Tutorial: Trainieren eines Machine Learning-Modells ohne Code (veraltet)
Sie können Ihre Daten in Spark-Tabellen mit neuen Machine Learning-Modellen anreichern, die Sie mithilfe von automatisiertem maschinellem Lernen trainieren. In Azure Synapse Analytics können Sie eine Spark-Tabelle im Arbeitsbereich auswählen, um sie als Trainingsdataset für die Erstellung von Machine Learning-Modellen in einer Umgebung ohne Code zu verwenden.
In diesem Tutorial erfahren Sie, wie Sie Machine Learning-Modelle in einer Umgebung ohne Code in Synapse Studio trainieren. Synapse Studio ist ein Feature von Azure Synapse Analytics.
Dabei wird automatisiertes maschinelles Lernen in Azure Machine Learning verwendet, anstatt die Umgebung manuell zu programmieren. Der Typ des trainierten Modells hängt von dem Problem ab, das Sie lösen möchten. In diesem Tutorial verwenden Sie ein Regressionsmodell, um Preise für Taxifahrten auf der Grundlage des New York City Taxi-Datasets vorherzusagen.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Warnung
- Ab dem 29. September 2023 wird Azure Synapse die offizielle Unterstützung für Spark 2.4 Runtimes einstellen. Nach dem 29. September 2023 werden wir keine Supporttickets im Zusammenhang mit Spark 2.4 mehr bearbeiten. Für Fehler- oder Sicherheitsfixes für Spark 2.4 ist keine Releasepipeline vorhanden. Die Nutzung von Spark 2.4 nach dem Ende der Unterstützung erfolgt auf eigenes Risiko. Aufgrund potenzieller Sicherheits- und Funktionalitätsbedenken raten wir dringend davon ab.
- Im Rahmen der Einstellung von Apache Spark 2.4 möchten wir Sie darüber informieren, dass AutoML in Azure Synapse Analytics ebenfalls veraltet sein wird. Dies umfasst sowohl die Low-Code-Schnittstelle als auch die APIs, die zum Erstellen von AutoML-Testversionen über Code verwendet werden.
- Bitte beachten Sie, dass die AutoML-Funktionalität ausschließlich über die Spark 2.4 Runtime verfügbar war.
- Kundinnen und Kunden, die weiterhin AutoML-Funktionen nutzen möchten, empfehlen wir, Ihre Daten in Ihrem Azure Data Lake Storage Gen2 (ADLSg2)-Konto zu speichern. Von dort aus können Sie nahtlos über Azure Machine Learning (AzureML) auf die AutoML-Erfahrung zugreifen. Weitere Informationen zu dieser Problemumgehung finden Sie hier.
Voraussetzungen
- Ein Azure Synapse Analytics-Arbeitsbereich. Er muss über ein Azure Data Lake Storage Gen2-Speicherkonto verfügen, das als Standardspeicher konfiguriert ist. Für das hier verwendete Data Lake Storage Gen2-Dateisystem müssen Sie über die Rolle Mitwirkender an Storage-Blobdaten verfügen.
- Ein Apache Spark-Pool (Version 2.4) in Ihrem Azure Synapse Analytics-Arbeitsbereich. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines serverlosen Apache Spark-Pools mithilfe von Synapse Studio.
- Ein verknüpfter Azure Machine Learning-Dienst in Ihrem Azure Synapse Analytics-Arbeitsbereich. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines neuen verknüpften Azure Machine Learning-Diensts in Synapse.
Melden Sie sich auf dem Azure-Portal an.
Melden Sie sich beim Azure-Portal an.
Erstellen einer Spark-Tabelle für das Trainingsdataset
Für dieses Tutorial benötigen Sie eine Spark-Tabelle. Mit dem folgenden Notebook wird eine solche Tabelle erstellt:
Laden Sie das Notebook Create-Spark-Table-NYCTaxi- Data.ipynb herunter.
Importieren Sie das Notebook in Synapse Studio.

Wählen Sie den gewünschten Spark-Pool und anschließend Alle ausführen aus. In diesem Schritt werden Daten für New Yorker Taxis aus dem offenen Dataset abgerufen und in Ihrer Spark-Standarddatenbank gespeichert.

Nach Abschluss der Notebookausführung wird unter der Spark-Standarddatenbank eine neue Spark-Tabelle angezeigt. Suchen Sie unter Daten nach der Tabelle nyc_taxi.
