindert, dass die Abfrage jede Partition durchsuchen muss.
- Berücksichtigen Sie den Speicherort einer Partition. Versuchen Sie nach Möglichkeit die Daten in Partitionen zu belassen, die geografisch dicht bei den Anwendungen und Benutzern liegen, die darauf zugreifen.
Besitzt eine Entität Durchsatz und Anforderungen an die Abfrageleistung, verwenden Sie funktionale Partitionierung basierend auf dieser Entität. Wenn die Anforderungen dadurch immer noch nicht erfüllt sind, wenden Sie auch eine horizontale Partitionierung an. In den meisten Fällen reicht eine einzelne Partitionierungsstrategie, aber in einigen Fällen ist es effizienter, beide Strategien zu kombinieren.
Erwägen Sie das parallele Ausführen von Abfragen über Partitionen hinweg, um die Leistung zu verbessern.
Entwerfen von Partitionen für Verfügbarkeit
Partitionieren von Daten kann die Verfügbarkeit von Anwendungen verbessern, indem Sie sicherstellen, dass das gesamte Dataset keine einzelne Fehlerquelle darstellt und einzelne Teilmengen des Datasets unabhängig voneinander verwaltet werden können.
Berücksichtigen Sie die folgenden Faktoren, die sich auf die Verfügbarkeit auswirken:
Wie kritisch sind die Daten für den Geschäftsbetrieb? Ermitteln Sie, welche Daten kritische geschäftliche Informationen wie z.B. Transaktionen sind, und welche Daten weniger kritische operative Daten sind, z.B. Protokolldateien.
Erwägen Sie das Speichern von kritischen Daten in hochverfügbaren Partitionen mit einem geeigneten Sicherungsplan.
Richten Sie separate Verwaltungs- und Überwachungsverfahren für die verschiedenen Datasets ein.
Speichern Sie Daten der gleichen Wichtigkeitsstufe in der gleichen Partition, sodass sie mit angemessener Häufigkeit zusammen gesichert werden können. Partitionen, die Transaktionsdaten enthalten, müssen z.B. häufiger gesichert werden als Partitionen mit Protokollierungs- oder Nachverfolgungsinformationen.
Wie werden die einzelnen Partitionen verwaltet? Das Entwerfen von Partitionen, um unabhängige Verwaltung und Wartung zu unterstützen, bietet mehrere Vorteile. Beispiel:
Wenn eine Partition ausfällt, kann sie ohne Anwendungen, die auf Daten in anderen Partitionen zugreifen, unabhängig wiederhergestellt werden.
Das Partitionieren von Daten nach geografischem Bereich ermöglicht die Ausführung von geplanten Wartungsaufgaben außerhalb der Spitzenzeiten für jeden Standort. Stellen Sie sicher, dass die Partitionen nicht zu groß sind, um zu verhindern, dass eine geplante Wartung während dieses Zeitraums abgeschlossen wird.
Sollen kritische Daten partitionsübergreifend repliziert werden? Diese Strategie kann zwar die Verfügbarkeit und Leistung verbessern, jedoch auch zu Konsistenzproblemen führen. Das Synchronisieren von Änderungen mit allen Replikaten kostet Zeit. Während dieses Zeitraums enthalten verschiedene Partitionen unterschiedliche Datenwerte.
Überlegungen zum Anwendungsentwurf
Durch Partitionierung werden der Entwurf und die Entwicklung des Systems komplexer. Betrachten Sie die Partitionierung als grundlegenden Bestandteil des Systementwurfs, selbst wenn das System zunächst nur eine Partition umfasst. Wenn Sie sich erst im Nachhinein mit der Partitionierung befassen, wird es schwieriger, da Sie bereits ein Livesystem zu verwalten haben:
- Datenzugriffslogik muss geändert werden.
- Möglicherweise müssen große Mengen an vorhandenen Daten migriert werden, um sie auf Partitionen zu verteilen.
- Benutzer erwarten, dass das System während der Migration weiter verwendet werden kann.
