Features und Terminologie in Azure Event Hubs
Azure Event Hubs ist ein skalierbarer Ereignisverarbeitungsdienst, der große Mengen von Ereignissen und Daten mit kurzer Wartezeit und hoher Zuverlässigkeit erfasst und verarbeitet. Unter Was ist Event Hubs? finden Sie einen allgemeinen Überblick über den Dienst.
Dieser Artikel setzt auf den Informationen in der Übersichtsartikel auf und bietet technische und Implementierungsdetails zu Event Hubs-Komponenten und -Features.
Namespace
Ein Event Hubs-Namespace ist ein Verwaltungscontainer für Event Hubs (oder „Themen“ in Kafka-Terminologie). Er verfügt über in das DNS integrierte Netzwerkendpunkte und verschiedene Verwaltungsfunktionen für die Zugriffssteuerung und Netzwerkintegration, z. B. IP-Filterung, VNET-Dienstendpunkt und Private Link.

Partitionen
In Event Hubs werden Sequenzen von an einen Event Hub gesendeten Ereignissen in einer oder mehreren Partitionen organisiert. Neu eingehende Ereignisse werden am Ende dieser Sequenz hinzugefügt.

Eine Partition kann als „Commitprotokoll“ betrachtet werden. Partitionen speichern Ereignisdaten, die folgende Informationen enthalten:
- Text des Ereignisses
- Benutzerdefinierte Eigenschaftensammlung zur Beschreibung des Ereignisses
- Metadaten wie den Offset in der Partition und die Nummer in der Datenstromsequenz
- Dienstseitiger Zeitstempel des Akzeptierungsvorgangs

Vorteile der Verwendung von Partitionen
Event Hubs wurde zur Unterstützung der Verarbeitung von großen Ereignismengen konzipiert, und die Partitionierung ist hierbei aus zwei Gründen hilfreich:
- Bei Event Hubs handelt es sich zwar um einen PaaS-Dienst, aber es gibt auch eine physische Komponente. Zum Führen eines Protokolls, in dem die Reihenfolge der Ereignisse festgehalten wird, müssen diese Ereignisse zusammen im zugrunde liegenden Speicher und in den zugehörigen Replikaten gespeichert werden. Dies führt dazu, dass für ein Protokoll dieser Art ein Grenzwert für den Durchsatz gilt. Die Partitionierung ermöglicht die Verwendung mehrerer paralleler Protokolle für den gleichen Event Hub, wodurch sich die verfügbare Rohkapazität für den E/A-Durchsatz (Eingabe/Ausgabe) multipliziert.
- Ihre eigenen Anwendungen müssen die Verarbeitung der Ereignismenge, die an einen Event Hub gesendet wird, bewältigen können. Dies kann ziemlich komplex sein und erfordert eine hohe Kapazität für die Parallelverarbeitung mit Skalierungsoptionen. Die Kapazität eines einzelnen Prozesses zum Verarbeiten von Ereignissen ist begrenzt, sodass Sie mehrere Prozesse benötigen. Partitionen werden von Ihrer Lösung verwendet, um diese Prozesse mit Daten zu versorgen, während gleichzeitig sichergestellt wird, dass jedes Ereignis über einen eindeutigen Verarbeitungsbesitzer verfügt.
Anzahl von Partitionen
Die Anzahl von Partitionen wird zum Zeitpunkt der Erstellung eines Event Hubs angegeben. Sie muss zwischen 1 und der maximal zulässigen Partitionsanzahl für jeden Tarif liegen. Informationen zum Grenzwert für die Partitionsanzahl für jeden Tarif finden Sie in diesem Artikel.
Wir empfehlen, mindestens so viele Partitionen auszuwählen, wie Sie voraussichtlich während der Spitzenauslastung Ihrer Anwendung für den entsprechenden Event Hub benötigen. Mit Ausnahme der Premium- und dedizierte Ebenen können Sie die Anzahl der Partitionen für einen Event-Hub nach dessen Erstellung nicht mehr ändern. Für einen Event-Hub auf einer Premium- oder dedizierten Ebene können Sie die Partitionsanzahl nach seiner Erstellung erhöhen, aber nicht verringern. Die Verteilung von Datenströmen auf die Partitionen, ändert die Zuordnung von Partitionsschlüsseln zu den Partitionen. Daher sollten Sie Änderungen dieser Art nach Möglichkeit unbedingt vermeiden, falls die relative Reihenfolge der Ereignisse in Ihrer Anwendung wichtig ist.