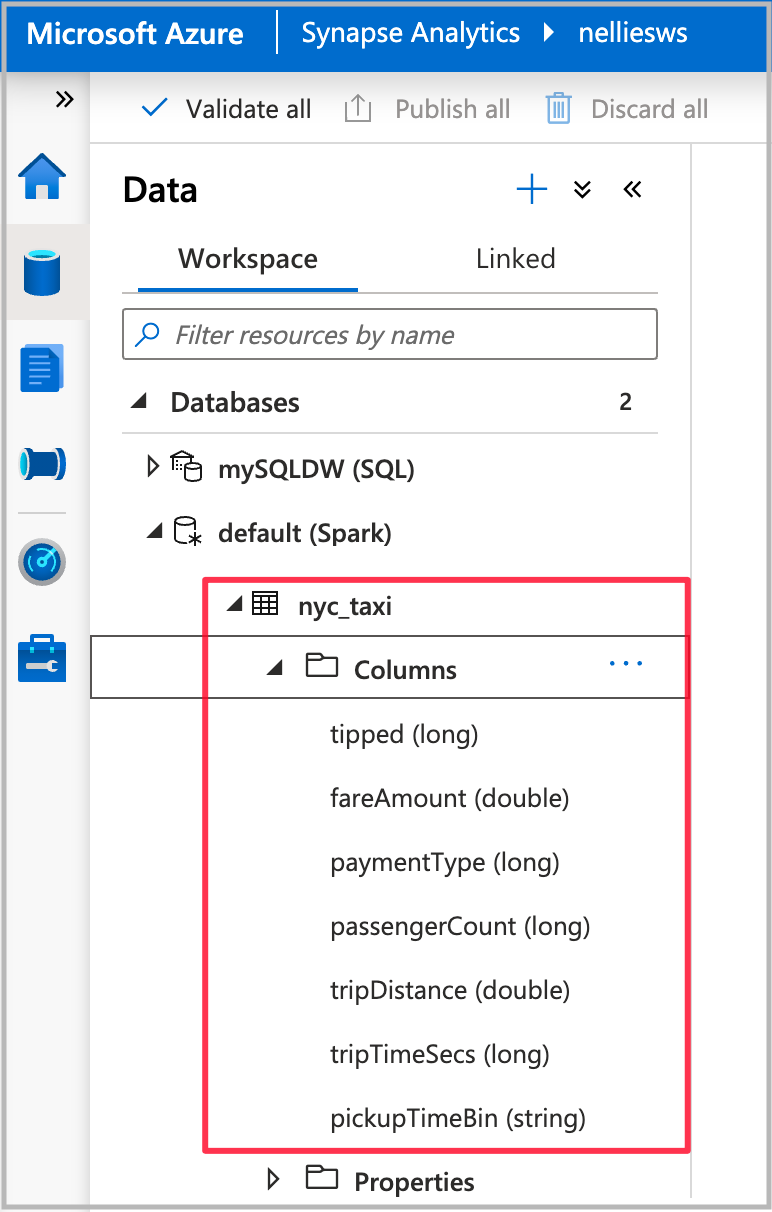
Öffnen des Assistenten für automatisiertes maschinelles Lernen
Klicken Sie zum Öffnen des Assistenten mit der rechten Maustaste auf die im vorherigen Schritt erstellte Spark-Tabelle. Wählen Sie anschließend Machine Learning>Neues Modell trainieren aus.

Auswählen eines Modelltyps
Wählen Sie die Art des Machine Learning-Modells für das Experiment basierend auf der zu beantwortenden Frage aus. Der Wert, den Sie vorhersagen möchten, ist numerisch (Preise für Taxifahrten). Wählen Sie daher hier Regression aus. Klicken Sie anschließend auf Weiter.

Konfigurieren des Experiments
Geben Sie Konfigurationsdetails für die Erstellung eines automatisierten Machine Learning-Experiments an, das in Azure Machine Learning ausgeführt wird. Bei dieser Ausführung werden mehrere Modelle trainiert. Das beste Modell aus einer erfolgreichen Ausführung wird in der Azure Machine Learning-Modellregistrierung registriert.