In einigen Fällen wird die Partitionierung nicht als wichtig angesehen, da das ursprüngliche Dataset klein ist und problemlos von einem einzelnen Server verarbeitet werden kann. Für einige Workloads mag dies möglich sein, aber viele kommerzielle Systeme müssen mit steigender Benutzeranzahl erweitert werden.
Außerdem ist Partitionierung nicht nur für große Datenspeicher von Vorteil. Beispielsweise kann auf einen kleinen Datenspeicher von mehreren hundert gleichzeitigen Clients intensiv zugegriffen werden. Das Partitionieren der Daten kann in dieser Situation helfen, Konflikte zu minimieren und den Durchsatz verbessern.
Beachten Sie beim Entwerfen eines Schemas für die Datenpartitionierung folgende Punkte:
Minimieren Sie partitionsübergreifende Datenzugriffsvorgänge. Halten Sie die Daten für die am häufigsten verwendeten Datenbankvorgänge nach Möglichkeit in jeder Partition zusammen, um partitionsübergreifende Datenzugriffsvorgänge zu minimieren. Das Abfragen über Partitionen hinweg kann mehr Zeit in Anspruch nehmen als das Abfragen innerhalb einer einzelnen Partition. Das Optimieren der Partitionen für eine Reihe von Abfragen könnte jedoch andere Sätze von Abfragen beeinträchtigen. Wenn Sie partitionsübergreifende Abfragen ausführen müssen, minimieren Sie die Abfragezeit, indem Sie parallele Abfragen ausführen und die Ergebnisse innerhalb der Anwendung aggregieren. (Diese Herangehensweise lässt sich möglicherweise nicht in allen Fällen umsetzen, z.B. wenn das Ergebnis aus einer bestimmten Abfrage in der nächsten Abfrage verwendet wird.)
Ziehen Sie in Betracht, statische Referenzdaten zu replizieren. Wenn in Abfragen relativ statische Referenzdaten genutzt werden, z.B. Tabellen mit Postleitzahlen oder Produktlisten, sollten Sie erwägen, diese Daten in allen Partitionen zu replizieren, um separate Suchvorgänge in verschiedenen Partitionen zu reduzieren. Dadurch lässt sich auch die Wahrscheinlichkeit verringern, dass Referenzdaten zu einem „heißen“ Dataset mit umfangreichem Datenverkehr aus dem gesamten System werden. Das Synchronisieren von Änderungen, die an diesen Referenzdaten vorgenommen werden, ist aber mit zusätzlichem Aufwand verbunden.
Minimieren Sie partitionsübergreifende Verknüpfungen. Minimieren Sie nach Möglichkeit die Anforderungen für referenzielle Integrität über vertikale und funktionale Partitionen hinweg. In diesen Schemen ist die Anwendung für die Wahrung der referenziellen Integrität über Partitionen hinweg verantwortlich. Abfragen, die Daten über mehrere Partitionen hinweg verknüpfen, sind ineffizient, da die Anwendung in der Regel aufeinanderfolgende Abfragen basierend auf einem Schlüssel und dann auf einem Fremdschlüssel durchführen muss. Ziehen Sie stattdessen in Betracht, die relevanten Daten zu replizieren oder zu denormalisieren. Wenn partitionsübergreifende Verknüpfungen notwendig sind, führen Sie parallele Abfragen über die Partitionen hinweg aus, und verknüpfen Sie die Daten innerhalb der Anwendung.
Implementieren Sie die letztliche Konsistenz. Überprüfen Sie, ob eine hohe Konsistenz tatsächlich erforderlich ist. Eine gängige Vorgehensweise in verteilten Systemen ist das Implementieren von letztendlicher Konsistenz. Die Daten in jeder Partition werden separat aktualisiert, und die Anwendungslogik stellt sicher, dass alle Updates erfolgreich abgeschlossen werden. Die Logik verarbeitet auch alle Inkonsistenzen, die durch Abfragen von Daten während eines letztlich konsistenten Vorgangs entstehen.
