Einer der wichtigsten Vorteile von Microservicearchitekturen sind kürzere Versionszyklen. Die Agilität, die von Microservices erwartet wird, lässt sich aber nur mit einem zuverlässigen CI/CD-Prozess erreichen. In diesem Artikel werden die Herausforderungen und einige Lösungsansätze für das Problem beschrieben.
Was ist CI/CD?
CI/CD umfasst eigentlich mehrere verwandte Prozesse: Continuous Integration, Continuous Delivery und Continuous Deployment.
Continuous Integration. Codeänderungen werden häufig in den Hauptbranch zusammengeführt. Mithilfe von automatisierten Build- und Testprozessen wird sichergestellt, dass der Code im Hauptbranch immer Produktionsqualität aufweist.
Continuous Delivery. Alle Codeänderungen, die den CI-Prozess durchlaufen, werden automatisch in einer produktionsähnlichen Umgebung veröffentlicht. Für die Bereitstellung in der aktiven Produktionsumgebung ist unter Umständen eine manuelle Freigabe erforderlich, ansonsten ist der Prozess jedoch automatisiert. Dadurch soll erreicht werden, dass Ihr Code stets für die Bereitstellung in der Produktionsumgebung bereit ist.
Kontinuierliche Bereitstellung: Codeänderungen, die die zwei vorhergehenden Schritte durchlaufen haben, werden automatisch in der Produktionsumgebung bereitgestellt.
Hier sind einige Ziele eines stabilen CI/CD-Prozesses für eine Microservicearchitektur aufgeführt:
Jedes Team kann die eigenen Dienste unabhängig erstellen und bereitstellen, ohne dass andere Teams hierdurch beeinträchtigt oder gestört werden.
Bevor eine neue Version eines Diensts für die Produktion bereitgestellt wird, wird sie zunächst zur Überprüfung in Umgebungen für die Entwicklung, Tests und Qualitätssicherung bereitgestellt. Jede Phase verfügt über so genannte „Quality Gates“.
Eine neue Version eines Diensts kann parallel zur vorherigen Version bereitgestellt werden.
Es sind ausreichende Richtlinien für die Zugriffssteuerung vorhanden.
Bei Workloads in Containern können Sie den Containerimages vertrauen, die für die Produktion bereitgestellt werden.
Wichtigkeit einer robusten CI/CD-Pipeline
In einer herkömmlichen monolithischen Anwendung gibt es eine einzelne Buildpipeline, die die ausführbare Datei der Anwendung ausgibt. Sämtliche Entwicklungsarbeiten werden dieser Pipeline zugeführt. Bei einem Fehler mit hoher Priorität muss eine Korrektur integriert, getestet und veröffentlicht werden, was die Veröffentlichung neuer Features verzögern kann. Diese Probleme lassen sich durch eine sorgfältige Modulgestaltung sowie durch die Verwendung von Featurebranches behandeln, die die Auswirkungen von Codeänderungen minimieren. Mit zunehmender Komplexität und wachsendem Funktionsumfang einer monolithischen Anwendung nimmt jedoch häufig auch die Fehleranfälligkeit des Releaseprozesses zu.
Die Microservices-Philosophie sieht kein langwieriges Releaseverfahren vor, in das sich die einzelnen Teams einreihen müssen. Das Team, das den Dienst „A“ erstellt, kann jederzeit ein Update veröffentlichen und muss nicht warten, bis Änderungen für den Dienst „B“ zusammengeführt, getestet und bereitgestellt wurden.
