Retrieval Augmented Generation (RAG) in Azure Databricks
Dieser Artikel enthält eine Übersicht über Retrieval Augmented Generation (RAG) und beschreibt die RAG-Anwendungsunterstützung in Azure Databricks.
Was ist Retrieval Augmented Generation?
RAG ist ein Entwurfsmuster für generative KI, bei dem ein großes Sprachmodell (Large Language Model, LLM) mit externem Wissensabruf kombiniert wird. RAG ist erforderlich, um Echtzeitdaten mit Ihren generativen KI-Anwendungen zu verbinden. Dadurch wird die Genauigkeit und Qualität der Anwendung verbessert, da Sie Ihre Daten zur Rückschlusszeit als Kontext für das LLM bereitstellen.
Die Databricks-Plattform bietet integrierte Tools, die die folgenden RAG-Szenarien unterstützen.
| RAG-Typ | Beschreibung | Beispiel eines Anwendungsfalls |
|---|---|---|
| Unstrukturierte Daten | Verwendung von Dokumenten – PDFs, Wikis, Websiteinhalte, Google- oder Microsoft Office-Dokumente usw. | Chatbot für Produktdokumentation |
| Strukturierte Daten | Verwendung von Tabellendaten – Delta-Tabellen, Daten aus vorhandenen Anwendungs-APIs | Chatbot zum Überprüfen des Bestellstatus |
| Tools und Funktionsaufruf | Rufen Sie Drittanbieter-APIs oder interne APIs auf, um bestimmte Aufgaben auszuführen oder Status zu aktualisieren. Beispiel: Ausführen von Berechnungen oder Auslösen eines Geschäftsworkflows | Chatbot zum Aufgeben einer Bestellung |
| Agents | Entscheiden Sie dynamisch, wie Sie mithilfe eines LLM auf eine Benutzerabfrage reagieren, um eine Folge von Aktionen auszuwählen. | Chatbot, der einen*eine Kundendienstmitarbeiter*in ersetzt |
RAG-Anwendungsarchitektur
Die folgende Abbildung veranschaulicht die Komponenten, aus denen sich eine RAG-Anwendung zusammensetzt:

RAG-Anwendungen erfordern eine Pipeline und eine Kettenkomponente für Folgendes:
- Indizierung: Eine Pipeline, die Daten aus einer Quelle erfasst und indiziert. Diese Daten können strukturiert oder unstrukturiert sein.
- Abruf und Generierung: Dies ist die eigentliche RAG-Kette. Sie verwendet die Benutzerabfrage, ruft ähnliche Daten aus dem Index ab und übergibt dann die Daten zusammen mit der Abfrage an das LLM-Modell.
Das folgende Diagramm veranschaulicht diese Kernkomponenten:

RAG-Beispiel für unstrukturierte Daten
In den folgenden Abschnitten werden die Details der Indizierungspipeline und der RAG-Kette im Kontext eines RAG-Beispiels für unstrukturierte Daten beschrieben.
Indizierungspipeline in einer RAG-App
Die folgenden Schritte beschreiben die Indizierungspipeline:
- Erfassen von Daten aus Ihrer geschützten Datenquelle.
- Aufteilen der Daten in Blöcke, die in das Kontextfenster des grundlegenden LLM passen. Dieser Schritt umfasst auch das Parsen der Daten und das Extrahieren von Metadaten. Diese Daten werden häufig als Wissensdatenbank bezeichnet, anhand der das grundlegende LLM trainiert wird.
- Verwenden eines Einbettungsmodells, um Vektoreinbettungen für die Datenblöcke zu erstellen.
- Speichern der Einbettungen und Metadaten in einer Vektordatenbank, um sie für die Abfrage durch die RAG-Kette zugänglich zu machen
Abrufen mithilfe der RAG-Kette
Nach der Vorbereitung des Index kann die RAG-Kette der Anwendung bereitgestellt werden, um Fragen zu beantworten. In den folgenden Schritten und Diagrammen wird beschrieben, wie die RAG-Anwendung auf eine eingehende Anforderung reagiert.
- Einbetten der Anforderung mithilfe des gleichen Einbettungsmodells, das zum Einbetten der Daten in der Wissensdatenbank verwendet wurde
- Abfragen der Vektordatenbank, um eine Ähnlichkeitssuche zwischen der eingebetteten Anforderung und den eingebetteten Datenblöcken in der Vektordatenbank durchzuführen
- Abrufen der Datenblöcke, die für die Anforderung am relevantesten sind
- Übertragen der relevanten Datenblöcke und der Anforderung an ein benutzerdefiniertes LLM. Die Datenblöcke stellen Kontext bereit, mit dessen Hilfe das LLM eine entsprechende Antwort generieren kann. Häufig verfügt das LLM über eine Vorlage zum Formatieren der Antwort.
- Generieren einer Antwort
Dieser Prozess wird anhand des folgenden Diagramms veranschaulicht.

