Worum handelt es sich bei „Benutzerdefinierte neuronale Stimme“?
„Benutzerdefinierte neuronale Stimme“ (Custom Neural Voice, CNV) ist ein Sprachsynthesefeature, mit dem Sie eine einzigartige, benutzerdefinierte synthetische Stimme für Ihre Anwendungen erstellen können. Mit „Benutzerdefinierte neuronale Stimme“ können Sie eine äußerst natürlich klingende Stimme für Ihre Marke oder Ihre Figuren erstellen, indem Sie Beispiele menschlicher Sprache als Trainingsdaten bereitstellen.
Wichtig
Der Zugriff auf die benutzerdefinierte neuronale Stimme ist auf der Grundlage von Berechtigungs- und Nutzungskriterien eingeschränkt. Fordern Sie den Zugriff über das Aufnahmeformular an.
Der Zugriff auf Benutzerdefinierte neuronale Stimme Lite (Custom Neural Voice, CNV) ist für alle verfügbar, um CNV in einer Demoversion auszuprobieren und zu bewerten, bevor Sie in professionelle Aufzeichnungen investieren, um eine hochwertigere Stimme zu generieren.
Standardmäßig kann Sprachsynthese mit vordefinierten neuronalen Stimmen für jede unterstützte Sprache verwendet werden. Die vordefinierten neuronalen Stimmen funktionieren in den meisten Sprachsyntheseszenarios gut, wenn keine eindeutige Stimme erforderlich ist.
„Benutzerdefinierte neuronale Stimme“ basiert auf der neuronalen Sprachsynthesetchnologie und dem mehrsprachigen Universalmodell mit mehreren Sprechern. Sie können synthetische Stimmen erstellen, die reich an Sprechstilen oder über Sprachgrenzen hinweg anpassbar sind. Die realistische und natürlich klingende Stimme der benutzerdefinierten neuronalen Stimme kann Marken repräsentieren, Computer personifizieren und es Benutzer*innen ermöglichen, mit Anwendungen zu interagieren. Hier finden Sie Informationen zu den unterstützten Sprachen für die benutzerdefinierte neuronale Stimme.
Wie funktioniert sie?
Um eine benutzerdefinierte neuronale Stimme zu erstellen, verwenden Sie Speech Studio, um die aufgenommenen Audiodaten und die entsprechenden Skripts hochzuladen, das Modell zu trainieren und die Stimme an einem benutzerdefinierten Endpunkt bereitzustellen.
Tipp
Testen Sie Benutzerdefinierte neuronale Stimme Lite, um CNV in einer Demoversion auszuprobieren und zu beurteilen, bevor Sie in professionelle Aufzeichnungen investieren, um eine hochwertigere Stimme zu generieren.
Die Erstellung einer hervorragenden benutzerdefinierten neuronalen Stimme erfordert eine sorgfältige Qualitätskontrolle in jedem Schritt, von Sprachentwurf und Datenaufbereitung bis hin zur Bereitstellung des Stimmmodells in Ihrem System.
Berücksichtigen Sie bei Ihrem Einstieg in Speech Studio diese Überlegungen:
- Entwerfen Sie eine Persona der Stimme, die Ihre Marke repräsentiert, mithilfe eines kurzen Persona-Dokuments. In diesem Dokument werden Elemente wie die Merkmale der Stimme und der Charakter hinter der Stimme definiert. Dies hilft, den Prozess der Erstellung eines benutzerdefinierten neuronalen Stimmmodells zu steuern, einschließlich des Definierens der Skripts, der Auswahl Ihres Sprechers, des Trainings und der Stimmoptimierung.
- Wählen Sie das Aufzeichnungsskript aus, das die Benutzerszenarien für Ihre Stimme darstellt. Sie können z. B. die Ausdrücke aus Botkonversationen als Aufzeichnungsskript verwenden, wenn Sie einen Kundendienstbot erstellen. Fügen Sie verschiedene Satztypen in Ihre Skripts ein, einschließlich Aussagen, Fragen und Ausrufen.
