Kapazitätsplanung für Service Fabric-Anwendungen
In diesem Dokument erfahren Sie, wie Sie die Anzahl der Ressourcen (CPU, Arbeitsspeicher, Datenträgerspeicher) bestimmen, die Sie zum Ausführen von Azure Service Fabric-Anwendungen benötigen. Es ist üblich, dass sich die erforderlichen Ressourcen mit der Zeit ändern. In der Regel brauchen Sie für das Entwickeln und Testen Ihres Diensts ein bestimmtes Maß an Ressourcen, das Sie erhöhen müssen, sobald Sie zur Produktionsumgebung wechseln und die Beliebtheit Ihrer Anwendung zunimmt. Vergegenwärtigen Sie sich beim Entwurf einer Anwendung die langfristigen Anforderungen, und treffen Sie Entscheidungen, die Ihrem Dienst eine Skalierung zum Erfüllen einer hohen Kundennachfrage ermöglichen.
Wenn Sie einen Service Fabric-Cluster erstellen, entscheiden Sie, aus welchen Arten von virtuellen Computern (VMs) der Cluster bestehen soll. Jede VM verfügt über eine begrenzte Menge an Ressourcen in Form von CPUs (Kernen und -Geschwindigkeit), Netzwerkbandbreite, Arbeitsspeicher (RAM) und Datenträgerspeicher. Wenn der Dienst mit der Zeit wächst, können Sie ein Upgrade auf VMs mit mehr Ressourcen vornehmen und/oder Ihrem Cluster weitere VMs hinzufügen. Für den letzteren Schritt müssen Sie Ihren Dienst anfänglich so planen, dass er neue VMs nutzen kann, die dem Cluster dynamisch hinzugefügt werden.
Einige Dienste verwalten wenige oder keine Daten auf den virtuellen Computern. Beim Planen der Kapazität für diese Dienste sollte daher der Schwerpunkt auf der Leistung liegen. Das bedeutet, dass VMs mit den entsprechenden CPUs (Kerne und Geschwindigkeit) gewählt werden müssen. Darüber hinaus müssen Sie die Netzwerkbandbreite prüfen, einschließlich der Häufigkeit von Netzwerkübertragungen sowie der übertragenen Datenmenge. Wenn Ihr Dienst bei steigender Nutzung weiter eine gute Leistung bieten soll, können Sie dem Cluster weitere VMs hinzufügen und unter alle VMs für einen Lastenausgleich der Netzwerkanforderungen sorgen.
Bei Diensten, die sehr große Datenmengen in den VMs verwalten, sollte der Fokus der Kapazitätsplanung auf der Größe liegen. Deshalb müssen Sie die Kapazität des Arbeits- und Datenträgerspeichers des virtuellen Computers sorgfältig prüfen. Das Windows-Verwaltungssystem für virtuellen Arbeitsspeicher sorgt dafür, dass der Anwendungscode Speicherplatz auf dem Datenträger als RAM interpretiert. Darüber hinaus bietet die Service Fabric-Laufzeit eine Smart Paging genannte intelligente Auslagerung, bei der nur aktive Daten im Arbeitsspeicher verbleiben und inaktive Daten auf Datenträger verschoben werden. Anwendungen können dadurch mehr Arbeitsspeicher nutzen, als auf dem virtuellen Computer physisch verfügbar ist. Durch den zusätzlichen RAM wird die Leistung gesteigert, da der virtuelle Computer mehr Datenträgerspeicher im RAM belassen kann. Der virtuelle Computer, den Sie auswählen, muss über einen Datenträger verfügen, der für die vorgesehene Datenmenge groß genug ist. Gleichfalls muss der virtuelle Computer genügend Arbeitsspeicher bieten, um die gewünschte Leistung bereitzustellen. Wenn die Daten Ihres Diensts mit der Zeit anwachsen, können Sie dem Cluster weitere VMs hinzufügen und die Daten auf alle VMs verteilen.
Festlegen der benötigten Anzahl von Knoten
Durch das Partitionieren Ihres Diensts können Sie die Daten für Ihren Dienst aufskalieren. Weitere Informationen zur Partitionierung finden Sie unter Partitionieren von Service Fabric. Jede Partition muss in eine einzige VM passen, doch mehrere (kleine) Partitionen können in einer einzelnen VM platziert werden. Eine große Anzahl kleiner Partitionen bietet Ihnen daher mehr Flexibilität als eine kleine Anzahl größerer Partitionen. Der Nachteil besteht darin, dass viele Partitionen den Verarbeitungsaufwand für Service Fabric erhöhen und Transaktionsvorgänge nicht partitionsübergreifend erfolgen können. Außerdem fällt potenziell mehr Netzwerkdatenverkehr an, wenn Ihr Dienst häufig auf Datenelemente zugreifen muss, die sich in verschiedenen Partitionen befinden. Wenn Sie Ihren Dienst entwerfen, müssen Sie diese Vor- und Nachteile sorgfältig prüfen, um zu einer effektiven Partitionierungsstrategie zu gelangen.
Nehmen wir an, dass Ihre Anwendung über einen einzelnen statusbehafteten Dienst verfügt, dessen Speichergröße in einem Jahr voraussichtlich auf „DB_Size GB“ (Datenbankgröße in GB) anwachsen wird. Sie sind bereit, auch über dieses Jahr hinaus dem Wachstum entsprechend weitere Anwendungen (und Partitionen) hinzuzufügen. Der Replikationsfaktor (RF), der die Anzahl der Replikate für Ihren Dienst bestimmt, wirkt sich auf die gesamte „DB_Size“ aus. Die gesamte „DB_Size“ in allen Replikaten ist der mit DB_Size multiplizierte Replikationsfaktor. „Node_Size“ (Knotengröße) stellt den Datenträgerspeicherplatz/RAM pro Knoten dar, den Sie für Ihren Dienst verwenden möchten. Für eine optimale Leistung sollte „DB_Size“ in den Arbeitsspeicher des gesamten Clusters passen, weshalb Sie eine Knotengröße wählen, die ungefähr der RAM-Kapazität der gewählten VM entspricht. Durch Zuordnen einer „Node_Size“, die die RAM-Kapazität übersteigt, sind Sie auf die von der Service Fabric-Laufzeit gebotene Auslagerung angewiesen. Folglich ist die Leistung möglicherweise nicht optimal, wenn Ihre gesamten Daten als aktiv angesehen werden (da dann die Daten ausgelagert werden und umgekehrt). Doch bei vielen Diensten, bei denen nur ein Bruchteil der Daten aktiv ist, ist dies wirtschaftlicher.
Die Anzahl der Knoten, die für eine maximale Leistung erforderlich ist, kann wie folgt berechnet werden:
Number of Nodes = (DB_Size * RF)/Node_Size
Berücksichtigen von Wachstum
Möglicherweise möchten Sie die Anzahl von Knoten basierend auf der Datenbankgröße „DB_Size“ berechnen, bis zu der Ihr Dienst erwartungsgemäß zusätzlich zur anfänglichen „DB_Size“ wachsen wird. Steigern Sie dann die Anzahl der Knoten mit dem Wachstum Ihres Diensts so, dass Sie sie nicht überdimensionieren. Die Anzahl der Partitionen sollte jedoch auf der Anzahl von Knoten basieren, die bei Ausführung des Diensts bei maximalem Wachstum erforderlich ist.
Es ist ratsam, jederzeit einige zusätzliche VMs vorzuhalten, damit Sie unerwartete Spitzen oder Ausfälle bewältigen können (z.B. wenn einige VMs ausfallen). Grundlage der Berechnung dieser Zusatzkapazität sollten Ihre erwarteten Spitzen sein. Als Ausgangspunkt für die Reservierung einiger zusätzlicher VMs empfiehlt sich ein Wert von 5-10 %.
Im vorangehenden Beispiel wird von einem einzelnen statusbehafteten Dienst ausgegangen. Wenn Sie mehr als einen statusbehafteten Dienst haben, müssen Sie die „DB_Size“ der anderen Dienste der Gleichung hinzufügen. Alternativ können Sie die Anzahl der Knoten für jeden statusbehafteten Dienst separat berechnen. Ihr Dienst weist möglicherweise Replikate oder Partitionen auf, die nicht ausgeglichen sind. Bedenken Sie, dass sich in Partitionen auch mehr Daten als in anderen befinden können. Weitere Informationen zur Partitionierung finden Sie im Artikel Partitionieren von Service Fabric Reliable Services. Die vorherige Gleichung ist jedoch unabhängig von der Anzahl der Partitionen oder Replikate, da Service Fabric dafür sorgt, dass die Replikate optimal auf die Knoten verteilt werden.
Verwenden einer Kalkulationstabelle zur Berechnung der Kosten
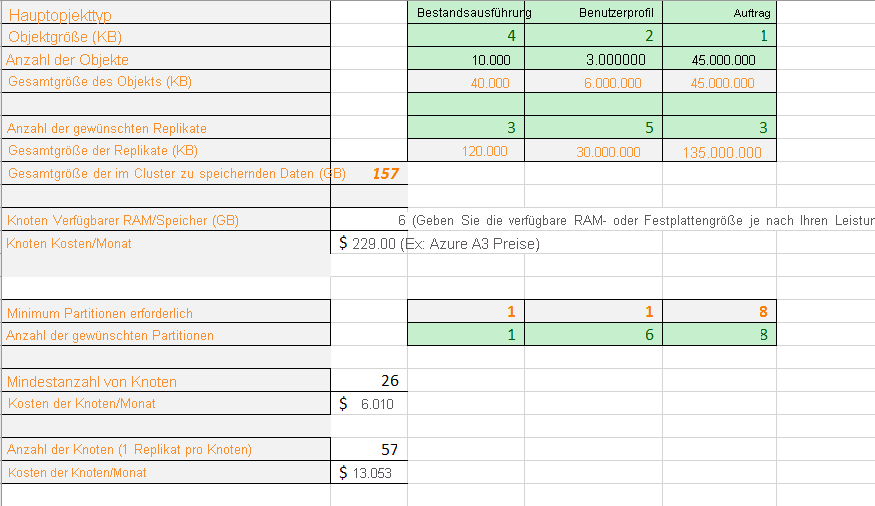
Jetzt werden wir die Formel mit echten Zahlen füllen. Im Beispielarbeitsblatt wird gezeigt, wie die Kapazität für eine Anwendung mit drei Arten von Datenobjekten geplant wird. Für jedes Objekt wählen wir einen Schätzwert für seine Größe und die erwartete Anzahl. Wir wählen außerdem aus, wie viele Replikate von jedem Objekttyp wir wünschen. Das Arbeitsblatt berechnet die Gesamtmenge des Arbeitsspeichers, der im Cluster gespeichert werden soll.
Dann geben wir eine VM-Größe und die monatlichen Kosten ein. Basierend auf der VM-Größe weist die Tabelle die Mindestanzahl von Partitionen aus, auf die Sie Ihre Daten verteilen müssen, damit diese physisch auf die Knoten passen. Sie benötigen ggf. mehr Partitionen, um die besonderen Rechnen- und Netzwerkverkehrsanforderungen Ihrer Anwendung zu erfüllen. Das Arbeitsblatt zeigt, dass sich die Anzahl der Partitionen zum Verwalten der Benutzerprofilobjekte von eins auf sechs erhöht hat.
Basierend auf all diesen Informationen zeigt das Arbeitsblatt nun, dass physisch für alle Daten mit den gewünschten Partitionen und Replikaten ein Cluster mit 26 Knoten erforderlich ist. Allerdings ist dieser Cluster dicht gepackt, weshalb einige zusätzliche Knoten für etwaige Knotenausfälle und Upgrades hinzugefügt werden sollten. Das Arbeitsblatt zeigt auch, dass sich mit mehr als 57 Knoten kein zusätzlicher Nutzen ergibt, da es leere Knoten gäbe. Doch für etwaige Knotenausfälle und Upgrades können Sie sich für mehr als 57 Knoten entscheiden. Sie können die Kalkulationstabelle an die speziellen Bedürfnisse Ihrer Anwendung anpassen.
Nächste Schritte
Unter Partitionieren von Service Fabric-Diensten erfahren Sie mehr über die Partitionierung von Diensten.