Es ist verlockend, die Anzahl von Partitionen auf den zulässigen Höchstwert festzulegen. Hierbei sollten Sie aber stets beachten, dass Ihre Ereignisdatenströme so strukturiert sein müssen, dass Sie wirklich mehrere Partitionen nutzen können. Falls bei Ihnen die Reihenfolge für alle Ereignisse oder auch nur eine Handvoll untergeordneter Datenströme unbedingt beibehalten werden muss, kommen Sie möglicherweise nicht in den Genuss der Vorteile, die sich aus der Verwendung von mehreren Partitionen ergeben. Wenn mehrere Partitionen genutzt werden, erhöht sich zudem die Komplexität der Verarbeitungsseite.
In Bezug auf die Abrechnung spielt es keine Rolle, wie viele Partitionen sich in einem Event Hub befinden. Die Kosten richten sich nach der Anzahl von Preiseinheiten (Durchsatzeinheiten (TUs) für den Standard-Tarif, Verarbeitungseinheiten (PUs) für den Premium-Tarif und Kapazitätseinheiten (CUs) für den dedizierten Tarif) für den Namespace oder den dedizierten Cluster. Für einen Event Hub im Standard-Tarif mit 32 Partitionen oder einen Event Hub mit nur einer Partition fallen z. B. die gleichen Kosten an, wenn der Namespace auf eine Kapazität von 1 TU festgelegt ist. Darüber hinaus können Sie die Durchsatzeinheiten oder Verarbeitungseinheiten für Ihren Namespace oder die Kapazitätseinheiten Ihres dedizierten Clusters unabhängig von der Partitionsanzahl skalieren.
Eine Partition ist ein Mechanismus für die Datenstrukturierung, mit dem Sie Daten parallel veröffentlichen und nutzen können. Daher empfiehlt es sich, ein ausgewogenes Verhältnis zwischen Skalierungseinheiten (Durchsatzeinheiten für die Standardebene, Verarbeitungseinheiten für die Premium-Ebene oder Kapazitätseinheiten für die dedizierte Ebene) und Partitionen anzustreben, um eine optimale Dimensionierung zu erzielen. Im Allgemeinen wird ein maximaler Durchsatz von 1 MB/s pro Partition empfohlen. Eine Faustregel für die Berechnung der Anzahl der Partitionen wäre daher, den maximal erwarteten Durchsatz durch 1 MB/s zu teilen. Wenn Ihr Anwendungsfall beispielsweise 20 MB/s erfordert, wird empfohlen, mindestens 20 Partitionen zu verwenden, um einen optimalen Durchsatz zu erreichen.
Wenn Sie jedoch über ein Modell verfügen, in dem die Anwendung eine bestimmte Partition bevorzugt, ist eine höhere Anzahl von Partitionen nicht von Vorteil. Weitere Informationen finden Sie unter Verfügbarkeit und Konsistenz.
Zuordnen der Ereignisse zu Partitionen
Sie können einen Partitionsschlüssel zum Zuordnen der in spezifischen Partitionen eingehenden Daten für die Datenorganisation verwenden. Der Partitionsschlüssel ist ein vom Absender bereitgestellter Wert, der an einen Event Hub übergeben wird. Er wird über eine statische Hashfunktion verarbeitet, welche die Partitionszuweisung erstellt. Wenn Sie beim Veröffentlichen eines Ereignisses keinen Partitionsschlüssel angeben, wird eine Roundrobinzuordnung verwendet.
Dem Ereignisherausgeber ist nur der Partitionsschlüssel bekannt, nicht die Partition, auf der die Ereignisse veröffentlicht werden. Dieses Entkoppeln von Schlüssel und Partition entbindet den Absender davon, zu viel über die Downstreamverarbeitung wissen zu müssen. Eine gerätebezogene oder für einen Benutzer eindeutige Identität stellt einen guten Partitionsschlüssel dar, es können aber auch andere Attribute wie z. B. Geografie zum Gruppieren von verwandten Ereignissen in einer einzelnen Partition verwendet werden.
