Was ist die richtige Größe für einen Microservice? Diese Frage wird häufig mit „nicht zu groß und nicht zu klein“ beantwortet. Das ist zwar richtig, aber nicht sonderlich hilfreich. Auf der Grundlage eines sorgfältig entworfenen Domänenmodells lassen sich Microservices viel leichter besprechen.
In diesem Artikel wird ein Drohnenlieferdienst als Beispiel verwendet. Weitere Informationen zum Szenario sowie die entsprechende Referenzimplementierung finden Sie hier.
Vom Domänenmodell zu Microservices
Im vorherigen Artikel haben wir eine Reihe von Kontextgrenzen für eine Drohnenlieferungsanwendung definiert. Anschließend haben wir uns eingehender mit einer dieser Kontextgrenzen (dem Versandkontext) befasst und eine Reihe von Entitäten, Aggregaten und Domänendiensten für diese Kontextgrenze identifiziert.
Nun sind wir bereit für den Schritt vom Domänenmodell zum Anwendungsentwurf. Mit dem folgenden Ansatz können Sie Microservices vom Domänenmodell ableiten.
Beginnen Sie mit einer Kontextgrenze. Grundsätzlich sollte die Funktion in einem Microservice nicht mehrere Kontextgrenzen umfassen. Eine Kontextgrenze markiert definitionsgemäß die Grenze eines bestimmten Domänenmodells. Falls ein Microservice verschiedene Domänenmodelle miteinander vermischt, sollten Sie ggf. wieder zur Domänenanalyse zurückkehren und diese optimieren.
Betrachten Sie als Nächstes die Aggregate in Ihrem Domänenmodell. Aggregate sind häufig gute Kandidaten für Microservices. Ein sorgfältig entworfenes Aggregat weist viele Merkmale eines sorgfältig entworfenen Microservice auf:
- Einem Aggregat liegen geschäftliche Anforderungen zugrunde, keine technischen Aspekte wie Datenzugriff oder Messaging.
- Ein Aggregat sollte über eine hohe funktionale Kohäsion verfügen.
- Ein Aggregat ist eine Persistenzgrenze.
- Aggregate sollten lose gekoppelt sein.
Auch Domänendienste sind gute Kandidaten für Microservices. Domänendienste sind zustandslose, aggregatübergreifende Vorgänge. Ein typisches Beispiel ist ein Workflow, der mehrere Microservices umfasst. Die Drohnenlieferungsanwendung enthält ein entsprechendes Beispiel.
Berücksichtigen Sie außerdem nicht funktionsbezogene Anforderungen. Betrachten Sie Faktoren wie Teamgröße, Datentypen und Technologien sowie Skalierbarkeits-, Verfügbarkeits- und Sicherheitsanforderungen. Auf der Grundlage dieser Faktoren können Sie einen Microservice ggf. in mehrere kompaktere Dienste aufspalten oder aber mehrere Microservices zu einem einzelnen Dienst zusammenfassen.
Nachdem Sie die Microservices in Ihrer Anwendung identifiziert haben, überprüfen Sie Ihren Entwurf anhand folgender Kriterien:
- Jeder Dienst hat eine einzelne Aufgabe.
- Zwischen Diensten findet keine übermäßige Kommunikation statt. Falls die Aufspaltung von Funktionen in zwei Dienste zu übermäßiger Kommunikation zwischen den Diensten führt, kann dies ein Indiz dafür sein, dass die Funktionen in einen einzelnen Dienst gehören.
- Jeder Dienst ist so kompakt, dass er von einem kleinen unabhängigen Team erstellt werden kann.
- Es bestehen keine gegenseitigen Abhängigkeiten, die eine Abstimmung bei der Bereitstellung mehrerer Dienste erforderlich machen. Die Bereitstellung eines Diensts muss immer ohne erneute Bereitstellung anderer Dienste möglich sein.
- Dienste sind nicht eng gekoppelt und können unabhängig voneinander weiterentwickelt werden.
- Ihre Dienstgrenzen führen nicht zu Problemen mit der Datenkonsistenz oder -integrität. Manchmal ist es wichtig, die Datenkonsistenz zu wahren, indem Funktionen in einem einzelnen Microservice platziert werden. Nichtsdestotrotz sollten Sie sich überlegen, ob Sie wirklich eine starke Konsistenz benötigt. Es gibt Strategien für die Implementierung von letztlicher Konsistenz in einem verteilten System, und die Vorteile einer Zerlegung der Dienste überwiegen häufig die Herausforderungen der Verwendung von letztlicher Konsistenz.
Am wichtigsten ist jedoch: Seien Sie pragmatisch, und denken Sie daran, dass DDD (Domain-Driven Design) ein iterativer Prozess ist. Beginnen Sie im Zweifelsfall mit undifferenzierteren Microservices. Die Aufspaltung eines Microservice in zwei kompaktere Dienste ist einfacher als ein Refactoring mehrerer vorhandener Microservices.
