Resilienz und Notfallwiederherstellung im Azure Web PubSub-Dienst
Resilienz und Notfallwiederherstellung sind eine übliche Anforderung für Onlinesysteme. Der Azure Web PubSub-Dienst garantiert bereits eine Verfügbarkeit von 99,9 %, ist aber noch immer ein regionaler Dienst. Bei einem regionsweiten Ausfall ist es wichtig, dass der Dienst weiterhin Echtzeitnachrichten in einer anderen Region verarbeiten kann.
Für die regionale Notfallwiederherstellung empfehlen wir die folgenden beiden Ansätze:
- Georeplikation aktivieren (einfach). Dieses Feature behandelt automatisch das regionale Failover. Wenn diese Option aktiviert ist, werden nur eine Azure SignalR-Instanz neu Standard und es werden keine Codeänderungen eingeführt. Überprüfen Sie die Georeplikation auf Details.
- Verwenden sie mehrere Endpunkte. In diesem Dokument erfahren Sie, wie Sie dies tun .
Hoch verfügbare Architektur für den Web PubSub-Dienst
Es gibt zwei typische Muster, die den Web PubSub-Dienst verwenden:
- Eins ist das Clientservermuster, das Clients Ereignisse an den Server senden und Server Nachrichten an die Clients pusht.
- Ein weiteres ist client-client-Muster, das Clients pub/sub messages über den Web PubSub-Dienst an andere Clients senden.
In den folgenden Abschnitten werden verschiedene Möglichkeiten für diese beiden Muster zum Ausführen der Notfallwiederherstellung beschrieben.
Hoch verfügbare Architektur für das Clientservermuster
Um regionsübergreifende Resilienz für den Web PubSub-Dienst zu erreichen, müssen Sie mehrere Dienstinstanzen in verschiedenen Regionen einrichten. So können beim Ausfall einer Region die anderen Regionen als Sicherung fungieren.
Ein typisches Setup für ein regionsübergreifendes Szenario ist die Verwendung von zwei (oder mehr) Paaren von Web PubSub-Dienstinstanzen und App-Servern.
In jedem Paar befinden sich App-Server und Web PubSub-Dienst in derselben Region, und der Web PubSub-Dienst legt den Ereignishandler upstream auf den App-Server in derselben Region fest.
Zur besseren Veranschaulichung der Architektur wird der Web PubSub-Dienst als primärer Dienst für den App-Server im gleichen Paar bezeichnet. Web PubSub-Dienste in anderen Paaren werden als sekundäre Dienste für den App-Server bezeichnet.
Der Anwendungsserver kann die API für die Überprüfung der Dienstintegrität verwenden, um zu ermitteln, ob die primären und sekundären Dienste fehlerfrei sind oder nicht. Für einen Web PubSub-Dienst mit dem Namen demo gibt der Endpunkt https://demo.webpubsub.azure.com/api/health beispielsweise den Wert 200 zurück, wenn der Dienst fehlerfrei ist. Der App-Server kann die Endpunkte in regelmäßigen Abständen oder bei Bedarf aufrufen, um zu überprüfen, ob die Endpunkte fehlerfrei sind. WebSocket-Clients verknüpfen sich in der Regel zuerst mit ihrem Anwendungsserver, um die URL abzurufen, die eine Verbindung mit dem Web PubSub-Dienst herstellt. Die Anwendung verwendet diesen Schritt des Verknüpfens, um ein Failover der Clients auf andere fehlerfreie sekundäre Dienste auszuführen. Hier finden Sie die ausführlichen Schritte:
- Beim Aushandeln zwischen einem Client und dem App-Server SOLLTE der App-Server nur primäre Web PubSub-Dienstendpunkte zurückgeben, sodass Clients im Normalfall nur eine Verbindung mit primären Endpunkten herstellen.
- Wenn die primäre Instanz nicht erreichbar ist, SOLLTE beim Aushandeln ein fehlerfreier sekundärer Endpunkt zurückgegeben werden, damit der Client weiterhin Verbindungen herstellen kann, und der Client stellt eine Verbindung mit dem sekundären Endpunkt her.
- Wenn die primäre Instanz eingerichtet ist, SOLLTE das Verknüpfen den fehlerfreien primären Endpunkt zurückgeben, damit Clients jetzt eine Verbindung mit dem primären Endpunkt herstellen können.
- Wenn der App-Server Nachrichten an mehrere Clients überträgt, SOLLTEN Nachrichten an alle fehlerfreien Endpunkte übertragen werden, sowohl an die primären als auch an die sekundären.
- Der App-Server kann Verbindungen schließen, die mit sekundären Endpunkten verbunden sind, um die Clients zu zwingen, stattdessen eine Verbindung mit dem fehlerfreien primären Endpunkt herzustellen.
In dieser Topologie können Nachrichten von einem Server weiterhin an alle Clients übermittelt werden, da alle App-Server und Web PubSub-Dienstinstanzen miteinander verbunden sind.
Wir haben die Strategie noch nicht in das SDK integriert, daher muss die Anwendung diese Strategie vorerst selbst implementieren.