Durch das Angeben eines Partitionsschlüssels können zusammengehörige Ereignisse gemeinsam auf derselben Partition und in der exakten Reihenfolge ihres Empfangs gespeichert werden. Der Partitionsschlüssel ist eine Zeichenfolge, die von Ihrem Anwendungskontext abgeleitet wird, und dient zum Identifizieren der Beziehung zwischen den Ereignissen. Eine von einem Partitionsschlüssel identifizierte Ereignissequenz ist ein Datenstrom. Eine Partition ist ein Multiplex-Protokollspeicher für viele Datenströme dieser Art.
Hinweis
Sie können Ereignisse zwar direkt an Partitionen senden, dies wird jedoch insbesondere dann nicht empfohlen, wenn Sie Wert auf Hochverfügbarkeit legen. Dadurch wird die Verfügbarkeit eines Event Hub auf Partitionsebene herabgestuft. Weitere Informationen finden Sie unter Verfügbarkeit und Konsistenz.
Ereignisherausgeber
Jede Entität, die Daten an einen Event Hub sendet, ist ein Ereignisherausgeber (Synonym: Ereigniserzeuger). Ereignisherausgeber können Ereignisse über HTTPS, AMQP 1.0 oder das Kafka-Protokoll veröffentlichen. Herausgeber von Ereignissen verwenden die auf Microsoft Entra ID basierende Autorisierung mit OAuth2-ausgestellten JWT-Tokens oder einem Event Hub-spezifischen Shared Access Signature (SAS)-Token, um Zugriff auf die Veröffentlichung zu erhalten.
Sie können ein Ereignis über AMQP 1.0, das Kafka-Protokoll oder HTTPS veröffentlichen. Der Event Hubs-Dienst stellt eine REST-API sowie .NET-, Java-, Python-, JavaScript- und Go-Clientbibliotheken für die Veröffentlichung von Ereignissen in einem Event Hub bereit. Für andere Runtimes und Plattformen können beliebige AMQP 1.0-Clients verwendet werden, z.B. Apache Qpid.
Die Wahl zwischen AMQP oder HTTPS ist auf das Verwendungsszenario bezogen. AMQP erfordert die Einrichtung eines persistenten bidirektionalen Sockets zusätzlich zu TLS (Transport Level Security) oder SSL/TLS. AMQP weist höhere Netzwerkkosten beim Initialisieren der Sitzung auf, HTTPS erfordert jedoch zusätzlichen TLS-Mehraufwand für jede Anforderung. Mit AMQP kann eine höhere Leistung für häufig genutzte Herausgeber erzielt werden, und es können deutlich geringere Latenzen realisiert werden, wenn asynchroner Veröffentlichungscode verwendet wird.
Sie können Ereignisse einzeln oder als Batch veröffentlichen. Jede Veröffentlichung ist auf 1 MB beschränkt. Dies gilt unabhängig davon, ob es sich um ein einzelnes Ereignis oder einen Batch handelt. Wenn dieser Schwellenwert für Veröffentlichungsereignisse überschritten wird, werden diese abgelehnt.
Der Event Hubs-Durchsatz wird skaliert, indem Partitionen und Zuteilungen von Durchsatzeinheiten verwendet werden. Eine bewährte Methode für Herausgeber besteht darin, dass das für einen Event Hub ausgewählte spezifische Partitionierungsmodell nicht bekannt ist und nur ein Partitionsschlüssel angegeben wird, der zum konsistenten Zuweisen von verwandten Ereignissen zu derselben Partition verwendet wird.
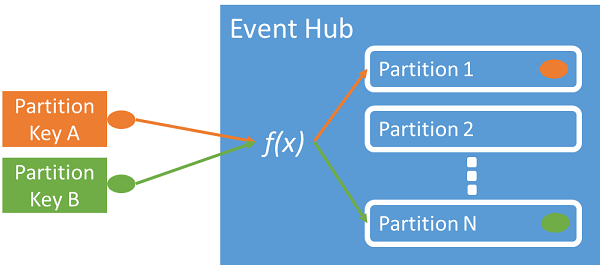
Event Hubs stellt sicher, dass alle Ereignisse mit dem gleichen Partitionsschlüsselwert zusammen gespeichert und in der Empfangsreihenfolge übermittelt werden. Wenn Partitionsschlüssel mit Herausgeberrichtlinien verwendet werden, müssen die Identität des Herausgebers und der Wert des Partitionsschlüssels übereinstimmen. Andernfalls tritt ein Fehler auf.
