Installieren und Konfigurieren von SAP HANA in Azure (große Instanzen)
In diesem Artikel wird die Überprüfung, Konfiguration und Installation von SAP HANA (große Instanzen) in Azure (sogenannte BareMetal-Infrastruktur) beschrieben.
Voraussetzungen
Bevor Sie diesen Artikel lesen, sollten Sie sich mit folgenden Themen vertraut machen:
Siehe auch:
- Verbinden von Azure-VMs mit HANA (große Instanzen)
- Verbinden eines virtuellen Netzwerks mit HANA (große Instanzen)
Planen der Installation
Für die Installation von SAP HANA sind Sie zuständig. Sie können mit dem Installieren eines neuen Servers für SAP HANA in Azure (große Instanzen) beginnen, nachdem Sie die Konnektivität zwischen Ihren virtuellen Azure-Netzwerken und den HANA-Einheiten (große Instanzen) eingerichtet haben.
Hinweis
Gemäß einer SAP-Richtlinie muss die Installation von SAP HANA durch eine Person durchgeführt werden, die die Prüfung „Certified SAP Technology Associate“ oder die Zertifizierungsprüfung „SAP HANA Installation“ bestanden hat oder ein von SAP zertifizierter Systemintegrator (SI) ist.
Wenn Sie planen, HANA 2.0 zu installieren, sollten Sie SAP Support Note #2235581 – SAP HANA: Supported operating systems lesen. Vergewissern Sie sich, dass das SAP HANA-Release, das Sie installieren möchten, von Ihrem Betriebssystem unterstützt wird. Das unterstützte Betriebssystem für HANA 2.0 ist stärker eingeschränkt als das Betriebssystem, das für HANA 1.0 unterstützt wird. Vergewissern Sie sich, dass das Betriebssystemrelease, für das Sie sich interessieren, für die bestimmte Instanz von SAP HANA (große Instanzen) unterstützt wird. Verwenden Sie dazu diese Liste. Wählen Sie eine Instanz von SAP HANA (große Instanzen) aus, um die Liste der dafür unterstützten Betriebssysteme anzuzeigen.
Überprüfen Sie Folgendes, bevor Sie mit der Installation von HANA beginnen:
Validieren der HANA-Einheiten (große Instanzen)
Nachdem Sie Ihre Instanzen von SAP HANA (große Instanzen) von Microsoft erhalten haben, stellen Sie Zugriff und Konnektivität her. Überprüfen Sie dann die folgenden Einstellungen, und passen Sie sie nach Bedarf an.
Überprüfen Sie im Azure-Portal, ob die Instanzen mit den richtigen SKUs und dem richtigen Betriebssystem angezeigt werden. Weitere Informationen finden Sie unter Steuerung von SAP HANA in Azure (große Instanzen) über das Azure-Portal.
Registrieren Sie das Betriebssystem der Instanz bei Ihrem Betriebssystemanbieter. Zu diesem Schritt gehört die Registrierung Ihres SUSE Linux-Betriebssystems in einer Instanz des SUSE Subscription Management Tools (SMT), die auf einer Azure-VM bereitgestellt wurde.
Die Instanz von SAP HANA (große Instanzen) kann eine Verbindung zu dieser SMT-Instanz herstellen. (Weitere Informationen finden Sie unter Einrichten eines SMT-Servers für SUSE Linux.) Wenn Sie ein Red Hat-Betriebssystem verwenden, muss dieses bei dem Red Hat Subscription Manager registriert werden, mit dem Sie eine Verbindung herstellen werden. Weitere Informationen finden Sie unter Was ist SAP HANA in Azure (große Instanzen)?.
Dieser Schritt ist auch zum Patchen des Betriebssystems notwendig, was in Ihren Zuständigkeitsbereich fällt. Informationen zu SUSE finden Sie in der Dokumentation zum Installieren und Konfigurieren von SMT.
