Datenmigration, ETL und Last für Oracle-Migrationen
Dieser Artikel ist Teil zwei einer siebenteiligen Reihe, die Anleitungen zur Migration von Oracle zu Azure Synapse Analytics enthält. Schwerpunktmäßig behandelt dieses Tutorial bewährte Methoden für ETL-Prozesse und Lademigration.
Überlegungen zur Datenmigration
Bei der Migration von Daten, ETL und Lasten aus einem Legacy-Data Warehouse und Data Marts von Oracle zu Azure Synapse sind viele Faktoren zu berücksichtigen.
Erste Entscheidungen zur Datenmigration von Oracle
Wenn Sie eine Migration von einer vorhandenen Oracle-Umgebung planen, berücksichtigen Sie die folgenden datenbezogenen Fragen:
Sollen nicht verwendete Tabellenstrukturen migriert werden?
Mit welchem Migrationsansatz lassen sich Risiken und Auswirkungen für Benutzer*innen am besten minimieren?
Soll beim Migrieren von Data Marts eine physische Implementierung (wie bisher) oder lieber eine virtuelle Implementierung verwendet werden?
Die nächsten Abschnitte behandeln diese Punkte im Kontext einer Migration von Oracle.
Migrieren nicht verwendeter Tabellen?
Es ist sinnvoll, nur Tabellen zu migrieren, die verwendet werden. Tabellen, die nicht aktiv sind, können archiviert und nicht migriert werden, sodass die Daten bei Bedarf in der Zukunft verfügbar sind. Es ist am besten, anstelle der Dokumentation Systemmetadaten und Protokolldateien zu verwenden, um festzustellen, welche Tabellen in Gebrauch sind, da die Dokumentation veraltet sein kann.
Katalogtabellen und Protokolle des Oracle-Systems enthalten Informationen, die verwendet werden können, um zu bestimmen, wann zuletzt auf eine bestimmte Tabelle zugegriffen wurde – was wiederum verwendet werden kann, um zu entscheiden, ob eine Tabelle ein Kandidat für die Migration ist oder nicht.
Wenn Sie das Oracle Diagnostic Pack lizenziert haben, haben Sie Zugriff auf den Active Session History, mit dem Sie feststellen können, wann zuletzt auf eine Tabelle zugegriffen wurde.
Tipp
In Legacy-Systemen ist es nicht ungewöhnlich, dass Tabellen im Laufe der Zeit redundant werden – diese müssen in den meisten Fällen nicht migriert werden.
Mit der folgenden Beispielabfrage wird nach der Verwendung einer bestimmten Tabelle innerhalb eines bestimmten Zeitfensters gesucht:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
Die Ausführung dieser Abfrage kann eine Weile dauern, wenn Sie zahlreiche Abfragen ausgeführt haben.
Was ist der beste Migrationsansatz, um Risiken und Auswirkungen auf Benutzer zu minimieren?
Diese Frage wird häufig gestellt, da Unternehmen möglicherweise die Auswirkungen von Änderungen auf das Data Warehouse-Datenmodell verringern möchten, um die Agilität zu verbessern. Unternehmen sehen oft eine Möglichkeit, ihre Daten während einer ETL-Migration weiter zu modernisieren oder umzuwandeln. Dieser Ansatz trägt ein höheres Risiko, da mehrere Faktoren gleichzeitig geändert werden, was einen Vergleich der Ergebnisse des alten Systems mit denen des neuen erschwert. Änderungen am Datenmodell an dieser Stelle können sich auch auf vor- oder nachgelagerte ETL-Jobs für andere Systeme auswirken. Aufgrund dieses Risikos ist es besser, nach der Data-Warehouse-Migration eine Neugestaltung in diesem Umfang vorzunehmen.
Auch wenn ein Datenmodell im Rahmen der Gesamtmigration absichtlich geändert wird, empfiehlt es sich, das vorhandene Modell unverändert zu Azure Synapse zu migrieren, anstatt eine Neuentwicklung auf der neuen Plattform vorzunehmen. Dieser Ansatz minimiert die Auswirkungen auf bestehende Produktionssysteme und profitiert gleichzeitig von der Leistung und elastischen Skalierbarkeit der Azure-Plattform für einmalige Reengineering-Aufgaben.