Zusammenfassend gilt: Die Anwendungsseite muss Folgendes implementieren:
- Integritätsprüfung Die Anwendung kann entweder überprüfen, ob der Dienst fehlerfrei ist, indem sie die API für die Überprüfung der Dienstintegrität in regelmäßigen Abständen im Hintergrund oder bei Bedarf für jeden Verknüpfungsaufruf verwendet.
- Verknüpfungslogik Die Anwendung gibt standardmäßig einen fehlerfreien primären Endpunkt zurück. Wenn der primäre Endpunkt nicht verfügbar ist, gibt die Anwendung einen fehlerfreien sekundären Endpunkt zurück.
- Übertragungslogik Wenn Nachrichten an mehrere Clients gesendet werden, muss die Anwendung sicherstellen, dass nachrichten an alle fehlerfreien Endpunkte übertragen werden.
Das folgende Diagramm veranschaulicht diese Topologie:
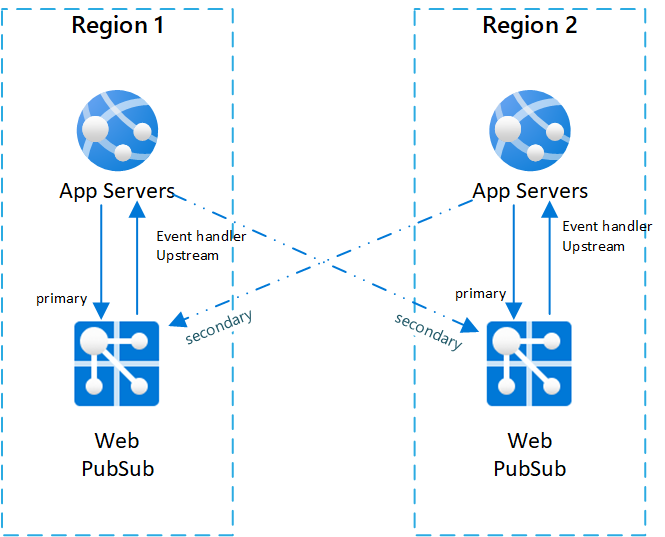
Failoversequenz und bewährte Methode
Sie verfügen jetzt über die richtige Konfiguration der Systemtopologie. Sollte eine Web PubSub-Dienstinstanz ausfallen, wird Onlinedatenverkehr zu anderen Instanzen geroutet. Folgendes geschieht, wenn eine primäre Instanz ausfällt (und später wiederhergestellt wird):
- Die primäre Dienstinstanz ist ausgefallen, alle damit verbundenen Clients werden getrennt.
- Neue Clients oder Clients, die die Verbindung wiederherstellen möchten, führen eine Aushandlung mit dem App-Server durch.
- Der App-Server erkennt, dass die primäre Dienstinstanz ausgefallen ist, und bei Aushandlungen wird nicht mehr dieser Endpunkt, sondern ein fehlerfreier sekundärer Endpunkt zurückgegeben.
- Clients stellen eine Verbindung mit der sekundären Instanz her.
- Die sekundäre Instanz übernimmt nun den gesamten Onlinedatenverkehr. Alle Nachrichten vom Server an Clients können weiterhin übermittelt werden, da die sekundäre Instanz mit allen App-Servern verbunden ist. Ereignismeldungen von Clients an den Server werden jedoch nur an den Upstream-App-Server in derselben Region gesendet.
- Nachdem die primäre Instanz wiederhergestellt und wieder online geschaltet wurde, erkennt der App-Server, dass die primäre Instanz wieder fehlerfrei ist. Bei der Aushandlung wird jetzt wieder der primäre Endpunkt zurückgegeben, sodass neue Clients mit dem primären Endpunkt verbunden werden. Vorhandene Clients werden jedoch nicht getrennt und sind weiterhin mit dem sekundären Endpunkt verbunden, bis sie die Verbindung selbst trennen.
