Sicherheit, Zugriff und Vorgänge für Teradata-Migrationen
Bei diesem Artikel handelt es sich um Teil 3 einer siebenteiligen Reihe, die einen Leitfaden zum Migrieren von Teradata zu Azure Synapse Analytics bereitstellt. In diesem Artikel werden schwerpunktmäßig bewährte Methoden für Sicherheit, Zugriff und Vorgänge behandelt.
Sicherheitshinweise
In diesem Artikel werden Verbindungsmethoden für vorhandene Teradata-Legacyumgebungen erläutert, und Sie erfahren, wie Sie diese Umgebungen mit minimalen Risiken und Auswirkungen auf Benutzer zu Azure Synapse Analytics migrieren können.
In diesem Artikel wird davon ausgegangen, dass die vorhandenen Verbindungsmethoden und die vorhandene Benutzer-, Rollen- und Berechtigungsstruktur unverändert migriert werden müssen. Ansonsten verwenden Sie das Azure-Portal, um ein neues Sicherheitsschema zu erstellen und zu verwalten.
Weitere Informationen zu den Optionen für die Azure Synapse-Sicherheit finden Sie im Whitepaper zur Sicherheit.
Verbindung und Authentifizierung
Autorisierungsoptionen von Teradata
Tipp
Sowohl in Teradata als auch in Azure Synapse kann die Authentifizierung „datenbankintern“ oder über externe Methoden erfolgen.
Teradata unterstützt mehrere Mechanismen für die Verbindung und Autorisierung. Folgende Werte für den Mechanismus sind gültig:
TD1: Teradata 1 wird als Authentifizierungsmechanismus ausgewählt. Benutzername und Kennwort sind erforderlich.
TD2: Teradata 2 wird als Authentifizierungsmechanismus ausgewählt. Benutzername und Kennwort sind erforderlich.
TDNEGO: Basierend auf der Richtlinie wird ohne Benutzereingriff automatisch einer der Authentifizierungsmechanismen ausgewählt.
LDAP: Das Lightweight Directory Access-Protokoll (LDAP) wird als Authentifizierungsmechanismus ausgewählt. Die Anwendung stellt den Benutzernamen und das Kennwort bereit.
KRB5: Kerberos (KRB5) wird auf Windows-Clients, die mit Windows-Servern arbeiten, ausgewählt. Zur Anmeldung mithilfe KRB5 muss der Benutzer eine Domäne, einen Benutzernamen und ein Kennwort angeben. Die Domäne wird durch Festlegen des Benutzernamens auf
MyUserName@MyDomainangegeben.NTLM: NTLM wird auf Windows-Clients, die mit Windows-Servern arbeiten, ausgewählt. Die Anwendung stellt den Benutzernamen und das Kennwort bereit.
Kerberos (KRB5), Kerberos-Kompatibilität (KRB5C), NT-LAN-Manager (NTLM) und NT-LAN-Manager-Kompatibilität (NTLMC) gelten nur für Windows.
Autorisierungsoptionen von Azure Synapse
Azure Synapse unterstützt zwei grundlegende Optionen für die Verbindung und Autorisierung:
SQL-Authentifizierung: Die SQL-Authentifizierung erfolgt über eine Datenbankverbindung, die einen Datenbankbezeichner, eine Benutzer-ID und ein Kennwort sowie andere optionale Parameter enthält. Dies entspricht funktionell TD1, TD2 und Standardverbindungen in Teradata.
Microsoft Entra-Authentifizierung: Mit der Microsoft Entra-Authentifizierung können Sie die Identitäten von Datenbankbenutzer*innen und anderen Microsoft-Diensten zentral an einem Ort verwalten. Die zentrale ID-Verwaltung bietet einen Ort, an dem die SQL Data Warehouse-Benutzer verwaltet werden und von vereinfacht die Berechtigungsverwaltung. Microsoft Entra ID kann auch Verbindungen mit LDAP- und Kerberos-Diensten unterstützen. Beispielsweise kann Microsoft Entra ID zum Herstellen einer Verbindung mit vorhandenen LDAP-Verzeichnissen verwendet werden, wenn diese nach der Migration der Datenbank beibehalten werden.
Benutzer, Rollen und Berechtigungen
Übersicht
Tipp
Für ein erfolgreiches Migrationsprojekt ist eine Planung auf hoher Ebene unerlässlich.