Tipp
Migrieren Sie das bestehende Modell zunächst im Ist-Zustand, auch wenn eine Änderung des Datenmodells in Zukunft geplant ist.
Data-Mart-Migration: physisch bleiben oder virtuell werden?
In älteren Oracle Data Warehouse-Umgebungen ist es gängige Praxis, viele Data Marts zu erstellen, die strukturiert sind, um eine gute Leistung für Ad-hoc-Self-Service-Abfragen und -Berichte für eine bestimmte Abteilung oder Geschäftsfunktion innerhalb einer Organisation zu bieten. Ein Data Mart besteht in der Regel aus einer Teilmenge des Data Warehouse, das aggregierte Versionen der Daten in einer Form enthält, die es Benutzern ermöglicht, diese Daten mit schnellen Reaktionszeiten einfach abzufragen. Benutzer können benutzerfreundliche Abfragetools wie Microsoft Power BI verwenden, das die Interaktionen von Geschäftsbenutzern mit Data Marts unterstützt. Die Form der Daten in einem Data Mart ist im Allgemeinen ein dimensionales Datenmodell. Eine Verwendung von Data Marts besteht darin, die Daten in einer verwendbaren Form bereitzustellen, selbst wenn das zugrunde liegende Warehouse-Datenmodell etwas anderes ist, z. B. ein Datentresor.
Sie können separate Data Marts für einzelne Geschäftseinheiten innerhalb einer Organisation verwenden, um stabile Datensicherheitssysteme zu implementieren. Beschränken Sie den Zugriff auf bestimmte Data Marts, die für Benutzer relevant sind, und löschen, verschleiern oder anonymisieren Sie sensible Daten.
Wenn diese Data Marts als physische Tabellen implementiert werden, benötigen sie zusätzliche Speicherressourcen und Verarbeitung, um sie regelmäßig zu erstellen und zu aktualisieren. Zudem entspricht die Aktualität der Daten im Data Mart nur dem letzten Aktualisierungsvorgang, sodass sie daher möglicherweise für stark veränderliche Datendashboards nicht geeignet sind.
Tipp
Durch die Virtualisierung von Daten Marts können Speicher- und Verarbeitungsressourcen gespart werden.
Mit dem Aufkommen kostengünstigerer skalierbarer MPP-Architekturen wie Azure Synapse und deren inhärenten Leistungsmerkmalen können Sie Datamart-Funktionalität bereitstellen, ohne den Mart als Satz physischer Tabellen zu instanziieren. Eine Methode besteht darin, die Data Marts effektiv über SQL-Ansichten auf das Haupt-Data Warehouse zu virtualisieren. Eine andere Möglichkeit besteht darin, die Data Marts über eine Virtualisierungsebene mit Funktionen wie Ansichten in Azure oder Virtualisierungsprodukten von Drittanbietern zu virtualisieren. Dieser Ansatz vereinfacht oder eliminiert die Notwendigkeit für zusätzliche Speicher- und Aggregationsverarbeitung und reduziert die Gesamtzahl der zu migrierenden Datenbankobjekte.
Es gibt einen weiteren potenziellen Vorteil dieses Ansatzes. Durch die Implementierung der Aggregations- und Verknüpfungslogik innerhalb einer Virtualisierungsebene und die Präsentation externer Berichterstellungstools über eine virtualisierte Ansicht wird die zum Erstellen dieser Ansichten erforderliche Verarbeitung in das Data Warehouse verschoben. Das Data Warehouse ist im Allgemeinen der beste Ort, um Verknüpfungen, Aggregationen und andere verwandte Operationen mit großen Datenmengen auszuführen.
Die Haupttreiber für die Implementierung eines virtuellen Data Mart über einen physischen Data Mart sind:
Mehr Agilität: Virtuelle Data Marts können einfacher geändert werden als physische Tabellen und die zugehörigen ETL-Prozesse.
Geringere Gesamtkosten: In einer virtualisierten Implementierung sind weniger Datenspeicher und Datenkopien erforderlich.
Keine zu migrierenden ETL-Aufträge und vereinfachte Data-Warehouse-Architektur in einer virtualisierten Umgebung.
Leistung: Obwohl physische Data Marts in der Vergangenheit eine bessere Leistung erbracht haben, implementieren Virtualisierungsprodukte jetzt intelligente Caching-Techniken, um diesen Unterschied auszugleichen.
Tipp
Leistung und Skalierbarkeit von Azure Synapse ermöglichen eine Virtualisierung ohne Leistungsbeeinträchtigung.
Datenmigration von Oracle
Verstehen Ihrer Daten
Im Rahmen der Migrationsplanung sollten Sie das zu migrierende Datenvolumen im Detail verstehen, da dies Entscheidungen über den Migrationsansatz beeinflussen kann. Bestimmen Sie anhand von Systemmetadaten physischen Speicherplatz, der von den Rohdaten in den zu migrierenden Tabellen belegt wird. In diesem Zusammenhang bedeutet Rohdaten die Menge an Speicherplatz, die von den Datenzeilen innerhalb einer Tabelle verwendet wird, ohne Overhead wie Indizes und Komprimierung. Die größten Faktentabellen umfassen in der Regel mehr als 95 % der Daten.
Diese Abfrage gibt Ihnen die Gesamtgröße der Datenbank in Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
Die Datenbankgröße entspricht der Größe von (data files + temp files + online/offline redo log files + control files). Die Gesamtgröße der Datenbank umfasst belegten und freien Speicherplatz.
Die folgende Beispielabfrage zeigt eine Aufschlüsselung des von Tabellendaten und Indizes belegten Speicherplatzes:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Darüber hinaus stellt das Microsoft-Datenbankmigrationsteam viele Ressourcen bereit, einschließlich der Oracle Inventory Script Artifacts. Das Oracle Inventory Script Artifacts-Tool enthält eine PL/SQL-Abfrage, die auf Oracle-Systemtabellen zugreift und eine Anzahl von Objekten nach Schematyp, Objekttyp und Status bereitstellt. Das Tool bietet auch eine grobe Schätzung der Rohdaten in jedem Schema und der Größe der Tabellen in jedem Schema, wobei die Ergebnisse in einem CSV-Format gespeichert werden. Eine enthaltene Kalkulationstabelle nimmt die CSV-Datei als Eingabe und liefert Größendaten.
Für jede Tabelle können Sie das zu migrierende Datenvolumen genau abschätzen, indem Sie eine repräsentative Stichprobe der Daten, z. B. eine Million Zeilen, in eine unkomprimierte ASCII-Datendatei mit Trennzeichen extrahieren. Verwenden Sie dann die Größe dieser Datei, um eine durchschnittliche Rohdatengröße pro Zeile zu erhalten. Multiplizieren Sie schließlich diese durchschnittliche Menge mit der Gesamtanzahl der Zeilen in der ganzen Tabelle, um die Menge der Rohdaten für die Tabelle zu erhalten. Verwenden Sie diese Rohdatenmenge für Ihre Planung.
Verwenden Sie SQL-Abfragen, um Datentypen zu finden
Durch Abfragen der statischen Oracle-Datenwörterbuchansicht DBA_TAB_COLUMNS können Sie bestimmen, welche Datentypen in einem Schema verwendet werden und ob diese Datentypen geändert werden müssen. Verwenden Sie SQL-Abfragen, um die Spalten in jedem Oracle-Schema mit Datentypen zu finden, die nicht direkt Datentypen in Azure Synapse zugeordnet sind. Ebenso können Sie Abfragen verwenden, um die Anzahl der Vorkommen jedes Oracle-Datentyps zu zählen, der nicht direkt Azure Synapse zugeordnet ist. Indem Sie die Ergebnisse dieser Abfragen in Kombination mit der Datentypvergleichstabelle verwenden, können Sie bestimmen, welche Datentypen in einer Azure Synapse-Umgebung geändert werden müssen.
Um die Spalten mit Datentypen zu finden, die keinen Datentypen in Azure Synapse zugeordnet sind, führen Sie die folgende Abfrage aus, nachdem Sie <owner_name> durch den entsprechenden Besitzer Ihres Schemas ersetzt haben:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Verwenden Sie die folgende Abfrage, um die Anzahl der nicht zuordenbaren Datentypen zu zählen:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft bietet SQL Server Migration Assistant (SSMA) für Oracle an, um die Migration von Data Warehouses aus Legacy-Oracle-Umgebungen zu automatisieren, einschließlich der Zuordnung von Datentypen. Sie können auch Azure Database Migration Services verwenden, um eine Migration von Umgebungen wie Oracle zu planen und durchzuführen. Drittanbieter bieten auch Tools und Dienste zur Automatisierung der Migration an. Wenn in der Oracle-Umgebung bereits ein ETL-Tool eines Drittanbieters verwendet wird, können Sie dieses Tool verwenden, um alle erforderlichen Datentransformationen zu implementieren. Im nächsten Abschnitt wird die Migration vorhandener ETL-Prozesse untersucht.
Überlegungen zur ETL-Migration
Erste Entscheidungen zur Oracle ETL-Migration
Für die ETL/ELT-Verarbeitung verwenden ältere Oracle Data Warehouses häufig benutzerdefinierte Skripts, ETL-Tools von Drittanbietern oder eine Kombination von Ansätzen, die sich im Laufe der Zeit entwickelt hat. Wenn Sie eine Migration zu Azure Synapse planen, bestimmen Sie die beste Möglichkeit, die erforderliche ETL/ELT-Verarbeitung in der neuen Umgebung zu implementieren und gleichzeitig Kosten und Risiken zu minimieren.
Tipp
Planen Sie den Ansatz für die ETL-Migration vorab, und nutzen Sie dabei gegebenenfalls Azure-Einrichtungen.
Das folgende Flussdiagramm fasst einen Ansatz zusammen:
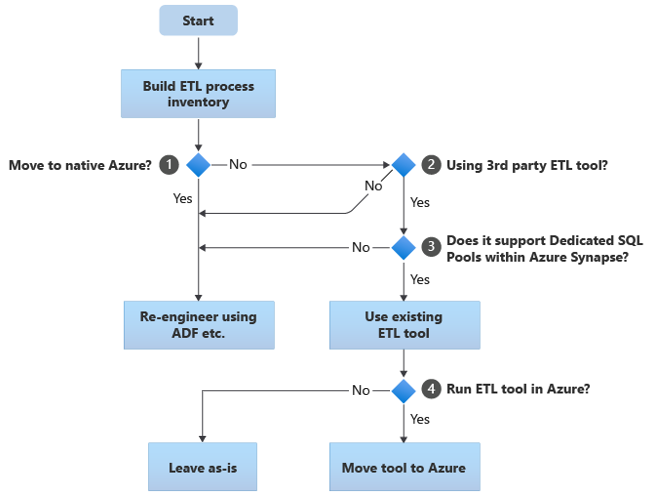
Wie im Flussdiagramm gezeigt, besteht der erste Schritt immer darin, eine Bestandsaufnahme der ETL/ELT-Prozesse zu erstellen, die migriert werden müssen. Mit den standardmäßig integrierten Azure-Funktionen müssen einige vorhandene Prozesse möglicherweise nicht verschoben werden. Für Planungszwecke ist es wichtig, dass Sie den Umfang der Migration verstehen. Betrachten Sie als Nächstes die Fragen im Entscheidungsbaum des Flussdiagramms:
Zu nativem Azure wechseln? Ihre Antwort hängt davon ab, ob Sie zu einer vollständig Azure-nativen Umgebung migrieren. In diesem Fall empfehlen wir Ihnen, die ETL-Verarbeitung mithilfe vonPipelines und Aktivitäten in Azure Data Factory oder Azure Synapse-Pipelines neu zu konstruieren.
Verwenden Sie ein ETL-Tool eines Drittanbieters? Wenn Sie nicht zu einer vollständig Azure-nativen Umgebung wechseln, prüfen Sie, ob bereits ein vorhandenes ETL-Tool eines Drittanbieters verwendet wird. In der Oracle-Umgebung stellen Sie möglicherweise fest, dass ein Teil oder die gesamte ETL-Verarbeitung von benutzerdefinierten Skripts ausgeführt wird, die Oracle-spezifische Dienstprogramme wie Oracle SQL Developer, Oracle SQL*Loader oder Oracle Data Pump verwenden. Der Ansatz in diesem Fall besteht darin, mithilfe von Azure Data Factory neu zu entwickeln.
Unterstützt der Drittanbieter dedizierte SQL-Pools in Azure Synapse? Überlegen Sie, ob eine große Investition in Fähigkeiten im ETL-Tool eines Drittanbieters erforderlich ist oder ob vorhandene Workflows und Zeitpläne dieses Tool verwenden. Ermitteln Sie in diesem Fall, ob das Tool Azure Synapse als Zielumgebung effizient unterstützen kann. Idealerweise enthält das Tool native Konnektoren, die Azure-Einrichtungen wie PolyBase oder COPY INTO für das effizienteste Laden von Daten verwenden können. Aber auch ohne native Konnektoren gibt es im Allgemeinen eine Möglichkeit, externe Prozesse wie PolyBase oder
COPY INTOaufzurufen und anwendbare Parameter zu übergeben. Verwenden Sie in diesem Fall vorhandene Fähigkeiten und Workflows mit Azure Synapse als neue Zielumgebung.Wenn Sie Oracle Data Integrator (ODI) für die ELT-Verarbeitung verwenden, benötigen Sie ODI Knowledge Modules for Azure Synapse. Wenn Ihnen diese Module in Ihrer Organisation nicht zur Verfügung stehen, Sie aber über ODI verfügen, können Sie ODI verwenden, um Flat Files zu generieren. Diese Flatfiles können dann nach Azure verschoben und in Azure Data Lake Storage aufgenommen werden, um sie in Azure Synapse zu laden.
ETL-Tools in Azure ausführen? Wenn Sie sich entscheiden, ein vorhandenes ETL-Tool eines Drittanbieters beizubehalten, können Sie dieses Tool in der Azure-Umgebung ausführen (statt auf einem vorhandenen lokalen ETL-Server) und Data Factory die Gesamtorchestrierung der vorhandenen Workflows übernehmen lassen. Entscheiden Sie also, ob Sie das vorhandene Tool unverändert ausführen oder in die Azure-Umgebung verschieben möchten, um Kosten-, Leistungs- und Skalierbarkeitsvorteile zu erzielen.
Tipp
Erwägen Sie die Ausführung von ETL-Tools in Azure, um Leistungs-, Skalierbarkeits- und Kostenvorteile zu nutzen.
Überarbeiten Sie vorhandene Oracle-spezifische Skripte
Wenn einige oder alle der vorhandenen Oracle Warehouse ETL/ELT-Verarbeitung von benutzerdefinierten Skripts verarbeitet werden, die Oracle-spezifische Dienstprogramme wie Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader oder Oracle Data Pump verwenden, müssen Sie dies tun codieren Sie diese Skripts für die Azure Synapse-Umgebung neu. Wenn ETL-Prozesse mithilfe gespeicherter Prozeduren in Oracle implementiert wurden, müssen Sie diese Prozesse ebenfalls neu codieren.
Einige Elemente des ETL-Prozesses lassen sich einfach migrieren, beispielsweise durch einfaches Massenladen von Daten aus einer externen Datei in eine Staging-Tabelle. Es ist möglicherweise sogar möglich, diese Teile des Prozesses zu automatisieren, indem Sie beispielsweise Azure Synapse COPY INTO oder PolyBase anstelle von SQL*Loader verwenden. Bei anderen Teilen des Prozesses, die beliebig komplexe SQL- und/oder andere gespeicherte Prozeduren enthalten, nimmt das Re-Engineering mehr Zeit in Anspruch.
Tipp
Der Bestand der zu migrierenden ETL-Aufgaben sollte Skripts und gespeicherte Prozeduren enthalten.
Eine Möglichkeit, Oracle SQL auf Kompatibilität mit Azure Synapse zu testen, besteht darin, einige repräsentative SQL-Anweisungen aus einer Verknüpfung von Oracle v$active_session_history und v$sql zu erfassen, um sql_text zu erhalten, und diesen Abfragen dann das Präfix EXPLAIN. Unter der Annahme eines gleichartigen migrierten Datenmodells in Azure Synapse führen Sie diese EXPLAIN-Anweisungen in Azure Synapse aus. Jedes inkompatible SQL gibt einen Fehler aus. Anhand dieser Informationen können Sie den Umfang der Rekodierungsaufgabe bestimmen.
Tipp
Verwenden Sie EXPLAIN, um SQL-Inkompatibilitäten zu finden.
Im schlimmsten Fall kann eine manuelle Umkodierung erforderlich sein. Es sind jedoch Produkte und Dienste von Microsoft-Partnern erhältlich, die Sie beim Reengineering von Oracle-spezifischem Code unterstützen.
Tipp
Partner bieten Produkte und Fähigkeiten an, die bei der Überarbeitung von Oracle-spezifischem Code helfen.
Verwenden Sie vorhandene ETL-Tools von Drittanbietern
In vielen Fällen wird das vorhandene Legacy-Data-Warehouse-System bereits mit einem ETL-Produkt eines Drittanbieters gefüllt und gewartet. Eine Liste der aktuellen Microsoft-Datenintegrationspartner für Azure Synapse finden Sie unter Azure Synapse Analytics-Datenintegrationspartner.
Die Oracle-Community verwendet häufig mehrere beliebte ETL-Produkte. In den folgenden Abschnitten werden die beliebtesten ETL-Tools für Oracle-Warehouses erörtert. Sie können alle diese Produkte auf einer VM in Azure ausführen und sie zum Lesen und Schreiben von Azure-Datenbanken und -Dateien verwenden.
Tipp
Nutzen Sie Investitionen in vorhandene Tools von Drittanbietern, um Kosten und Risiken zu reduzieren.
Laden von Daten aus Oracle
Auswahlmöglichkeiten beim Laden von Daten aus Oracle
Wenn Sie die Migration von Daten aus einem Oracle Data Warehouse vorbereiten, entscheiden Sie, wie Daten physisch aus der vorhandenen lokalen Umgebung in Azure Synapse in der Cloud verschoben werden und welche Tools für die Übertragung und das Laden verwendet werden. Betrachten Sie die folgenden Fragen, die in den folgenden Abschnitten behandelt werden.
Sollen die Daten in Dateien extrahiert oder direkt über eine Netzwerkverbindung verschoben werden?
Soll der Prozess über das Quellsystem oder die Azure-Zielumgebung orchestriert werden?
Welche Tools werden Sie verwenden, um den Migrationsprozess zu automatisieren und zu verwalten?
Werden Daten mittels Dateien oder einer Netzwerkverbindung übertragen?
Sobald die zu migrierenden Datenbanktabellen in Azure Synapse erstellt wurden, können Sie die Daten, die diese Tabellen füllen, aus dem veralteten Oracle-System in die neue Umgebung verschieben. Dabei gibt es grundsätzlich zwei Ansätze:
Dateiextraktion: Extrahieren Sie die Daten aus den Oracle-Tabellen in flach getrennte Dateien, normalerweise im CSV-Format. Sie können Tabellendaten auf verschiedene Arten extrahieren:
- Verwenden Sie standardmäßige Oracle-Tools wie SQL*Plus, SQL Developer und SQLcl.
- Verwenden Sie Oracle Data Integrator (ODI), um Flatfiles zu generieren.
- Verwenden Sie den Oracle-Connector in Data Factory, um Oracle-Tabellen parallel zu entladen, um das Laden von Daten nach Partitionen zu ermöglichen.
- Verwenden Sie ein ETL-Tool eines Drittanbieters.
Beispiele zum Extrahieren von Oracle-Tabellendaten finden Sie im Artikelanhang.
Bei diesem Ansatz wird Speicherplatz zum Speichern der extrahierten Datendateien benötigt. Der Speicherplatz kann lokal in der Oracle-Quelldatenbank sein, wenn ausreichend Speicher verfügbar ist, oder remote in Azure Blob Storage. Die beste Leistung wird erzielt, wenn eine Datei lokal geschrieben wird, da dies Netzwerk-Overhead vermeidet.
Um die Speicher- und Netzwerkübertragungsanforderungen zu minimieren, komprimieren Sie die extrahierten Datendateien mit einem Dienstprogramm wie gzip.
Verschieben Sie die Flatfiles nach dem Extrahieren in Azure Blob Storage. Microsoft bietet verschiedene Optionen zum Verschieben großer Datenmengen, darunter:
- AzCopy zum Verschieben von Dateien über das Netzwerk in Azure Storage.
- Azure ExpressRoute zum Verschieben von Massendaten über eine private Netzwerkverbindung.
- Azure Data Box zum Verschieben von Dateien auf ein physisches Speichergerät, das Sie zum Laden an ein Azure-Rechenzentrum senden.
Weitere Informationen finden Sie unter Übertragen von Daten in und aus Azure.
Direktes Extrahieren und Laden über das Netzwerk: Die Azure-Zielumgebung sendet eine Datenextraktionsanforderung, normalerweise über einen SQL-Befehl, an das alte Oracle-System, um die Daten zu extrahieren. Die Ergebnisse werden über das Netzwerk gesendet und direkt in Azure Synapse geladen, ohne dass die Daten in Zwischendateien gespeichert werden müssen. Der limitierende Faktor in diesem Szenario ist normalerweise die Bandbreite der Netzwerkverbindung zwischen der Oracle-Datenbank und der Azure-Umgebung. Für außergewöhnlich große Datenmengen ist dieser Ansatz möglicherweise nicht praktikabel.
Tipp
Verstehen Sie die zu migrierenden Datenmengen und die verfügbare Netzwerkbandbreite, da diese Faktoren die Entscheidung für den Migrationsansatz beeinflussen.
Es gibt auch einen Hybridansatz, bei dem beide Methoden verwendet werden. Sie können beispielsweise den Ansatz der direkten Netzwerkextraktion für kleinere Dimensionstabellen und Stichproben größerer Faktentabellen zum schnellen Bereitstellen einer Testumgebung in Azure Synapse verwenden. Für umfangreiche historische Faktentabellen können Sie den Dateiextraktions- und -übertragungsansatz mit Azure Data Box verwenden.
Von Oracle oder Azure orchestrieren?
Der empfohlene Ansatz beim Umstieg auf Azure Synapse besteht darin, die Datenextraktion und das Laden aus der Azure-Umgebung mithilfe von SSMA oder Data Factory zu orchestrieren. Verwenden Sie die zugehörigen Dienstprogramme wie PolyBase oder COPY INTO für das effizienteste Laden von Daten. Dieser Ansatz profitiert von integrierten Azure-Funktionen und reduziert den Aufwand zum Erstellen wiederverwendbarer Datenladepipelines. Sie können metadatengesteuerte Datenladepipelines verwenden, um den Migrationsprozess zu automatisieren.
Der empfohlene Ansatz minimiert auch die Leistungseinbußen in der vorhandenen Oracle-Umgebung während des Datenladeprozesses, da der Verwaltungs- und Ladeprozess in Azure ausgeführt wird.
Vorhandene Datenmigrationstools
Datentransformation und -bewegung ist die Grundfunktion aller ETL-Produkte. Wenn in der vorhandenen Oracle-Umgebung bereits ein Datenmigrationstool verwendet wird und Azure Synapse als Zielumgebung unterstützt, sollten Sie dieses Tool verwenden, um die Datenmigration zu vereinfachen.
Auch wenn kein bestehendes ETL-Tool vorhanden ist, bieten Azure Synapse Analytics-Datenintegrationspartner ETL-Tools an, um die Aufgabe der Datenmigration zu vereinfachen.
