Erstellen von Apache Spark-Anwendungen für HDInsight-Cluster mit dem Azure-Toolkit für Eclipse
Verwenden Sie die HDInsight-Tools im Azure-Toolkit für Eclipse, um in Scala geschriebene Apache Spark-Anwendungen zu entwickeln und diese direkt aus der Eclipse-IDE an einen Azure HDInsight Spark-Cluster zu senden. Sie können das HDInsight-Tools-Plug-In auf verschiedene Weise verwenden:
- Zum Entwickeln und Übermitteln einer Scala Spark-Anwendung an einen HDInsight Spark-Cluster
- Zum Zugreifen auf Ihre Azure HDInsight Spark-Clusterressourcen
- Zum Entwickeln und lokalen Ausführen einer Scala Spark-Anwendung
Voraussetzungen
Apache Spark-Cluster in HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Eclipse-IDE. In diesem Artikel wird die Eclipse-IDE für Java-Entwickler verwendet.
Installieren der erforderlichen Plug-Ins
Installieren des Azure-Toolkits für Eclipse
Installationsanweisungen finden Sie unter Installieren des Azure-Toolkits für Eclipse.
Installieren des Scala-Plug-Ins
Wenn Sie Eclipse öffnen, erkennen die HDInsight Tools automatisch, ob das Scala-Plug-In installiert ist. Klicken Sie auf OK um fortzufahren, und folgen Sie dann den Anweisungen zum Installieren des Plug-Ins vom Eclipse-Marketplace. Führen Sie nach dem Abschluss der Installation einen Neustart des Computers durch.

Plug-Ins bestätigen
Navigieren Sie zu Hilfe>Eclipse Marketplace... .
Wählen Sie die Registerkarte Installiert aus.
Es sollte mindestens Folgendes angezeigt werden:
- Azure-Toolkit für Eclipse<-Version>.
- Scala-IDE<-Version>.
Melden Sie sich bei Ihrem Azure-Abonnement an.
Starten Sie die Eclipse-IDE.
Navigieren Sie zu Fenster>Ansicht anzeigen>Sonstige...>Anmelden.. .
Navigieren Sie im Dialogfeld Ansicht anzeigen zu Azure>Azure Explorer, und wählen Sie dann Öffnen aus.

Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Knoten Azure, und wählen Sie dann Anmelden aus.
Wählen Sie im Dialogfeld Azure-Anmeldung die Authentifizierungsmethode aus, klicken Sie auf Anmelden, und schließen Sie den Anmeldevorgang ab.
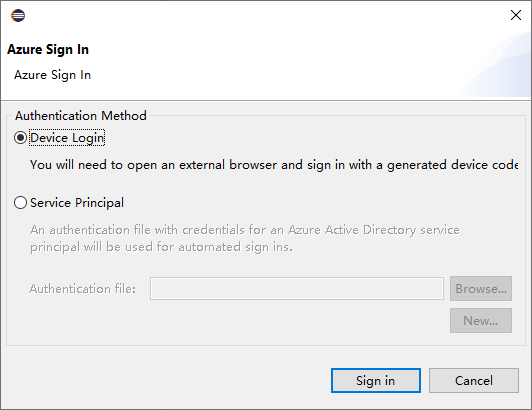
Nachdem Sie sich angemeldet haben, werden im Dialogfeld Ihre Abonnements alle Azure-Abonnements aufgelistet, die den Anmeldeinformationen zugeordnet sind. Wählen Sie im Dialogfeld Auswählen aus, um es zu schließen.
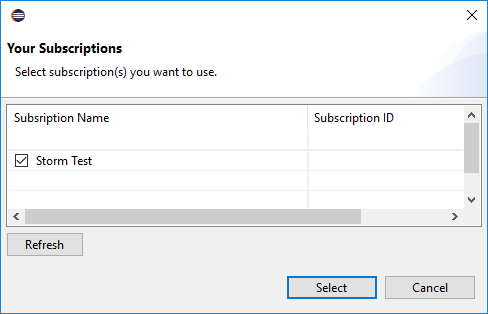
Navigieren Sie im Azure Explorer zu Azure>HDInsight, um die HDInsight Spark-Cluster in Ihrem Abonnement anzuzeigen.