Sowohl Teradata als auch Azure Synapse implementieren die Zugriffssteuerung für Datenbanken über eine Kombination von Benutzern, Rollen und Berechtigungen. Beide Systeme verwenden die SQL-Standardanweisungen CREATE USER und CREATE ROLE zum Definieren von Benutzern und Rollen sowie GRANT- und REVOKE-Anweisungen zum Zuweisen oder Entfernen von Berechtigungen für diese Benutzer und/oder Rollen.
Tipp
Die Automatisierung von Migrationsprozessen wird empfohlen, um den Zeitaufwand und die Wahrscheinlichkeit von Fehlern zu reduzieren.
Konzeptionell ähneln sich die beiden Datenbanken, und es kann möglich sein, die Migration vorhandener Benutzer-IDs, Rollen und Berechtigungen zu einem gewissen Grad zu automatisieren. Migrieren Sie solche Daten, indem Sie die vorhandenen Informationen zu Benutzern und Rollen aus den Teradata-Systemkatalogtabellen extrahieren und entsprechende CREATE USER- und CREATE ROLE-Anweisungen generieren, die in Azure Synapse ausgeführt werden, um die gleiche Benutzer-/Rollenhierarchie neu zu erstellen.
Generieren Sie nach der Datenextraktion mithilfe der Teradata-Systemkatalogtabellen entsprechende GRANT-Anweisungen zum Zuweisen von Berechtigungen (sofern ein Äquivalent vorhanden ist). Das folgende Diagramm zeigt, wie vorhandene Metadaten zum Generieren der erforderlichen SQL-Anweisungen verwendet werden können.
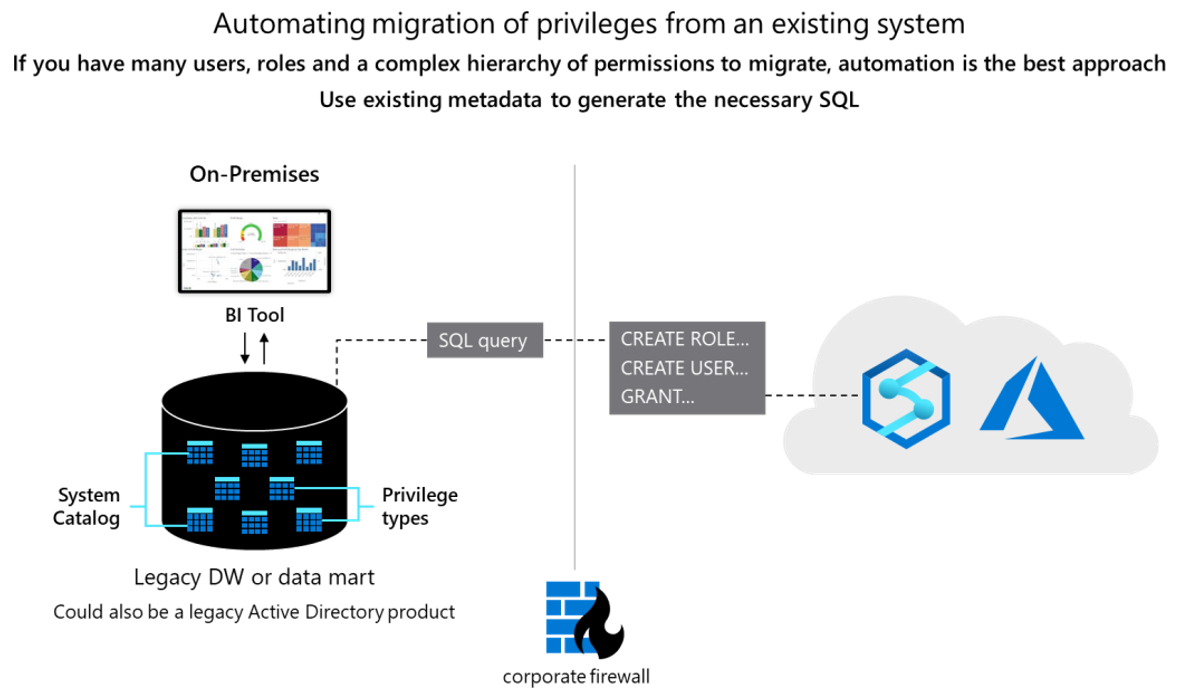
Benutzer und Rollen
Tipp
Die Migration eines Data Warehouse erfordert mehr als nur Tabellen, Ansichten und SQL-Anweisungen.