Wenn Sie schließlich planen, ein ETL-Tool zu verwenden, sollten Sie dieses Tool in der Azure-Umgebung ausführen, um die Leistung, Skalierbarkeit und Kosten der Azure-Cloud zu nutzen. Dieser Ansatz setzt auch Ressourcen im Oracle-Rechenzentrum frei.
Zusammenfassung
Zusammenfassend lauten unsere Empfehlungen für die Migration von Daten und zugehörigen ETL-Prozessen von Oracle zu Azure Synapse:
Planen Sie zur Gewährleistung einer erfolgreichen Migration voraus.
Verschaffen Sie sich einen umfassenden Überblick über die Daten und Prozesse, die so schnell wie möglich migriert werden müssen.
Verschaffen Sie sich anhand von Systemmetadaten und Protokolldateien einen umfassenden Überblick über die Nutzung von Daten und Prozessen. Verlassen Sie sich nicht auf die Dokumentation, da sie möglicherweise veraltet ist.
Verschaffen Sie sich einen Überblick über die zu migrierenden Datenmengen und die Netzwerkbandbreite zwischen dem lokalen Rechenzentrum und Azure-Cloudumgebungen.
Erwägen Sie die Verwendung einer Oracle-Instanz in einer Azure-VM als Sprungbrett für die Auslagerung der Migration aus der Legacy-Oracle-Umgebung.
Verwenden Sie standardmäßige integrierte Azure-Funktionen, um den Migrationsarbeitslast zu minimieren.
Identifizieren und verstehen Sie die effizientesten Tools zum Extrahieren und Laden von Daten in Oracle- und Azure-Umgebungen. Verwenden Sie in den einzelnen Phasen des Prozesses die jeweils geeigneten Tools.
Verwenden Sie Azure-Einrichtungen wie Data Factory, um den Migrationsprozess zu orchestrieren und zu automatisieren und gleichzeitig die Auswirkungen auf das Oracle-System zu minimieren.
Anhang: Beispiele für Techniken zum Extrahieren von Oracle-Daten
Sie können mehrere Techniken verwenden, um Oracle-Daten zu extrahieren, wenn Sie von Oracle zu Azure Synapse migrieren. In den nächsten Abschnitten wird gezeigt, wie Sie Oracle-Daten mit Oracle SQL Developer und dem Oracle-Connector in Data Factory extrahieren.
Oracle SQL Developer für die Datenextraktion verwenden
Sie können die Oracle SQL Developer-Benutzeroberfläche verwenden, um Tabellendaten in viele Formate, einschließlich CSV, zu exportieren, wie im folgenden Screenshot gezeigt:

Weitere Exportoptionen sind JSON und XML. Sie können die Benutzeroberfläche verwenden, um eine Reihe von Tabellennamen zu einem „Warenkorb“ hinzuzufügen, und dann den Export auf das gesamte Set im Warenkorb anwenden:

Sie können auch Oracle SQL Developer Command Line (SQLcl) verwenden, um Oracle-Daten zu exportieren. Diese Option unterstützt die Automatisierung mit einem Shell-Skript.
Bei relativ kleinen Tabellen ist diese Technik möglicherweise hilfreich, wenn Sie beim Extrahieren von Daten über eine direkte Verbindung auf Probleme stoßen.
Verwenden Sie den Oracle-Connector in Azure Data Factory für paralleles Kopieren
Sie können den Oracle-Connector in Data Factory verwenden, um große Oracle-Tabellen parallel zu entladen. Der Oracle-Connector stellt eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten aus Oracle zur Verfügung. Die Optionen für die Datenpartitionierung finden Sie auf der Registerkarte Quelle der Kopieraktivität.

Informationen zum Konfigurieren des Oracle-Connectors für paralleles Kopieren finden Sie unter Paralleles Kopieren von Oracle.
Weitere Informationen zur Leistung und Skalierbarkeit von Data Factory-Kopieraktivitäten finden Sie im Leitfaden zur Leistung und Skalierbarkeit von Copy-Aktivität.
Nächste Schritte
Weitere Informationen zu Sicherheitszugriffsvorgängen finden Sie im nächsten Artikel dieser Reihe: Sicherheit, Zugriff und Vorgänge für Oracle-Migrationen.