Suchen Sie nach neuen Patches und Fixes für das spezielle Release oder die spezielle Version des Betriebssystems. Vergewissern Sie sich, dass die Instanz von SAP HANA (große Instanzen) über die neuesten Patches verfügt. Manchmal sind die neuesten Patches nicht enthalten. Führen Sie daher unbedingt eine Überprüfung durch.
Lesen Sie die relevanten SAP-Hinweise (SAP Notes) zur Installation und Konfiguration von SAP HANA unter dem speziellen Release oder der speziellen Version des Betriebssystems. Microsoft führt nicht immer eine vollständige Konfiguration einer Instanz von SAP HANA (große Instanzen) durch. Änderungen an Empfehlungen, SAP-Hinweisen oder Konfigurationen, die von den jeweiligen Szenarios abhängen, können dies unmöglich machen.
Lesen Sie daher unbedingt die SAP-Hinweise zu SAP HANA für Ihr bestimmtes Linux-Release. Prüfen Sie außerdem die Konfigurationen der Betriebssystemversion, und wenden Sie die Konfigurationseinstellungen an, falls dies nicht bereits geschehen ist.
Prüfen Sie insbesondere die folgenden Parameter, und passen Sie diese ggf. an:
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
- net.core.rmem_default = 16777216
- net.core.wmem_default = 16777216
- net.core.optmem_max = 16777216
- net.ipv4.tcp_rmem = 65536 16777216 16777216
- net.ipv4.tcp_wmem = 65536 16777216 16777216
Seit SLES12 SP1 und Red Hat Enterprise Linux 7.2 (RHEL) müssen diese Parameter in einer Konfigurationsdatei festgelegt sein, die sich im Verzeichnis „/etc/sysctl.d“ befindet. Beispielsweise muss eine Konfigurationsdatei namens „91-NetApp-HANA.conf“ erstellt werden. Für ältere SLES- und RHEL-Versionen müssen diese Parameter in „/etc/sysctl.conf“ festgelegt sein.
Beachten Sie bei allen RHEL-Versionen ab RHEL 6.3 Folgendes:
- Der Parameter „sunrpc.tcp_slot_table_entries = 128“ muss auf „in/etc/modprobe.d/sunrpc-local.conf“ festgelegt sein. Wenn die Datei nicht vorhanden ist, erstellen Sie sie zuerst, indem Sie den Eintrag hinzufügen:
- options sunrpc tcp_max_slot_table_entries=128
Prüfen Sie die Systemzeit Ihrer Instanz von SAP HANA (große Instanzen). Die Instanzen werden mit einer Systemzeitzone bereitgestellt. Diese Zeitzone repräsentiert den Standort der Azure-Region, in der sich der Stempel für die große HANA-Instanz befindet. Sie können die Systemzeit oder Zeitzone der Instanzen ändern, deren Besitzer Sie sind.
Wenn Sie weitere Instanzen in Ihrem Mandanten bestellen, müssen Sie die Zeitzone der neu bereitgestellten Instanzen anpassen. Microsoft hat keinen Einblick in die Systemzeitzone, die Sie nach der Übergabe für die Instanzen einrichten. Daher kann es sein, dass neu bereitgestellte Instanzen nicht mit der Zeitzone eingerichtet sind, zu der Sie gewechselt haben. Es liegt an Ihnen, die Zeitzone der übergebenen Instanzen nach Bedarf anzupassen.
Überprüfen Sie die Datei „etc/hosts“. Wenn Bladeserver übergeben werden, haben diese unterschiedliche IP-Adressen, die unterschiedlichen Zwecken zugeordnet sind. Es ist wichtig, die Datei „etc/hosts“ zu überprüfen, wenn Instanzen zu einem bestehenden Mandanten hinzugefügt werden. Die Datei „etc/hosts“ der neu bereitgestellten Systeme wird möglicherweise nicht ordnungsgemäß mit den IP-Adressen der zuvor ausgelieferten Systeme verwaltet. Stellen Sie sicher, dass eine neu bereitgestellte Instanz die Namen von zuvor in Ihrem Mandanten bereitgestellten Instanzen auflösen kann.