Aufbewahrung von Ereignissen
Veröffentlichte Ereignisse werden basierend auf einer konfigurierbaren, zeitbasierten Aufbewahrungsrichtlinie aus einem Event Hub entfernt. Folgende wichtige Punkte sind zu beachten:
- Der Standardwert und der kürzestmögliche Aufbewahrungszeitraum beträgt eine Stunde. Derzeit können Sie den Aufbewahrungszeitraum in Stunden nur im Azure-Portal festlegen. Resource Manager-Vorlage, PowerShell und CLI lassen das Festlegen dieser Eigenschaft nur in Tagen zu.
- Für Event Hubs Standard beträgt der maximale Aufbewahrungszeitraum sieben Tage.
- Für die Event Hubs Premium und Dedicated beträgt der maximale Aufbewahrungszeitraum 90 Tage.
- Wenn Sie den Aufbewahrungszeitraum ändern, gilt dies für alle Ereignisse, einschließlich Ereignisse, die sich bereits im Event Hub befinden.
Von Event Hubs werden Ereignisse über einen konfigurierten Aufbewahrungszeitraum aufbewahrt, der für alle Partitionen gilt. Ereignisse werden automatisch entfernt, nachdem das Ende des Aufbewahrungszeitraums erreicht wurde. Wenn Sie einen Aufbewahrungszeitraum mit einer Dauer von einem Tag (24 Stunden) angegeben haben, endet die Verfügbarkeit des Ereignisses genau 24 Stunden nach dem Akzeptierungsvorgang. Sie haben nicht die Möglichkeit, Ereignisse explizit zu löschen.
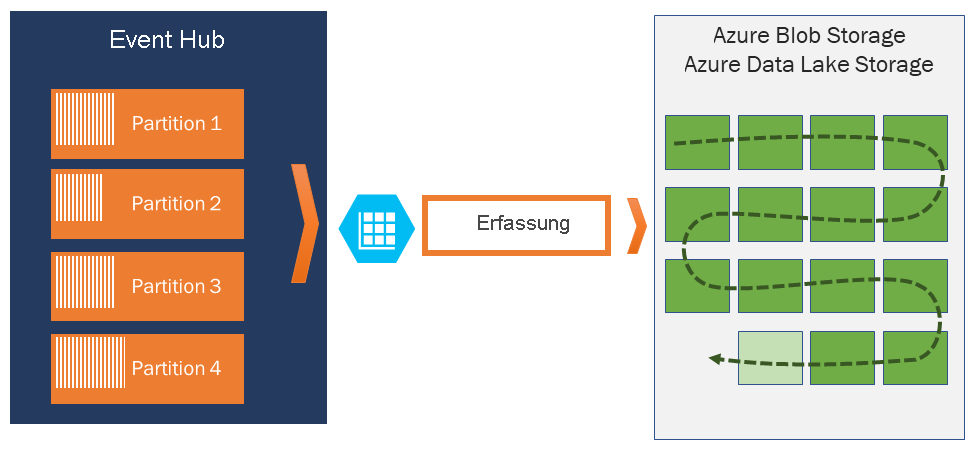
Wenn Sie Ereignisse über die zulässige Aufbewahrungsfrist hinaus archivieren müssen, können Sie sie automatisch in Azure Storage oder Azure Data Lake speichern, indem Sie die Funktion Event Hubs Capture aktivieren. Wenn Sie solche tiefen Archive durchsuchen oder analysieren müssen, können Sie sie einfach in Azure Synapse oder andere ähnliche Speicher und Analyseplattformen importieren.