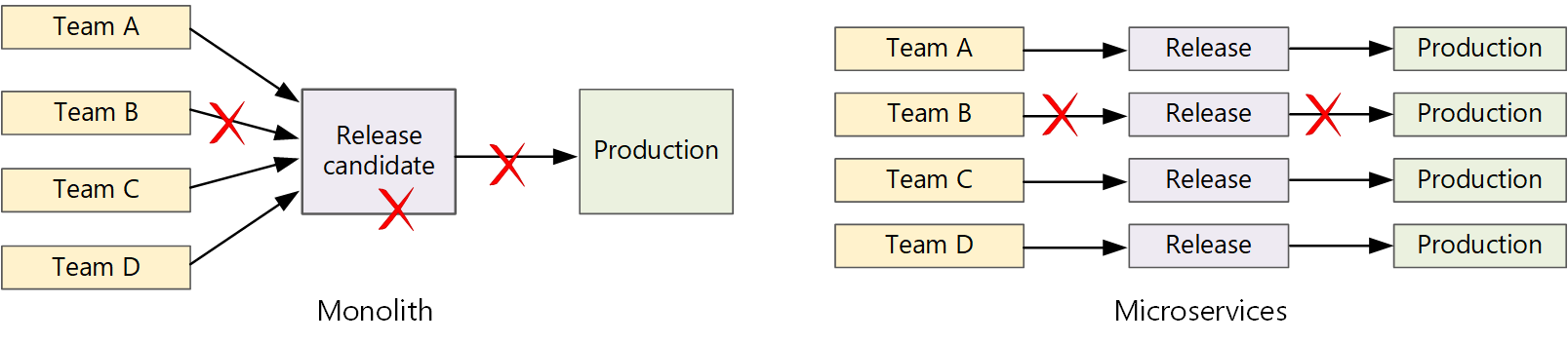
Um eine hohe Releasegeschwindigkeit zu erreichen, muss Ihre Releasepipeline automatisiert und sehr zuverlässig sein, um Risiken zu minimieren. Bei täglich oder mehrmals täglich durchgeführten Veröffentlichungen in der Produktionsumgebung darf es nur selten zu Regressionen oder Dienstausfällen kommen. Sollte doch einmal ein fehlerhaftes Update bereitgestellt werden, müssen Sie schnell und zuverlässig einen Rollback oder Rollforward auf eine frühere Dienstversion ausführen können.
Herausforderungen
Zahlreiche kompakte und unabhängige Codebasen: Jedes Team ist für die Erstellung seines eigenen Diensts verantwortlich und verfügt über eine eigene Buildpipeline. In einigen Organisationen verwenden die Teams unter Umständen separate Coderepositorys. Getrennte Repositorys können dazu führen, dass das Know-how für die Erstellung des Systems auf mehrere Teams verteilt ist und niemand in der Organisation weiß, wie die gesamte Anwendung bereitgestellt wird. Was passiert beispielsweise in einem Notfallwiederherstellungsszenario, wenn Sie schnell eine Bereitstellung in einem neuen Cluster durchführen müssen?
Lösung: Verwenden Sie für Build und Bereitstellung von Diensten eine einheitliche und automatisierte Pipeline, so dass dieses Wissen nicht in den einzelnen Teams „verborgen“ ist.
Mehrere Sprachen und Frameworks: Wenn jedes Team seinen eigenen Technologie-Mix verwendet, kann es schwierig sein, einen einzelnen Buildprozess zu erstellen, der für die gesamte Organisation geeignet ist. Der Buildprozess muss so flexibel sein, dass jedes Team ihn für die gewählte Sprache oder das gewählte Framework anpassen kann.
Lösung: Kapseln Sie den Buildprozess für jeden Dienst in einem Container. Auf diese Weise muss das Buildsystem nur dazu fähig sein, die Container auszuführen.
Integration und Auslastungstests: Wenn Teams Updates nach ihrem eigenen Zeitplan veröffentlichen, kann die Entwicklung zuverlässiger End-to-End-Tests zur Herausforderung werden – insbesondere, wenn Dienste von anderen Diensten abhängen. Darüber hinaus kann der Betrieb eines vollwertigen Produktionsclusters teuer sein, weshalb es unwahrscheinlich ist, dass jedes Team allein zu Testzwecken einen eigenen vollwertigen Cluster auf Produktionsniveau betreibt.
Releaseverwaltung: Jedes Team sollte in der Lage sein, ein Update in der Produktionsumgebung bereitzustellen. Das bedeutet nicht, dass jedes einzelne Teammitglied über entsprechende Berechtigungen verfügt. Durch eine zentrale Release-Manager-Rolle werden Bereitstellungen jedoch unter Umständen ausgebremst.
Lösung: Je zuverlässiger und stärker automatisiert Ihr CI/CD-Prozess ist, desto weniger Bedarf besteht für eine zentrale Instanz. Für die Veröffentlichung wichtiger Featureupdates und kleinerer Fehlerbehebung können jeweils unterschiedliche Richtlinien gelten. Dezentralisierung bedeutet keinen Verzicht auf Governance.
Dienstupdates: Wenn Sie einen Dienst auf eine neue Version aktualisieren, dürfen dadurch keine anderen Dienste beeinträchtigt werden, die von diesem Dienst abhängen.