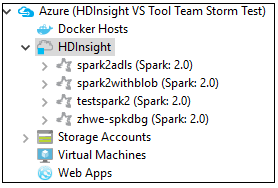
Sie können einen Clusternamenknoten noch einmal erweitern, um die dem Cluster zugeordneten Ressourcen (z.B. Speicherkonten) anzuzeigen.
Verknüpfen eines Clusters
Sie können einen normalen Cluster mithilfe des verwalteten Ambari-Benutzernamens verknüpfen. In ähnlicher Weise können Sie einen in eine Domäne eingebundenen HDInsight-Cluster unter Verwendung von Domäne und Benutzername verknüpfen, wie etwa user1@contoso.com.
Klicken Sie im Azure Explorer mit der rechten Maustaste auf HDInsight, und wählen Sie Cluster verknüpfen aus.
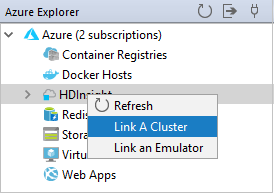
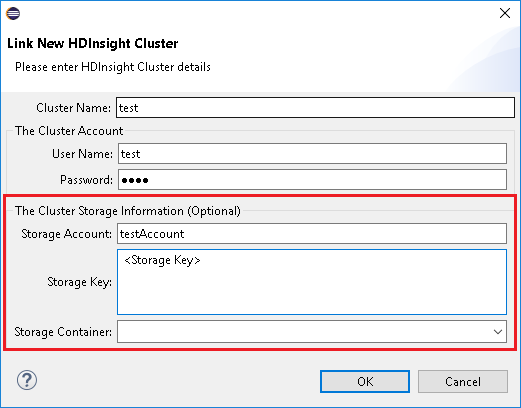
Geben Sie Clustername, Benutzername und Kennwort ein, und wählen Sie dann OK aus. Geben Sie optional das Speicherkonto und den Speicherschlüssel ein, und wählen Sie anschließend den Speichercontainer aus, damit der Speicher-Explorer in der linken Strukturansicht funktioniert.
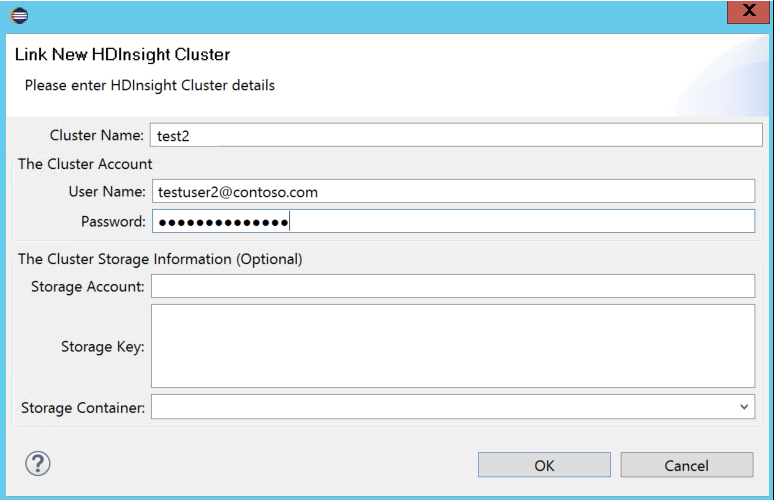
Hinweis
Wir verwenden den verknüpften Speicherschlüssel, den Benutzernamen und das Kennwort, wenn der Cluster im Azure-Abonnement angemeldet ist und einen Cluster verknüpft hat.