Entwickeln von RAG-Anwendungen mit Azure Databricks
Databricks bietet die folgenden Funktionen, mit denen Sie RAG-Anwendungen entwickeln können.
- Unity Catalog für Governance, Ermittlung, Versionsverwaltung und Zugriffssteuerung für Daten, Features, Modelle und Funktionen.
- Notebooks und Workflows für die Erstellung und Orchestrierung von Datenpipelines
- Delta-Tabellen zum Speichern strukturierter Daten und unstrukturierter Datenblöcke und Einbettungen
- Die Vektorsuche stellt eine abfragefähige Vektordatenbank bereit, in der eingebettete Vektoren gespeichert und die so konfiguriert werden kann, dass sie automatisch mit Ihrer Wissensdatenbank synchronisiert wird.
- Databricks-Modellbereitstellung für das Bereitstellen von LLMs und das Hosten Ihrer RAG-Kette. Sie können einen dedizierten Model Serving-Endpunkt speziell für den Zugriff auf hochmoderne offene LLMs mit Foundation Model-APIs oder für Drittanbietermodelle mit externen Modellen konfigurieren.
- MLflow für die Nachverfolgung der RAG-Kettenentwicklung und LLM-Auswertung
- Feature Engineering und Featurebereitstellung. Dies gilt in der Regel für RAG-Szenarien mit strukturierten Daten.
- Onlinetabellen. Sie können Onlinetabellen als latenzarme API bereitstellen, um die Daten in RAG-Anwendungen einzuschließen.
- Lakehouse Monitoring für die Datenüberwachung und Nachverfolgung von Modellvorhersagequalität und -drift mithilfe automatischer Nutzlastprotokollierung mit Rückschlusstabellen
- KI-Playground. Eine chatbasierte Benutzeroberfläche zum Testen und Vergleichen von LLMs.
RAG-Architektur mit Azure Databricks
Die folgenden Architekturdiagramme veranschaulichen, wie die einzelnen Azure Databricks-Features in den RAG-Workflow passen. Ein Beispiel finden Sie in der Demo zum Bereitstellen Ihres LLM-Chatbots mit Retrieval Augmented Generation.
Verarbeiten unstrukturierter Daten und der von Databricks verwalteten Einbettungen
Das folgende Diagramm zeigt die für die Verarbeitung unstrukturierter Daten und der von Databricks verwalteten Einbettungen erforderlichen Schritte:
- Datenerfassung aus Ihrer proprietären Datenquelle. Sie können diese Daten in einer Delta-Tabelle oder auf einem Unity Catalog-Volume speichern.
- Die Daten werden dann in Blöcke aufgeteilt, die in das Kontextfenster des zugrunde liegenden LLM passen. Dieser Schritt umfasst auch das Parsen der Daten und das Extrahieren von Metadaten. Sie können Databricks-Workflows, Databricks-Notebooks und Delta Live Tables verwenden, um diese Aufgaben auszuführen. Diese Daten werden häufig als Wissensdatenbank bezeichnet, anhand der das grundlegende LLM trainiert wird.
- Die geparsten und unterteilten Daten werden dann von einem Einbettungsmodell verwendet, um Vektoreinbettungen zu erstellen. In diesem Szenario berechnet Databricks die Einbettungen für Sie als Teil der Vektorsuchfunktion, die Model Serving verwendet, um ein Einbettungsmodell bereitzustellen.
- Nachdem die Vektorsuche Einbettungen berechnet hat, speichert Databricks sie in einer Delta-Tabelle.
- Ebenfalls im Rahmen der Vektorsuche werden die Einbettungen und Metadaten indiziert und in einer Vektordatenbank gespeichert, um sie für die Abfrage durch die RAG-Kette verfügbar zu machen. Die Vektorsuche berechnet automatisch Einbettungen für neue Daten, die der Quelldatentabelle hinzugefügt werden, und aktualisiert den Vektorsuchindex.

