Ein gängiges Problem, mit dem Organisationen konfrontiert sind, ist das Sammeln von Daten aus mehreren Quellen in verschiedenen Formaten. Anschließend müssen Sie diese in einen oder mehrere Datenspeicher übertragen. Der Zielspeicher ist möglicherweise nicht derselbe Typ von Datenspeicher wie die Quelle. Häufig ist das Format anders, oder die Daten müssen vor dem Laden in den endgültigen Zielspeicher strukturiert oder bereinigt werden.
Zur Bewältigung dieser Herausforderungen wurden im Laufe der Jahre verschiedene Tools, Dienste und Prozesse entwickelt. Unabhängig vom ausgeführten Prozess muss die Arbeit im Allgemeinen koordiniert und ein gewisses Maß an Datentransformation innerhalb der Datenpipeline angewendet werden. In den folgenden Abschnitten werden gängige Methoden für die Durchführung dieser Aufgaben erläutert.
Extrahieren, Transformieren und Laden (ETL-Prozess)
Extrahieren, Transformieren und Laden (ETL) ist eine Datenpipeline, die zum Sammeln von Daten aus verschiedenen Quellen verwendet wird. Sie transformiert die Daten daraufhin gemäß den Geschäftsregeln und lädt sie in einen Zieldatenspeicher. Die Transformation in ETL findet in einem spezialisierten Modul statt und beinhaltet häufig die Verwendung von Stagingtabellen zur vorübergehenden Speicherung von Daten, während diese transformiert und schließlich in das Ziel geladen werden.
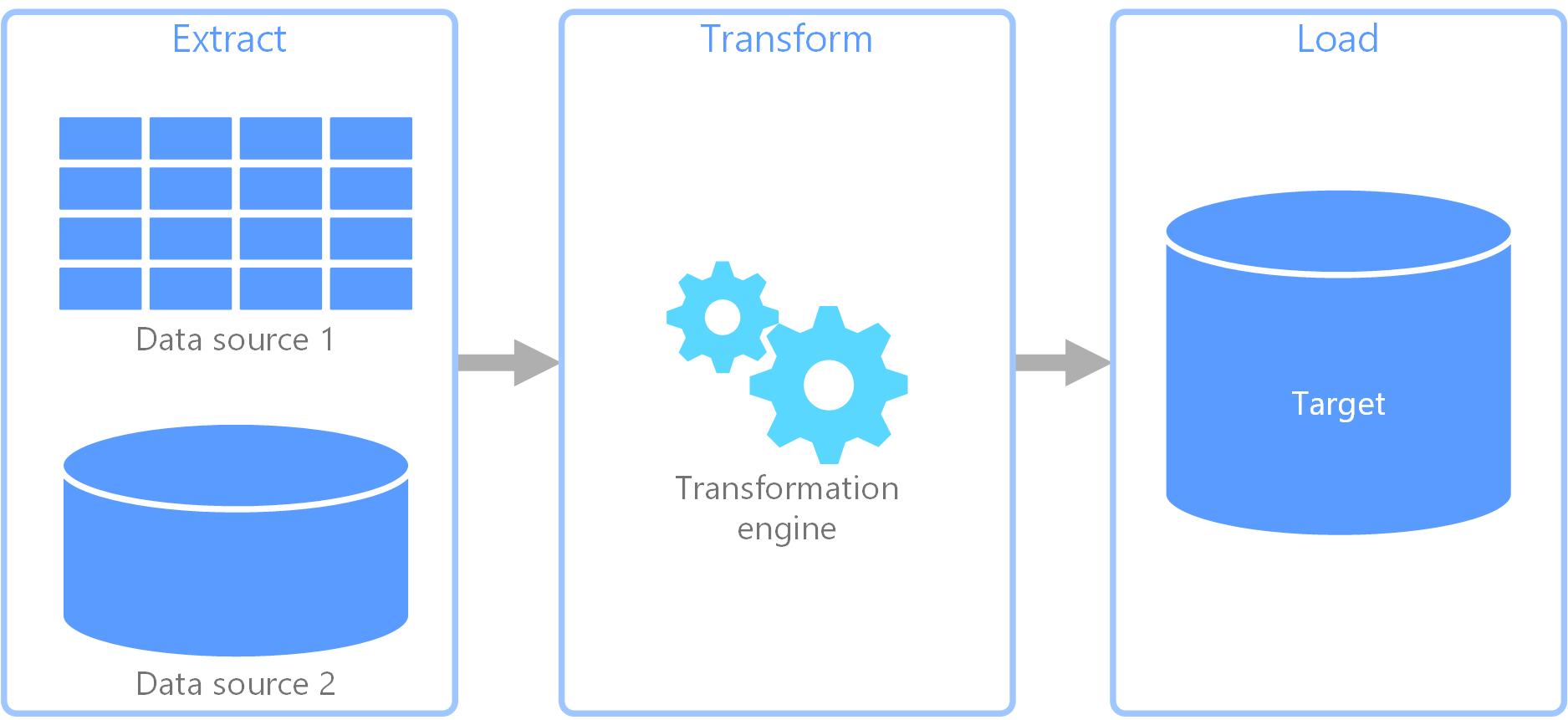
Die durchgeführte Datentransformation umfasst in der Regel verschiedene Vorgänge wie Filtern, Sortieren, Aggregieren, Verknüpfen, Bereinigen, Deduplizieren und Validieren von Daten.