Die Informationen zu aktuellen Benutzern und Rollen in einem Teradata-System finden Sie in den Systemkatalogtabellen DBC.USERS (oder DBC.DATABASES) und DBC.ROLEMEMBERS. Fragen Sie diese Tabellen ab (wenn der Benutzer über SELECT-Zugriff auf diese Tabellen verfügt), um aktuelle Listen der im System definierten Benutzer und Rollen abzurufen. Mit den folgenden Beispielabfragen, können diese Informationen für einzelne Benutzer abgerufen werden:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
In diesen Beispielen werden SELECT-Anweisungen geändert, indem der entsprechende Text als Literal in die SELECT-Anweisung eingeschlossen wird, um ein Resultset zu generieren, bei dem es sich um eine Reihe von CREATE USER- und CREATE ROLE-Anweisungen handelt.
Das Abrufen vorhandener Kennwörter ist nicht möglich. Sie müssen daher ein Schema für die Zuordnung neuer anfänglicher Kennwörter in Azure Synapse implementieren.
Berechtigungen
Tipp
Für grundlegende Datenbankvorgänge wie Datenbearbeitungssprache (Data Manipulation Language, DML) und Datenbeschreibungssprache (Data Definition Language, DDL) sind entsprechende Azure Synapse-Berechtigungen verfügbar.
In einem Teradata-System enthalten die Systemtabellen DBC.ALLRIGHTS und DBC.ALLROLERIGHTS die Zugriffsrechte für Benutzer und Rollen. Fragen Sie diese Tabellen ab (wenn der Benutzer über SELECT-Zugriff auf diese Tabellen verfügt), um aktuelle Listen der im System definierten Zugriffsrechte abzurufen. Mit den folgenden Beispielabfragen, können Sie die Zugriffsrechte für einzelne Benutzer abrufen:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Ändern Sie diese SELECT-Beispielanweisungen, um ein Resultset zu generieren, das aus einer Reihe von GRANT-Anweisungen besteht, indem Sie den entsprechenden Text als Literal in die SELECT-Anweisung einfügen.
Der Joinschlüssel ist ein abgekürztes Typfeld. Suchen Sie daher in der Tabelle AccessRightsAbbv nach dem vollständigen Text des Zugriffsrechts. Die folgende Tabelle enthält eine Liste der Teradata-Zugriffsrechte und ihrer Entsprechungen in Azure Synapse.
| Name der Teradata-Berechtigung | Teradata-Typ | Azure Synapse-Äquivalent |
|---|---|---|
| ABORT SESSION | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREATE EXTERNALPROCEDURE | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | CM | CREATE PROCEDURE 2 |
| CREATE OWNER PROCEDURE | OP | CREATE PROCEDURE |
| CREATE PROCEDURE | PC | CREATE PROCEDURE |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | DO | DROP LOGIN 1 |
| DROP ROLE | DR | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| DUMP | DP | 4 |
| EXECUTE | E | Führen Sie |
| EXECUTE FUNCTION | EF | Führen Sie |
| EXECUTE PROCEDURE | PE | Führen Sie |
| GLOP MEMBER | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| OVERRIDE DUMP CONSTRAINT | OA | 4 |
| OVERRIDE RESTORE CONSTRAINT | oder | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| SHOW | SH | 3 |
| UPDATE | U | UPDATE |
Hinweise zur Tabelle AccessRightsAbbv:
PROFILEin Teradata entspricht funktionellLOGINin Azure Synapse.In der folgenden Tabelle finden Sie eine Zusammenfassung der Unterschiede zwischen Makros und gespeicherten Prozeduren in Teradata. In Azure Synapse stellen Prozeduren die in der Tabelle beschriebenen Funktionen bereit.
Makro Gespeicherte Prozedur Enthält SQL Enthält SQL Kann BTEQ-Punktbefehle enthalten Enthält umfassende SPL Kann übergebene Parameterwerte empfangen Kann übergebene Parameterwerte empfangen Kann eine oder mehrere Zeilen abrufen Erfordert die Verwendung eines Cursors, um mehr als eine Zeile abzurufen Gespeichert in DBC PERM Gespeichert in DATABASE oder USER PERM Gibt Zeilen an den Client zurück Kann einen oder mehrere Werte als Parameter an den Client zurückgeben Für
SHOW,GLOPundTRIGGERgibt es kein direktes Äquivalent in Azure Synapse.Diese Features werden in Azure Synapse automatisch vom System verwaltet. Weitere Informationen finden Sie in den Überlegungen zum Betrieb.
In Azure Synapse werden diese Features außerhalb der Datenbank behandelt.
Weitere Informationen zu Zugriffsrechten in Azure Synapse finden Sie unter Azure Synapse Analytics-Sicherheitsberechtigungen.
Überlegungen zur Verwendung
Tipp
Bei jedem Data Warehouse sind für den effizienten Betrieb operative Aufgaben erforderlich.
In diesem Abschnitt wird erläutert, wie Sie typische operative Teradata-Aufgaben mit minimalen Risiken und Auswirkungen auf Benutzer in Azure Synapse implementieren.
Wie bei allen Data Warehouse-Produkten sind bei der Verwendung in der Produktion laufende Verwaltungsaufgaben erforderlich, um den effizienten Betrieb des Systems aufrechtzuerhalten und Daten für die Überwachung und Überprüfung bereitzustellen. Die Ressourcenverwendung und Kapazitätsplanung für zukünftiges Wachstum fällt wie die Sicherung/Wiederherstellung von Daten ebenfalls in diese Kategorie.
Obwohl sich die Verwaltungsaufgaben und operativen Aufgaben verschiedener Data Warehouses ähneln, können sich die einzelnen Implementierungen unterscheiden. Moderne cloudbasierte Produkte wie Azure Synapse beruhen meist auf einem Ansatz mit umfassender Automatisierung und „systemseitiger Verwaltung“ (im Gegensatz zum eher „manuellen“ Ansatz bei Legacy-Data Warehouses wie Teradata).
In den folgenden Abschnitten werden die Teradata- und Azure Synapse-Optionen für verschiedene operative Aufgaben verglichen.
Housekeepingaufgaben
Tipp
Housekeepingaufgaben sorgen dafür, dass ein Data Warehouse in der Produktion effizient funktioniert, und optimieren die Verwendung von Ressourcen wie z. B. Speicher.
In den meisten Data Warehouse-Legacyumgebungen müssen regelmäßige „Housekeepingaufgaben“ ausgeführt werden, wie z. B. das Freigeben von Speicherplatz durch Entfernen alter Versionen von aktualisierten oder gelöschten Zeilen oder das Neuorganisieren von Datenprotokolldateien oder Indexblöcken zum Verbessern der Effizienz. Eine weitere potenziell zeitaufwendige Aufgabe ist das Sammeln von Statistiken. Das Sammeln von Statistiken ist nach einer Massendatenerfassung erforderlich, um für den Abfrageoptimierer aktuelle Daten zur Basisgenerierung von Abfrageausführungsplänen bereitzustellen.
Teradata empfiehlt, zum Sammeln von Statistiken wie folgt vorzugehen:
Sammeln Sie Statistiken für nicht aufgefüllte Tabellen, um das Intervallhistogramm einzurichten, das bei der internen Verarbeitung verwendet wird. Durch diese anfängliche Erfassung wird der Zeitaufwand für nachfolgende Statistikerfassungen reduziert. Stellen Sie sicher, dass nach dem Hinzufügen von Daten erneut Statistiken erfasst werden.
Erfassen Sie in der Prototypphase Statistiken für neu aufgefüllte Tabellen.
Erfassen Sie in der Produktionsphase Statistiken, nachdem eine signifikante prozentuale Änderung an der Tabelle oder Partition vorgenommen wurde (~10 % der Zeilen). Bei einer großen Anzahl nicht eindeutiger Werte (z. B. Datumsangaben oder Zeitstempel), kann es von Vorteil sein, bei 7 % erneut eine Sammlung durchzuführen.
Erfassen Sie Statistiken in der Produktionsphase, nachdem Sie Benutzer erstellt und realistische Abfragelasten für die Datenbank ausgeführt haben (Abfragen von bis zu drei Monaten).
Sammeln Sie Statistiken in den ersten Wochen nach einem Upgrade oder einer Migration in Zeiträumen mit geringer CPU-Auslastung.
Die Statistiksammlung kann manuell mithilfe von offenen APIs für die automatisierte Statistikverwaltung oder automatisch mithilfe des Portlets „Teradata Viewpoint Stats Manager“ verwaltet werden.
Tipp
Automatisieren und überwachen Sie Housekeepingaufgaben in Azure.
Die Teradata-Datenbank enthält viele Protokolltabellen im Datenwörterbuch, die Daten automatisch oder nach dem Aktivieren bestimmter Features sammeln. Da Protokolldaten im Laufe der Zeit an Umfang zunehmen, sollten Sie ältere Informationen löschen, damit sie nicht permanent Speicherplatz belegen. Zum Automatisieren der Verwaltung dieser Protokolle stehen verschiedene Optionen zur Verfügung. Die Teradata-Wörterbuchtabellen, die verwaltet werden müssen, werden im Folgenden erläutert.
Wörterbuchtabellen, die verwaltet werden müssen
Setzen Sie Akkumulatoren und Spitzenwerte mithilfe der Ansicht DBC.AMPUsage und des Makros ClearPeakDisk der Software zurück:
DBC.Acctg: Ressourcenverwendung nach Konto/BenutzerDBC.DataBaseSpace: Nachverfolgung des Datenbank- und Tabellenspeicherplatzes
Teradata verwaltet diese Tabellen automatisch, durch geeignete Methoden kann ihre Größe jedoch verringert werden:
DBC.AccessRights: Benutzerrechte für ObjekteDBC.RoleGrants: Rollenrechte für ObjekteDBC.Roles: Definierte RollenDBC.Accounts: Kontocodes nach Benutzer
Archivieren Sie diese Protokollierungstabellen (falls gewünscht), und löschen Sie Informationen nach 60 bis 90 Tagen. Die Aufbewahrung richtet sich nach den Kundenanforderungen:
DBC.SW_Event_Log: Protokoll der DatenbankkonsoleDBC.ResUsage: Tabellen zur RessourcenüberwachungDBC.EventLog: Verlauf der Sitzungsanmeldungen/-abmeldungenDBC.AccLogTbl: Protokollierte Benutzer-/ObjektereignisseDBC.DBQL tables: Protokollierte Benutzer-/SQL-Aktivitäten.NETSecPolicyLogTbl: Protokollierung von dynamischen Überwachungspfaden für Sicherheitsrichtlinien.NETSecPolicyLogRuleTbl: Steuert, wann und wie dynamische Sicherheitsrichtlinien protokolliert werden
Bereinigen Sie diese Tabellen, wenn die zugeordneten Wechselmedien abgelaufen sind und überschrieben werden:
DBC.RCEvent: Archivierungs-/WiederherstellungsereignisseDBC.RCConfiguration: Archivierungs-/WiederherstellungskonfigurationDBC.RCMedia: VolSerial für Archivierung/Wiederherstellung
Azure Synapse bietet eine Option zum automatischen Erstellen von Statistiken, sodass diese bei Bedarf verfügbar sind. Führen Sie die Defragmentierung von Indizes und Datenblöcken manuell, nach einem Zeitplan oder automatisch aus. Durch die Nutzung nativer integrierter Azure-Funktionen kann der erforderliche Aufwand für eine Migration reduziert werden.
Überwachung und Überprüfung
Tipp
Im Laufe der Zeit wurden verschiedene Tools implementiert, die die Überwachung und Protokollierung von Teradata-Systemen ermöglichen.
Teradata bietet mehrere Tools zum Überwachen des Betriebs, darunter Teradata Viewpoint und Ecosystem Manager. Für die Protokollierung des Abfrageverlaufs bietet das Datenbankabfrageprotokoll (Database Query Log, DBQL), ein Datenbankfeature von Teradata, eine Reihe vordefinierter Tabellen, in denen Verlaufsdatensätze von Abfragen sowie deren Dauer, Leistung und Zielaktivität basierend auf benutzerdefinierten Regeln gespeichert werden können.
Datenbankadministratoren können Teradata Viewpoint verwenden, um den Systemstatus, Trends und den Status einzelner Abfragen zu ermitteln. Durch die Beobachtung von Trends in der Systemnutzung können Systemadministratoren Projektimplementierungen, Batchaufträge und Wartungsaufgaben besser planen und bei deren Ausführung Spitzenauslastungszeiten vermeiden. Geschäftsbenutzer können mithilfe von Teradata Viewpoint schnell auf den Status von Berichten und Abfragen zugreifen und einen Drilldown in Details ausführen.
Tipp
Das Azure-Portal bietet eine Benutzeroberfläche zum Verwalten von Überwachungs- und Überprüfungsaufgaben für alle Azure-Daten und -Prozesse.
Für Azure Synapse ist im Azure-Portal eine vergleichbare Benutzeroberfläche mit umfassenden Funktionen für die Überwachung verfügbar, die Erkenntnisse zur Arbeitsauslastung Ihres Data Warehouse liefert. Das Azure-Portal ist das empfohlene Tool zum Überwachen Ihrer Data Warehouse-Instanz, weil es eine konfigurierbare Aufbewahrungsdauer, Warnungen, Empfehlungen und anpassbare Diagramme und Dashboards für Metriken und Protokolle bietet.
Das Portal ermöglicht außerdem die Integration weiterer Azure-Überwachungsdienste – z.B. Operations Management Suite (OMS) und Azure Monitor (Protokolle) –, um Ihnen nicht nur für das Data Warehouse, sondern für die gesamte Azure-Analyseplattform eine ganzheitliche und integrierte Überwachungsoberfläche bereitzustellen.
Tipp
Metriken auf niedriger Ebene und systemweite Metriken werden in Azure Synapse automatisch protokolliert.
Statistiken zur Ressourcenverwendung für Azure Synapse werden automatisch im System protokolliert. Die Metriken für die einzelnen Abfragen enthalten Verwendungsstatistiken für CPU, Arbeitsspeicher, Cache, E/A und temporäre Arbeitsbereiche sowie Verbindungsinformationen (z. B. Fehler bei Verbindungsversuchen).
Azure Synapse bietet eine Reihe von dynamischen Verwaltungssichten (Dynamic Management View, DMV). Diese Sichten sind nützlich für die aktive Problembehandlung und das Identifizieren von Leistungsengpässen in Ihrer Workload.
Weitere Informationen finden Sie unter Optionen für Vorgänge und die Verwaltung in Azure Synapse.
Hochverfügbarkeit und Notfallwiederherstellung
Teradata implementiert Features wie FALLBACK, das Hilfsprogramm Archive Restore Copy (ARC) und Data Stream Architecture (DSA), um durch Replikation und Archivierung von Daten Schutz vor Datenverlust zu bieten und Hochverfügbarkeit bereitzustellen. Zu den Optionen für die Notfallwiederherstellung (Disaster Recovery, DR) zählen je nach Anforderungen bezüglich der Wiederherstellungszeit Dual Active Solution, DR-as-a-Service oder ein Ersatzsystem.
Tipp
Azure Synapse erstellt automatisch Momentaufnahmen, um eine schnelle Wiederherstellung sicherzustellen.
Azure Synapse verwendet Datenbankmomentaufnahmen, um die Hochverfügbarkeit des Data Warehouse zu gewährleisten. Mit einer Data Warehouse-Momentaufnahme wird ein Wiederherstellungspunkt erstellt, mit dessen Hilfe ein vorheriger Zustand eines Data Warehouse wiederhergestellt oder kopiert werden kann. Da Azure Synapse ein verteiltes System ist, besteht eine Data Warehouse-Momentaufnahme aus zahlreichen Dateien, die in Azure Storage gespeichert sind. Momentaufnahmen erfassen inkrementelle Änderungen der Daten, die in Ihrem Data Warehouse gespeichert sind.
Azure Synapse erstellt im Lauf des Tages automatisch Momentaufnahmen, und die generierten Wiederherstellungspunkte sind für sieben Tage verfügbar. Dieser Aufbewahrungszeitraum kann nicht geändert werden. Azure Synapse unterstützt eine Recovery Point Objective (RPO) von acht Stunden. Ein Data Warehouse kann in der primären Region anhand einer beliebigen Momentaufnahme wiederhergestellt werden, die in den vergangenen sieben Tagen erstellt wurde.
Tipp
Verwenden Sie benutzerdefinierte Momentaufnahmen, um vor wichtigen Updates einen Wiederherstellungspunkt zu definieren.
Es werden auch benutzerdefinierte Wiederherstellungspunkte unterstützt, sodass Momentaufnahmen manuell ausgelöst werden können, um Wiederherstellungspunkte eines Data Warehouse vor und nach großen Änderungen zu erstellen. Diese Funktion gewährleistet die logische Konsistenz von Wiederherstellungspunkten und sorgt somit bei Workloadunterbrechungen oder Benutzerfehlern für zusätzlichen Datenschutz und die gewünschte RPO von weniger als acht Stunden.
Tipp
Für die Notfallwiederherstellung bietet Microsoft Azure automatische Sicherungen an einem separaten geografischen Standort.
Zusätzlich zu den oben beschriebenen Momentaufnahmen führt Azure Synapse auch standardmäßig einmal pro Tag eine Geosicherung in einem gekoppelten Rechenzentrum aus. Die RPO für eine Geowiederherstellung beträgt 24 Stunden. Sie können die Geosicherung auf einem Server in einer beliebigen anderen Region wiederherstellen, in der Azure Synapse unterstützt wird. Durch eine Geosicherung wird gewährleistet, dass ein Data Warehouse wiederhergestellt werden kann, falls die Wiederherstellungspunkte in der primären Region nicht verfügbar sind.
Verwalten von Arbeitsauslastungen
Tipp
In einem Data Warehouse in der Produktion gibt es in der Regel gemischte Workloads mit unterschiedlichen, gleichzeitig ausgeführten Ressourcenverwendungseigenschaften.
Eine Workload ist eine Klasse von Datenbankanforderungen mit gemeinsamen Merkmalen, deren Zugriff auf die Datenbank mit einer Reihe von Regeln verwaltet werden kann. Workloads eignen sich für folgende Zwecke:
Festlegen verschiedener Zugriffsprioritäten für unterschiedliche Anforderungstypen
Überwachen von Ressourcenverwendungsmustern, Leistungsoptimierung und Kapazitätsplanung
Einschränken der Anzahl von Anforderungen oder Sitzungen, die gleichzeitig ausgeführt werden können
In einem Teradata-System ist unter der Workloadverwaltung das Verwalten der Workloadleistung durch Überwachen der Systemaktivität und Ergreifen geeigneter Maßnahmen beim Erreichen vordefinierter Grenzwerte zu verstehen. Bei der Workloadverwaltung werden Regeln verwendet, und jede Regel gilt nur für einige Datenbankanforderungen. Die Sammlung aller Regeln gilt jedoch für alle aktiven Aufgaben auf der Plattform. Teradata Active System Management (TASM) führt die gesamte Workloadverwaltung in einer Teradata-Datenbank aus.
In Azure Synapse sind Ressourcenklassen vorab festgelegte Ressourcengrenzwerte, die Computeressourcen und die Parallelität für die Abfrageausführung regeln. Ressourcenklassen können Sie bei der Verwaltung Ihrer Workload unterstützen, da sie es Ihnen ermöglichen, Limits für die Anzahl gleichzeitig ausgeführter Abfragen und für Computeressourcen festzulegen, die den einzelnen Abfragen zugewiesen werden. Dabei erfolgt ein Ausgleich zwischen Speicher und Parallelität.
Azure Synapse protokolliert Ressourcenauslastungsstatistiken automatisch. Zu den Metriken gehören Nutzungsstatistiken für CPU, Arbeitsspeicher, Cache, E/A und temporären Arbeitsbereich für jede Abfrage. Azure Synapse protokolliert auch Verbindungsinformationen, z. B. fehlgeschlagene Verbindungsversuche.
Tipp
Metriken auf niedriger Ebene und systemweite Metriken werden in Azure automatisch protokolliert.
Azure Synapse unterstützt diese grundlegenden Workloadverwaltungskonzepte:
Workloadklassifizierung: Sie können eine Anforderung einer Workloadgruppe zuweisen, um Wichtigkeitsstufen festzulegen.
Workloadpriorität: Sie können die Reihenfolge beeinflussen, in der eine Anforderung Zugriff auf Ressourcen erhält. Standardmäßig werden Abfragen nach dem First-In-First-Out-Prinzip aus der Warteschlange freigegeben, wenn Ressourcen verfügbar werden. Die Workloadpriorität ermöglicht es Abfragen mit höherer Priorität, Ressourcen unabhängig von der Warteschlange sofort zu erhalten.
Workloadisolation: Sie können Ressourcen für eine Workloadgruppe reservieren, eine maximale und minimale Nutzung für unterschiedliche Ressourcen zuweisen, die Ressourcen begrenzen, die eine Gruppe von Anforderungen verbrauchen kann, und einen Zeitüberschreitungswert festlegen, um außer Kontrolle geratene Abfragen automatisch zu beenden.
Das Ausführen gemischter Workloads kann bei ausgelasteten Systemen zu Ressourcenproblemen führen. Mit einem erfolgreichen Schema Workloadverwaltung werden Ressourcen effektiv verwaltet, wird eine hochgradig effiziente Ressourcennutzung sichergestellt und die Rendite (ROI) maximiert. Die Workloadklassifizierung, die Workloadpriorität und die Workloadisolation bieten mehr Kontrolle darüber, wie die Workload Systemressourcen nutzt.
Im Workload Management Guide (Handbuch zur Workloadverwaltung) werden die Techniken zur Analyse der Workload, der Verwaltung und Überwachung der Workloadpriorität](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) sowie die Schritte zum Konvertieren einer Ressourcenklasse in eine Workloadgruppe beschrieben. Verwenden Sie das Azure-Portal und T-SQL-Abfragen auf DMVs, um die Workload zu überwachen und sicherzustellen, dass die entsprechenden Ressourcen effizient genutzt werden. Azure Synapse stellt eine Reihe von dynamischen Verwaltungssichten (Dynamic Management Views, DMVs) bereit, um alle Aspekte der Workloadverwaltung zu überwachen. Diese Sichten sind nützlich für die aktive Problembehandlung und die Identifizierung von Leistungsengpässen in Ihrer Workload.
Diese Informationen können auch für die Kapazitätsplanung verwendet werden, um die erforderlichen Ressourcen für zusätzliche Benutzer oder Anwendungsworkloads zu ermitteln. Dies gilt auch für die Planung des Hoch- und Herunterskalierens von Computeressourcen, um Workloads mit Auslastungsspitzen kosteneffizient zu unterstützen.
Weitere Informationen zur Workloadverwaltung in Azure Synapse finden Sie unter Workloadverwaltung mit Ressourcenklassen.
Skalieren von Computeressourcen
Tipp
Ein großer Vorteil von Azure ist die Möglichkeit, Ressourcen nach Bedarf separat hoch- und herunterzuskalieren, um die Kosten für Workloads mit Auslastungsspitzen zu optimieren.
In der Architektur von Azure Synapse sind Speicher- und Computeressourcen voneinander getrennt, sodass sie unabhängig voneinander skaliert werden können. Dies ermöglicht die Skalierung von Computeressourcen, um Leistungsanforderungen unabhängig vom Datenspeicher zu erfüllen. Sie können Computeressourcen auch anhalten und fortsetzen. Ein logischer Vorteil dieser Architektur ist die separate Abrechnung für Compute- und Speicherressourcen. Wenn ein Data Warehouse nicht verwendet wird, können Sie Computekosten sparen, indem Sie Computeressourcen anhalten.
Computeressourcen können durch Anpassen der Einstellung für die Data Warehouse-Einheiten des Data Warehouse hoch- oder herunterskaliert werden. Die Lade- und Abfrageleistung nimmt linear zu, wenn Sie Data Warehouse-Einheiten hinzufügen.
Durch das Hinzufügen weiterer Computeknoten werden die Computeleistung und die Möglichkeiten zur Nutzung der Parallelverarbeitung erhöht. Mit zunehmender Anzahl von Computeknoten verringert sich die Anzahl von Verteilungen pro Computeknoten, sodass für Abfragen mehr Computeleistung und mehr Kapazität für die Parallelverarbeitung verfügbar ist. Entsprechend sinkt bei einer Verringerung der Data Warehouse-Einheiten die Anzahl von Computeknoten und in der Folge die Menge an Computeressourcen für Abfragen.
Nächste Schritte
Weitere Informationen zur Visualisierung und Berichterstellung finden Sie im nächsten Artikel dieser Reihe: Visualisierung und Berichterstellung für Teradata-Migrationen