Durch die zeitliche Beschränkung der Datenaufbewahrung für Event Hubs soll verhindert werden, dass große Mengen von Verlaufsdaten der Kunden in einem tiefen Speicher, der nur mit einem Zeitstempel indiziert ist und für den nur der sequenzielle Zugriff zulässig ist, quasi gefangen sind. Der Grundgedanke dieser Architektur ist, dass für Verlaufsdaten eine umfassendere Indizierung und eine direktere Zugriffsoption benötigt werden, als dies über die Echtzeitoberfläche für Ereignisse von Event Hubs oder Kafka möglich ist. Ereignisdatenstrom-Engines sind nicht gut geeignet, um die Rolle von Data Lakes oder Langzeitarchiven für die Ereignisherkunftsermittlung zu übernehmen.
Hinweis
Event Hubs ist eine Engine für das Ereignisstreaming in Echtzeit. Sie ist nicht dafür ausgelegt, anstelle einer Datenbank bzw. als dauerhafter Speicher für Ereignisdatenströme mit unendlich langer Aufbewahrungsdauer verwendet zu werden.
Je umfangreicher der Verlauf eines Ereignisdatenstroms wird, desto mehr benötigen Sie Hilfsindizes, um ein bestimmtes Verlaufssegment eines bestimmten Datenstroms zu finden. Die Untersuchung von Ereignisnutzdaten und die Indizierung sind nicht Teil des Funktionsumfangs von Event Hubs (oder Apache Kafka). Datenbanken und spezielle Analysespeicher und Engines, z. B. Azure Data Lake Store, Azure Data Lake Analytics und Azure Synapse, sind zum Speichern von Verlaufsereignissen daher viel besser geeignet.
Event Hubs Capture ist direkt in Azure Blob Storage und Azure Data Lake Storage integriert und ermöglicht daher auch das direkte Senden von Ereignissen an Azure Synapse.
Herausgeberrichtlinie
Event Hubs ermöglicht eine differenzierte Kontrolle über Ereignisherausgeber durch Herausgeberrichtlinien. Herausgeberrichtlinien sind Laufzeitfunktionen, mit denen große Mengen unabhängiger Herausgeber verwaltet werden können. Mit Herausgeberrichtlinien verwendet jeder Herausgeber einen eigenen eindeutigen Bezeichner für die Veröffentlichung von Ereignissen in einem Event Hub. Dabei kommt der folgende Mechanismus zum Einsatz:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Sie müssen Herausgebernamen nicht im Voraus erstellen, jedoch müssen diese mit dem SAS-Token übereinstimmen, das beim Veröffentlichen eines Ereignisses verwendet wird, um die Identitäten unabhängiger Herausgeber sicherzustellen. Wenn Sie Herausgeberrichtlinien verwenden, muss der PartitionKey-Wert auf den Herausgebernamen festgelegt werden. Diese Werte müssen übereinstimmen, damit alles ordnungsgemäß funktioniert.
Erfassung
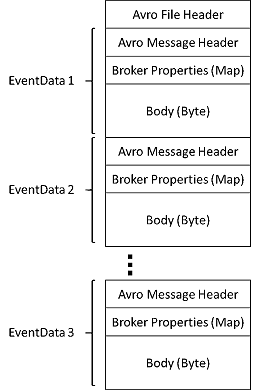
Mit Event Hubs Capture lassen sich die Streamingdaten automatisch in Event Hubs aufzeichnen und in einem Blob Storage-Konto oder einem Azure Data Lake Storage-Konto speichern. Sie können Event Hubs Capture im Azure-Portal aktivieren und eine Mindestgröße sowie ein Mindestzeitfenster für die Aufzeichnung angeben. Mit Event Hubs Capture legen Sie ein eigenes Azure Blob Storage-Konto und einen Container bzw. ein Azure Data Lake Storage-Konto fest, von denen eines zum Speichern der aufgezeichneten Daten verwendet wird. Die aufgezeichneten Daten werden im Apache Avro-Format geschrieben.
Die von Event Hubs Capture erzeugten Dateien weisen das folgende Avro-Schema auf:
Hinweis
Wenn Sie keinen Code-Editor im Azure-Portal verwenden, können Sie Streamingdaten in Event Hubs in einem Azure Data Lake Storage Gen2-Konto im Parquet-Format erfassen. Weitere Informationen finden Sie unter Erfassen von Daten aus Event Hubs im Parquet-Format und Tutorial: Erfassen von Event Hubs-Daten im Parquet-Format und Analysieren der Daten mit Azure Synapse Analytics.