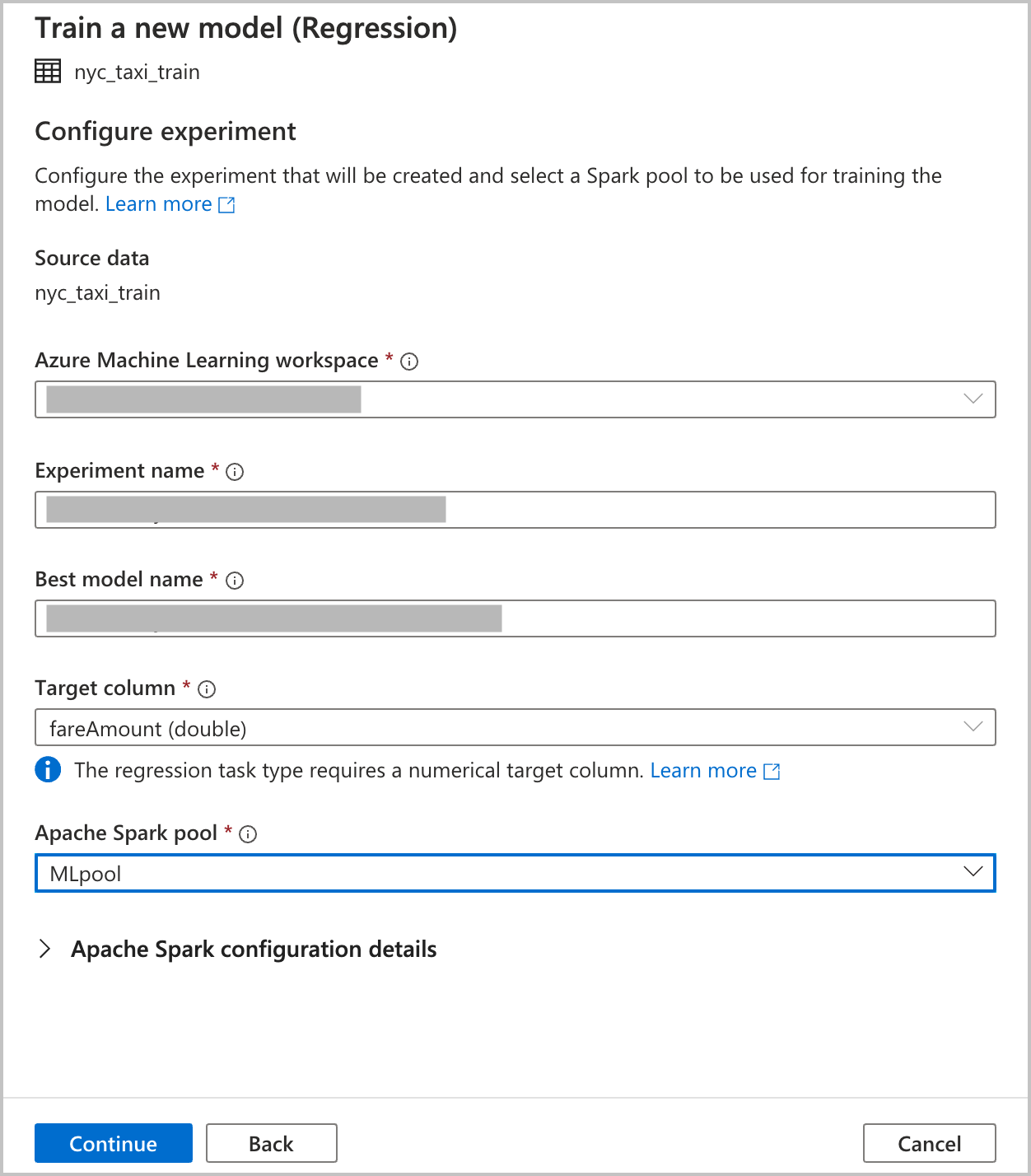
Azure Machine Learning-Arbeitsbereich: Für die Erstellung der Ausführung eines automatisierten Machine Learning-Experiments ist ein Azure Machine Learning-Arbeitsbereich erforderlich. Außerdem müssen Sie Ihren Azure Synapse Analytics-Arbeitsbereich mithilfe eines verknüpften Diensts mit dem Azure Machine Learning-Arbeitsbereich verknüpfen. Sind alle Voraussetzungen erfüllt, können Sie den Azure Machine Learning-Arbeitsbereich angeben, den Sie für diese automatisierte Ausführung verwenden möchten.
Experimentname: Geben Sie den Namen des Experiments an. Beim Übermitteln einer Ausführung von automatisiertem maschinellem Lernen muss ein Experimentname angegeben werden. Die Informationen für die Ausführung werden im Azure Machine Learning-Arbeitsbereich unter diesem Experiment gespeichert. Hierdurch wird standardmäßig ein neues Experiment erstellt und ein vorgeschlagener Name generiert. Sie können aber auch den Namen eines vorhandenen Experiments angeben.