Lösung: Verwenden Sie für geringfügige Änderungen Bereitstellungstechniken wie Blaugrün- oder Canary-Releases. Stellen Sie für Breaking Changes an APIs die neue Version parallel zur vorherigen Version bereit. Auf diese Weise können Dienste, die die vorherige API nutzen, aktualisiert und für die neue API getestet werden. Mehr dazu finden Sie unten unter Aktualisieren von Diensten.
Monorepo im Vergleich mit mehreren Repositorys
Vor dem Erstellen eines CI/CD-Workflows müssen Sie sich darüber im Klaren sein, wie die Codebasis strukturiert sein und verwaltet werden soll.
- Arbeiten die Teams in separaten Repositorys oder in einem „Monorepo“ (einzelnen Repository)?
- Wie sieht Ihre Strategie für das „Branchen“ aus?
- Wer kann Code per Pushvorgang in die Produktion übertragen? Ist eine Release Manager-Rolle vorhanden?
Die Beliebtheit des Monorepo-Ansatzes ist gestiegen, aber beide Ansätze haben sowohl Vor- als auch Nachteile.
| Monorepo | Mehrere Repositorys | |
|---|---|---|
| Vorteile | Codefreigabe Einfacheres Standardisieren von Code und Tools Einfacheres Umgestalten von Code Auffindbarkeit: Zentrale Codeansicht |
Eindeutige Eigentümerschaft pro Team Potenziell weniger Zusammenführungskonflikte Unterstützung bei der Durchsetzung der Entkopplung von Microservices |
| Herausforderungen | Änderungen an freigegebenem Code können sich auf mehrere Microservices auswirken Höheres Potenzial für Zusammenführungskonflikte Tools müssen auf große Codebasis skaliert werden Zugriffssteuerung Komplexerer Bereitstellungsprozess |
Schwierigere Codefreigabe Schwierigeres Durchsetzen von Codierungsstandards Verwaltung von Abhängigkeiten Diffuse Codebasis, schlechte Auffindbarkeit Mangel an freigegebener Infrastruktur |
Aktualisieren von Diensten
Für die Aktualisierung eines Diensts, der sich bereits in Produktion befindet, gibt es verschiedene Strategien. Hier werden drei gängige Optionen erläutert: paralleles Update, Blaugrün-Bereitstellung und Canary-Release.
Parallele Updates
Bei einem parallelen Update stellen Sie neue Instanzen eines Diensts bereit, und diese neuen Instanzen nehmen sofort Anforderungen entgegen. Wenn die neuen Instanzen online geschaltet werden, werden die vorherigen Instanzen entfernt.
Beispiel: In Kubernetes stellen parallele Updates das Standardverhalten dar, wenn Sie die Pod-Spezifikation für eine Bereitstellung aktualisieren. Der Bereitstellungscontroller erstellt eine neue Replikatgruppe (ReplicaSet) für die aktualisierten Pods. Anschließend wird die neue Replikatgruppe zentral hoch- und die alte Gruppe zentral herunterskaliert, sodass die gewünschte Replikatanzahl erhalten bleibt. Alte Pods werden erst gelöscht, wenn die neuen Pods bereit sind. Kubernetes protokolliert den Verlauf des Updates, damit Sie bei Bedarf ein Rollback für das Update ausführen können.
Beispiel: Azure Service Fabric verwendet standardmäßig die Strategie paralleler Updates. Diese Strategie eignet sich am besten für die Bereitstellung einer Dienstversion mit neuen Features, ohne vorhandene APIs zu ändern. Service Fabric startet eine Upgradebereitstellung, indem es den Anwendungstyp für eine Teilmenge der Knoten oder eine Updatedomäne aktualisiert. Anschließend wird der Vorgang für die nächste Updatedomäne fortgesetzt, bis alle Domänen aktualisiert sind. Falls eine Upgradedomäne nicht aktualisiert werden kann, wird der Anwendungstyp für alle Domänen wieder auf die vorherige Version zurückgesetzt. Beachten Sie, dass ein Anwendungstyp mit mehreren Diensten (und bei Aktualisierung aller Dienste im Rahmen einer Upgradebereitstellung) fehleranfällig ist. Wenn ein Dienst nicht aktualisiert werden kann, wird die gesamte Anwendung auf die vorherige Version zurückgesetzt, und die weiteren Dienste werden nicht aktualisiert.