Die folgenden Diagramme veranschaulichen, wie ein Failover durchgeführt wird:
Abb.1 Vor Failover 
Abb.2 Nach Failover 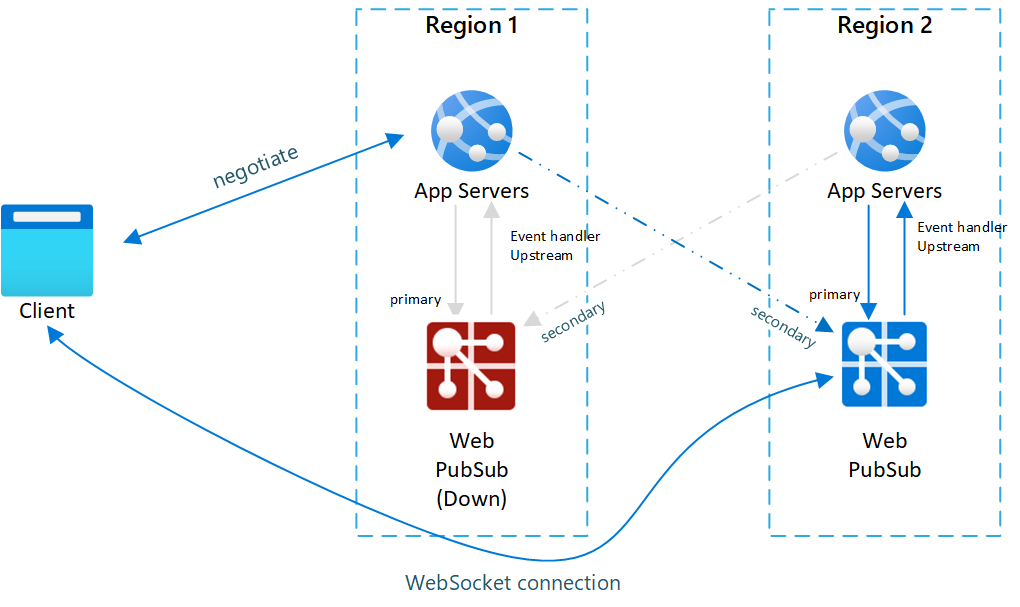
Abb.3 Kurze Zeit nach der primären Wiederherstellung 
Wie Sie sehen, ist Onlinedatenverkehr im Normalfall nur für den primären App-Server und die primäre Web PubSub-Dienstinstanz vorhanden (blau dargestellt).
Nach dem Failover werden auch der sekundäre App-Server und die sekundäre Web PubSub-Instanz aktiv. Nach dem der primäre Web PubSub-Dienst wieder online geschaltet wurde, stellen neue Clients eine Verbindung mit der primären Web PubSub-Instanz her. Vorhandene Clients stellen jedoch weiterhin eine Verbindung mit der sekundären Instanz her, sodass beide Instanzen Datenverkehr verarbeiten.
Nachdem alle vorhandenen Clients die Verbindung getrennt haben, kehrt das System zum normalen Betriebszustand zurück (Abb. 1).
Für die Implementierung einer regionsübergreifenden hochverfügbaren Architektur stehen zwei grundlegende Muster zur Verfügung:
- Das erste ist die Verwendung eines Paars aus App-Server und Web PubSub-Dienstinstanz, das den gesamten Onlinedatenverkehr verarbeitet, und eines weiteren Paars als Sicherung (bezeichnet als Aktiv/Passiv-Konfiguration, siehe Abb. 1).
- Das zweite ist die Verwendung von zwei (oder mehr) Paaren aus App-Servern und Web PubSub-Dienstinstanzen, die alle Onlinedatenverkehr verarbeiten und als Sicherung für andere Paare fungieren (bezeichnet als Aktiv/Aktiv-Konfiguration, siehe Abb. 3).
Der Web PubSub-Dienst kann beide Muster unterstützen. Der wesentliche Unterschied besteht in der Implementierung der App-Server. Wenn App-Server aktiv/passiv sind, sind auch die Web PubSub-Instanzen aktiv/passiv (weil der primäre App-Server nur seine primäre Web PubSub-Dienstinstanz zurückgibt). Wenn App-Server aktiv/aktiv sind, sind auch die Web PubSub-Instanzen aktiv/aktiv (weil alle App-Server ihre eigenen primären Web PubSub-Instanzen zurückgeben und daher alle Datenverkehr empfangen können).
Beachten Sie, dass Sie unabhängig vom ausgewählten Muster jede Web PubSub-Dienstinstanz als primäre Rolle mit einem App-Server verbinden müssen.
Aufgrund der Natur von WebSocket-Verbindungen (lange Verbindungen) treten zudem im Fall eines Failovers nach einem Notfall Verbindungsabbrüche bei Clients auf. Sie müssen solche Verbindungsabbrüche auf der Clientseite behandeln, damit sie für Ihre Endkunden transparent sind. Stellen Sie beispielsweise nach dem Schließen einer Verbindung erneut eine Verbindung her.
High available architecture for client-client pattern
Für client-client-muster ist es derzeit noch nicht möglich, eine Zero-Down-Time-Notfallwiederherstellung mit mehreren Instanzen zu unterstützen. Wenn Sie hohe Verfügbarkeitsanforderungen haben, sollten Sie die Georeplikation in Betracht ziehen.
So testen Sie ein Failover
Führen Sie die Schritte aus, um das Failover auszulösen:
- Deaktivieren Sie auf der Registerkarte "Netzwerk" für die primäre Ressource im Portal den Öffentlichen Netzwerkzugriff. Wenn die Ressource ein privates Netzwerk aktiviert hat, verwenden Sie Zugriffssteuerungsregeln , um den gesamten Datenverkehr zu verweigern.
- Starten Sie die primäre Ressource neu .
Nächste Schritte
In diesem Artikel haben Sie erfahren, wie Sie Ihre Anwendung konfigurieren, um Resilienz für den Web PubSub-Dienst zu erreichen.
Erstellen Sie mithilfe dieser Ressourcen Ihre eigene Anwendung: