Graphdatenmodellierung mit Azure Cosmos DB for Apache Gremlin
GILT FÜR: ![]() Gremlin
Gremlin
Dieser Artikel enthält Empfehlungen für die Verwendung von Graphdatenmodellen. Diese bewährten Methoden sind von entscheidender Bedeutung, um die Skalierbarkeit und Leistung eines Graphdatenbanksystems bei der Entwicklung der Daten sicherzustellen. Ein effizientes Datenmodell ist insbesondere für große Graphen wichtig.
Requirements (Anforderungen)
Der in dieser Anleitung beschriebene Prozess basiert auf folgenden Annahmen:
- Die Entitäten im Aufgabenbereich sind bekannt. Diese Entitäten müssen bei jeder Anforderung atomisch genutzt werden. Das heißt, das Datenbanksystem ist nicht darauf ausgelegt, die Daten einer einzelnen Entität in mehreren Abfrageanforderungen abzurufen.
- Die Lese- und Schreibanforderungen für das Datenbanksystem sind bekannt. Von diesen Anforderungen hängt ab, welche Optimierungen für das Graphdatenmodell erforderlich sind.
- Die Prinzipien des Eigenschaftsgraph-Standards von Apache Tinkerpop sind bekannt.
Wann benötige ich eine Graphdatenbank?
Eine Graphdatenbanklösung kann optimal verwendet werden, wenn die Entitäten und Beziehungen in einer Datendomäne folgende Merkmale aufweisen:
- Die Entitäten sind durch beschreibende Beziehungen stark vernetzt. Der Vorteil in diesem Szenario besteht darin, dass die Beziehungen im Speicher persistent sind.
- Es gibt zyklische Beziehungen und Entitäten mit Selbstverweis. Dieses Muster stellt bei relationalen Datenbanken oder Dokumentdatenbanken häufig eine Herausforderung dar.
- Zwischen Entitäten gibt es Beziehungen, die sich dynamisch entwickeln. Dieses Muster ist insbesondere bei hierarchischen oder auf einer Baumstruktur basierenden Daten mit zahlreichen Ebenen anzutreffen.
- Zwischen Entitäten gibt es m:n-Beziehungen.
- Es gibt Schreib- und Leseanforderungen (sowohl für Entitäten als auch für Beziehungen) .
Sind die obigen Kriterien erfüllt, hat ein Ansatz mit einer Graphdatenbank wahrscheinlich Vorteile für die Abfragekomplexität, die Skalierbarkeit des Datenmodells und die Abfrageleistung.
Im nächsten Schritt muss bestimmt werden, ob der Graph für Analysen oder für Transaktionen verwendet wird. Wenn der Graph für Workloads mit hohen Rechen- und Datenverarbeitungsanforderungen vorgesehen ist, sollten Sie sich mit dem Cosmos DB Spark-Connector sowie mit der Verwendung der GraphX-Bibliothek vertraut machen.
Verwenden von Graphobjekten
Im Eigenschaftsgraph-Standard von Apache Tinkerpop sind zwei Arten von Objekten definiert: Scheitelpunkte und Kanten.
Im Anschluss finden Sie bewährte Methoden für die Eigenschaften in den Graphobjekten:
| Object | Eigenschaft | type | Notizen |
|---|---|---|---|
| Scheitelpunkt | id | String | Individuell pro Partition erzwungen. Ist beim Einfügen kein Wert angegeben, wird ein automatisch generierter GUID gespeichert. |
| Scheitelpunkt | Bezeichnung | String | Diese Eigenschaft dient zum Definieren der Art von Entität, die der Scheitelpunkt darstellt. Ist kein Wert angegeben, wird der Standardwert vertex verwendet. |
| Scheitelpunkt | Eigenschaften | Zeichenfolge, boolescher Wert, numerischer Wert | Eine Liste separater Eigenschaften, die in jedem Scheitelpunkt als Schlüssel-Wert-Paare gespeichert sind. |
| Scheitelpunkt | Partitionsschlüssel | Zeichenfolge, boolescher Wert, numerischer Wert | Diese Eigenschaft definiert den Speicherort für den Scheitelpunkt und die zugehörigen ausgehenden Kanten. Weitere Informationen zur Graphpartitionierung finden Sie hier. |
| Microsoft Edge | id | String | Individuell pro Partition erzwungen. Standardmäßig automatisch generiert. Kanten müssen in der Regel nicht individuell anhand einer ID abgerufen werden. |
| Edge | Bezeichnung | String | Diese Eigenschaft dient zum Definieren der Art von Beziehung zwischen zwei Scheitelpunkten. |
| Microsoft Edge | Eigenschaften | Zeichenfolge, boolescher Wert, numerischer Wert | Eine Liste separater Eigenschaften, die in jeder Kante als Schlüssel-Wert-Paare gespeichert sind. |
Hinweis
Für Kanten ist kein Partitionsschlüsselwert erforderlich, da der Wert automatisch auf der Grundlage des Quellscheitelpunkts zugewiesen wird. Weitere Informationen finden Sie unter Verwenden eines partitionierten Graphen in Azure Cosmos DB.
Richtlinien für die Modellierung von Entitäten und Beziehungen
Die folgenden Richtlinien helfen Ihnen bei der Modellierung von Daten einer Azure Cosmos DB for Apache Gremlin-Graphdatenbank. Bei diesen Richtlinien wird davon ausgegangen, dass eine Datendomänendefinition sowie Abfragen für diese Domäne vorhanden sind.
Hinweis
Die folgenden Schritte stellen Empfehlungen dar. Sie sollten das endgültige Modell bewerten und testen, bevor Sie es als bereit für die Produktion betrachten. Die Empfehlungen gelten außerdem speziell für die Gremlin-API-Implementierung von Azure Cosmos DB.
Modellieren von Scheitelpunkten und Eigenschaften
Im ersten Schritt für ein Graphdatenmodell muss jede identifizierte Entität einem Scheitelpunktobjekt zugeordnet werden. Eine 1: 1-Zuordnung aller Entitäten zu Scheitelpunkten sollte ein erster Schritt sein, wobei die Zuordnung ggf. später noch geändert werden kann.
Ein häufig begangener Fehler besteht darin, Eigenschaften einer einzelnen Entität als separate Scheitelpunkte zuzuordnen. Im folgenden Beispiel ist die gleiche Entität auf zwei verschiedene Arten dargestellt:
Scheitelpunktbasierte Eigenschaften: Bei diesem Ansatz werden die Eigenschaften der Entität mithilfe von drei separaten Scheitelpunkten und zwei Kanten beschrieben. Dadurch verringert sich zwar möglicherweise die Redundanz, dafür erhöht sich die Komplexität. Eine höhere Modellkomplexität kann längere Wartezeiten, eine höhere Abfragekomplexität sowie höhere Computekosten zur Folge haben. Darüber hinaus erschwert dieses Modell unter Umständen auch die Partitionierung.

In Scheitelpunkte eingebettete Eigenschaften: Bei diesem Ansatz wird die Liste mit Schlüssel-Wert-Paaren verwendet, um alle Eigenschaften der Entität innerhalb eines Scheitelpunkts darzustellen. Dadurch verringert sich die Modellkomplexität, was wiederum zu einfacheren Abfragen und kosteneffizienteren Traversierungen führt.

Hinweis
Die obigen Diagramme zeigen ein vereinfachtes Graphmodell, das nur die zwei Möglichkeiten der Unterteilung von Entitätseigenschaften vergleicht.
Das Muster der in Scheitelpunkte eingebetteten Eigenschaften ist in der Regel die leistungsfähigere und besser skalierbare Lösung. Bei neuen Graphdatenmodellen sollte daher standardmäßig zunächst dieses Muster in Betracht gezogen werden.
Es gibt jedoch Szenarien, in denen unter Umständen Verweise auf eine Eigenschaft vorzuziehen sind. Ein Beispiel wäre etwa, wenn die referenzierte Eigenschaft häufig aktualisiert wird. Verwenden Sie einen separaten Scheitelpunkt zur Darstellung einer häufig aktualisierten Eigenschaft, um für die Aktualisierung erforderlichen Schreibvorgänge zu minimieren.
Beziehungsmodelle mit Kantenrichtungen
Nach Abschluss der Scheitelpunktmodellierung können die Kanten hinzugefügt werden, um die gegenseitigen Beziehungen anzugeben. Der erste Aspekt, der ausgewertet werden muss, ist die Richtung der Beziehung.
Kantenobjekte haben eine Standardrichtung, die bei einer Traversierung unter Verwendung der Funktionen out() oder outE() verwendet wird. Die Verwendung dieser natürlichen Richtung ist effizient, da alle Scheitelpunkte mit ihren ausgehenden Kanten gespeichert werden.
Eine Traversierung entgegen der Kantenrichtung (mit der Funktion in()) hat dagegen immer eine partitionsübergreifende Abfrage zur Folge. Informieren Sie sich eingehender über die Graphpartitionierung. Wenn kontinuierlich Traversierungen unter Verwendung der Funktion in() erforderlich sind, empfiehlt es sich, Kanten in beiden Richtungen hinzuzufügen.
Die Kantenrichtung kann mithilfe des Prädikats .to() oder .from() im Gremlin-Schritt .addE() bestimmt werden. Alternativ kann die Bulk Executor-Bibliothek für die Gremlin-API verwendet werden.
Hinweis
Kantenobjekte haben standardmäßig eine Richtung.
Beziehungsbezeichnungen
Die Verwendung aussagekräftiger Beziehungsbezeichnungen kann zur Verbesserung der Effizienz von Kantenauflösungsvorgängen beitragen. Sie können dieses Muster wie folgt anwenden:
- Verwenden Sie spezifische Begriffe für Beziehungsbezeichnungen.
- Ordnen Sie die Bezeichnung des Quellscheitelpunkts der Bezeichnung des Zielscheitelpunkts mit dem Beziehungsnamen zu.
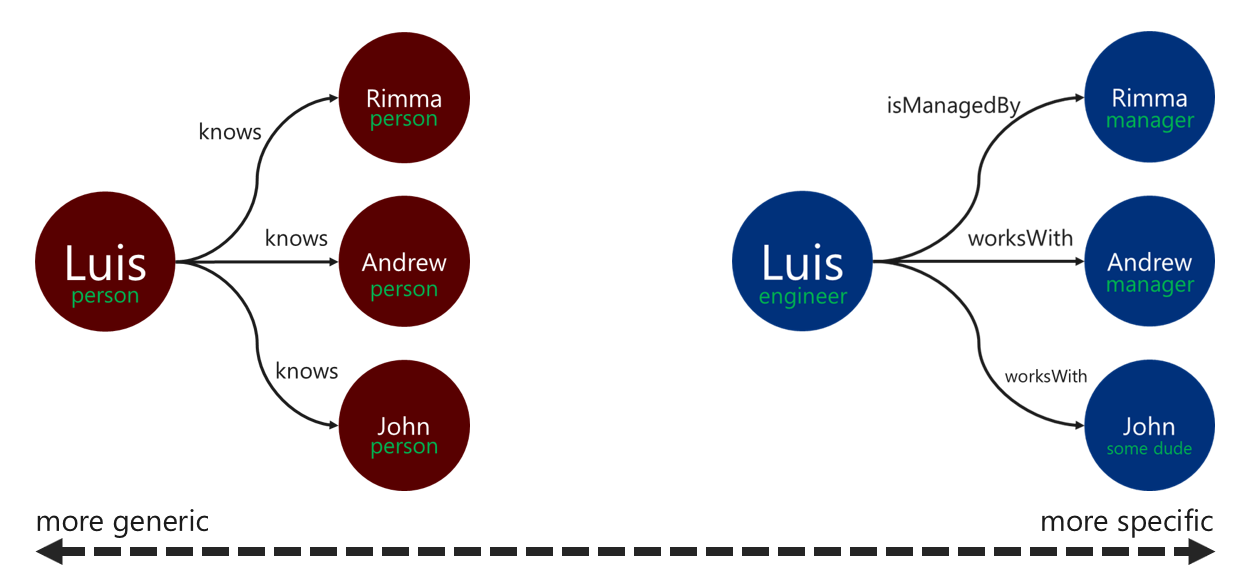
Je spezifischer die Bezeichnung, die bei der Traversierung zum Filtern der Kanten verwendet wird, desto besser. Diese Entscheidung kann sich auch erheblich auf die Abfragekosten auswirken. Die Abfragekosten können jederzeit mithilfe des Schritts „Ausführungsprofil“ ausgewertet werden.
Nächste Schritte
- Sehen Sie sich die Liste mit den unterstützten Gremlin-Schritten an.
- Informieren Sie sich über das Verwenden eines partitionierten Graphen in Azure Cosmos DB für große Graphen.
- Verwenden Sie den Schritt „Ausführungsprofil“, um Ihre Gremlin-Abfragen auszuwerten.
- Ein Graph-Design-Datenmodell von einem Drittanbieter