Überlegen Sie, wie Abfragen die richtige Partition finden. Wenn eine Abfrage alle Partitionen durchsuchen muss, um die erforderlichen Daten zu finden, wirkt sich das erheblich auf die Leistung aus, auch wenn mehrere parallele Abfragen ausgeführt werden. Mit vertikalen und funktionalen Partitionierungsstrategien können Abfragen natürlich die Partition angeben. Bei horizontaler Partitionierung kann das Auffinden eines Elements dagegen schwierig sein, da jeder Shard über das gleiche Schema verfügt. Eine typische Lösung ist die Verwaltung einer Zuordnung, die verwendet wird, um den Shard-Speicherort für bestimmte Elemente zu suchen. Diese Zuordnung kann in der Shardinglogik der Anwendung implementiert sein oder vom Datenspeicher verwaltet werden, wenn transparentes Sharding unterstützt wird.
Erwägen Sie eine Neuverteilung von Shards in regelmäßigen Abständen. Bei horizontaler Partitionierung kann eine Neuverteilung von Shards dazu beitragen, die Daten nach Größe und Workload gleichmäßig zu verteilen, um Hotspots zu minimieren, die Abfrageleistung zu maximieren und physische Speichereinschränkungen zu umgehen. Dies ist jedoch eine komplexe Aufgabe, die häufig ein benutzerdefiniertes Tool oder einen benutzerdefinierten Prozess erfordert.
Replizieren Sie Partitionen. Die Replikation jeder Partition bietet zusätzlichen Schutz vor Ausfällen. Wenn ein einzelnes Replikat fehlschlägt, können Abfragen gegen eine Arbeitskopie geleitet werden.
Wenn die physischen Grenzen einer Partitionierungsstrategie erreicht sind, müssen Sie die Skalierbarkeit auf eine andere Ebene erweitern. Wurde die Partitionierung beispielsweise auf Datenbankebene implementiert, müssen Sie möglicherweise Partitionen in mehreren Datenbanken suchen oder replizieren. Wenn die Partitionierung bereits auf Datenbankebene implementiert wurde und physische Einschränkungen ein Problem sind, kann dies bedeuten, dass Sie Partitionen in mehreren Hostingkonten suchen oder replizieren müssen.
Vermeiden Sie Transaktionen, die auf Daten in mehreren Partitionen zugreifen. Einige Datenspeicher implementieren Transaktionskonsistenz und -integrität für Vorgänge, die Daten ändern, aber nur, wenn sich diese in einer einzelnen Partition befinden. Wenn Sie Transaktionsunterstützung über mehrere Partitionen benötigen, müssen Sie diese wahrscheinlich als Teil Ihrer Anwendungslogik implementieren, da die meisten Partitionierungssysteme keine systemeigene Unterstützung bereitstellen.
Alle Datenspeicher erfordern ein gewisses Maß an Betriebsverwaltung und Überwachung. Die Aufgaben können vom Laden der Daten, Backup und Wiederherstellen der Daten bis Neuorganisieren der Daten reichen und stellen sicher, dass das System ordnungsgemäß und effizient arbeitet.
Berücksichtigen Sie die folgenden Faktoren, die sich auf die Betriebsverwaltung auswirken:
Wie werden die notwendigen verwaltungsbezogenen und operativen Aufgaben implementiert, wenn die Daten partitioniert sind? Hierzu können Aufgaben zur Sicherung und Wiederherstellung, Datenarchivierung, Systemüberwachung sowie weitere administrative Aufgaben gehören. Beispielsweise kann das Verwalten von logischer Konsistenz bei Backup- und Wiederherstellungsvorgängen schwierig sein.
Wie werden Daten in die verschiedenen Partitionen geladen und neue Daten aus anderen Quellen hinzugefügt? Einige Tools und Hilfsprogramme unterstützen Datenvorgänge in Shards wie das Laden von Daten in die richtige Partition möglicherweise nicht.
Wie werden die Daten in regelmäßigen Abständen archiviert und gelöscht? Um ein übermäßiges Wachstum der Partitionen zu verhindern, müssen Daten in regelmäßigen Abständen (z. B. monatlich) archiviert und gelöscht werden. Es kann notwendig sein, die Daten zu transformieren, um einem anderen Archivschema zu entsprechen.