Name des besten Modells: Geben Sie den Namen des besten Modells aus der automatisierten Ausführung an. Dem besten Modell wird dieser Name zugewiesen und nach dieser Ausführung automatisch in der Azure Machine Learning-Modellregistrierung gespeichert. Im Rahmen einer Ausführung von automatisiertem maschinellem Lernen werden zahlreiche Machine Learning-Modelle erstellt. Basierend auf der primären Metrik, die Sie in einem späteren Schritt auswählen, können diese Modelle verglichen werden, um das beste Modell auszuwählen.
Zielspalte: Für die Vorhersage dieses Werts wird das Modell trainiert. Wählen Sie die Spalte im Dataset, die die Daten enthält, die Sie vorhersagen möchten. Wählen Sie in diesem Tutorial die numerische Spalte
fareAmountals Zielspalte aus.Spark-Pool: Geben Sie den Spark-Pool an, den Sie für die Ausführung des automatisierten Experiments verwenden möchten. Die Berechnungen werden für den von Ihnen angegebenen Pool ausgeführt.
Details zur Spark-Konfiguration: Zusätzlich zum Spark-Pool haben Sie die Möglichkeit, Details zur Sitzungskonfiguration anzugeben.
Wählen Sie Weiter.
Konfigurieren des Modells
Da Sie im vorherigen Abschnitt die Option Regression als Modelltyp ausgewählt haben, stehen folgende Konfigurationen zur Verfügung. (Diese sind auch für den Modelltyp Klassifizierung verfügbar.)
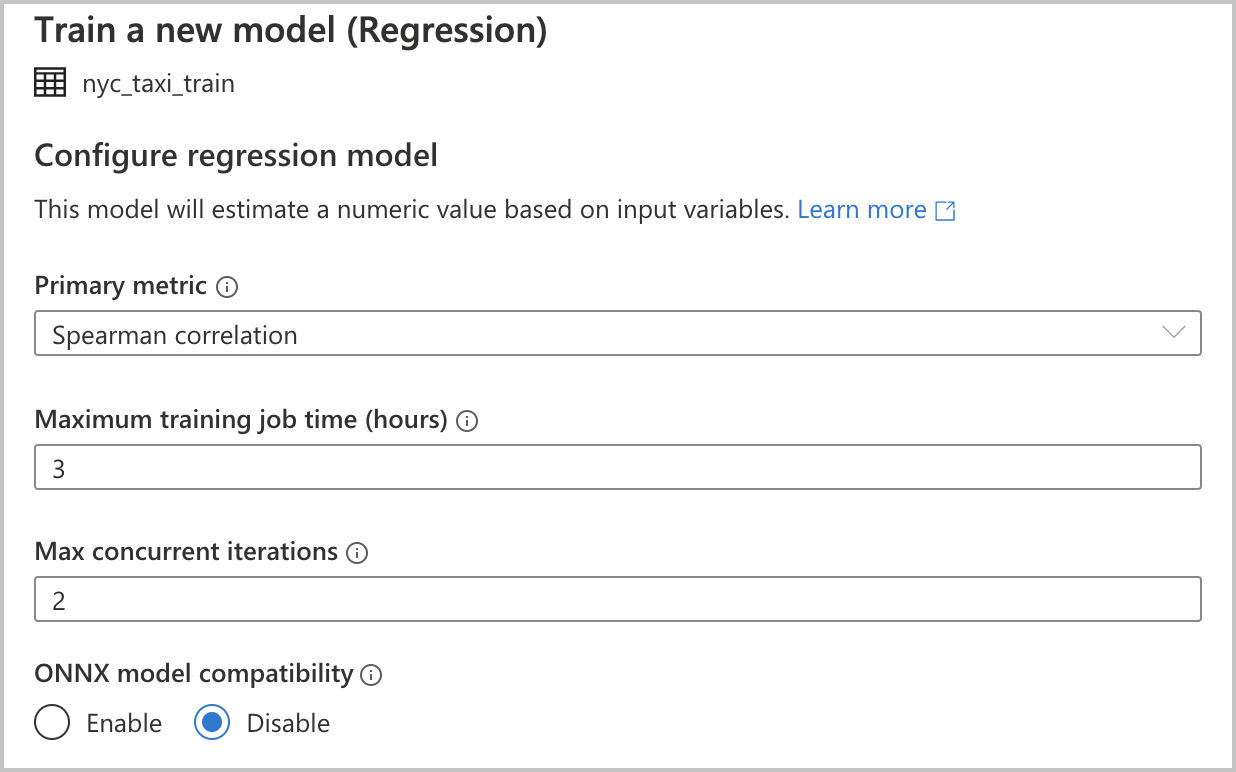
Primary metric (Primäre Metrik): Geben Sie die Metrik ein, mit der gemessen wird, wie gut die Leistung des Modells ist. Anhand dieser Metrik werden verschiedene Modelle, die durch die automatisierte Ausführung erstellt wurden, miteinander verglichen, um das Modell zu ermitteln, das am besten abgeschnitten hat.