SAS-Token
Event Hubs verwendet Shared Access Signatures, die auf Namespace- und Event Hub-Ebene verfügbar sind. Ein SAS-Token wird aus einem SAS-Schlüssel generiert und ist ein SHA-Hash einer URL, der in einem bestimmten Format codiert ist. Event Hubs kann den Hash anhand des Schlüsselnamens (Richtlinie) und des Tokens erneut generieren und somit den Absender authentifizieren. In der Regel werden SAS-Token für Ereignisherausgeber nur mit Senden-Berechtigung für einen bestimmten Event Hub erstellt. Dieser SAS-Token-URL-Mechanismus bildet die Grundlage für die Herausgeberidentifizierung, die in der Herausgeberrichtlinie eingeführt wurde. Weitere Informationen zur Verwendung von SAS finden Sie unter SAS-Authentifizierung (Shared Access Signature) mit Service Bus.
Ereignisconsumer
Eine Entität, die Ereignisdaten von einem Event Hub liest, ist ein Ereignisconsumer. Alle Event Hubs-Consumer stellen über eine AMQP 1.0-Sitzung eine Verbindung her und Ereignisse werden über die Sitzung übermittelt, sobald sie verfügbar sind. Der Client muss die Verfügbarkeit der Daten nicht abfragen.
Verbrauchergruppen
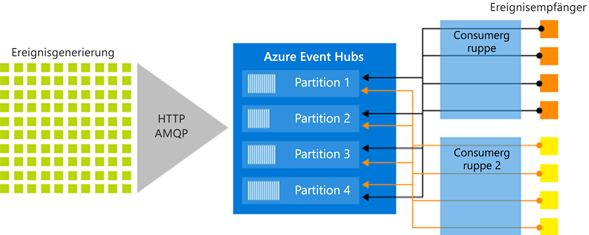
Der Veröffentlichen-/Abonnieren-Mechanismus von Event Hubs erfolgt durch Consumergruppen. Eine Consumergruppe ist eine logische Gruppierung von Consumern, die Daten aus einem Event Hub- oder Kafka-Thema lesen. Sie ermöglicht es mehreren verarbeitenden Anwendungen, die gleichen Streamingdaten in einem Event Hub unabhängig in ihrem eigenen Tempo mit ihren Offsets zu lesen. Sie ermöglicht es Ihnen, den Verbrauch von Nachrichten zu parallelisieren und die Workload auf mehrere Consumer zu verteilen, wobei die Reihenfolge der Nachrichten in jeder Partition beibehalten wird.
Es wird empfohlen, dass nur ein aktiver Empfänger auf einer Partition innerhalb einer Consumergruppe vorhanden ist. In bestimmten Szenarien können Sie jedoch bis zu fünf Consumer oder Empfänger pro Partition verwenden, bei denen alle Empfänger alle Ereignisse der Partition empfangen. Wenn Sie für die gleiche Partition über mehrere Leser verfügen, verarbeiten Sie doppelte Ereignisse. Sie müssen sie in Ihrem Code behandeln, was nicht trivial ist. In einigen Szenarien ist dies jedoch ein gültiger Ansatz.
In einer Streamverarbeitungsarchitektur entspricht jede Downstreamanwendung einer Consumergruppe. Wenn Sie Ereignisdaten in den langfristigen Speicher schreiben möchten, ist die entsprechende Speicherschreibanwendung eine Consumergruppe. Komplexe Ereignisverarbeitung kann von einer anderen separaten Consumergruppe ausgeführt werden. Sie können auf Partitionen nur über eine Consumergruppe zugreifen. In einem Event Hub gibt es immer eine Standardconsumergruppe, und Sie können eine von Ihrem Tarif abhängige maximale Anzahl an Consumergruppen erstellen.
Bei einigen Clients der Azure SDKs handelt es sich um intelligente Consumer-Agents, die im Detail sicherstellen, dass jede Partition über einen einzelnen Reader verfügt und dass alle Partitionen eines Event Hubs ausgelesen werden. Ihr Code muss daher nur noch die aus dem Event Hub gelesenen Ereignisse verarbeiten und kann viele Details der Partitionen ignorieren. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit einer Partition.
Nachstehend finden Sie einige Beispiele für die URI-Konvention für Consumergruppen:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
Die folgende Abbildung zeigt die Datenstromverarbeitungsarchitektur von Event Hubs:
Streamoffsets
Ein Offset ist die Position eines Ereignisses innerhalb einer Partition. Sie können sich einen Offset als einen clientseitigen Zeiger vorstellen. Der Offset ist eine Nummerierung des Ereignisses in Byte. Dieser Offset ermöglicht es Ereignisconsumern (Lesern), einen Punkt im Ereignisstream anzugeben, ab dem Ereignisse gelesen werden sollen. Sie können den Offset als Zeitstempel oder als Offsetwert angeben. Es liegt in der Verantwortung jedes Consumers, seine eigenen Offsetwerte außerhalb des Event Hubs-Diensts zu speichern. Innerhalb einer Partition enthält jedes Ereignis einen Offset.

Setzen von Prüfpunkten
Setzen von Prüfpunkten ist ein Vorgang, bei dem Leser ihre Position innerhalb einer Partitionsereignissequenz markieren oder bestätigen. Dies liegt in der Verantwortung des Consumers und erfolgt auf Partitionsbasis innerhalb einer Consumergruppe. Das bedeutet, dass jeder Partitionsleser für jede Consumergruppe seine aktuelle Position im Ereignisstream nachverfolgen muss und den Dienst informieren kann, wenn er den Datenstrom als abgeschlossen betrachtet.
Wenn ein Leser die Verbindung zu eine Partition trennt, beginnt nach dem erneuten Herstellen der Verbindung das Lesen bei dem Prüfpunkt, der zuvor durch den letzten Leser dieser Partition in dieser Consumergruppe übermittelt wurde. Wenn der Leser verbunden ist, übergibt er diesen Offset an den Event Hub, um die Position für den nächsten Lesevorgang anzugeben. Auf diese Weise können mithilfe von Prüfpunkten Ereignisse von Downstreamanwendungen als abgeschlossen markiert werden. Darüber hinaus sorgen Prüfpunkte für Resilienz bei einem Failover zwischen Lesern, die auf unterschiedlichen Computern ausgeführt werden. Sie können ältere Daten zurückgeben, indem Sie einen niedrigeren Offset aus diesem Prüfpunktprozess angeben. Durch diesen Mechanismus ermöglicht das Setzen von Prüfpunkten Failoverstabilität und eine erneute Wiedergabe des Ereignisstreams.
Wichtig
Offsets werden vom Event Hubs-Dienst bereitgestellt. Es liegt in der Verantwortung des Consumers, einen Prüfpunkt zu erstellen, wenn Ereignisse verarbeitet werden.
Befolgen Sie diese Empfehlungen, wenn Sie Azure Blob Storage als Prüfpunktspeicher verwenden:
- Verwenden Sie einen separaten Container für jede Consumergruppe. Sie können dasselbe Speicherkonto verwenden, aber verwenden Sie für jede Gruppe einen eigenen Container.
- Verwenden Sie weder den Container noch das Speicherkonto für andere Zwecke.
- Das Speicherkonto sollte sich in derselben Region befinden, in der sich die bereitgestellte Anwendung befindet. Wenn die Anwendung lokal ist, versuchen Sie, die nächstgelegene Region auszuwählen.
Stellen Sie auf der Seite Speicherkonto im Azure-Portal im Abschnitt Blobdienst sicher, dass die folgenden Einstellungen deaktiviert sind.
- Hierarchischer Namespace
- Vorläufiges Löschen von Blobs
- Versionsverwaltung
Protokollkomprimierung
Azure Event Hubs unterstützt das Komprimieren des Ereignisprotokolls, um die neuesten Ereignisse eines bestimmten Ereignisschlüssels beizubehalten. Mit komprimierten Event Hubs-/Kafka-Themen können Sie schlüsselbasierte Aufbewahrung anstelle der gröberen zeitbasierten Aufbewahrung verwenden.
Weitere Informationen zur Protokollkomprimierung finden Sie unter Protokollkomprimierung.
Allgemeine Consumeraufgaben
Alle Event Hubs-Consumer stellen eine Verbindung über eine AMQP 1.0-Sitzung (statusaktivierter bidirektionaler Kommunikationskanal) her. Jede Partition weist eine AMQP 1.0-Sitzung auf, die den Transport von Ereignissen nach Partition getrennt ermöglicht.