Wie werden Datenintegritätsprobleme ermittelt? Es empfiehlt sich, einen regelmäßigen Prozess zum Ermitteln möglicher Datenintegritätsprobleme auszuführen, wie z.B. Daten in einer Partition, die auf nicht vorhandene Informationen in einer anderen Partition verweisen. Der Prozess kann entweder versuchen, diese Probleme automatisch zu beheben, oder einen Bericht für die manuelle Überprüfung generieren.
Neuverteilen von Partitionen
Im Zuge der Weiterentwicklung eines Systems müssen Sie möglicherweise das Partitionierungsschema anpassen. Beispielsweise ist es möglich, dass in einzelnen Partitionen ein unverhältnismäßig großes Datenverkehrsvolumen auftritt, sodass diese Partitionen zu „heißen“ Partitionen werden, was zu übermäßigen Konflikten führt. Oder Sie haben möglicherweise die Datenmenge in einigen Partitionen unterschätzt, sodass einige Partitionen bald an die Kapazitätsgrenzen stoßen.
Einige Datenspeicher, wie z. B. Azure Cosmos DB, können Partitionen automatisch austarieren. In anderen Fällen ist das Neuverteilen eine administrative Aufgabe, die aus zwei Schritten besteht:
Bestimmen Sie eine neue Partitionierungsstrategie.
- Welche Partitionen müssen aufgeteilt (oder möglicherweise kombiniert) werden?
- Was ist der neue Partitionsschlüssel?
Migrieren Sie Daten vom alten Partitionierungsschema in den neuen Satz von Partitionen.
Je nach Datenspeicher können Sie Daten möglicherweise zwischen Partitionen migrieren, während sie verwendet werden. Dies wird als Onlinemigration bezeichnet. Wenn dies nicht möglich ist, müssen Sie die Verfügbarkeit von Partitionen vorübergehend aufheben, während die Daten verschoben werden (Offlinemigration).
Offlinemigration
Die Offlinemigration ist in der Regel einfacher, da sie die Wahrscheinlichkeit von Konflikten reduziert. Vom Konzept her funktioniert die Offlinemigration wie folgt:
- Markieren Sie die Partition als offline.
- Teilen Sie die Daten auf bzw. führen Sie sie zusammen, und verschieben Sie sie in die neuen Partitionen.
- Überprüfen Sie die Daten.
- Schalten Sie die neuen Partitionen online.
- Entfernen Sie die alte Partition.
Sie haben in Schritt 1 die Option, eine Partition als schreibgeschützt zu markieren, damit Anwendungen die Daten weiterhin lesen können, während diese verschoben werden.
Onlinemigration
Die Ausführung der Onlinemigration ist komplexer, aber sie ist weniger störend. Der Prozess ähnelt der Offlinemigration, außer dass die ursprüngliche Partition nicht als offline markiert wird. Je nach Granularität des Migrationsvorgangs (z.B. abhängig davon, ob der Vorgang Element für Element oder Shard für Shard ausgeführt wird) muss der Datenzugriffscode in den Clientanwendungen Daten an zwei Orten lesen und schreiben (in der ursprünglichen und der neuen Partition).
Nächste Schritte
- Erfahren Sie mehr über Partitionierungsstrategien für bestimmte Azure-Dienste. Siehe Strategien für die Datenpartitionierung.
- Skalierbarkeits- und Leistungsziele für Azure Storage
Zugehörige Ressourcen
Die folgenden Entwurfsmuster können für Ihr Szenario relevant sein:
Das Sharding-Muster beschreibt einige allgemeine Strategien für das Sharding von Daten.
Das Indextabellenmuster zeigt das Erstellen von sekundären Indizes für Daten. Mit diesem Ansatz kann eine Anwendung Daten durch Abfragen, die nicht auf den Primärschlüssel einer Sammlung verweisen, schnell abrufen.
Das Muster für materialisierte Sichten erläutert, wie Sie vorab aufgefüllte Ansichten generieren können, die Daten zusammenfassen, um schnelle Abfragevorgänge zu unterstützen. Dieser Ansatz kann in einem partitionierten Datenspeicher hilfreich sein, wenn die Partitionen, die die Daten enthalten, die zusammengefasst werden, über mehrere Standorte verteilt sind.