Tutorial: Hochladen, Zugreifen auf und Erkunden von Daten in Azure Machine Learning
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
In diesem Tutorial lernen Sie Folgendes:
- Hochladen Ihrer Daten in Cloudspeicher
- Erstellen einer Azure Machine Learning-Datenressource
- Zugreifen auf Ihre Daten in einem Notebook für die interaktive Entwicklung
- Erstellen neuer Versionen von Datenressourcen
Am Anfang eines Machine Learning-Projekts stehen in der Regel die explorative Datenanalyse (EDA), die Datenvorverarbeitung (Bereinigung, Feature Engineering) und die Erstellung von Machine Learning-Modellprototypen zur Validierung von Hypothesen. Die Projektphase der Prototypenentwicklung zeichnet sich durch eine hohe Interaktivität aus. Sie bietet sich für die Entwicklung in einer IDE oder einem Jupyter-Notebook mit interaktiver Python-Konsole an. Diese Ideen werden im vorliegenden Tutorial beschrieben.
Dieses Video zeigt Ihnen, wie Sie mit Azure Machine Learning Studio loslegen, um den Schritten des Tutorials folgen zu können. Das Video zeigt, wie Sie ein Notebook erstellen, das Notebook klonen, eine Computeinstanz erstellen und die für das Tutorial erforderlichen Daten herunterladen. Die Schritte sind in den folgenden Abschnitten beschrieben.
Voraussetzungen
-
Um Azure Machine Learning verwenden zu können, benötigen Sie zuerst einen Arbeitsbereich. Wenn Sie noch keinen haben, schließen Sie Erstellen von Ressourcen, die Sie für die ersten Schritte benötigen ab, um einen Arbeitsbereich zu erstellen, und mehr über dessen Verwendung zu erfahren.
-
Melden Sie sich bei Studio an, und wählen Sie Ihren Arbeitsbereich aus, falls dieser noch nicht geöffnet ist.
-
Öffnen oder erstellen Sie ein neues Notebook in Ihrem Arbeitsbereich:
- Erstellen Sie ein neues Notebook, wenn Sie Code in Zellen kopieren/einfügen möchten.
- Alternativ öffnen Sie im Abschnitt Beispiele von Studio die Datei tutorials/get-started-notebooks/explore-data.ipynb. Wählen Sie dann Klonen aus, um das Notebook zu Ihren Dateien hinzuzufügen. (Erfahren Sie, wo Beispiele zu finden sind.)
Festlegen Ihres Kernels
Erstellen Sie auf der oberen Leiste über Ihrem geöffneten Notizbuch eine Compute-Instanz, falls Sie noch keine besitzen.

Wenn die Compute-Instanz beendet wurde, wählen Sie Compute starten aus, und warten Sie, bis sie ausgeführt wird.

Stellen Sie sicher, dass der Kernel rechts oben
Python 3.10 - SDK v2ist. Falls nicht, wählen Sie diesen Kernel in der Dropdownliste aus.
Wenn Sie ein Banner mit dem Hinweis sehen, dass Sie authentifiziert werden müssen, wählen Sie Authentifizieren aus.



Wichtig
Der Rest dieses Tutorials enthält Zellen des Tutorial-Notebooks. Kopieren Sie in Ihr neues Notebook, und fügen Sie es ein, oder wechseln Sie jetzt zum Notebook, falls Sie es geklont haben.
Herunterladen der in diesem Tutorial verwendeten Daten
Für die Datenerfassung verarbeitet Azure Data Explorer Rohdaten in diesen Formaten. Im vorliegenden Tutorial wird dieses Beispiel für Kreditkarten-Kundendaten im CSV-Format verwendet. Wir sehen, wie die Schritte in einer Azure Machine Learning-Ressource ablaufen. In dieser Ressource erstellen wir einen lokalen Ordner mit dem vorgeschlagenen Namen data direkt unter dem Ordner, in dem sich dieses Notebook befindet.
Hinweis
Dieses Tutorial hängt von Daten ab, die in einem Azure Machine Learning-Ressourcenordner gespeichert sind. In diesem Tutorial bezieht sich „lokal“ auf einen Ordner in dieser Azure Machine Learning-Ressource.
Wählen Sie unterhalb der drei Punkte Terminal öffnen aus, wie in dieser Abbildung gezeigt:
Das Terminalfenster wird auf einer neuen Registerkarte geöffnet.
Stellen Sie sicher, dass Sie zu dem Ordner wechseln (
cd), in dem sich dieses Notebook befindet. Wenn sich das Notebook beispielsweise in einem Ordner mit dem Namen get-started-notebooks befindet:cd get-started-notebooks # modify this to the path where your notebook is locatedGeben Sie diese Befehle in das Terminalfenster ein, um die Daten auf Ihre Compute-Instanz zu kopieren:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvSie können das Terminalfenster nun schließen.
Erfahren Sie mehr über diese Daten im UCI Machine Learning-Repository.
Erstellen eines Handles für den Arbeitsbereich
Bevor wir uns genauer mit dem Code befassen, benötigen Sie eine Möglichkeit, um auf Ihren Arbeitsbereich zu verweisen. Sie erstellen „ml_client“ als Handle für den Arbeitsbereich. Anschließend verwenden Sie ml_client zum Verwalten von Ressourcen und Aufträgen.
Geben Sie in der nächsten Zelle Ihre Abonnement-ID, den Namen der Ressourcengruppe und den Namen des Arbeitsbereichs ein. So finden Sie diese Werte:
- Wählen Sie auf der oben rechts angezeigten Azure Machine Learning Studio-Symbolleiste den Namen Ihres Arbeitsbereichs aus.
- Kopieren Sie den Wert für Arbeitsbereich, Ressourcengruppe und Abonnement-ID in den Code.
- Sie müssen einen Wert kopieren, den Bereich schließen und einfügen und den Vorgang dann für den nächsten wiederholen.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Hinweis
Beim Erstellen von MLClient wird keine Verbindung mit dem Arbeitsbereich hergestellt. Die Clientinitialisierung erfolgt verzögert, d. h., es wird abgewartet, bis das erste Mal ein Aufruf erforderlich ist (dies geschieht in der nächsten Codezelle).
Hochladen von Daten in Cloudspeicher
Azure Machine Learning verwendet Uniform Resource Identifiers (URIs), die auf Speicherorte in der Cloud verweisen. Ein URI erleichtert den Zugriff auf Daten in Notebooks und Aufträgen. Daten-URI-Formate ähneln den Web-URLs, die Sie in Ihrem Webbrowser für den Zugriff auf Webseiten verwenden. Beispiel:
- Zugreifen auf Daten vom öffentlichen HTTPS-Server:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Zugreifen auf Daten aus Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Azure Machine Learning-Datenobjekte ähneln Lesezeichen (Favoriten) in Webbrowsern. Anstatt sich lange Speicherpfade (URIs) zu merken, die auf Ihre am häufigsten verwendeten Daten verweisen, können Sie eine Datenressource erstellen und dann mit einem Anzeigenamen auf diese Ressource zugreifen.
Durch Erstellen einer Datenressource erstellen Sie einen Verweis auf den Speicherort der Datenquelle zusammen mit einer Kopie der zugehörigen Metadaten. Da die Daten an ihrem bisherigen Speicherort verbleiben, entstehen Ihnen keine zusätzlichen Speicherkosten, und Sie riskieren nicht die Integrität Ihrer Datenquellen. Sie können Datenobjekte aus Azure Machine Learning-Datenspeichern, Azure Storage, öffentlichen URLs und lokalen Dateien erstellen.
Tipp
Bei kleineren Datenuploads funktioniert die Erstellung von Azure Machine Learning-Datenressourcen gut für Datenuploads von lokalen Computeressourcen in einen Cloudspeicher. Bei diesem Ansatz werden keine zusätzlichen Tools oder Hilfsprogramme benötigt. Für das Hochladen größerer Datenmengen ist jedoch möglicherweise ein dediziertes Tool oder Hilfsprogramm erforderlich, zum Beispiel azcopy. Das Befehlszeilentool azcopy verschiebt Daten in und aus Azure Storage. Hier erfahren Sie mehr über azcopy.
In der nächsten Notebookzelle wird die Datenressource erstellt. Im Codebeispiel wird die unbearbeitete Datendatei in den gewünschten Cloudspeicher hochgeladen.
Bei jeder Erstellung einer Datenressource wird für diese eine eindeutige Version benötigt. Wenn die Version bereits vorhanden ist, erhalten Sie eine Fehlermeldung. In diesem Code verwenden wir „Initial“ für den ersten Lesevorgang der Daten. Wenn diese Version bereits vorhanden ist, überspringen wir das erneute Erstellen.