Herstellen einer Verbindung mit einer Partition
Bei der Verbindungsherstellung zu Partitionen erfolgt die Koordination von Readerverbindungen zu bestimmten Partitionen oft mithilfe eines Leasingmechanismus. Auf diese Weise ist es möglich, dass jede Partition in einer Consumergruppe nur über einen aktiven Reader verfügt. Wenn Sie die Clients in den Event Hubs-SDKs verwenden, erleichtern Sie sich das Leasing und die Verwaltung von Readern sowie das Setzen von Prüfpunkten für diese, denn diese Clients verhalten sich wie intelligente Consumer-Agents. Es sind:
- EventProcessorClient für .NET
- EventProcessorClient für Java
- EventHubConsumerClient für Python
- EventHubConsumerClient für JavaScript/TypeScript
Lesen von Ereignissen
Nachdem eine AMQP 1.0-Sitzung und ein Link für eine bestimmte Partition geöffnet wurde, werden Ereignisse vom Event Hubs-Dienst an den AMQP 1.0-Client übergeben. Dieser Mechanismus ermöglicht einen höheren Durchsatz und eine niedrigere Latenz als Pull-basierte Mechanismen wie z. B. HTTP GET. Wenn Ereignisse an den Client gesendet werden, enthält jede Ereignisdateninstanz wichtige Metadaten wie z. B. den Offset und die Sequenznummer, die zur Vereinfachung des Setzens von Prüfpunkten in der Ereignissequenz verwendet werden.
Ereignisdaten:
- Offset
- Sequenznummer
- Body
- Benutzereigenschaften
- Systemeigenschaften
Die Verwaltung des Offsets liegt in Ihrer Verantwortung.
Anwendungsgruppen
Eine Anwendungsgruppe ist eine Sammlung von Clientanwendungen, die mit einer eindeutigen Identifizierung bedingung wie dem Sicherheitskontext eine Verbindung mit einem Event Hubs-Namespace herstellen. Beim Sicherheitskontext handelt es sich z. B. um eine SAS-Richtlinie oder eine Microsoft Entra Anwendungs-ID.
Azure Event Hubs ermöglicht es Ihnen, Ressourcenzugriffsrichtlinien wie z. B. Einschränkungsrichtlinien für eine bestimmte Anwendungsgruppe zu definieren und Ereignisstreaming, d. h. Veröffentlichung oder Nutzung, zwischen Clientanwendungen und Event Hubs zu steuern.
Weitere Informationen finden Sie unter Ressourcengovernance für Clientanwendungen mit Anwendungsgruppen.
Apache Kafka-Unterstützung
Die Protokollunterstützung für Apache Kafka-Clients (Versionen >=1.0) stellt Endpunkte bereit, mit denen vorhandene Kafka-Anwendungen Event Hubs verwenden können. Die meisten vorhandenen Kafka-Anwendungen können leicht neu konfiguriert werden, damit sie nicht auf den Bootstrapserver eines Kafka-Clusters verweisen, sondern auf einen s-Namespace.
Aus Sicht der Kosten, des Betriebsaufwands und der Zuverlässigkeit ist Azure Event Hubs eine hervorragende Alternative zur Bereitstellung und zum Betrieb Ihrer eigenen Kafka- und Zookeeper-Cluster sowie zu Kafka-as-a-Service-Angeboten, die nicht standardmäßig in Azure integriert sind.
Sie erhalten nicht nur Zugang zu derselben Kernfunktionalität wie beim Apache Kafka-Broker, sondern auch zu den folgenden Azure Event Hub-Features: Automatische Batchverarbeitung und Archivierung über Event Hubs Capture, automatische Skalierung und automatischer Ausgleich, Notfallwiederherstellung, Unterstützung kostenneutraler Verfügbarkeitszonen, flexible und sichere Netzwerkintegration und Unterstützung mehrerer Protokolle, z. B. des firewallfreundlichen AMQP-over-WebSockets-Protokolls.
Nächste Schritte
Weitere Informationen zu Event Hubs erhalten Sie unter den folgenden Links:
- Erste Schritte mit Event Hubs