Beispiel: Definieren von Microservices für die Drohnenlieferungsanwendung
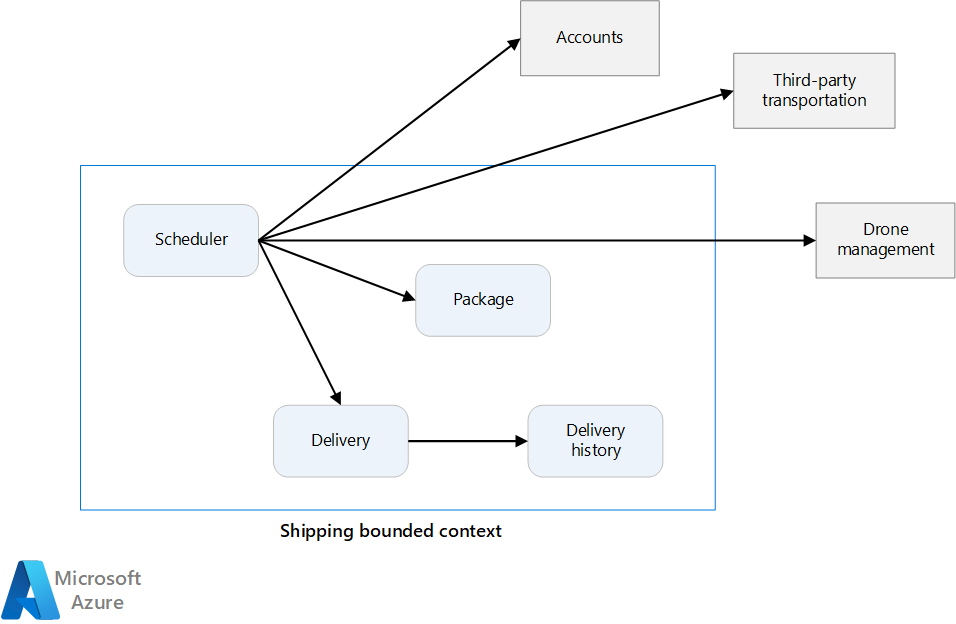
Das Entwicklungsteam hatte ja die vier Aggregate „Delivery“ (Lieferung), „Package“ (Paket), „Drone“ (Drohne) und „Account“ (Konto) sowie die beiden Domänendienste „Scheduler“ (Planung) und „Supervisor“ identifiziert.
„Delivery“ und „Package“ sind offensichtliche Kandidaten für Microservices. „Scheduler“ und „Supervisor“ koordinieren die Aktivitäten anderer Microservices, weshalb es sinnvoll ist, diese Domänendienste als Microservices zu implementieren.
„Drone“ und „Account“ sind interessant, da sie zu anderen Kontextgrenzen gehören. Eine Möglichkeit wäre, dass „Scheduler“ die Kontextgrenzen „Drone“ und „Account“ direkt aufruft. Eine andere Möglichkeit besteht darin, die Microservices „Drone“ und „Account“ innerhalb der Kontextgrenze „Shipping“ (Versand) zu erstellen. Diese Microservices würden dann als Vermittler zwischen den Kontextgrenzen fungieren, indem sie APIs oder Datenschemas verfügbar machen, die besser für den Versandkontext geeignet sind.
Da wir in diesem Leitfaden nicht weiter auf die Details der Kontextgrenzen „Drone“ und „Account“ eingehen, haben wir in unserer Referenzimplementierung entsprechende Pseudodienste erstellt. Hier sind jedoch einige Faktoren, die Sie in dieser Situation berücksichtigen sollten:
Wie hoch ist der zusätzliche Netzwerkaufwand, der durch direkte Aufrufe an die andere Kontextgrenze entsteht?
Eignet sich das Datenschema der anderen Kontextgrenze für diesen Kontext, oder ist es besser, ein Schema zu verwenden, das speziell auf diese Kontextgrenze zugeschnitten ist?
Handelt es sich bei der anderen Kontextgrenze um ein Legacysystem? In diesem Fall können Sie einen Dienst erstellen, der als Antibeschädigungsebene fungiert und zwischen dem Legacysystem und der modernen Anwendung vermittelt.
Welche Teamstruktur wird verwendet? Kann problemlos mit dem Team kommuniziert werden, das für die andere Kontextgrenze zuständig ist? Falls nicht, kann es hilfreich sein, einen Dienst als Vermittler zwischen den beiden Kontexten zu erstellen, um die Kosten für die teamübergreifende Kommunikation zu senken.
Bislang haben wir noch keine nicht funktionsbezogenen Anforderungen berücksichtigt. Angesichts der Durchsatzanforderungen der Anwendung hat das Entwicklungsteam beschlossen, einen separaten Microservice namens „Ingestion“ (Erfassung) zu erstellen, der für die Erfassung von Clientanforderungen zuständig ist. Dieser Microservice implementiert einen Belastungsausgleich, indem er eingehende Anforderungen zur Verarbeitung in einem Puffer platziert. „Scheduler“ liest die Anforderungen aus dem Puffer und führt den Workflow aus.