Hier sehen Sie eine Übersicht der Schritte zum Erstellen einer benutzerdefinierten neuronalen Stimme in Speech Studio:
- Erstellen Sie ein Projekt, das Ihre Daten, Sprachmodelle, Tests und Endpunkte enthält. Jedes Projekt ist für ein Land/eine Region und eine Sprache spezifisch. Wenn Sie mehrere Stimmen erstellen möchten, empfiehlt es sich, für jede Stimme ein Projekt zu erstellen.
- Richten Sie eine(n) Sprecher*in ein. Bevor Sie eine neuronale Stimme trainieren können, müssen Sie eine Aufzeichnung der Einwilligungserklärung des/der Sprecher*in einreichen. Die Erklärung des/der Sprecher*in ist eine Aufzeichnung des/der Sprecher*in beim Verlesen einer Erklärung, dass er/sie der Verwendung seiner/ihrer Sprachdaten zum Trainieren eines benutzerdefinierten Stimmmodells zustimmt.
- Bereiten Sie Trainingsdaten im richtigen Format vor. Es wird empfohlen, die Audioaufzeichnungen in einem professionellen Aufnahmestudio mit entsprechender Qualität zu erfassen, um einen hohen Signal-Rausch-Abstand zu erzielen. Die Qualität des Stimmmodells hängt stark von Ihren Trainingsdaten ab. Konsistente Lautstärke, Sprechgeschwindigkeit, Tonhöhe und Konsistenz in den ausdrucksvollen Eigenheiten der Sprache sind erforderlich.
- Trainieren Sie Ihr Stimmmodell. Wählen Sie mindestens 300 Äußerungen aus, um eine benutzerdefinierte neuronale Stimme zu erstellen. Eine Reihe von Datenqualitätsprüfungen werden automatisch ausgeführt, wenn Sie sie hochladen. Um qualitativ hochwertige Stimmmodelle zu erstellen, sollten Sie alle Fehler beheben und die Übermittlung erneut durchführen.
- Testen Sie Ihre Stimme. Bereiten Sie Testskripts für Ihr Sprachmodell vor, die die verschiedenen Anwendungsfälle für Ihre Apps abdecken. Es wird empfohlen, Skripts innerhalb und außerhalb des Trainingsdatasets zu verwenden, damit Sie die Qualität für verschiedene Inhalte umfassender testen können.
- Stellen Sie Ihr Stimmmodell bereit, und verwenden Sie es in Ihren Apps.
Sie können Ihre benutzerdefinierte Stimme ganz ähnlich wie eine vordefinierte neuronale Stimme optimieren, anpassen und verwenden. Konvertieren Sie Text in Echtzeit in Sprache oder generieren Sie offline Audioinhalte mit Texteingabe. Sie verwenden die REST-API, das Speech SDK oder Speech Studio.
Tipp
Sie können auch das Speech-SDK und die Custom Voice-REST-API verwenden, um eine benutzerdefinierte neuronale Stimme zu trainieren.
Sehen Sie sich die Codebeispiele im Speech-SDK-Repository auf GitHub an, um zu erfahren, wie Sie eine benutzerdefinierte neurale Stimme in Ihrer Anwendung verwenden.
Der Stil und die Merkmale des trainierten Stimmmodells hängen vom Stil und der Qualität der Aufzeichnungen des Sprechers ab, der für das Training verwendet wird. Sie können jedoch mehrere Anpassungen mithilfe von SSML (Speech Synthesis Markup Language) vornehmen, wenn Sie die API-Aufrufe für Ihr Sprachmodell vornehmen, um synthetische Sprache zu generieren. SSML ist die Markupsprache, die für die Kommunikation mit dem Sprachsynthese-Dienst verwendet wird, um Text in Audio zu konvertieren. Die Anpassungen, die Sie vornehmen können, umfassen die Änderung von Tonhöhe, Geschwindigkeit, Intonation und Aussprachekorrektur. Wenn das Stimmmodell mit mehreren Stilen erstellt wird, können Sie auch SSML verwenden, um die Stile zu wechseln.