Sie können den Parameter version auch weglassen. In diesem Fall wird eine Versionsnummer für Sie generiert, die mit 1 beginnt und anschließend inkrementiert wird.
In diesem Tutorial verwenden wir den Namen „initial“ als erste Version. Im Tutorial Erstellen von Produktionspipelines für maschinelles Lernen wird auch diese Version der Daten verwendet. Daher verwenden wir hier einen Wert, den Sie in diesem Tutorial erneut sehen werden.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Sie können die hochgeladenen Daten anzeigen, indem Sie auf der linken Seite die Option Daten auswählen. Sie sehen, dass die Daten hochgeladen wurden und eine Datenressource erstellt wurde:
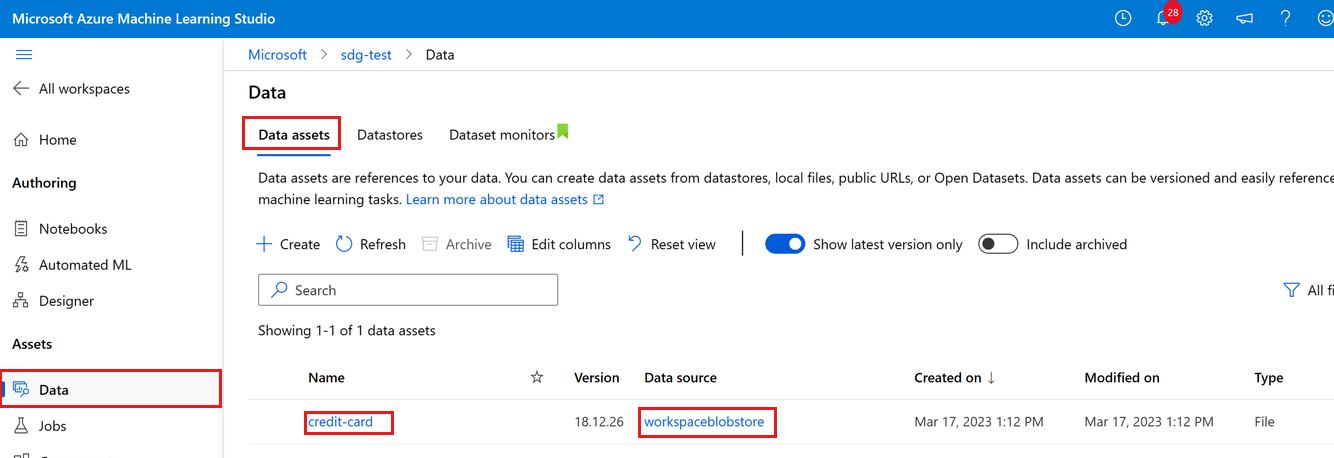
Der Name der Datenressource lautet credit-card, und auf der Registerkarte Datenressourcen wird dieser in der Spalte Name angezeigt. Diese Datenressource wird in den Standarddatenspeicher workspaceblobstore Ihres Arbeitsbereichs hochgeladen, der in der Spalte Datenquelle angezeigt wird.
Ein Azure Machine Learning-Datenspeicher ist ein Verweis auf ein vorhandenes Speicherkonto in Azure. Ein Datenspeicher bietet folgende Vorteile:
- Eine allgemeine und benutzerfreundliche API für die Interaktion mit verschiedenen Speichertypen (Blob/Dateien/Azure Data Lake Storage) und Authentifizierungsmethoden.
- Eine einfache Methode, um bei der Arbeit im Team nützliche Datenspeicher zu ermitteln.
- Eine Möglichkeit zum Verbergen von Verbindungsinformationen für den auf Anmeldeinformationen basierenden Datenzugriff (Dienstprinzipal/SAS/Schlüssel) in Ihren Skripts.
Zugreifen auf Ihre Daten in einem Notebook
Pandas bietet direkte Unterstützung für URIs: Dieses Beispiel zeigt, wie Sie eine CSV-Datei aus einem Azure Machine Learning-Datenspeicher lesen:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Wie bereits erwähnt, kann es jedoch schwierig werden, sich diese URIs zu merken. Außerdem müssen Sie alle Werte der <Teilzeichenfolgen> im Befehl pd.read_csv manuell durch die tatsächlichen Werte für Ihre Ressourcen ersetzen.
Sie sollten Datenressourcen für häufig genutzte Daten erstellen. So können Sie einfacher auf die CSV-Datei in Pandas zugreifen:
Wichtig
Führen Sie diesen Code in einer Notebookzelle aus, um die Python-Bibliothek azureml-fsspec in Ihrem Jupyter-Kernel zu installieren:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Weitere Informationen zum Datenzugriff in einem Notebook finden Sie unter Zugreifen auf Daten aus Azure-Cloudspeicher während der interaktiven Entwicklung.
Erstellen einer neuen Version der Datenressource
Sie haben vielleicht bemerkt, dass die Daten noch etwas bereinigt werden müssen, damit sie für das Training eines Machine Learning-Modells geeignet sind. Es bietet Folgendes:
- Zwei Überschriften
- Eine Client-ID-Spalte; dieses Feature kommt beim maschinellen Lernen nicht zum Einsatz
- Leerzeichen im Namen der Antwortvariablen
Darüber hinaus eignet sich das Parquet-Dateiformat im Vergleich zum CSV-Format besser zum Speichern dieser Daten. Parquet ermöglicht eine Komprimierung und verwaltet ein Schema. Verwenden Sie daher diesen Code, um die Daten zu bereinigen und sie in Parquet zu speichern:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Diese Tabelle zeigt die Struktur der Daten in der ursprünglichen CSV-Datei default_of_credit_card_clients.csv, die in einem vorherigen Schritt heruntergeladen wurde. Die hochgeladenen Daten enthalten 23 erklärende Variablen und 1 Antwortvariable, wie hier gezeigt:
| Spaltenname(n) | Variablentyp | BESCHREIBUNG |
|---|---|---|
| X1 | Erklärend | Höhe des eingeräumten Kreditrahmens (NT-Dollar): Umfasst sowohl den individuellen Verbraucherkredit als auch den (zusätzlichen) Familienkredit. |
| X2 | Erklärend | Geschlecht (1 = männlich; 2 = weiblich). |
| X3 | Erklärend | Schulbildung (1 = Fachhochschule; 2 = Universität; 3 = Abitur; 4 = andere). |
| X4 | Erklärend | Familienstand (1 = verheiratet; 2 = ledig; 3 = andere). |
| X5 | Erklärend | Alter (Jahre). |
| X6-X11 | Erklärend | Verlauf der vergangenen Zahlungen. Wir haben die vergangenen monatlichen Zahlungseingänge (von April bis September 2005) nachverfolgt. -1 = ordnungsgemäße Zahlung; 1 = einmonatiger Zahlungsverzug; 2 = zweimonatiger Zahlungsverzug; ... . ; 8 = achtmonatiger Zahlungsverzug; 9 = neunmonatiger Zahlungsverzug und mehr |
| X12-17 | Erklärend | Rechnungsbetrag (NT-Dollar) von April bis September 2005. |
| X18-23 | Erklärend | Betrag der vorherigen Zahlung (NT-Dollar) von April bis September 2005. |
| J | Antwort | Standardzahlung (Ja = 1, Nein = 0) |
Erstellen Sie als Nächstes eine neue Version der Datenressource (die Daten werden automatisch in den Cloudspeicher hochgeladen). Für diese Version fügen wir einen Zeitwert hinzu, sodass bei jeder Ausführung dieses Codes eine andere Versionsnummer erstellt wird.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Die bereinigte Parquet-Datei ist die neueste Version der Datenquelle. Dieser Code zeigt zuerst das Resultset der CSV-Version und dann die Parquet-Version:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Bereinigen von Ressourcen
Wenn Sie nun mit dem anderen Tutorials fortfahren möchten, springen Sie zu Nächste Schritte.
Beenden der Compute-Instanz
Wenn Sie die Compute-Instanz jetzt nicht verwenden möchten, beenden Sie sie:
- Wählen Sie im Studio im linken Navigationsbereich Compute aus.
- Wählen Sie auf den oberen Registerkarten Compute-Instanzen aus.
- Wählen Sie in der Liste die Compute-Instanz aus.
- Wählen Sie auf der oberen Symbolleiste Beenden aus.
Löschen aller Ressourcen
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Nächste Schritte
Weitere Informationen zu Datenressourcen finden Sie unter Erstellen von Datenressourcen.
Wenn Sie mehr über Datenspeicher erfahren möchten, lesen Sie Erstellen von Datenspeichern.
Fahren Sie mit den Tutorials fort, um zu erfahren, wie Sie ein Trainingsskript entwickeln können.