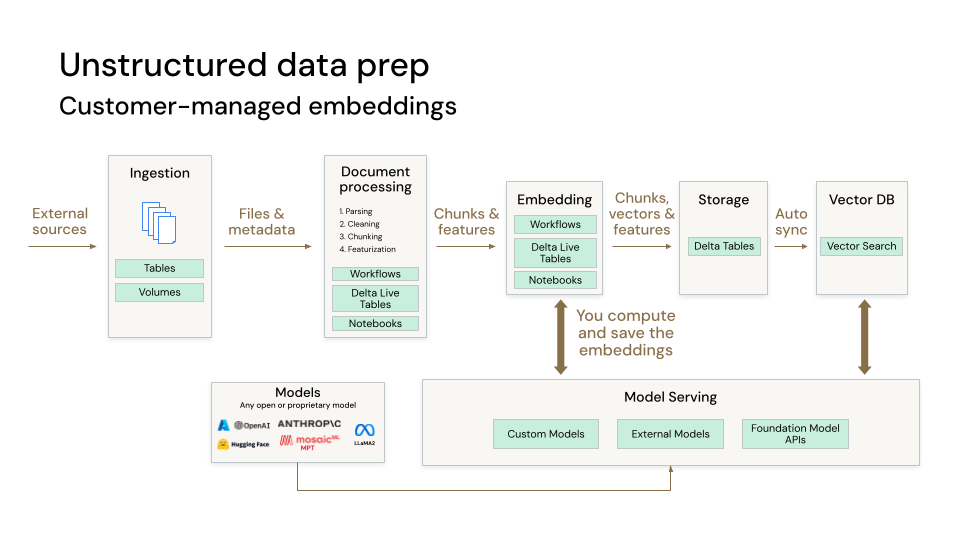
Verarbeiten unstrukturierter Daten und von kundenseitig verwalteten Einbettungen
Das folgende Diagramm zeigt die für die Verarbeitung unstrukturierter Daten und von kundenseitig verwalteten Einbettungen erforderlichen Schritte:
- Datenerfassung aus Ihrer proprietären Datenquelle. Sie können diese Daten in einer Delta-Tabelle oder auf einem Unity Catalog-Volume speichern.
- Sie können die Daten in Blöcke aufteilen, die in das Kontextfenster des zugrunde liegenden LLM passen. Dieser Schritt umfasst auch das Parsen der Daten und das Extrahieren von Metadaten. Sie können Databricks-Workflows, Databricks-Notebooks und Delta Live Tables verwenden, um diese Aufgaben auszuführen. Diese Daten werden häufig als Wissensdatenbank bezeichnet, anhand der das grundlegende LLM trainiert wird.
- Danach können die geparsten und unterteilten Daten von einem Einbettungsmodell verwendet werden, um Vektoreinbettungen zu erstellen. In diesem Szenario berechnen Sie die Einbettungen selbst und können Model Serving verwenden, um ein Einbettungsmodell bereitzustellen.
- Nachdem Sie Einbettungen berechnet haben, können Sie diese in einer Delta-Tabelle speichern, die mit der Vektorsuche synchronisiert werden kann.
- Im Rahmen der Vektorsuche werden die Einbettungen und Metadaten indiziert und in einer Vektordatenbank gespeichert, um sie für die Abfrage durch die RAG-Kette verfügbar zu machen. Die Vektorsuche synchronisiert automatisch neue Einbettungen, die Ihrer Delta-Tabelle hinzugefügt werden, und aktualisiert den Vektorsuchindex.
Verarbeiten strukturierter Daten
Das folgende Diagramm zeigt die für die Verarbeitung strukturierter Daten erforderlichen Schritte:
- Datenerfassung aus Ihrer proprietären Datenquelle. Sie können diese Daten in einer Delta-Tabelle oder auf einem Unity Catalog-Volume speichern.
- Sie können für die Featurisierung Databricks-Notebooks, Databricks-Workflows und Delta Live Tables verwenden.
- Erstellen einer Featuretabelle Eine Featuretabelle ist eine Delta-Tabelle in Unity Catalog, die über einen Primärschlüssel verfügt.
- Erstellen Sie eine Onlinetabelle, und hosten Sie diese auf einem Feature & Function Serving-Endpunkt. Der Endpunkt bleibt automatisch synchron mit der Featuretabelle.
Ein Beispielnotebook zur Verwendung von Onlinetabellen und von Feature & Function Serving für RAG-Anwendungen finden Sie unter Databricks-Onlinetabellen und Feature & Function Serving-Endpunkte für RAG: Beispielnotebook.

RAG-Kette
Nach der Vorbereitung des Index kann die RAG-Kette der Anwendung bereitgestellt werden, um Fragen zu beantworten. Die folgenden Schritte und das Diagramm beschreiben, wie die RAG-Kette als Reaktion auf eine eingehende Frage funktioniert.
- Die eingehende Frage wird mithilfe desselben Einbettungsmodells eingebettet, das zum Einbetten der Daten in die Wissensdatenbank verwendet wurde. Für die Bereitstellung des Einbettungsmodells wird Model Serving verwendet.
- Nachdem die Frage eingebettet wurde, können Sie die Vektorsuche verwenden, um eine Ähnlichkeitssuche zwischen der eingebetteten Frage und den eingebetteten Datenblöcken in der Vektordatenbank durchzuführen.
- Nachdem die Vektorsuche die Datenblöcke abgerufen hat, die für die Anforderung am relevantesten sind, werden diese Datenblöcke zusammen mit relevanten Features aus Feature & Function Serving und der eingebetteten Frage in einem benutzerdefinierten LLM für die Nachbearbeitung verwendet, bevor eine Antwort generiert wird.
- Die Datenblöcke und Features stellen den Kontext bereit, mit dessen Hilfe das LLM eine passende Antwort generieren kann. Häufig verfügt das LLM über eine Vorlage zum Formatieren der Antwort. Erneut wird Model Serving für das LLM verwendet. Sie können auch Unity Catalog und Lakehouse Monitoring verwenden, um Protokolle zu speichern bzw. den Kettenworkflow zu überwachen.
- Generieren einer Antwort

Regionale Verfügbarkeit
Die Features, die die RAG-Anwendungsentwicklung in Databricks unterstützen, sind in den gleichen Regionen wie die Modellbereitstellung verfügbar.
Wenn Sie die Verwendung von Foundation Model-APIs im Rahmen der RAG-Anwendungsentwicklung planen, sind Sie auf die unterstützten Regionen für Foundation Model-APIs beschränkt.