Betriebssystem
Der Auslagerungsbereich des bereitgestellten Betriebssystemimage ist gemäß SAP Support Note #1999997 – FAQ: SAP HANA Memory (SAP-Supporthinweis #1999997 – FAQ: SAP HANA-Arbeitsspeicher) auf 2 GB festgelegt. Wenn Sie eine andere Einstellung möchten, müssen Sie diese selbst festlegen.
SUSE Linux Enterprise Server 12 SP1 for SAP Applications ist die Distribution von Linux, die für SAP HANA in Azure (große Instanzen) installiert wird. Diese Distribution bietet SAP-spezifische Funktionen, einschließlich vorab festgelegter Parameter für die effektive Ausführung von SAP unter SLES.
Nützliche Ressourcen zur Bereitstellung von SAP HANA unter SLES:
- Ressourcenbibliothek/Whitepaper auf der SUSE-Website
- SAP unter SUSE im SAP Community Network (SCN)
Diese Ressourcen enthalten Informationen zum Einrichten von Hochverfügbarkeit, zur Sicherheitshärtung speziell für SAP-Vorgänge und mehr.
Weitere Ressourcen für SAP unter SUSE:
- Website zu SAP HANA unter SUSE Linux (in englischer Sprache)
- Best Practice for SAP: Enqueue replication – SAP NetWeaver on SUSE Linux Enterprise 12
- ClamSAP – SLES Virus Protection for SAP (einschließlich SLES 12 für SAP-Anwendungen)
SAP-Supporthinweise zur Implementierung von SAP HANA unter SLES 12:
- SAP Support Note #1944799 – SAP HANA Guidelines for SLES Operating System Installation (SAP-Supporthinweis 1944799 – SAP HANA-Richtlinien für die Installation des SLES-Betriebssystems)
- SAP Support Note #2205917 – SAP HANA DB Recommended OS Settings for SLES 12 for SAP Applications (SAP-Supporthinweis 2205917 – SAP HANA DB: Empfohlene Betriebssystemeinstellungen für SLES 12 für SAP-Anwendungen)
- SAP Support Note #1984787 – SUSE Linux Enterprise Server 12: Installation Notes (SAP-Supporthinweis 1984787 – SUSE Linux Enterprise Server 12: Installationshinweise)
- SAP Support Note #171356 – SAP Software on Linux: General Information (SAP-Supporthinweis 171356 – SAP-Software unter Linux: allgemeine Informationen)
- SAP Support Note #1391070 – Linux UUID Solutions (SAP-Supporthinweis 1391070 – Linux UUID-Lösungen)
Red Hat Enterprise Linux für SAP HANA ist ein weiteres Angebot zum Ausführen von SAP HANA auf großen SAP HANA-Instanzen. Releases von RHEL 7.2 und 7.3 sind verfügbar und werden unterstützt. Weitere Informationen zu SAP unter Red Hat finden Sie auf der Website zu SAP HANA unter Red Hat Linux.
SAP-Supporthinweise zur Implementierung von SAP HANA unter Red Hat:
- SAP Support Note #2009879 – SAP HANA Guidelines for Red Hat Enterprise Linux (RHEL) Operating System (SAP-Supporthinweis 2009879 – SAP HANA-Richtlinien für das RHEL-Betriebssystem [Red Hat Enterprise Linux])
- SAP support note #2292690 - SAP HANA DB: Recommended OS Settings for RHEL 7 (2292690 – SAP HANA DB: empfohlene Betriebssystemeinstellungen für RHEL 7)
- SAP Support Note #1391070 – Linux UUID Solutions (SAP-Supporthinweis 1391070 – Linux UUID-Lösungen)
- SAP support note #2228351 - Linux: SAP HANA Database SPS 110 revision 6 (or higher) on RHEL 11 or SLES 11 (SAP-Supporthinweis 2228351 – Linux: SAP HANA-Datenbank SPS 11 Revision 110 (oder höher) unter RHEL 6 oder SLES 11)
- SAP support note #2397039 - FAQ: SAP on RHEL (SAP-Supporthinweis 2397039 – Häufig gestellte Fragen: SAP unter RHEL)
- SAP support note #2002167 - Red Hat Enterprise Linux 7.x: Installation and upgrade (SAP-Supporthinweis 2002167 – Red Hat Enterprise Linux 7.x: Installation und Upgrade)
Zeitsynchronisierung
SAP-Anwendungen, die auf Basis der SAP NetWeaver-Architektur erstellt werden, reagieren sehr empfindlich auf Zeitunterschiede zwischen den verschiedenen Komponenten des SAP-Systems. SAP ABAP-Kurzdumps mit der Fehlerbezeichnung „ZDATE_LARGE_TIME_DIFF“ sind Ihnen möglicherweise bekannt. Das liegt daran, dass diese kurzen Speicherabbilder angefertigt werden, wenn die Systemzeiten verschiedener Server oder VMs zu stark voneinander abweichen.
Für Compute-Einheiten in Stempeln von SAP HANA in Azure (große Instanzen) gilt nicht die Zeitsynchronisierung in Azure. Sie gilt auch nicht für SAP-Anwendungen, die auf nativen Azure-VMs ausgeführt werden, da Azure sicherstellt, dass die Uhrzeit eines Systems richtig synchronisiert wird.
Daher müssen Sie einen separaten Zeitserver einrichten. Dieser Server wird von SAP-Anwendungsservern verwendet, die auf Azure-VMs ausgeführt werden. Er wird auch von den SAP HANA-Datenbankinstanzen verwendet, die auf Instanzen von SAP HANA (große Instanzen) ausgeführt werden. Der Speicherinfrastruktur in Stempeln von SAP HANA (große Instanzen) wird mit Network Time Protocol-Servern (NTP) zeitlich synchronisiert.
Netzwerk
Beim Entwerfen Ihrer virtuellen Azure-Netzwerke und Verbinden dieser virtuellen Netzwerke mit SAP HANA (große Instanzen) sollten Sie darauf achten, die folgenden Empfehlungen einzuhalten:
- Übersicht und Architektur von SAP HANA in Azure (große Instanzen)
- Infrastruktur und Verbindungen mit SAP HANA in Azure (große Instanzen)
Es gibt einige Details zum Netzwerkbetrieb der einzelnen Einheiten, die Sie kennen sollten. Jede Einheit von SAP HANA (große Instanzen) wird mit zwei oder drei IP-Adressen geliefert, die zwei oder drei Netzwerkanschlussports zugewiesen sind. Drei IP-Adressen werden in HANA-Konfigurationen für die horizontale Skalierung und im Szenario für die HANA-Systemreplikation verwendet. Eine der IP-Adressen, die dem Netzwerkanschluss der Einheit zugewiesen sind, stammt aus dem Server-IP-Pool, der in Übersicht und Architektur von SAP HANA in Azure (große Instanzen) beschrieben ist.
Weitere Informationen zu den Ethernet-Details für Ihre Architektur finden Sie unter Unterstützte Szenarios für SAP HANA (große Instanzen).
Speicher
Das Speicherlayout für SAP HANA (große Instanzen) wird von SAP HANA in der Azure-Dienstverwaltung auf Basis der von SAP empfohlenen Richtlinien konfiguriert.
Die ungefähren Größen der verschiedenen Volumes mit den unterschiedlichen SKUs für HANA (große Instanzen) sind unter Übersicht und Architektur von SAP HANA in Azure (große Instanzen) dokumentiert.
Die Benennungskonventionen der Speichervolumes sind in der folgenden Tabelle aufgeführt:
| Speicherverwendung | Mountname | Volumename |
|---|---|---|
| HANA-Daten | /hana/data/SID/mnt0000<m> | Speicher-IP: /hana_data_SID_mnt00001_tenant_vol |
| HANA-Protokoll | /hana/log/SID/mnt0000<m> | Speicher-IP: /hana_log_SID_mnt00001_tenant_vol |
| HANA-Protokollsicherung | /hana/log/backups | Speicher-IP: /hana_log_backups_SID_mnt00001_tenant_vol |
| HANA-Freigabe | /hana/shared/SID | Speicher-IP: /hana_shared_SID_mnt00001_tenant_vol/shared |
| usr/sap | /usr/sap/SID | Speicher-IP: /hana_shared_SID_mnt00001_tenant_vol/usr_sap |
SID ist die System-ID der HANA-Instanz.
Tenant ist eine interne Enumeration von Vorgängen beim Bereitstellen eines Mandanten.
„usr/sap“ in HANA nutzt das gleiche Volume. Die Nomenklatur der Bereitstellungspunkte enthält die System-ID der HANA-Instanzen und die Bereitstellungsnummer. In Bereitstellungen zum Hochskalieren ist nur ein Bereitstellungspunkt vorhanden, z. B. mnt00001. Bei Bereitstellungen für horizontales Skalieren werden so viele Bereitstellungspunkte verwendet, wie Worker- und Hauptknoten vorhanden sind.
Für Umgebungen für horizontales Skalieren werden Daten-, Protokoll- und Protokollsicherungsvolumes gemeinsam genutzt und an jeden Knoten in der Konfiguration für horizontales Skalieren angefügt. Für Konfigurationen, die aus mehreren SAP-Instanzen bestehen, werden andere Volumes erstellt und an die Instanz von SAP HANA (große Instanzen) angefügt. Speicherlayoutdetails für Ihr Szenario finden Sie unter Unterstützte HLI-Szenarien.
Instanzen von SAP HANA (große Instanzen) verfügen über ein ausgesprochen großes Datenträgervolume für „HANA/data“ und ein Volume „HANA/log/backup“. HANA/data wurde so groß angelegt, weil die Speichermomentaufnahmen das gleiche Datenträgervolume verwenden. Je mehr Speichermomentaufnahmen Sie erstellen, desto mehr Speicherplatz wird von den Momentaufnahmen in Ihren zugewiesenen Speichervolumes belegt.
Das Volume „HANA/log/backup“ ist nicht für die Speicherung von Datenbanksicherungen vorgesehen. Seine Größe ist so ausgelegt, dass es als Sicherungsvolume für HANA-Transaktionsprotokollsicherungen verwendet werden kann. Weitere Informationen finden Sie unter Hochverfügbarkeit und Notfallwiederherstellung für SAP HANA in Azure (große Instanzen).
Sie können Ihren Speicher vergrößern, indem Sie zusätzliche Kapazität in Schritten von 1 TB erwerben. Dieser zusätzliche Speicher kann einer Instanz von SAP HANA (große Instanzen) in Form von neuen Volumes hinzugefügt werden.
Während des Onboardings mit der Dienstverwaltung für SAP HANA in Azure geben Sie eine Benutzer-ID (UID) und eine Gruppen-ID (GID) für den Benutzer „sidadm“ und die Gruppe „sapsys“ an (Beispiel: 1000,500). Während der Installation des SAP HANA-Systems müssen Sie genau diese Werte verwenden. Da Sie mehrere HANA-Instanzen in einer Einheit bereitstellen möchten, erhalten Sie mehrere Gruppen von Volumes (eine Gruppe für jede Instanz). Daher müssen Sie zur Bereitstellungszeit Folgendes definieren:
- Die SID der verschiedenen HANA-Instanzen („sidadm“ wird daraus abgeleitet).
- Die Arbeitsspeichergrößen der verschiedenen HANA-Instanzen. Die Arbeitsspeichergröße pro Instanz definiert die Größe der Volumes in den einzelnen Volumesätzen.
Basierend auf den Empfehlungen von Speicheranbietern werden für alle Mountvolumes (mit Ausnahme der Start-LUN) die folgenden Mountoptionen konfiguriert:
- nfs rw, vers=4, hard, timeo=600, rsize=1048576, wsize=1048576, intr, noatime, lock 0 0
Diese Bereitstellungspunkte werden in „/etc/fstab“ konfiguriert, wie in den folgenden Screenshots dargestellt:

Die Ausgabe des Befehls „df -h“ in einer S72m-Instanz von SAP HANA (große Instanzen) sieht wie folgt aus:
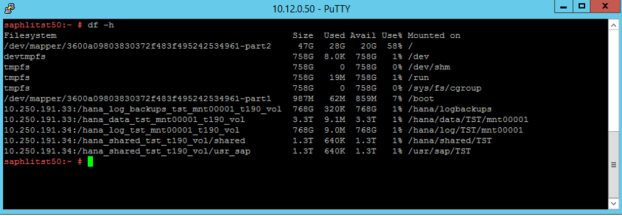
Der Speichercontroller und die Knoten in den „Große Instanz“-Stapeln werden mit NTP-Servern synchronisiert. Es ist wichtig, die Instanz von SAP HANA in Azure (große Instanzen) und die Azure-VMs mit einem NTP-Server zu synchronisieren. Dies vermeidet erhebliche Zeitabweichungen zwischen der Infrastruktur und den Compute-Einheiten in Azure oder den Stempeln in der Instanz von SAP HANA (große Instanzen).
Um SAP HANA für den zugrunde liegenden Speicher zu optimieren, legen Sie die folgenden SAP HANA-Konfigurationsparameter fest:
- max_parallel_io_requests 128
- async_read_submit on
- async_write_submit_active on
- async_write_submit_blocks all
Für SAP HANA 1.0-Versionen bis SPS12 können diese Parameter während der Installation der SAP HANA-Datenbank festgelegt werden, wie in SAP Note #2267798 – Configuration of the SAP HANA Database (SAP-Hinweis 2267798 – Konfiguration der SAP HANA-Datenbank) beschrieben.
Sie können die Parameter auch nach der Installation der SAP HANA-Datenbank konfigurieren, indem Sie das hdbparam-Framework verwenden.
Der in HANA (große Instanzen) genutzte Speicher weist eine Dateigrößenbeschränkung auf. Die Größenbeschränkung beträgt 16 TB pro Datei. Anders als bei den Einschränkungen der Dateigröße in EXT3-Dateisystemen wird die durch SAP HANA (große Instanzen) erzwungene Speichereinschränkung in HANA nicht implizit berücksichtigt. Daher erstellt HANA nicht automatisch eine neue Datendatei, wenn die maximale Dateigröße von 16 TB erreicht ist. Während HANA versucht, die Datei über 16 TB hinaus zu vergrößern, werden Fehler gemeldet, und der Indexserver stürzt am Ende ab.
Wichtig
Damit HANA nicht versucht, Datendateien über die für den Speicher in SAP HANA (große Instanzen) geltende Dateigrößenbeschränkung von 16 TB hinaus zu vergrößern, müssen Sie in der Konfigurationsdatei „global.ini“ von SAP HANA die folgenden Parameter festlegen:
Seit SAP HANA Version 2.0 ist das hdbparam-Framework veraltet. Daher müssen die Parameter mithilfe von SQL-Befehlen festgelegt werden. Weitere Informationen finden Sie in SAP-Hinweis 2399079: Beseitigung von hdbparam in HANA 2.
Informationen zum Speicherlayout für Ihre Architektur finden Sie unter Unterstützte HLI-Szenarien.
Nächste Schritte
Machen Sie sich mit den Schritten zum Installieren von SAP HANA in Azure (große Instanzen) vertraut.