Nicht funktionsbezogene Anforderungen haben das Team zur Erstellung eines zusätzlichen Diensts veranlasst. Bislang ging es bei allen Diensten um die Zeitplanung und Auslieferung von Paketen in Echtzeit. Für die Datenanalyse muss das System jedoch auch den Verlauf jeder Lieferung in einem langfristigen Speicher speichern. Das Team hat erwogen, diese Funktion dem Dienst „Delivery“ zuzuordnen. Die Datenspeicheranforderungen für die Analyse von Verlaufsdaten unterscheiden sich jedoch deutlich von den Anforderungen für laufende Vorgänge. (Weitere Informationen finden Sie unter Überlegungen zu Daten). Aus diesem Grund hat sich das Team dazu entschieden, einen separaten Dienst namens „Delivery History“ (Lieferverlauf) zu erstellen, der auf DeliveryTracking-Ereignisse des Diensts „Delivery“ lauscht und die Ereignisse in einen langfristigen Speicher schreibt.
Das folgende Diagramm zeigt den aktuellen Stand des Designs:
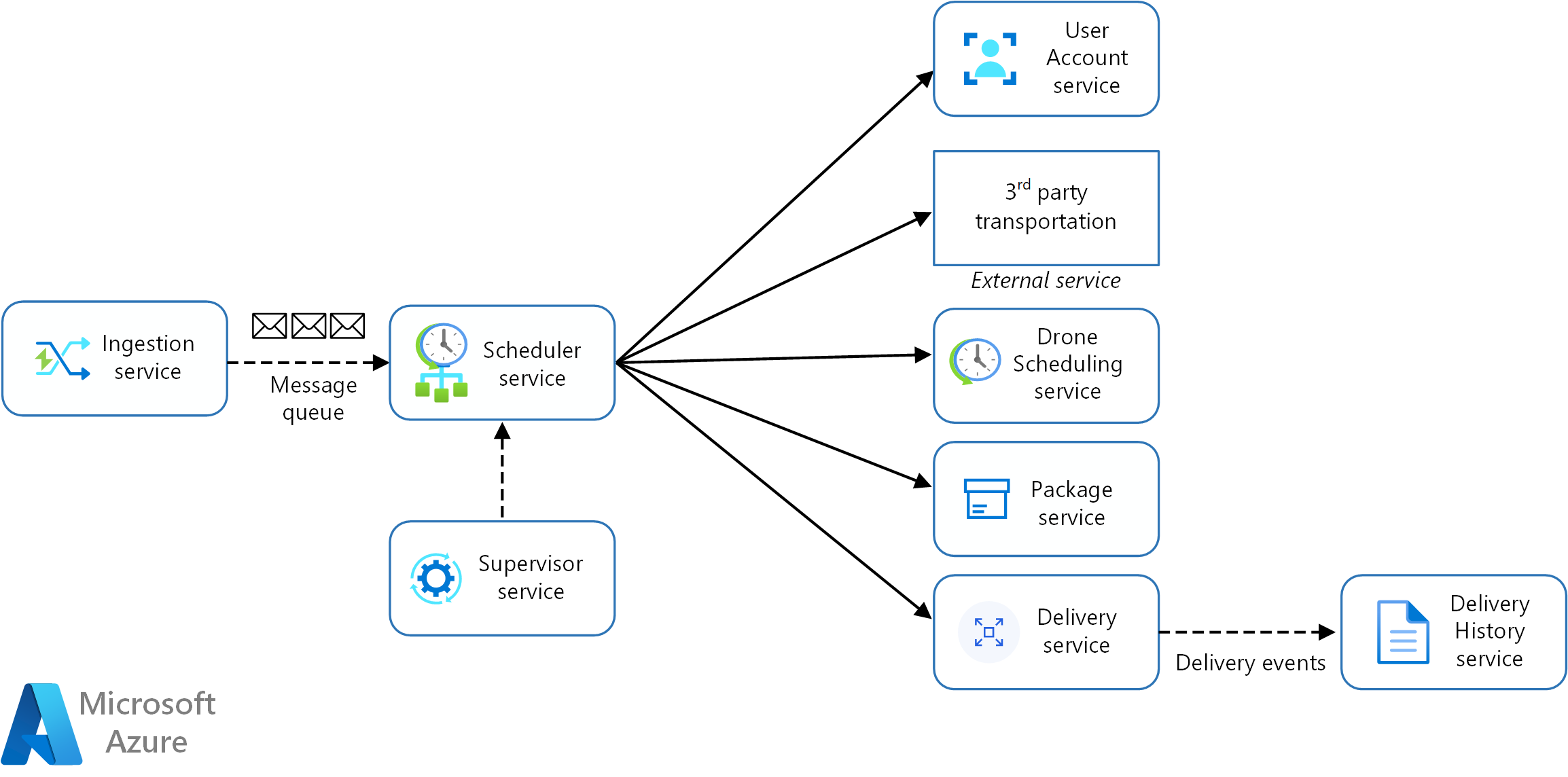
Laden Sie eine Visio-Datei dieser Architektur herunter.
Nächste Schritte
Sie sollten nun mit dem Zweck und der Funktion der einzelnen Microservices in Ihrem Entwurf vertraut sein. Als Nächstes können Sie die Architektur des Systems erstellen.