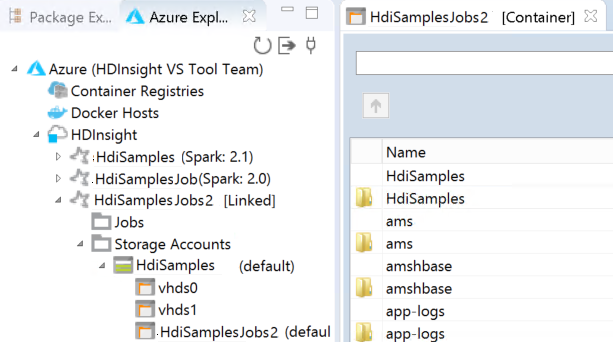
Wenn Speicherschlüssel den aktuellen Fokus besitzt, müssen Benutzer, die nur die Tastatur verwenden, STRG+TAB verwenden, um den Fokus in das nächste Feld im Dialogfeld zu verschieben.
Der verknüpfte Cluster wird unter HDInsight angezeigt. Jetzt können Sie eine Anwendung an diesen verknüpften Cluster übermitteln.
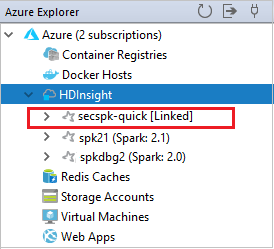
Sie können die Verknüpfung eines Clusters im Azure-Explorer auch aufheben.
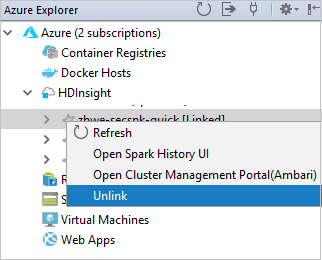
Einrichten eines Spark Scala-Projekts für einen HDInsight Spark-Cluster
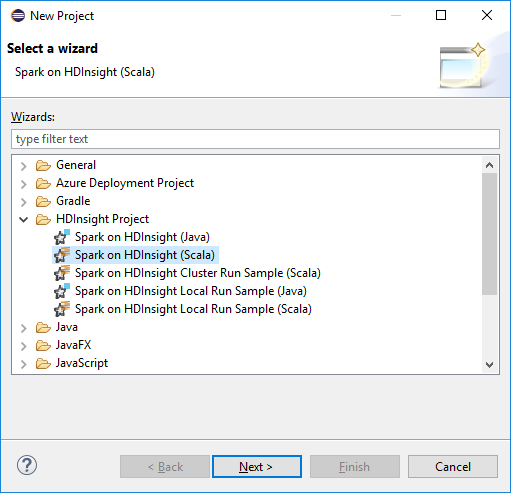
Wählen Sie im Arbeitsbereich der Eclipse-IDE Datei>Neu>Projekt... aus.
Wählen Sie im Assistenten Neues ProjektHDInsight-Projekt>Spark auf HDInsight (Scala) aus. Wählen Sie Weiteraus.
Geben Sie im Dialogfeld New HDInsight Scala Project (Neues HDInsight Scala-Projekt) die folgenden Werte an, und klicken Sie dann auf Next (Weiter):
- Geben Sie einen Namen für das Projekt ein.
- Achten Sie darauf, dass im Bereich JRE für Ausführungsumgebungs-JRE verwenden die Option JavaSE-1.7 oder höher festgelegt ist.
- Im Bereich Spark-Bibliothek können Sie die Option Spark-SDK mit Maven konfigurieren auswählen. Unser Tool integriert die richtige Version für das Spark-SDK und das Scala-SDK. Sie können auch die Option Spark-SDK manuell hinzufügen auswählen, um das Spark-SDK manuell herunterzuladen und hinzuzufügen.

Überprüfen Sie im nächsten Dialogfeld die Details, und wählen Sie dann Fertigstellen aus.
Erstellen einer Scala-Anwendung für einen HDInsight Spark-Cluster
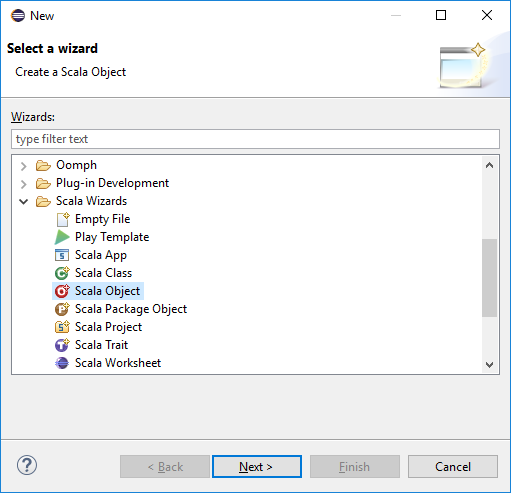
Erweitern Sie im Paket-Explorer das zuvor erstellte Projekt. Klicken Sie mit der rechten Maustaste auf src, und wählen Sie Neu>Sonstiges... aus.
Wählen Sie im Dialogfeld Auswählen eines AssistentenScala-Assistenten>Scala-Objekt aus. Wählen Sie Weiteraus.
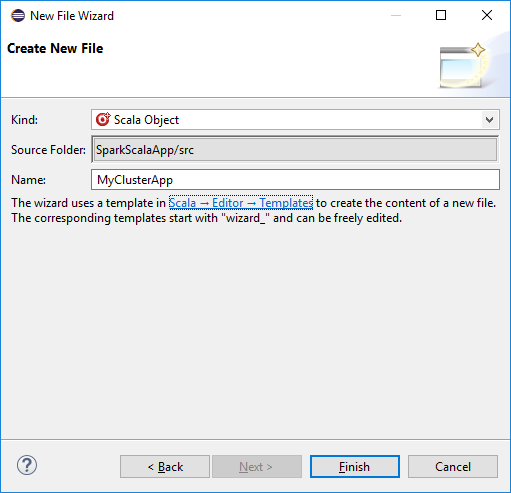
Geben Sie im Dialogfeld Create New File (Neue Datei erstellen) einen Namen für das Objekt ein, und klicken Sie dann auf Finish (Fertig stellen). Ein Text-Editor wird geöffnet.
Ersetzen Sie den aktuellen Inhalt im Text-Editor durch den Code unten:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Führen Sie die Anwendung in einem HDInsight Spark-Cluster aus:
a. Klicken Sie im Paket-Explorer mit der rechten Maustaste auf den Projektnamen, und wählen Sie dann Submit Spark Application to HDInsight (Spark-Anwendung an HDInsight senden) aus.
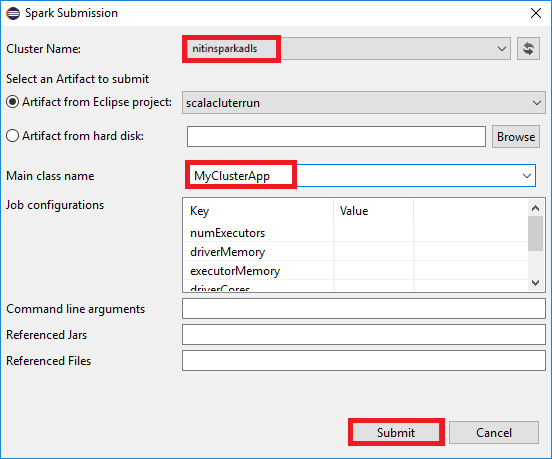
b. Geben Sie im Dialogfeld Spark Submission (Spark-Übermittlung) die folgenden Werte ein, und wählen Sie dann Submit (Übermitteln) aus:
Wählen Sie für Cluster Nameden HDInsight Spark-Cluster aus, auf dem Sie Ihre Anwendung ausführen möchten.
Wählen Sie ein Artefakt aus dem Eclipse-Projekt oder von der Festplatte aus. Der Standardwert hängt von dem Element ab, auf das Sie im Paket-Explorer mit der rechten Maustaste klicken.
In der Dropdownliste Main class name (Hauptklassenname) zeigt der Übermittlungs-Assistent alle Objektnamen aus Ihrem Projekt an. Wählen Sie ein Objekt aus, oder geben Sie den Namen des Objekts ein, das Sie ausführen möchten. Wenn Sie ein Artefakt von einer Festplatte ausgewählt haben, müssen Sie den Namen der Hauptklasse manuell eingeben.
Da der Anwendungscode in diesem Beispiel keine Befehlszeilenargumente oder Referenzdateien (z. B. JAR) erfordert, können Sie die restlichen Textfelder leer lassen.
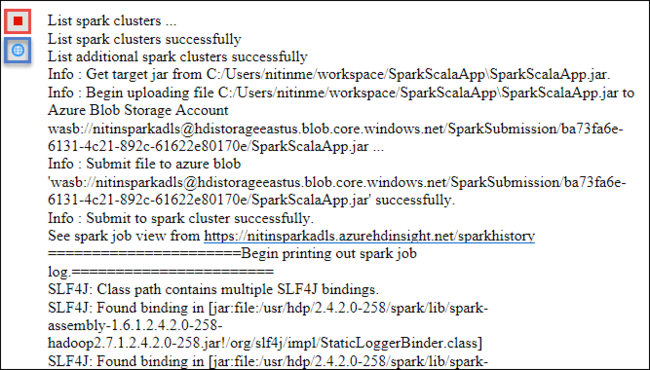
Auf der Registerkarte Spark Submission sollte nun der Fortschritt angezeigt werden. Sie können die Anwendung anhalten, indem Sie im Fenster Spark Submission (Spark-Übermittlung) auf die rote Schaltfläche klicken. Sie können auch die Protokolle für die Anwendungsausführung anzeigen, indem Sie auf das Globussymbol klicken (in der Abbildung gekennzeichnet durch das blaue Feld).
Zugreifen auf und Verwalten von HDInsight Spark-Clustern mithilfe der HDInsight-Tools im Azure-Toolkit für Eclipse
Sie können mithilfe der HDInsight-Tools verschiedene Vorgänge durchführen, z.B. auf die Auftragsausgabe zugreifen.
Zugreifen auf die Auftragsansicht
Erweitern Sie im Azure Explorer die Option HDInsight, den Namen des Spark-Clusters, und wählen Sie dann Aufträge aus.
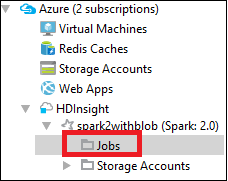
Wählen Sie den Knoten Jobs (Aufträge) aus. Wenn die Java-Version niedriger als 1.8 ist, erinnern Sie HDInsight Tools automatisch daran, das E(fx)clipse-Plug-In zu installieren. Klicken Sie auf OK, um fortzufahren, befolgen Sie dann die Anweisungen des Assistenten zum Installieren über den Eclipse Marketplace, und starten Sie Eclipse neu.
Öffnen Sie in der Auftragsansicht den Knoten Jobs (Aufträge). Im rechten Bereich werden auf der Registerkarte Spark Job View (Spark-Auftragsansicht) alle Anwendungen angezeigt, die in dem Cluster ausgeführt wurden. Wählen Sie den Namen der Anwendung aus, zu der Sie weitere Details anzeigen möchten.

Sie können dann eine der folgenden Aktionen ausführen:
Zeigen Sie auf den Auftragsgraphen. Dadurch werden grundlegende Informationen zum ausgeführten Auftrag angezeigt. Wenn Sie den Auftragsgraphen auswählen, werden die Phasen und die von den einzelnen Aufträgen generierten Informationen angezeigt.
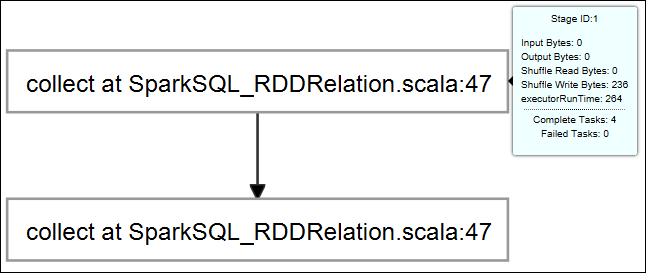
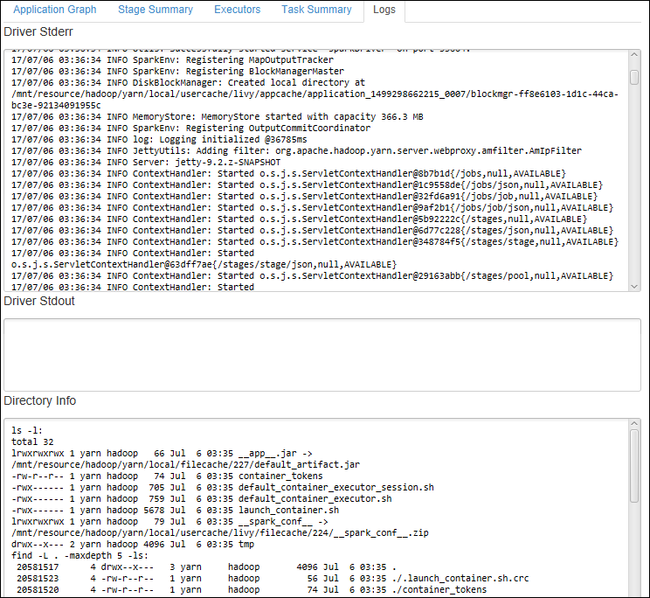
Klicken Sie auf die Registerkarte Log (Protokoll), um häufig verwendete Protokolle anzuzeigen, z. B. Driver Stderr, Driver Stdout und Directory Info.
Öffnen Sie die Spark-Verlaufsbenutzeroberfläche und die Apache Hadoop YARN-Benutzeroberfläche (auf Anwendungsebene), indem Sie auf die Links im oberen Bereich des Fensters klicken.
Zugreifen auf den Speichercontainer des Clusters
Erweitern Sie im Azure Explorer den Stammknoten HDInsight, um eine Liste der verfügbaren HDInsight Spark-Cluster anzuzeigen.
Erweitern Sie den Namen des Clusters, um das Speicherkonto und den Standardspeichercontainer des Clusters anzuzeigen.
Wählen Sie den Namen des Speichercontainers aus, der dem Cluster zugeordnet ist. Doppelklicken Sie im rechten Bereich auf den Ordner HVACOut. Öffnen Sie eine der part-Dateien, um die Ausgabe der Anwendung anzuzeigen.
Zugreifen auf den Spark-Verlaufsserver
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Namen Ihres Spark-Clusters, und wählen Sie dann Open Spark History UI (Spark-Verlaufsbenutzeroberfläche öffnen) aus. Geben Sie die Anmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden. Diese Anmeldeinformationen haben Sie bei der Bereitstellung des Clusters angegeben.
Im Dashboard des Spark-Verlaufsservers können Sie die Anwendung, deren Ausführung Sie gerade beendet haben, anhand des Anwendungsnamens suchen. Im obigen Code legen Sie den Namen der Anwendung mit
val conf = new SparkConf().setAppName("MyClusterApp")fest. Daher lautete der Name Ihrer Spark-Anwendung MyClusterApp.
Starten des Apache Ambari-Portals
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Namen Ihres Spark-Clusters, und wählen Sie dann Open Cluster Management Portal (Ambari) (Clusterverwaltungsportal [Ambari] öffnen) aus.
Geben Sie die Anmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden. Diese Anmeldeinformationen haben Sie bei der Bereitstellung des Clusters angegeben.
Verwalten von Azure-Abonnements
Standardmäßig führen HDInsight Tools im Azure-Toolkit für Eclipse die Spark-Cluster in all Ihren Azure-Abonnements auf. Bei Bedarf können Sie die Abonnements angeben, für die Sie auf den Cluster zugreifen möchten.
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Hauptknoten Azure, und wählen Sie dann Abonnements verwalten aus.
Deaktivieren Sie im Dialogfeld die Kontrollkästchen für die Abonnements, auf die Sie nicht zugreifen möchten, und klicken Sie dann auf Close (Schließen). Sie können auch Abmelden auswählen, wenn Sie sich von Ihrem Azure-Abonnement abmelden möchten.
Lokales Ausführen einer Spark Scala-Anwendung
Mithilfe der HDInsight-Tools-im Azure-Toolkit für Eclipse können Sie Spark Scala-Anwendungen lokal auf Ihrer Arbeitsstation ausführen. In der Regel müssen solche Anwendungen nicht auf Clusterressourcen wie den Speichercontainer zugreifen und können lokal ausgeführt und getestet werden.