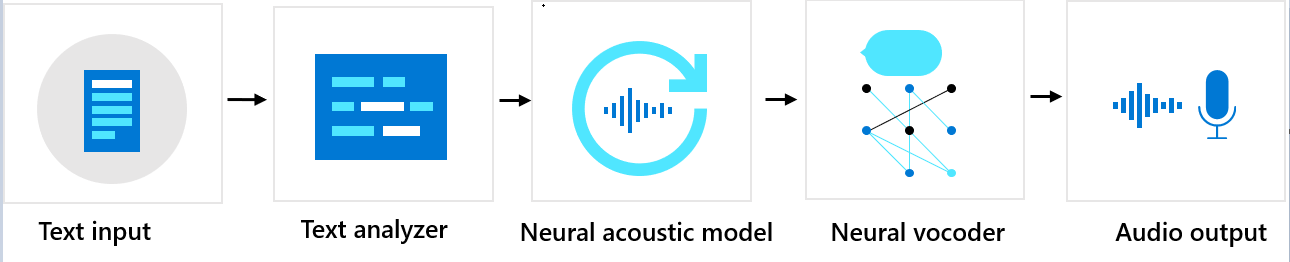
Reihenfolge der Komponenten
„Benutzerdefinierte neuronale Stimme“ besteht aus drei Hauptkomponenten: der Textanalyse, dem neuronalen Akustikmodell und dem neuronalen Vocoder. Zum Erzeugen einer natürlichen synthetischen Stimme aus Text wird der Text zunächst in die Textanalyse eingegeben, die eine Ausgabe in Form einer Phonemfolge liefert. Ein Phonem ist eine grundlegende Lauteinheit, die ein Wort in einer bestimmten Sprache von einem anderen unterscheidet. Eine Folge von Phonemen definiert die Aussprache der im Text vorgesehenen Wörter.
Als Nächstes geht die Phonemsequenz in das neuronale Akustikmodell ein, um Akustikfeatures vorherzusagen, die Sprachsignale definieren. Zu den Akustikfeatures gehören das Timbre, der Sprechstil, die Geschwindigkeit, Intonationen und Betonungsmuster. Schließlich wandelt der neuronale Vocoder die akustischen Features in hörbare Wellen um, sodass synthetische Sprache erzeugt wird.
Neuronale Modelle zur Sprachsynthese werden mithilfe von Deep Neural Networks trainiert, die auf Aufnahmestichproben menschlicher Stimmen basieren. Weitere Informationen finden Sie in diesem Microsoft-Blogbeitrag. Weitere Informationen zum Trainieren eines neuronalen Vocoders finden Sie in diesem Microsoft-Blogbeitrag.
Migrieren zur benutzerdefinierten neuronalen Stimme
Wenn Sie die alte Version von Custom Voice verwenden (die im Februar 2024 eingestellt werden soll), finden Sie weitere Informationen unter Migrieren zu „Benutzerdefinierte neuronale Stimme“.
Verantwortungsvolle KI
Zu einem KI-System gehört nicht nur die Technologie, sondern auch die Personen, die das System verwenden, sowie die davon betroffenen Personen und die Umgebung, in der es bereitgestellt wird. Lesen Sie die Transparenzhinweise, um mehr über die verantwortungsvolle Nutzung und den Einsatz von KI in Ihren Systemen zu erfahren.
- Transparenzhinweis und Anwendungsfälle für die benutzerdefinierte neuronale Stimme
- Merkmale und Einschränkungen bei der Verwendung der benutzerdefinierten neuronalen Stimme
- Eingeschränkter Zugriff auf die benutzerdefinierte neuronale Stimme
- Richtlinien für die verantwortungsvolle Bereitstellung von Technologien mit künstlicher Sprache
- Offenlegung für Sprecher
- Entwurfsrichtlinien für die Offenlegung
- Entwurfsmuster für die Offenlegung
- Verhaltensregeln für Sprachsynthese-Integrationen
- Daten, Datenschutz und Sicherheit für die benutzerdefinierte neuronale Stimme