Eine der Herausforderungen bei parallelen Updates besteht darin, dass während der Aktualisierung eine Mischung aus alten und neuen Versionen ausgeführt wird und Datenverkehr empfängt. Während dieser Zeit können Anforderungen jeweils an eine der beiden Versionen weitergeleitet werden.
Für Breaking Changes an APIs ist es eine bewährte Methode, beide Versionen parallel zu unterstützen, bis alle Clients der Vorversion aktualisiert wurden. Mehr dazu finden Sie unter API-Versionsverwaltung.
Blaugrün-Bereitstellung
Bei einer Blaugrün-Bereitstellung stellen Sie die neue Version zusammen mit der vorherigen Version bereit. Nach der Überprüfung der neuen Version leiten Sie sämtlichen Datenverkehr von der vorherigen Version zur neuen Version um. Anschließend überwachen Sie die Anwendung auf mögliche Probleme. Im Problemfall können Sie zur alten Version zurückkehren. Liegen keine Probleme, können Sie die alte Version löschen.
Bei einer eher traditionellen monolithischen oder n-schichtigen Anwendung war eine Blaugrün-Bereitstellung in der Regel mit der Bereitstellung zweier identischer Umgebungen verbunden. Dabei musste die neue Version in einer Stagingumgebung bereitgestellt und der Clientdatenverkehr anschließend an die Stagingumgebung umgeleitet werden (beispielsweise durch Austauschen der VIP-Adressen). In einer Microservicearchtektur erfolgen Updates in der Microserviceschicht, also stellen Sie normalerweise das Update in der gleichen Umgebung bereit und verwenden einen Mechanismus für die Diensterkennung für den Umstieg.
Beispiel. In Kubernetes müssen Sie für eine Blaugrün-Bereitstellung keinen separaten Cluster bereitstellen. Stattdessen können Sie Selektoren nutzen. Erstellen Sie eine neue Bereitstellungsressource mit einer neuen Pod-Spezifikation und einem anderen Satz von Bezeichnungen. Erstellen Sie diese Bereitstellung, ohne die vorherige Bereitstellung zu löschen oder den Dienst zu ändern, der darauf verweist. Wenn die neuen Pods aktiv sind, können Sie den Selektor des Diensts auf die neue Bereitstellung aktualisieren.
Ein Nachteil von Blaugrün-Bereitstellungen ist, dass während der Aktualisierung doppelt so viele Pods für den Dienst (aktuelle und neue Version) aktiv sind. Wenn die Pods einen hohen Bedarf an CPU- oder Arbeitsspeicherressourcen haben, müssen Sie den Cluster zur Bewältigung des Ressourcenbedarfs möglicherweise vorübergehend aufskalieren.
Canary-Release
Bei einem Canary-Release führen Sie eine aktualisierte Version für eine geringe Anzahl von Clients ein. Anschließend überwachen Sie das Verhalten des neuen Diensts, bevor Sie ihn für alle Clients einführen. Dies ermöglicht eine langsame, kontrollierte Einführung, die Beobachtung echter Daten und die Erkennung von Problemen, bevor alle Kunden betroffen sind.
Die Verwaltung eines Canary-Release ist im Vergleich zu einer Blaugrün-Bereitstellung oder einem parallelen Update komplexer, da Anforderungen dynamisch an verschiedene Versionen des Diensts weitergeleitet werden müssen.
Beispiel. In Kubernetes können Sie einen Dienst so konfigurieren, dass er sich über zwei Replikatgruppen (eine für jede Version) erstreckt, und die Replikatanzahl manuell anpassen. Aufgrund des von Kubernetes verwendeten Lastenausgleichs zwischen Pods ist dieser Ansatz jedoch nicht sehr präzise. Ein Beispiel: Wenn Sie insgesamt über 10 Replikate verfügen, können Sie Datenverkehr nur in Zehn-Prozent-Schritten verlagern. Bei Verwendung eines Dienstnetzes können Sie mithilfe der entsprechenden Routingregeln eine komplexere Canary-Release-Strategie implementieren.
Nächste Schritte
- Lernpfad: Definieren und Implementieren von Continuous Integration
- Training: Einführung in Continuous Delivery (CD)
- Microservicearchitektur
- Gründe für einen Microservices-Ansatz zum Erstellen von Anwendungen