Voraussetzung
Beim Ausführen der lokalen Spark Scala-Anwendung auf einem Windows-Computer wird unter Umständen eine Ausnahme wie unter SPARK-2356 beschrieben ausgelöst. Diese Ausnahme tritt auf, weil WinUtils.exe in Windows fehlt.
Um diesen Fehler zu beheben, müssen Sie Winutils.exe herunterladen und an einem Speicherort wie C:\WinUtils\bin ablegen. Fügen Sie dann die Umgebungsvariable HADOOP_HOME hinzu, und legen Sie den Wert der Variable auf C\WinUtils fest.
Ausführen einer lokalen Spark Scala-Anwendung
Starten Sie Eclipse, und erstellen Sie ein Projekt. Nehmen Sie im Dialogfeld New Project (Neues Projekt) die folgenden Einstellungen vor, und klicken Sie anschließend auf Next (Weiter).
Wählen Sie im Assistenten Neues ProjektHDInsight-Projekt>Spark auf HDInsight – Beispiel für lokale Ausführung (Scala) aus. Wählen Sie Weiteraus.

Um die Projektdetails anzugeben, führen Sie die Schritte 3 bis 6 wie oben im Abschnitt Einrichten eines Spark Scala-Projekts für einen HDInsight Spark-Cluster gezeigt durch.
Die Vorlage fügt einen Beispielcode (LogQuery) unter dem Ordner src hinzu, der lokal auf Ihrem Computer ausgeführt werden kann.
Klicken Sie mit der rechten Maustaste auf logquery.scala, und wählen Sie Ausführen als>1 Scala-Anwendung aus. Auf der Registerkarte Console (Konsole) wird eine Ausgabe der folgenden Art angezeigt:
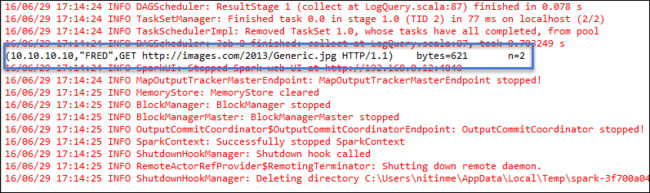
Rolle nur mit Leseberechtigung
Wenn Benutzer, die über eine Rolle nur mit Leseberechtigung verfügen, einen Auftrag an einen Cluster übermitteln, sind Ambari-Anmeldeinformationen erforderlich.
Kontextmenü zum Verknüpfen eines Clusters
Melden Sie sich mit einem Konto an, das über eine Rolle nur mit Leseberechtigung verfügt.
Erweitern Sie im Azure Explorer die Option HDInsight, um die HDInsight-Cluster anzuzeigen, die sich in Ihrem Abonnement befinden. Cluster mit der Kennzeichnung "Role: Reader" verfügen über eine Rolle nur mit Leseberechtigung.

Klicken Sie mit der rechten Maustaste auf den Cluster, der über eine Rolle nur mit Leseberechtigung verfügt. Wählen Sie aus dem Kontextmenü den Eintrag Link this cluster (Diesen Cluster verknüpfen) aus, um den Cluster zu verknüpfen. Geben Sie den Benutzernamen und das Kennwort für Ambari ein.
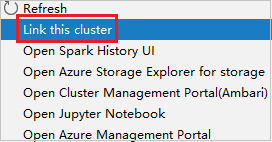
Wenn der Cluster erfolgreich verknüpft wurde, wird HDInsight aktualisiert. Der Status des Clusters ändert sich zu „Linked“ (Verknüpft).
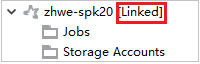
Verknüpfen eines Clusters durch Erweitern des Knotens „Jobs“ (Aufträge)
Klicken Sie auf den Knoten Jobs (Aufträge). Das Fenster Cluster Job Access Denied (Zugriff auf Clusterauftrag verweigert) wird angezeigt.