Training job time (hours) Trainingsauftragszeit (Stunden): Geben Sie den maximalen Zeitraum (in Stunden) an, in dem ein Experiment ausgeführt und das Training von Modellen durchgeführt werden kann. Beachten Sie, dass Sie auch Werte kleiner 1 angeben können (beispielsweise 0,5).
Max concurrent iterations (Maximale Anzahl gleichzeitiger Iterationen): Wählen Sie die maximale Anzahl von Iterationen aus, die parallel ausgeführt werden.
ONNX model compatibility (Kompatibilität des ONNX-Modells): Wenn Sie diese Option aktivieren, werden die mittels automatisiertem maschinellem Lernen trainierten Modelle in das ONNX-Format konvertiert. Dies ist vor allem relevant, wenn Sie das Modell für die Bewertung in Azure Synapse Analytics-SQL-Pools nutzen möchten.
Diese Einstellungen verfügen alle über einen Standardwert, den Sie anpassen können.
Starten einer Ausführung
Nachdem alle erforderlichen Konfigurationen vorgenommen wurden, können Sie Ihre automatisierte Ausführung starten. Sie können eine Ausführung direkt erstellen, indem Sie Create run (Ausführung erstellen) auswählen. Dadurch wird die Ausführung ohne Code gestartet. Wenn Sie Code bevorzugen, können Sie alternativ Open in notebook (In Notebook öffnen) auswählen. Dadurch wird ein Notebook geöffnet, das den Code enthält, mit dem die Ausführung erstellt wird. So können Sie den Code anzeigen und die Ausführung selbst starten.

Hinweis
Wenn Sie im vorherigen Abschnitt die Option Zeitreihenprognosen als Modelltyp ausgewählt haben, sind weitere Konfigurationsschritte erforderlich. Für Vorhersagen wird darüber hinaus die ONNX-Modellkompatibilität nicht unterstützt.
Direktes Erstellen einer Ausführung
Wenn Sie die Ausführung des automatisierten maschinellen Lernens direkt starten möchten, wählen Sie Create Run (Ausführung erstellen) aus. Daraufhin wird eine Benachrichtigung mit dem Hinweis angezeigt, dass die Ausführung gestartet wird. Anschließend wird eine Erfolgsbenachrichtigung angezeigt. Sie können auch den Link in der Benachrichtigung auswählen, um den Status in Azure Machine Learning zu überprüfen.
Erstellen einer Ausführung mit einem Notebook
Wählen Sie zum Generieren eines Notebooks die Option Open In Notebook (In Notebook öffnen) aus. Dadurch haben Sie die Möglichkeit, Einstellungen hinzuzufügen oder den Code für Ihre Ausführung des automatisierten maschinellen Lernens auf andere Weise zu ändern. Wenn Sie zum Ausführen des Codes bereit sind, wählen Sie Alle ausführen aus.

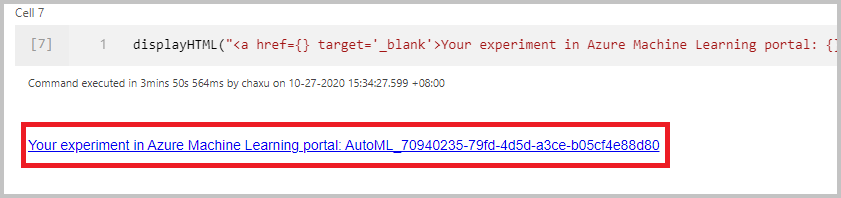
Überwachen der Ausführung
Nach erfolgreicher Übermittlung der Ausführung wird in der Ausgabe des Notebooks ein Link zur Experimentausführung im Azure Machine Learning-Arbeitsbereich angezeigt. Wählen Sie den Link aus, um Ihre automatisierte Ausführung in Azure Machine Learning zu überwachen.