Die drei ETL-Phasen werden häufig parallel ausgeführt, um Zeit zu sparen. Während der Datenextraktion kann also beispielsweise ein Transformationsprozess für bereits empfangene Daten ausgeführt werden, um die Daten für das Laden vorzubereiten, und ein Ladevorgang kann mit der Arbeit an den vorbereiteten Daten beginnen, anstatt auf den Abschluss des gesamten Extraktionsprozesses zu warten.
In Frage kommender Azure-Dienst:
Weitere Tools:
Extrahieren, Laden und Transformieren (ELT)
Extrahieren, Laden und Transformieren (ELT) unterscheidet sich von ETL lediglich darin, an welcher Stelle die Transformation erfolgt. In der ELT-Pipeline findet die Transformation im Zieldatenspeicher statt. Die Daten werden mithilfe der Verarbeitungsfunktionen des Zieldatenspeichers transformiert, anstatt ein separates Transformationsmodul zu verwenden. Dadurch wird das Transformationsmodul aus der Pipeline entfernt, was die Architektur vereinfacht. Ein weiterer Vorteil dieses Ansatzes ist, dass durch Skalieren des Zieldatenspeichers auch die Leistung der ELT-Pipeline skaliert wird. ELT setzt jedoch voraus, dass das Zielsystem über genügend Leistung verfügt, um die Daten effizient transformieren zu können.
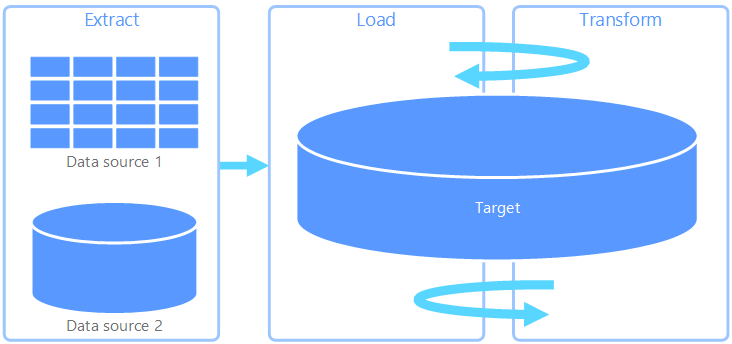
ELT kommt üblicherweise in Big Data-Szenarien zum Einsatz. Sie können beispielsweise damit beginnen, alle Quelldaten in Flatfiles in einen skalierbaren Speicher zu extrahieren, z. B. ein Hadoop Distributed File System, einen Azure-Blobspeicher oder Azure Data Lake Gen 2 (oder eine Kombination aus diesen). Sie können die Quelldaten anschließend mit Technologien wie Spark, Hive oder Polybase abfragen. Entscheidend bei ELT ist, dass der für die Transformation verwendete Datenspeicher der gleiche Datenspeicher ist, in dem die Daten später auch genutzt werden. Dieser Datenspeicher liest direkt aus dem skalierbaren Speicher, anstatt die Daten in seinen eigenen proprietären Speicher zu laden. Bei diesem Ansatz wird also der Datenkopierschritt des ETL-Prozesses übersprungen, der bei umfangreichen Datasets häufig zeitaufwendig sein kann.
In der Praxis ist der Zieldatenspeicher ein Data Warehouse, das entweder ein Hadoop-Cluster (mit Hive oder Spark) oder einen dedizierten SQL-Pool mit Azure Synapse Analytics verwendet. Im Allgemeinen wird bei der Abfrage ein Schema auf die Flatfiledaten angewendet und als Tabelle gespeichert, wodurch die Daten wie jede andere Tabelle im Datenspeicher abgefragt werden können. Diese werden als externe Tabellen bezeichnet, da die Daten sich nicht in einem Speicher befinden, der vom Datenspeicher selbst verwaltet wird, sondern in einem externen skalierbaren Speicher wie Azure Data Lake Store oder Azure Blob Storage.