Klicken Sie auf Link this cluster (Diesen Cluster verknüpfen), um den Cluster zu verknüpfen.

Verknüpfen des Clusters aus dem Fenster für die Spark-Übermittlung
Erstellen Sie ein HDInsight-Projekt.
Klicken Sie mit der rechten Maustaste auf das Paket. Wählen Sie dann Submit Spark Application to HDInsight (Spark-Anwendung an HDInsight senden) aus.
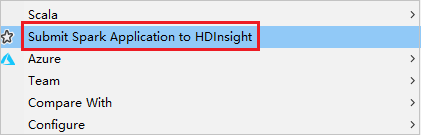
Wählen Sie einen Cluster aus, der über eine Rolle nur mit Leseberechtigung für Clustername verfügt. Es wird eine Warnmeldung angezeigt. Sie können auf Link this cluster (Diesen Cluster verknüpfen) klicken, um den Cluster zu verknüpfen.
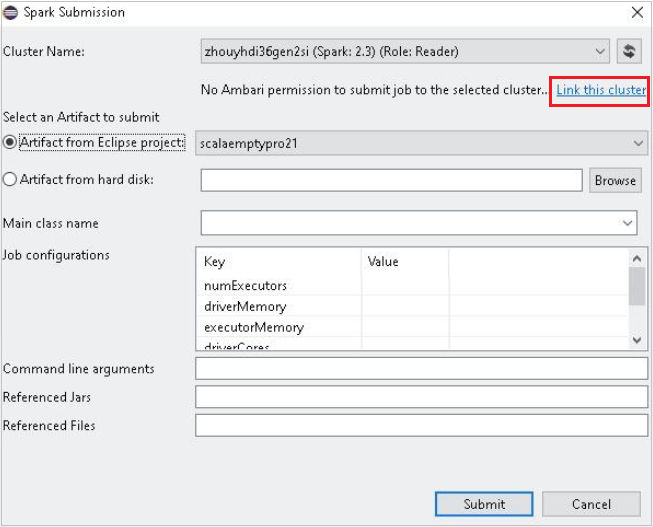
Anzeigen von Speicherkonten
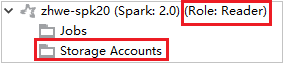
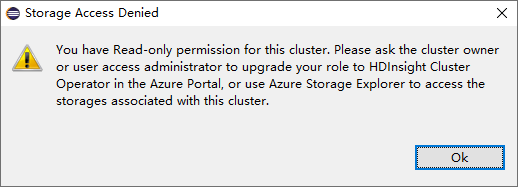
Klicken Sie in einem Cluster, der über eine Rolle nur mit Leseberechtigung verfügt, auf den Knoten Storage Accounts (Speicherkonten). Das Fenster Storage Access Denied (Zugriff auf Speicher verweigert) wird angezeigt.
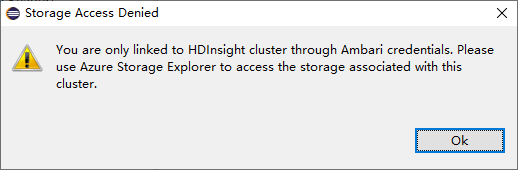
Klicken Sie in einem verknüpften Cluster auf den Knoten Storage Accounts (Speicherkonten). Das Fenster Storage Access Denied (Zugriff auf Speicher verweigert) wird angezeigt.
Bekannte Probleme
Beim Verwenden von Cluster verknüpfen empfehle ich, die Anmeldeinformationen des Speichers anzugeben.
Es gibt zwei Modi zum Übermitteln der Aufträge. Wenn Speicheranmeldeinformationen bereitgestellt werden, wird der Auftrag im Batchmodus übermittelt. Andernfalls wird der interaktive Modus verwendet. Wenn der Cluster ausgelastet ist, erhalten Sie möglicherweise die folgende Fehlermeldung.


Weitere Informationen
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Verwenden des Azure-Toolkits für IntelliJ zum Erstellen und Übermitteln von Spark Scala-Anwendungen
- Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über VPN
- Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über SSH
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Kernel für Jupyter Notebook in Apache Spark-Clustern für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)