Der Datenspeicher verwaltet nur das Schema der Daten und wendet es beim Lesen an. Ein Hadoop-Cluster mit Hive beschreibt beispielsweise eine Hive-Tabelle, in der die Datenquelle im Grunde ein Pfad zu einer Gruppe von Dateien in HDFS ist. In Azure Synapse lässt sich mit PolyBase das gleiche Ergebnis erzielen: Es wird eine Tabelle für Daten erstellt, die außerhalb der eigentlichen Datenbank gespeichert sind. Nach dem Laden der Quelldaten können die in externen Tabellen enthaltenen Daten mithilfe der Funktionen des Datenspeichers verarbeitet werden. In Big Data-Szenarios muss der Datenspeicher für MPP (Massively Parallel Processing) geeignet sein. Dabei werden die Daten in kleinere Blöcke aufgeteilt und die Verarbeitung dieser Blöcke parallel auf mehrere Knoten verteilt.
In der letzten Phase der ELT-Pipeline werden die Quelldaten üblicherweise in ein endgültiges Format transformiert, das besser für die Arten von Abfragen geeignet ist, die unterstützt werden müssen. So können die Daten beispielsweise partitioniert werden. ELT kann außerdem optimierte Speicherformate wie Parquet verwendet, das zeilenorientierte Daten spaltenförmig speichert und eine optimierte Indizierung bietet.
In Frage kommender Azure-Dienst:
- Dedizierte SQL-Pools auf Azure Synapse Analytics
- Serverlose SQL-Pools auf Azure Synapse Analytics
- HDInsight mit Hive
- Azure Data Factory
- Datamarts in Power BI
Weitere Tools:
Datenfluss und Ablaufsteuerung
Im Kontext von Datenpipelines gewährleistet die Ablaufsteuerung die geordnete Verarbeitung mehrerer Aufgaben. Zur Erzwingung der korrekten Verarbeitungsreihenfolge dieser Tasks werden Rangfolgeneinschränkungen verwendet. Diese Einschränkungen können Sie sich als Connectors in einem Workflowdiagramm vorstellen, wie in der folgenden Abbildung zu sehen. Jeder Task hat ein Ergebnis wie „Erfolgreich“, „Fehler“ oder „Abschluss“. Die Verarbeitung nachfolgender Tasks wird erst initiiert, wenn der vorherige Task mit einem dieser Ergebnisse abgeschlossen wurde.
Ablaufsteuerungen führen Datenflüsse als Task aus. In einem Datenflusstask werden Daten aus einer Quelle extrahiert, transformiert oder in einen Datenspeicher geladen. Die Ausgabe eines einzelnen Datenflusstasks kann als Eingabe für den nächsten Datenflusstask verwendet werden, und Datenflüsse können parallel ausgeführt werden. Im Gegensatz zu Ablaufsteuerungen können zwischen Tasks in einem Datenfluss keine Einschränkungen hinzugefügt werden. Sie können jedoch einen Daten-Viewer hinzufügen, um die Daten zu beobachten, die durch die einzelnen Tasks verarbeitet werden.
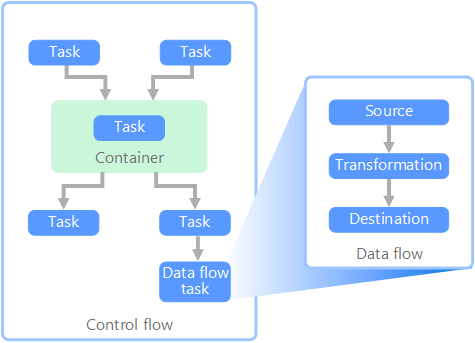
Das obige Diagramm enthält mehrere Tasks innerhalb der Ablaufsteuerung. Einer davon ist ein Datenflusstask. Einer der Tasks ist in einen Container geschachtelt. Container ermöglichen die Strukturierung von Tasks, um eine Arbeitseinheit bereitzustellen. Ein Beispiel wäre etwa die Wiederholung von Elementen in einer Sammlung (beispielsweise Dateien in einem Ordner oder Datenbankanweisungen).
In Frage kommender Azure-Dienst:
Weitere Tools:
Auswahl der Technologie
- OLTP-Datenspeicher (Online Transaction Processing)
- OLAP-Datenspeicher (Online Analytical Processing)
- Data Warehouses
- Pipelineorchestrierung
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Raunak Jhawar | Senior Cloud Architect
- Zoiner Tejada | CEO und Architekt
Nächste Schritte
- Integrieren von Daten mit Azure Data Factory oder Azure Synapse-Pipeline
- Einführung in Azure Synapse Analytics
- Orchestrieren der Datenverschiebung und -transformation in Azure Data Factory oder Azure Synapse Pipeline
Zugehörige Ressourcen
Die folgenden Referenzarchitekturen zeigen End-to-End-ELT-Pipelines in Azure: