Häufig verwendete Webanwendungsarchitekturen
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architect Modern Web Applications with ASP.NET Core and Azure“, das unter .NET Docs oder als kostenlos herunterladbare PDF-Datei verfügbar ist, die offline gelesen werden kann.

„Wenn Sie denken, dass gute Architektur teuer ist, versuchen Sie es mit schlechter Architektur.“ – Brian Foote und Joseph Yoder
Die meisten herkömmlichen .NET-Anwendungen werden als einzelne Einheiten bereitgestellt, die einer ausführbaren Datei oder einer Webanwendung entsprechen, die innerhalb einer IIS-Anwendungsdomäne ausgeführt wird. Bei diesem Ansatz handelt es sich um das wohl einfachste Bereitstellungsmodell, das sich gut für interne und kleinere öffentliche Anwendungen eignet. Allerdings eignet sich für die meisten wichtigen Geschäftsanwendungen sogar mit dieser einzelnen Bereitstellungseinheit die logische Unterteilung in mehrere Schichten.
Was sind monolithische Anwendungen?
Monolithische Anwendungen sind in Bezug auf ihr Verhalten vollkommen unabhängig. Sie interagieren zwar möglichweise mit anderen Diensten oder Datenspeichern, während sie Vorgänge ausführen, aber der Hauptbestandteil ihres Verhaltens liegt in ihren eigenen Prozessen, und die gesamte Anwendung wird in der Regel als einzelne Einheit bereitgestellt. Wenn eine solche Anwendung eine horizontale Skalierung vornehmen muss, wird in der Regel die gesamte Anwendung auf mehreren Servern oder virtuellen Computern dupliziert.
All-in-One-Anwendungen
Jede Anwendungsarchitektur muss mindestens ein Projekt umfassen. In dieser Architektur ist die gesamte Logik der Anwendung in nur einem Projekt enthalten. Außerdem wird sie in nur eine Assembly kompiliert und als einzelne Einheit bereitgestellt.
Wenn ein neues ASP.NET Core-Projekt erstellt wird, stellt dieses anfangs immer einen All-in-One-Monolith dar. Dabei macht es keinen Unterschied, ob es über Visual Studio oder die Befehlszeile erstellt wird. Dieser Monolith enthält das gesamte Verhalten der Anwendung, einschließlich der Darstellungs-, Geschäfts- und Datenzugriffslogik. In Abbildung 5-1 wird die Dateistruktur einer App dargestellt, die aus einem Projekt besteht.
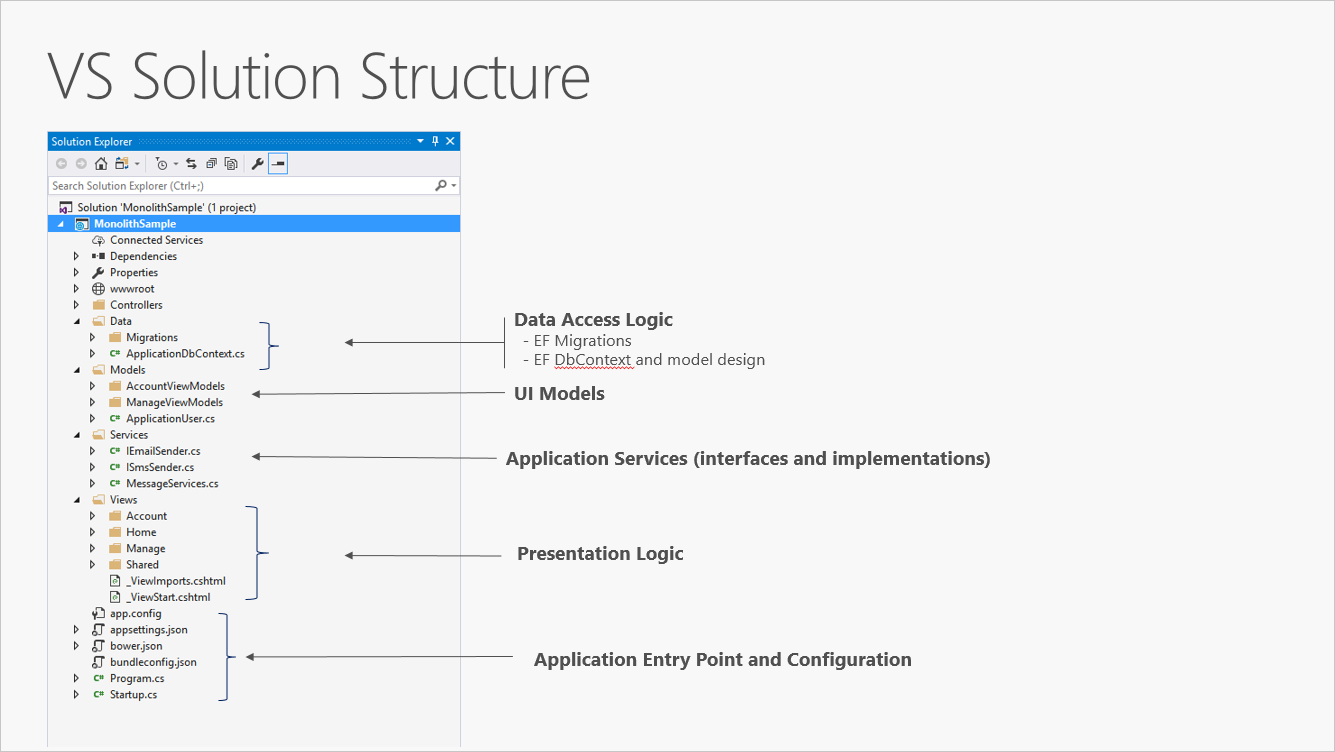
Abbildung 5-1. Eine ASP.NET Core-App, die nur aus einem Projekt besteht.
Wenn eine App nur aus einem Projekt besteht, wird das Prinzip „Separation of Concerns“ durch die Verwendung von Ordnern unterstützt. Die Standardvorlage enthält separate Ordner für Verantwortlichkeiten von MVC-Mustern für Modelle, Ansichten und Controller sowie zusätzliche Ordner für Daten und Dienste. Wenn Sie diese Vorlage verwenden, sollten Darstellunsgdetails weitestgehend auf den Ansichtenordner (Views) beschränkt sein, und Implementierungsdetails zum Datenzugriff sollten auf Klassen beschränkt sein, die im Datenordner (Data) gespeichert werden. Die Geschäftslogik sollte in Diensten und Klassen gespeichert sein, die im Modellordner (Models) enthalten sind.
Diese monolithische Projektmappe, die aus nur einem Projekt besteht, ist zwar sehr einfach strukturiert, weist aber auch einige Nachteile auf. Wenn der Umfang des Projekts ausgeweitet wird, entstehen auch immer mehr Dateien und Ordner. Elemente, die die Benutzeroberfläche (UI) betreffen (z.B. Modelle, Ansichten und Controller), sind in unterschiedlichen Ordnern gespeichert, die nicht gemeinsam in alphabetischer Reihenfolge sortiert sind. Dieses Problem wird noch größer, wenn zusätzliche Konstrukte auf Benutzeroberflächenebene wie Filter oder ModelBinders-Elemente zu ihren jeweiligen Ordnern hinzugefügt werden. Die Geschäftslogik ist auf die Ordner „Models“ und „Services“ aufgeteilt, und es gibt keinen Anhaltspunkt dafür, welche Klassen in welchen Ordnern von welchen anderen Elementen abhängig sein sollen. Dadurch, dass auf Projektebene keine Sortierung vorgenommen wird, wird der Code häufig unübersichtlich, und es entsteht sogenannter Spaghetticode.
Um diese Probleme zu umgehen, greifen Entwickler häufig auf die Möglichkeit zurück, Anwendungen in Projektmappen mit mehreren Projekten auszuweiten. In diesen Projektmappen ist dann jedes Projekt auf einer bestimmten Schicht einer Anwendung gespeichert.
Was sind Schichten?
Wenn eine Anwendung immer komplexer wird, können Sie dagegen vorgehen, indem Sie sie anhand ihrer Zuständigkeiten und Aufgaben aufteilen. Dieser Ansatz befolgt das Prinzip „Separation of Concerns“ (Trennung von Belangen) und hilft Ihnen dabei, die Codebasis zu ordnen, damit Sie problemlos feststellen können, an welcher Stelle eine bestimmte Funktionalität implementiert wurde. Die Strukturierung Ihres Codes ist aber nicht der einzige Vorteil einer aus Schichten bestehenden Architektur.
Wenn Sie Code in Schichten unterteilen, können häufig verwendete grundlegende Funktionen in der gesamten Anwendung wiederverwendet werden. Dies hat den Vorteil, dass Sie weniger Code schreiben müssen und die Anwendung für eine Implementierung standardisiert wird, was dem Don‘t Repeat Yourself-Prinzip entspricht.
Wenn eine Architektur aus Schichten besteht, können Anwendungen Einschränkungen für die Kommunikation zwischen den einzelnen Schichten erzwingen. Diese Architektur erleichtert die Kapselung. Wenn eine Schicht geändert oder ersetzt wird, sollten nur die Schichten betroffen sein, die mit dieser zusammenarbeiten. Wenn Sie einschränken, welche Schichten voneinander abhängig sind, können die Auswirkungen von Änderungen verringert werden, sodass eine einzige Änderung nicht die gesamte Anwendung betrifft.
Schichten (und die Kapselung) vereinfachen das Ersetzen von Funktionen innerhalb der Anwendung. Möglicherweise verwendet z.B. eine Anwendung anfangs ihre eigene SQL Server-Datenbank als Persistenzspeicher. Sie können sich dann später aber immer noch dafür entscheiden, eine cloudbasierte Persistenzstrategie oder eine Web-API zu verwenden. Wenn die Anwendungen ihre Persistenzimplementierungen innerhalb einer logischen Schicht kapseln, kann diese SQL Server-spezifische Schicht durch eine neue Implementierung derselben öffentlichen Schnittstelle ersetzt werden.
Neben der Möglichkeit, Implementierungen auszutauschen, um möglichen zukünftigen Änderungen von Anforderungen vorzubeugen, können diese mithilfe von Anwendungsschichten auch zu Testzwecken ausgetauscht werden. Die Schichten können während der Tests durch falsche Implementierungen ersetzt werden, die bekannte Antworten auf Anforderungen bereitstellen, sodass Sie keine Tests mehr schreiben müssen, die mit der echten Daten- oder Benutzeroberflächenschicht der Anwendung arbeiten. Mithilfe dieses Ansatzes können Tests in der Regel einfacher geschrieben und im Vergleich zu Tests der echten Infrastruktur der Anwendung schneller ausgeführt werden.
Das Erstellen logischer Schichten ist eine häufig verwendete Technik zum Verbessern der Strukturierung von Code in Unternehmensanwendungen. Es gibt mehrere Möglichkeiten, Code in Schichten zu strukturieren.
Hinweis
Schichten stellen eine logische Unterteilung aller Bestandteile einer App dar. Wenn die Anwendungslogik physisch auf separate Server oder Prozesse verteilt wird, werden diese separaten Bereitstellunsgsziele als Ebenen bezeichnet. Die Verwendung einer Anwendung mit mehreren Schichten, die für eine einzelne Schicht bereitgestellt wird, ist möglich und wird häufig angewandt.
Traditionelle Architektur einer Anwendung mit mehreren Schichten
In Abbildung 5-2 wird die am häufigsten verwendete Unterteilung einer Anwendungslogik in Schichten dargestellt.
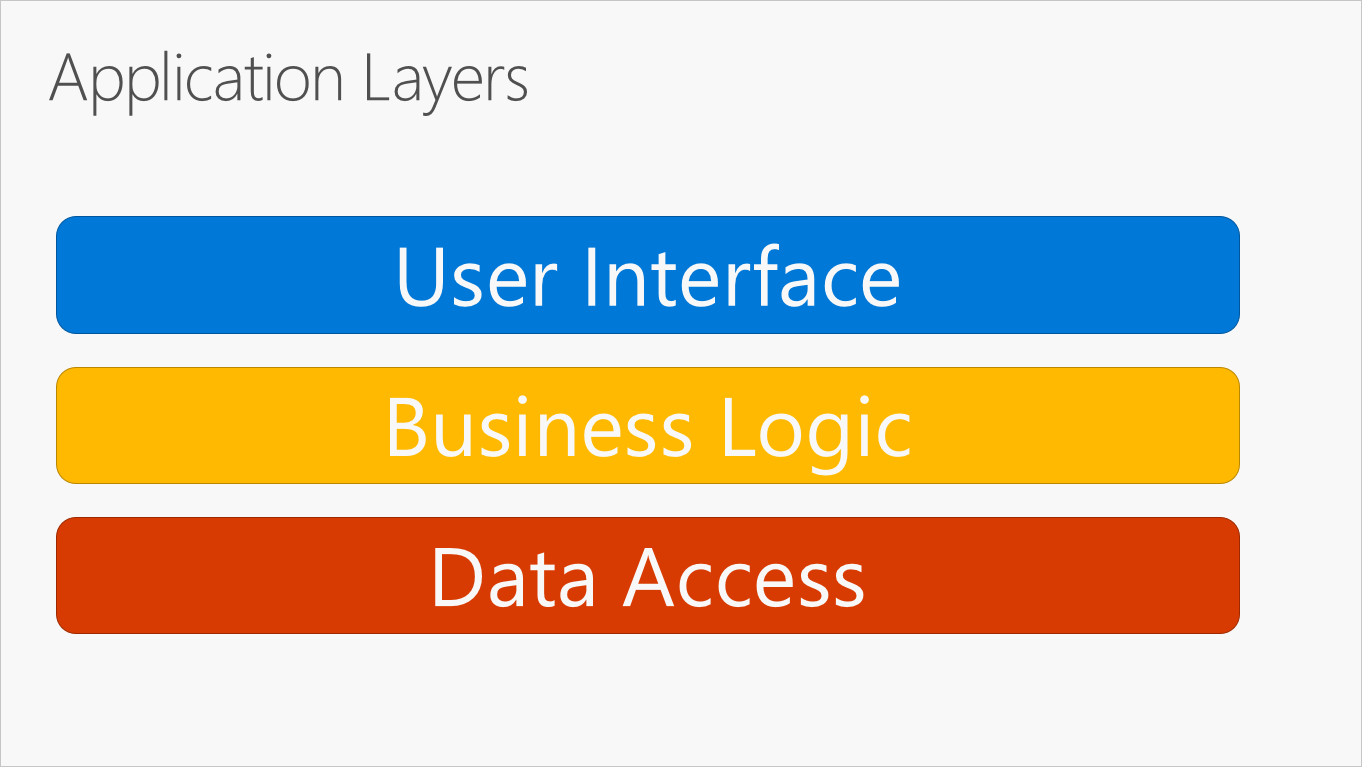
Abbildung 5-2. Typische Anwendungsschichten
Diese Schichten werden häufig mit den englischen Abkürzungen UI für User Interface (Benutzeroberfläche), BLL für Business Logic Layer (Schicht der Geschäftslogik) und DAL für Data Access Layer (Schicht für den Datenzugriff) bezeichnet. Wenn diese Architektur verwendet wird, senden Benutzer Anforderungen über die Benutzeroberflächenschicht, die nur mit der BLL interagiert. Die BLL kann wiederum die DAL für Anforderungen hinsichtlich des Datenzugriffs aufrufen. Die UI-Schicht sollte keine direkten Anforderungen an die DAL senden oder direkt mithilfe anderer Methoden mit der Persistenz interagieren. Gleichzeitig sollte die BLL nur über die DAL mit der Persistenz interagieren. Auf diese Weise wird jeder Schicht eine individuelle bekannte Verantwortlichkeit zugewiesen.
Dieser traditionelle Ansatz zum Erstellen von Schichten hat allerdings den Nachteil, dass Abhängigkeiten zur Kompilierzeit von oben nach unten ausgeführt werden. Das heißt, die UI-Schicht ist von der BLL abhängig, die wiederum von der DAL abhängig ist. Das wiederum bedeutet, dass die BLL, die in der Regel die wichtigste Logik innerhalb der Anwendung aufweist, von den Implementierungsdetails zum Datenzugriff abhängig ist (und dadurch häufig auch eine Datenbank benötigt). Das Testen einer Geschäftslogik in einer Architektur wie dieser gestaltet sich häufig als schwierig und erfordert eine Testdatenbank. Sie können dieses Problem wie im nächsten Abschnitt beschrieben mit dem Dependency Inversion-Prinzip angehen.
In Abbildung 5-3 wird eine Projektmappe als Beispiel dargestellt, in der die Anwendung anhand von Zuständigkeiten bzw. Schichten in drei Projekte unterteilt wird.
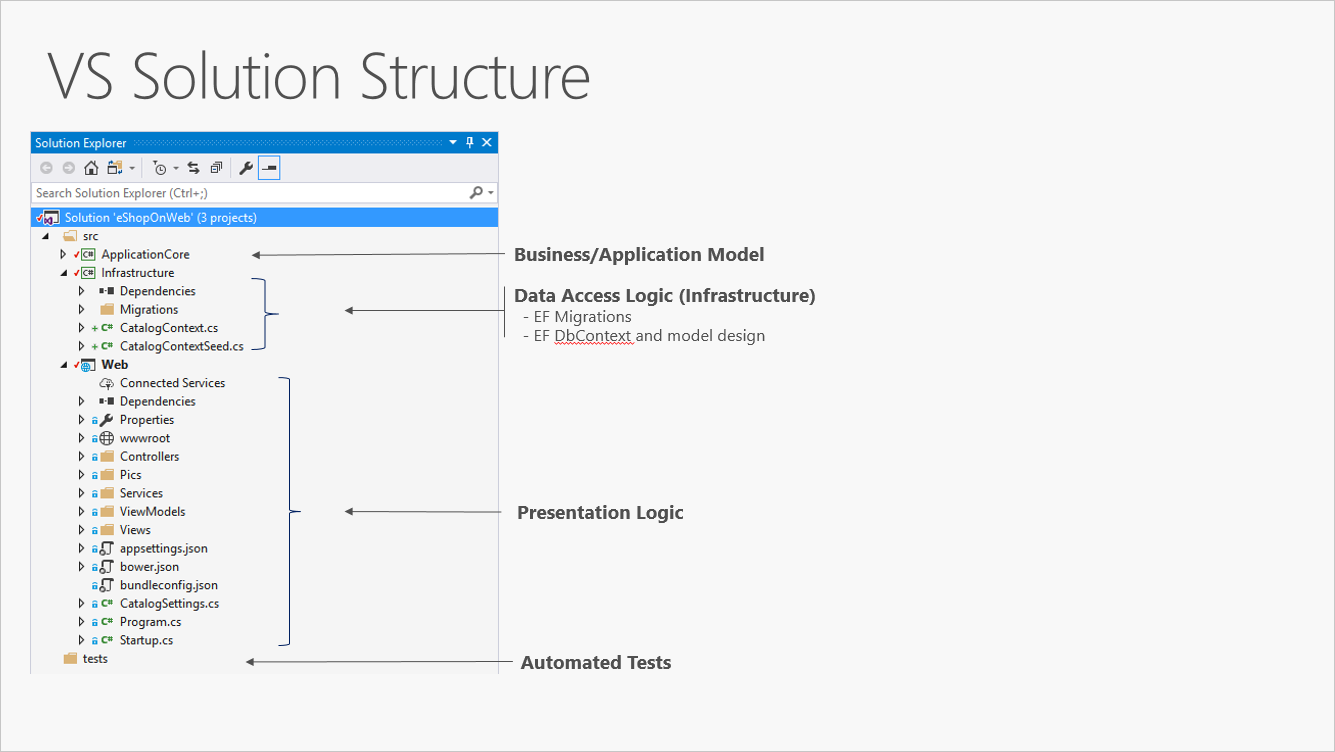
Abbildung 5-3. Eine einfache monolithische Anwendung mit drei Projekten
Obwohl diese Anwendung aus Strukturierungsgründen mehrere Projekte verwendet, wird sie als einzelne Einheit bereitgestellt, und ihre Clients interagieren mit ihr wie mit einer einzelnen Web-App. Dies vereinfacht die Bereitstellung. In Abbildung 5-4 wird dargestellt, wie eine solche App unter Verwendung von Azure gehostet werden kann.
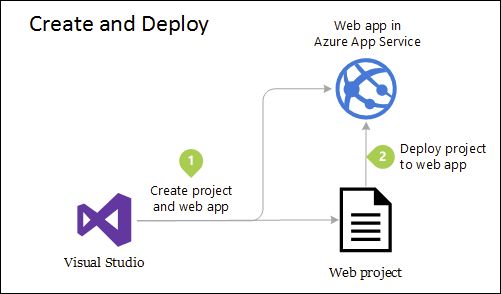
Abbildung 5-4. Einfache Bereitstellung einer Azure-Web-App
Wenn die Anforderungen an eine App höher werden, ist möglicherweise eine komplexere und robustere Bereitstellungslösung erforderlich. In Abbildung 5-5 ist ein Beispiel einer komplexeren Bereitstellung dargestellt, die mehrere zusätzliche Funktionen unterstützt.
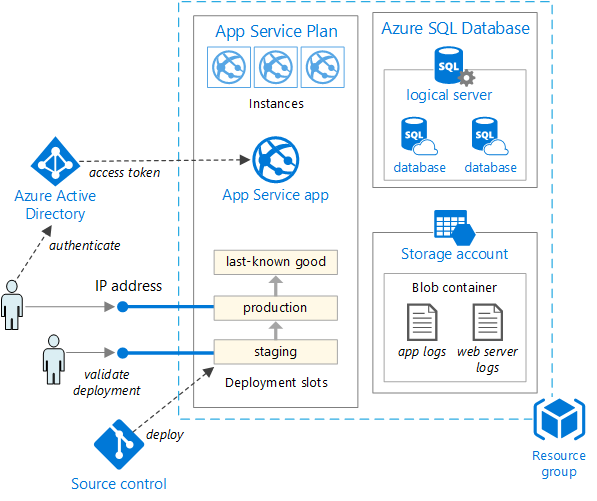
Abbildung 5-5. Bereitstellen einer Web-App in Azure App Service
Innerhalb der Anwendung verbessert diese Unterteilung in mehrere Projekte anhand von Zuständigkeiten deren Verwaltbarkeit.
Diese Einheit kann zentral oder horizontal hochskaliert werden, um die cloudbasierte bedarfsgesteuerte Skalierbarkeit zu nutzen. Beim zentralen Hochskalieren werden zusätzliche CPU, zusätzlicher Arbeitsspeicher, zusätzlicher Speicherplatz auf dem Datenträger oder andere Ressourcen zu dem Server bzw. den Servern hinzugefügt, der bzw. die Ihre App hosten. Beim horizontalen Hochskalieren werden zusätzliche Instanzen solcher Server hinzugefügt. Dabei macht es keinen Unterschied, ob es sich um physische Server, virtuelle Computer oder Container handelt. Wenn Ihre App auf mehreren Instanzen gehostet wird, wird ein Lastenausgleich vorgenommen, um individuellen App-Instanzen Anforderungen zuzuweisen.
Der einfachste Ansatz zum Skalieren einer Webanwendung in Azure ist das manuelle Konfigurieren einer Skalierung im App Service-Plan der Anwendung. In Abbildung 5-6 wird die Anzeige des Azure-Dashboards dargestellt, über die Sie konfigurieren können, wie viele Instanzen einer App zugrunde liegen.
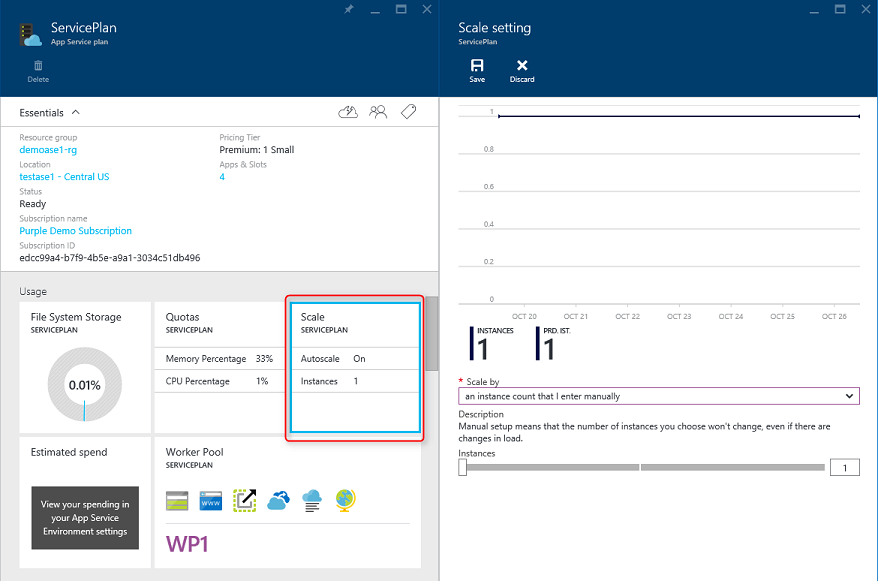
Abbildung 5-6. Skalieren des App Service-Plans in Azure
Clean Architecture
Anwendungen, die den Prinzipien der Abhängigkeitsumkehr und des domänengesteuerten Entwurfs (DDD) folgen, weisen alle eine ähnliche Architektur auf. Diese Architektur wurde in den vergangenen Jahren unterschiedlich benannt. Zuerst wurde diese Architektur als „Hexagonal Architecture“ bezeichnet. Darauf folgte der Begriff „Ports-and-Adapters“. Heutzutage spricht man aber eher von Onion Architecture bzw. Clean Architecture. Der zweite Name, „Clean Architecture“, wird in diesem E-Book als Name dieser Architektur verwendet.
Die Referenzanwendung eShopOnWeb befolgt den Ansatz der Clean Architecture bei der Aufteilung des Codes in Projekte. Eine Projektmappenvorlage, die Sie als Ausgangspunkt für Ihren eigenen ASP.NET Core-Code verwenden können, finden Sie im GitHub-Repository ardalis/cleanarchitecture oder durch Installation der Vorlage aus NuGet.
In der Clean Architecture sind die Geschäftslogik und das Anwendungsmodell im Kern der Anwendung enthalten. Es wird dann das Prinzip Dependency Inversion angewendet, bei dem die Geschäftslogik nicht mehr vom Datenzugriff oder anderen Aufgaben, die die Infrastruktur betreffen, abhängig ist. Stattdessen sind die Informationen zur Infrastruktur und Implementierung vom Anwendungskern abhängig. Für diese Funktionalität werden Abstraktionen oder Schnittstellen im Anwendungskern definiert und anschließend anhand von Typen implementiert, die in der Infrastrukturschicht definiert werden. Diese Architektur wird häufig in Kreisringen dargestellt, die dem Aufbau einer Zwiebel ähneln. In Abbildung 5-7 ist ein Beispiel für die Darstellung der Architektur enthalten.
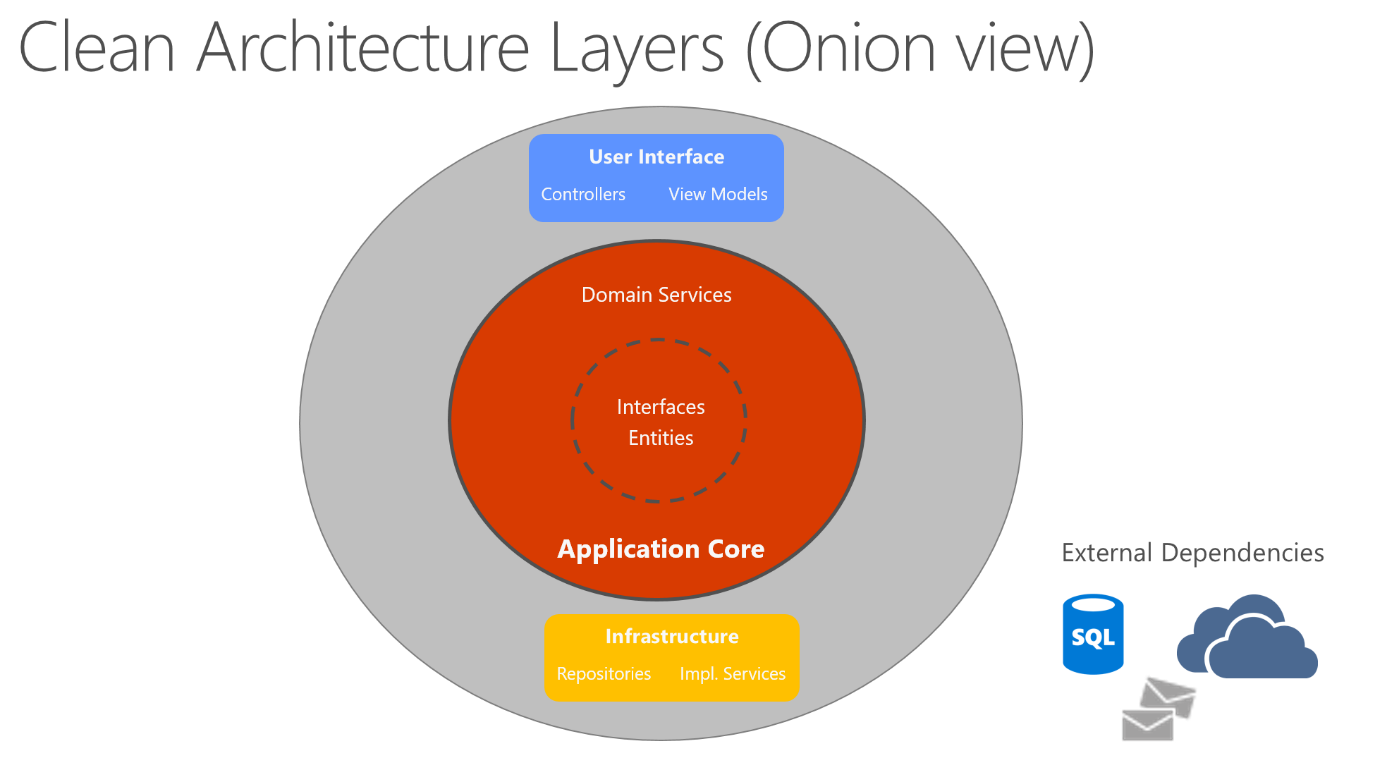
Abbildung 5-7. Clean Architecture: „Zwiebelansicht“
In diesem Diagramm beziehen sich alle Abhängigkeiten auf den inneren Kreisring, also auf den Anwendungskern. Der Anwendungskern erhält seinen Namen aufgrund seiner Position im Zentrum des Diagramms. Auf dem Diagramm können Sie auch sehen, dass der Anwendungskern über keine Abhängigkeiten von anderen Anwendungsschichten verfügt. Die Entitäten und Schnittstellen der Anwendung stehen im Mittelpunkt. Domänendienste, die in der Regel Schnittstellen implementieren, die im inneren Kreisring definiert sind, befinden sich am äußeren Rand des Anwendungskerns. Außerhalb des Anwendungskerns sind sowohl die Benutzeroberfläche als auch die Infrastrukturebenen zwar vom Anwendungskern, aber nicht (unbedingt) voneinander abhängig.
In Abbildung 5-8 wird ein herkömmlicheres horizontales Schichtendiagramm dargestellt, das die Abhängigkeit zwischen Benutzeroberfläche und anderen Schichten besser darstellt.
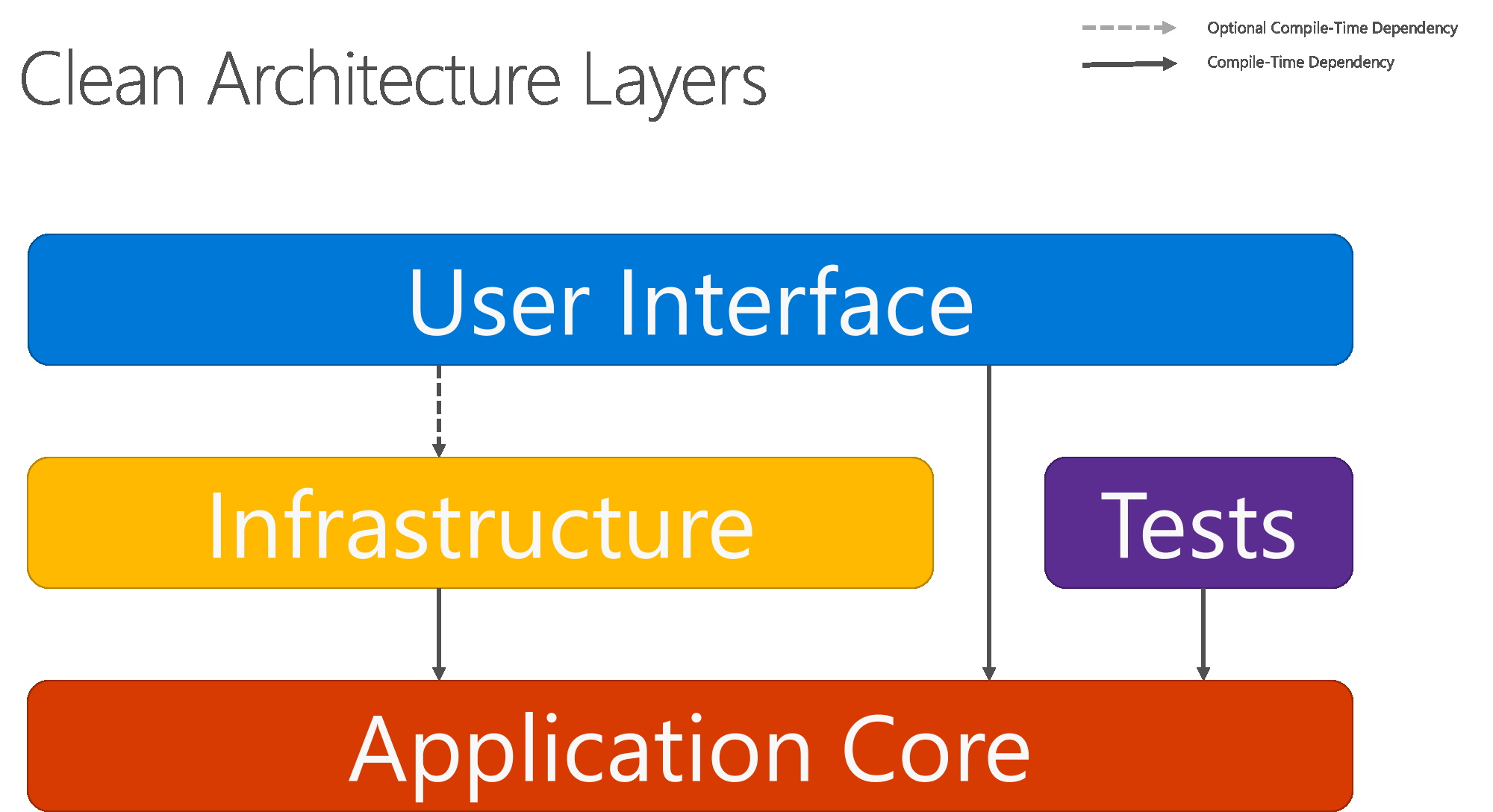
Abbildung 5-8. Clean Architecture: Ansicht mit horizontalen Schichten
Beachten Sie, dass die Pfeile mit durchgezogener Linie Abhängigkeiten zur Kompilierzeit darstellen. Die Pfeile mit gestrichelten Linien stellen Abhängigkeiten dar, die nur zur Laufzeit bestehen. Unter Verwendung von Clean Architecture funktioniert die UI-Schicht nur mit Schnittstellen, die zur Kompilierzeit im Anwendungskern definiert werden. Im Idealfall sollten diese außerdem nicht über Informationen zu den in der Infrastrukturebene definierten Implementierungstypen verfügen. Zur Laufzeit sind diese Implementierungstypen jedoch erforderlich, damit die App ausgeführt werden kann. Daher müssen sie definiert und über Dependency Injection mit den Schnittstellen des Anwendungskerns verbunden sein.
In Abbildung 5-9 wird eine detailliertere Ansicht der Architektur einer ASP.NET Core-Anwendung dargestellt, die anhand dieser Empfehlungen erstellt wurde.
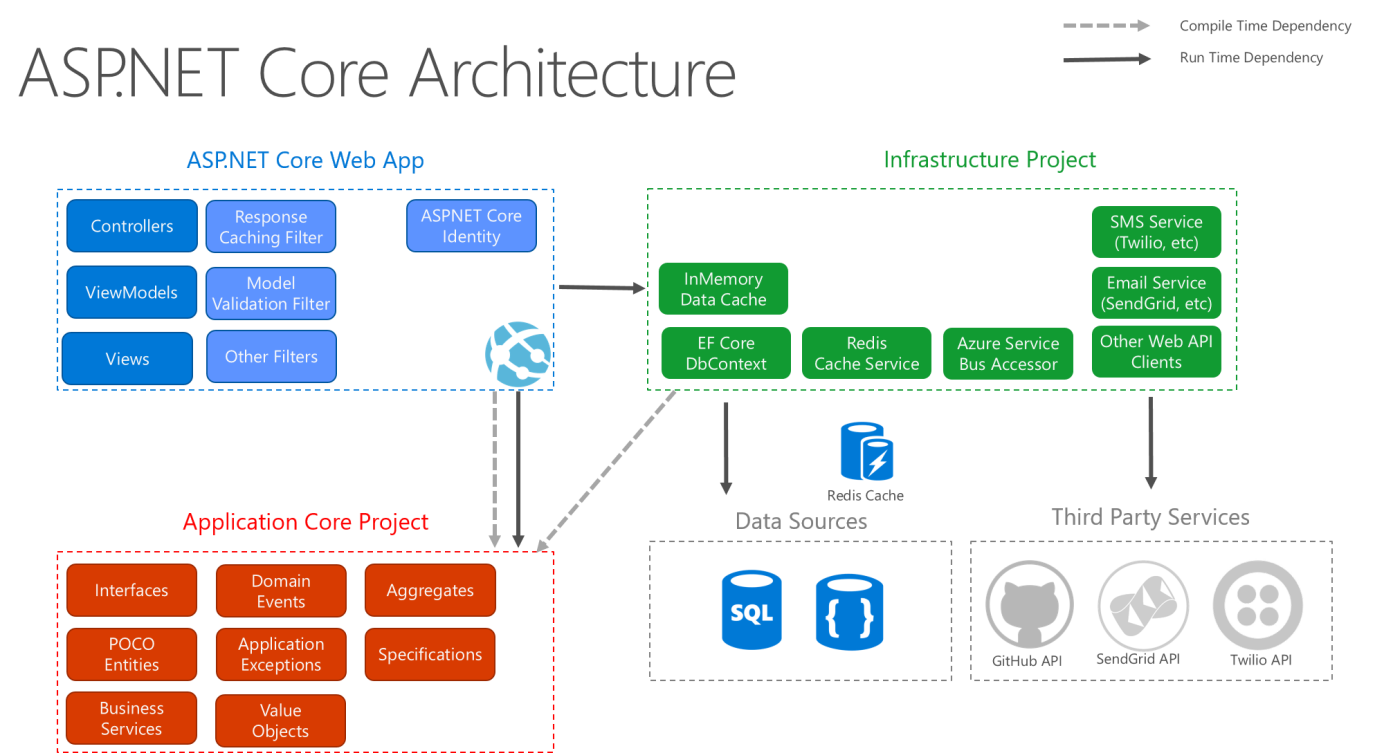
Abbildung 5-9. Diagramm der ASP.NET Core-Architektur, die dem Prinzip der Clean Architecture folgt
Da der Anwendungskern nicht von der Infrastrukturebene abhängig ist, ist es leicht, automatisierte Komponententests für diese Schicht zu schreiben. In den Abbildungen 5-10 und 5-11 wird dargestellt, wie Tests mit dieser Architektur in Einklang gebracht werden können.
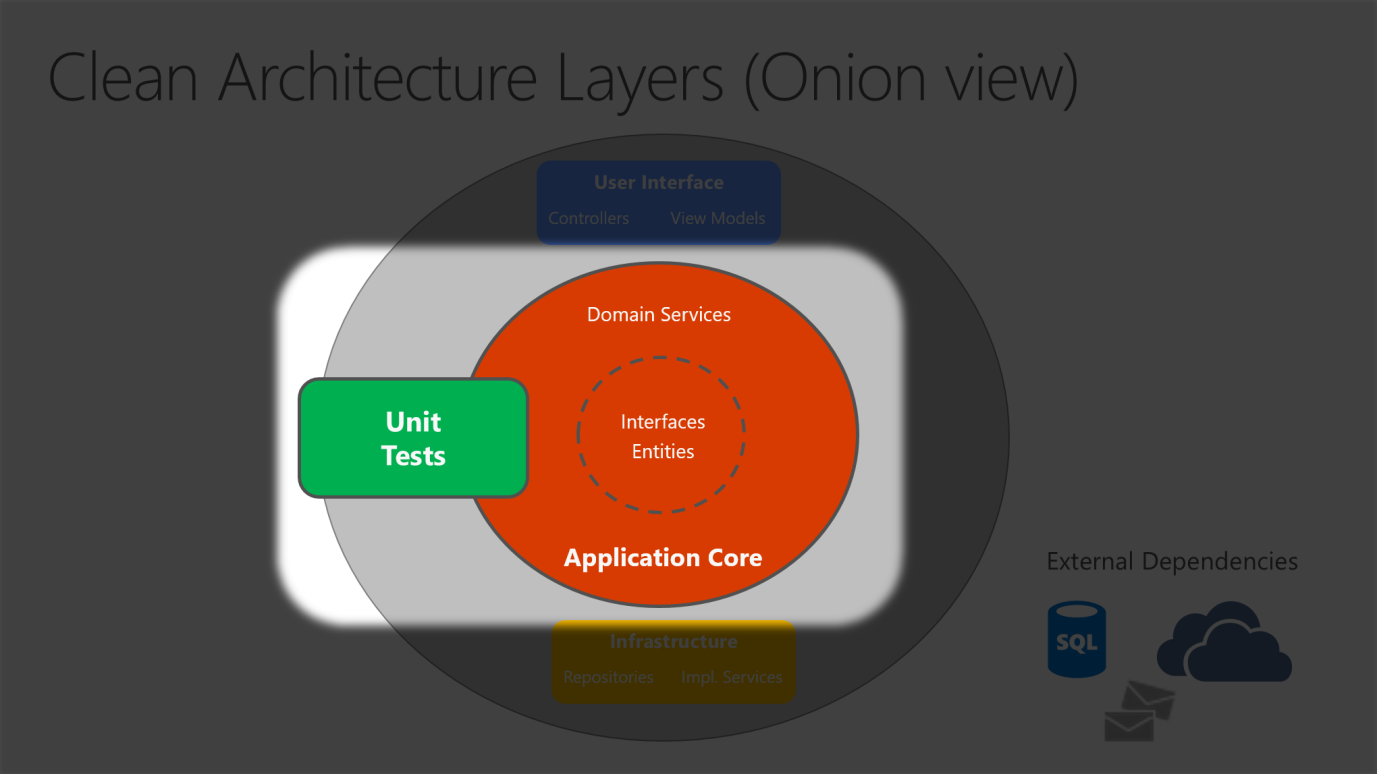
Abbildung 5-10. Isolierter Komponententest des Anwendungskerns
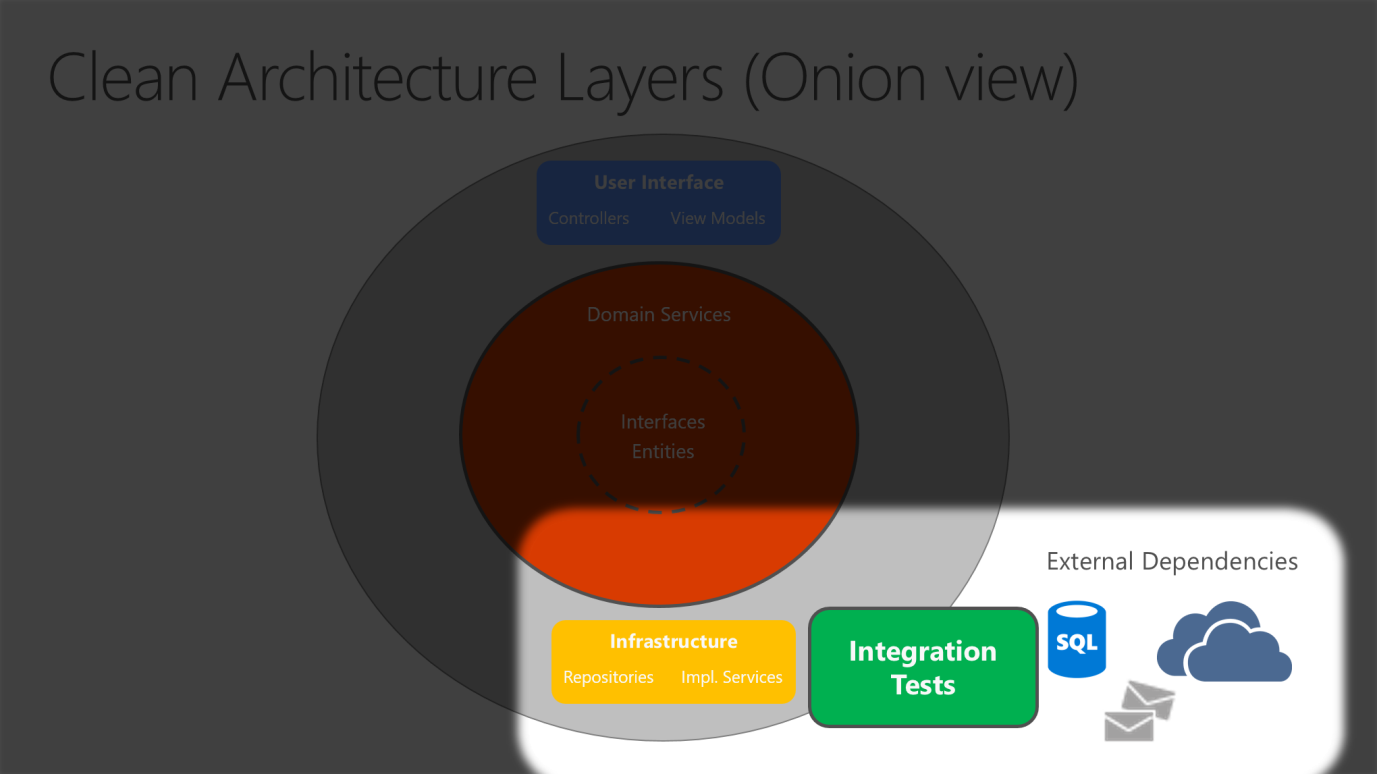
Abbildung 5-11. Integrationstest von Infrastrukturimplementierungen mit externen Abhängigkeiten
Da die UI-Schicht nicht über direkte Abhängigkeiten von im Infrastrukturprojekt definierten Typen verfügt, können Implementierungen leicht ausgetauscht werden. Dadurch kann das Testen vereinfacht werden, oder sich ändernde Anwendungsanforderungen lassen sich leichter umsetzen. Durch die in ASP.NET Core integrierte Verwendung von und Unterstützung für Dependency Injection eignet sich diese Architektur besonders gut zum Strukturieren wichtiger monolithischer Anwendungen.
Bei monolithischen Anwendungen werden Projekte für den Anwendungskern, die Infrastruktur und die Benutzeroberfläche als einzelne Anwendung ausgeführt. Die Anwendungsarchitektur zur Laufzeit sieht in etwa wie in Abbildung 5-12 dargestellt aus.
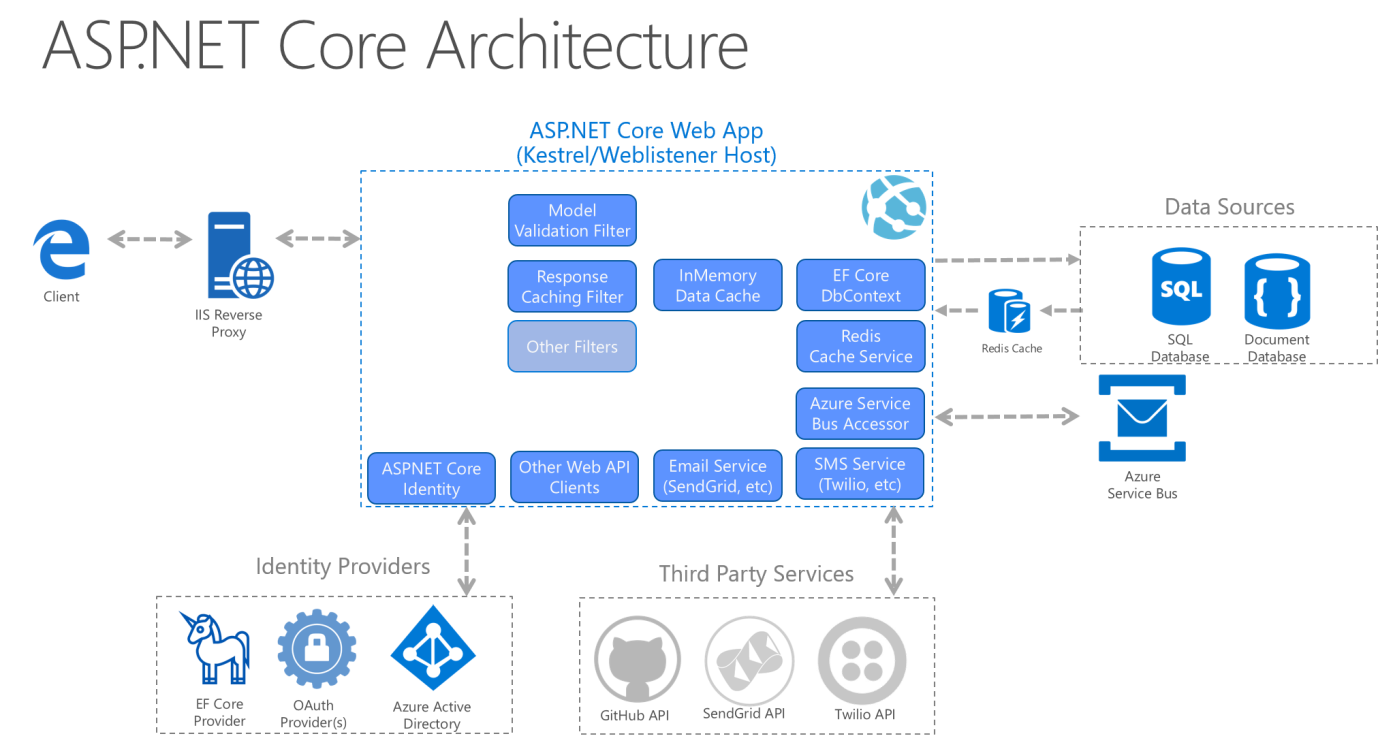
Abbildung 5-12. Beispiel für die Laufzeitarchitektur einer ASP.NET Core-App
Strukturieren von Code anhand des Clean Architecture-Prinzips
In einer gemäß der Clean Architecture erstellten Projektmappe verfügt jedes Projekt über klare Zuständigkeiten. Daher gehören zu jedem Projekt bestimmte Typen, und häufig entsprechen Ordner im jeweiligen Projekt diesen Typen.
Anwendungskern
Der Anwendungskern enthält das Geschäftsmodell, das wiederum Entitäten, Dienste und Schnittstellen umfasst. Diese Schnittstellen umfassen Abstraktionen für Vorgänge, die unter Verwendung der Infrastruktur ausgeführt werden. Damit sind z.B. der Datenzugriff, der Zugriff auf Dateisysteme und Netzwerkaufrufe gemeint. Gelegentlich müssen für diese Schicht installierte Dienste und Schnittstellen mit Typen zusammenarbeiten, bei denen es sich nicht um Entitäten handelt und die nicht von der Benutzeroberfläche oder der Infrastruktur abhängig sind. Diese Dienste und Schnittstellen können als einfache Datentransferobjekte (Data Transfer Objects, DTOs) definiert sein.
Typen des Anwendungskerns
- Entitäten (Klassen von Geschäftsmodellen, die dauerhaft gespeichert werden)
- Aggregate (Entitätsgruppen)
- Schnittstellen
- Domänendienste
- Spezifikationen
- Benutzerdefinierte Ausnahmen und Wächterklauseln
- Domänenereignisse und Handler
Infrastruktur
Das Infrastrukturprojekt umfasst in der Regel Implementierungen für den Datenzugriff. In einer herkömmlichen ASP.NET Core-Webanwendung umfassen diese Implementierungen die Entity Framework-Klasse „DbContext“, jegliche Migration-Objekte von EF Core, die definiert wurden, und Klassen für die Implementierungen des Datenzugriffs. Die beste Möglichkeit, Implementierungscode für den Datenzugriff zu implementieren, stellt das Entwurfsmuster Repository dar.
Das Infrastrukturprojekt sollte neben Implementierungen für den Datenzugriff Implementierungen von Diensten enthalten, die mit verschiedenen Bestandteilen der Infrastruktur interagieren. Diese Dienste sollten im Anwendungskern definierte Schnittstellen implementierten. Daher sollte im Infrastrukturprojekt ein Verweis auf das Anwendungskernprojekt enthalten sein.
Typen der Infrastruktur
- EF Core-Typen (
DbContext,Migration) - Implementierungstypen für den Datenzugriff (Repositorys)
- Infrastrukturspezifische Dienste (z.B.
FileLoggeroderSmtpNotifier)
Benutzeroberflächenschicht
Die UI-Schicht in einer ASP.NET Core MVC-Anwendung stellt den Einstiegspunkt für die Anwendung dar. Dieses Projekt sollte auf das Anwendungskernprojekt verweisen, und dessen Typen sollten ausschließlich über im Anwendungskern definierte Schnittstellen mit der Infrastruktur interagieren. In der UI-Schicht sollten keine direkte Instanziierung oder statische Aufrufe von Typen von Infrastrukturebenen zugelassen werden.
Arten von Benutzeroberflächenschichten
- Controller
- Benutzerdefinierte Filter
- Benutzerdefinierte Middleware
- Ansichten
- ViewModels
- Start
Die Konfiguration der Anwendung erfolgt in der Klasse Startup bzw. in der Datei Program.cs, wo auch die Implementierungstypen mit den Schnittstellen verknüpft werden. Der Ort, an dem diese Logik ausgeführt wird, wird als Kompositionsstamm der Anwendung bezeichnet und ermöglicht es, dass die Abhängigkeitsinjektion zur Laufzeit ordnungsgemäß funktioniert.
Hinweis
Um die Abhängigkeitsinjektion während des App-Starts zu verknüpfen, muss das Projekt der UI-Ebene möglicherweise auf das Infrastrukturprojekt verweisen. Diese Abhängigkeit kann am einfachsten mithilfe eines benutzerdefinierten DI-Containers beseitigt werden, der integrierte Unterstützung für das Laden von Typen aus Assemblys bereitstellt. Im Rahmen dieses Beispiels besteht der einfachste Ansatz darin, dem UI-Projekt zu gestatten, auf das Infrastrukturprojekt zu verweisen (Entwickler sollten jedoch tatsächliche Verweise auf Typen im Infrastrukturprojekt auf den Kompositionsstamm der Anwendung beschränken).
Monolithische Anwendungen und Container
Sie können eine einzelne, monolithisch bereitgestellte Webanwendung oder einen Webdienst erstellen und als Container bereitstellen. Die Anwendung ist in ihrem Inneren möglicherweise nicht monolithisch strukturiert, sondern in mehrere Bibliotheken, Komponenten oder Schichten unterteilt. Extern handelt es sich um einen einzelnen Container mit einem einzelnen Prozess, einer einzelnen Webanwendung oder einem einzelnen Dienst.
Stellen Sie einen einzelnen Container bereit, der diese Anwendung darstellt, um dieses Modell zu verwalten. Fügen Sie zum Skalieren einfach weitere Kopien mit einem vorangestellten Lastenausgleich hinzu. Die Einfachheit stammt aus der Verwaltung einer einzelnen Bereitstellung in einem einzelnen Container oder virtuellen Computer.
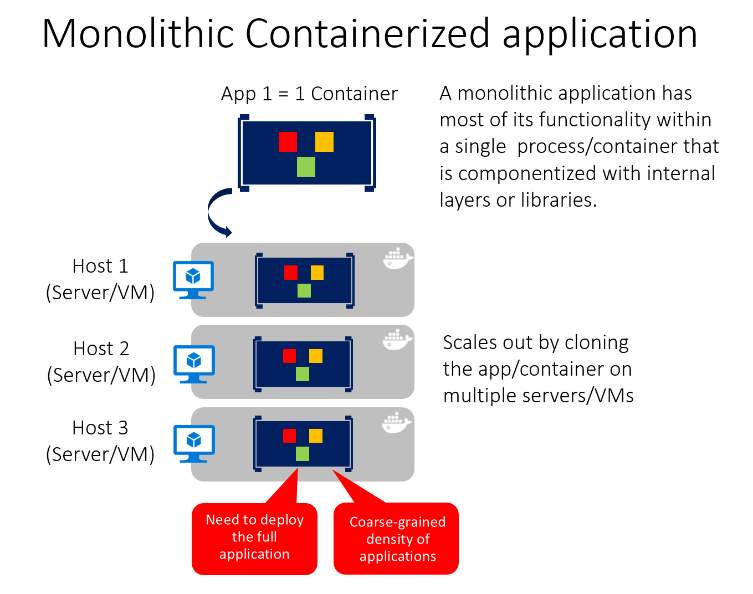
Sie können, wie in Abbildung 5-13 veranschaulicht, mehrere Komponenten, Bibliotheken oder interne Schichten in jeden Container einschließen. Allerdings kann dieses monolithische Muster zu einem Konflikt mit dem Containerprinzip Jeder Container hat nur eine Aufgabe, die er in einem Prozess ausführt führen.
Der Nachteil dieses Ansatzes wird offensichtlich, wenn die Anwendung wächst und skaliert werden muss. Wenn die gesamte Anwendung skaliert werden kann, ist dies kein Problem. In den meisten Fällen stellen jedoch nur einige Teile der Anwendung Engpässe dar, die eine Skalierung erfordern, während andere Komponente weniger häufig verwendet werden.
Wenn Sie das gewöhnliche eCommerce-Beispiel verwenden, müssen Sie sehr wahrscheinlich die Komponente für die Produktinformationen skalieren. Viele Kunden suchen Produkte erst und kaufen sie anschließend. Mehr Kunden verwenden Ihren Warenkorb als die Zahlungspipeline. Weniger Kunden fügen Kommentare hinzu oder zeigen ihren Bestellungsverlauf an. Und Sie haben möglicherweise nur eine Handvoll Mitarbeiter in einer bestimmten Region, die den Inhalt und die Marketingkampagnen verwalten müssen. Wenn der monolithische Entwurf skaliert wird, wird der gesamte Code mehrmals bereitgestellt.
Zusätzlich zu dem Problem, dass „alle Komponenten skaliert werden müssen“, erfordern Änderungen einer einzelnen Komponente einen erneuten Test der gesamten Anwendung und eine vollständige erneute Bereitstellung aller Instanzen.
Der monolithische Ansatz wird häufig verwendet, und viele Organisationen arbeiten mit dieser Architektur. Viele von ihnen erzielen damit akzeptable Ergebnisse, aber andere stoßen an ihre Grenzen. Viele Unternehmen haben ihre Anwendungen unter Verwendung dieses Modells entworfen, da Tools und Infrastruktur schon seit Jahren zu komplex für die Erstellung einer dienstorientierten Architektur (SOA) sind. Sie haben die Notwendigkeit nicht erkannt, etwas zu ändern, bis die Anwendung gewachsen ist. Wenn Sie an die Grenzen des monolithischen Ansatzes stoßen, ist der nächste logische Schritt das Aufteilen der App, damit diese Container und Microservices besser nutzen kann.
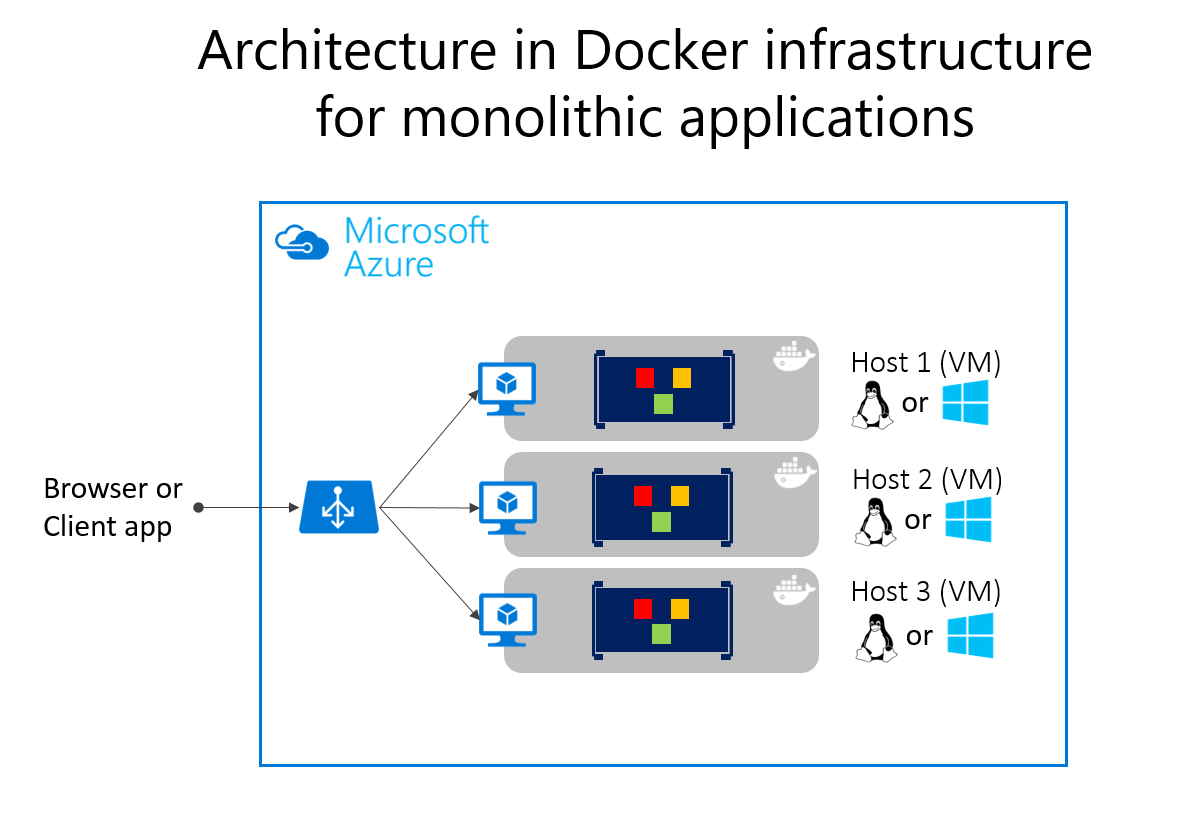
Monolithische Anwendungen in Microsoft Azure können mithilfe von dedizierten VMs für jede Instanz bereitgestellt werden. Sie können die VMs problemlos skalieren, wenn Sie Azure Virtual Machine Scale Sets verwenden. Azure App Service kann auch monolithische Anwendungen ausführen und Instanzen problemlos skalieren, ohne dass die VMs verwaltet werden müssen. Azure App Services kann ebenfalls einzelne Instanzen von Docker-Containern ausführen, was die Bereitstellung vereinfacht. Wenn Sie Docker verwenden, können Sie eine einzelne VM als Docker-Host bereitstellen und mehrere Instanzen ausführen. Wenn Sie wie in Abbildung 5-14 dargestellt den Azure Balancer verwenden, können Sie die Skalierung verwalten.
Die Bereitstellung auf den verschiedenen Hosts kann mit herkömmlichen Bereitstellungsverfahren verwaltet werden. Docker-Hosts können manuell mit Befehlen wie docker run oder durch Automatisierung, z.B. Pipelines für Continuous Delivery (CD), verwaltet werden.
Monolithische Anwendung, die als Container bereitgestellt wird
Das Verwenden von Containern zur Verwaltung monolithischer Anwendungsbereitstellungen hat einige Vorteile. Das Skalieren von Containerinstanzen ist wesentlich schneller und einfacher als die Bereitstellung zusätzlicher VMs. Auch wenn VM-Skalierungsgruppen zum Skalieren von VMs verwendet werden, nimmt deren Erstellung Zeit in Anspruch. Wenn die App-Konfiguration als App-Instanz bereitgestellt wird, wird diese als Teil der VM verwaltet.
Die Bereitstellung von Updates, wie Docker-Images, ist wesentlich schneller und effizienter im Netzwerk. Docker-Images starten in der Regel in Sekunden, wodurch Rollouts beschleunigt werden. Das Löschen einer Docker-Instanz ist genauso einfach wie das Ausführen eines docker stop-Befehls und in der Regel in weniger als einer Sekunde abgeschlossen.
Da Container unveränderlich sind, müssen Sie sich keine Gedanken über beschädigte VMs machen. Updateskripts hingegen berücksichtigen spezifische auf dem Datenträger verbleibende Konfigurationen oder Dateien möglicherweise nicht.
Sie können Docker-Container für die monolithische Bereitstellung einfacherer Webanwendungen verwenden. Dieser Ansatz verbessert die CI/DC-Pipelines (Continuous Integration und Continuous Deployment) und unterstützt Sie bei der erfolgreichen Bereitstellung in der Produktion. Sie müssen sich nie wieder fragen, warum die Anwendung auf Ihrem Computer, aber nicht in der Produktion funktioniert.
Eine auf Microservices basierende Architektur hat viele Vorteile, die jedoch eine erhöhte Komplexität mit sich bringen. In manchen Fällen überwiegen die Kosten die Vorteile. Dann ist die monolithische Bereitstellung einer Anwendung, die in einem einzigen oder in wenigen Containern ausgeführt wird, besser geeignet.
Eine monolithische Anwendung in gut getrennte Microservices zu zerteilen, ist nicht einfach. Microservices sollten unabhängig voneinander funktionieren, um eine widerstandsfähigere Anwendung bereitzustellen. Wenn Sie keine unabhängigen Feature-Slices der Anwendung bereitstellen können, führt das Trennen derselben nur zu erhöhter Komplexität.
Eine Anwendung muss möglicherweise noch keine Features unabhängig voneinander skalieren. Viele Anwendungen können dies mithilfe eines relativ einfachen Prozesses zum Klonen der gesamten Instanz durchführen, wenn sie über eine einzelne Instanz hinaus skaliert werden müssen. Die zusätzliche Arbeit zum Unterteilen der Anwendung in diskrete Dienste bietet minimale Vorteile, wenn die Skalierung von vollständigen Instanzen der Anwendung einfach und kosteneffizient ist.
Zu einem frühen Zeitpunkt während der Entwicklung einer Anwendung haben Sie möglicherweise noch keine Vorstellung davon, wo die natürlichen funktionalen Grenzen liegen. Beim Entwickeln eines mindestens anwendungsfähigen Produkts könnte die natürliche Trennung noch nicht verfügbar sein. Einige dieser Bedingungen können temporär sein. Sie können mit dem Erstellen einer monolithischen Anwendung beginnen und später einige Features trennen, damit diese als Microservices entwickelt und bereitgestellt werden. Andere Bedingungen können entscheidend für den Problembereich der Anwendung sein. Das bedeutet, dass die Anwendung möglicherweise nicht in mehrere Microservices unterteilt werden kann.
Das Trennen einer Anwendung in viele diskrete Prozesse führt außerdem zu Mehraufwand. Durch das Teilen der Features in verschiedene Prozesse wird die Komplexität erhöht. Die Kommunikationsprotokolle werden komplexer. Anstelle von Methodenaufrufen müssen Sie asynchrone Kommunikationen zwischen den Diensten verwenden. Wenn Sie eine Microservices-Architektur verschieben, müssen Sie viele der Bausteine hinzufügen, die in die Microservices-Version der eShopOnContainers-Anwendung implementiert sind: Eventbusbehandlung, Meldungsstabilität und -wiederholungen, Eventual Consistency usw.
Die deutlich einfachere Referenzanwendung eShopOnWeb unterstützt die Verwendung einzelner monolithischer Container. Die Anwendung umfasst eine Webanwendung, die herkömmliche MVC-Ansichten, Web-APIs und Razor Pages enthält. Optional können Sie die Blazor-basierte Verwaltungskomponente der Anwendung ausführen, für die auch ein separates API-Projekt ausgeführt werden muss.
Die Anwendung kann über den Projektmappenstamm mithilfe der Befehle docker-compose build und docker-compose up gestartet werden. Dieser Befehl konfiguriert mithilfe der Dockerfile aus dem Webprojektstamm einen Container für die Webinstanz und führt den Container auf einem angegebenen Port aus. Sie können die Quelle für diese Anwendung von GitHub herunterladen und diese lokal ausführen. Auch die monolithische Anwendung profitiert von der Bereitstellung in einer Containerumgebung.
Durch die Containerumgebung wird jede Instanz der Anwendung in derselben Umgebung ausgeführt. Dieser Ansatz schließt die Entwicklungsumgebung ein, in der die ersten Tests und die Entwicklung stattfinden. Das Entwicklungsteam kann die Anwendung in einer Containerumgebung ausführen, die der Produktionsumgebung entspricht.
Darüber hinaus können containerisierte Anwendungen zu geringeren Kosten aufskaliert werden. Die Verwendung einer Containerumgebung ermöglicht eine größere Ressourcenfreigabe als herkömmliche VM-Umgebungen.
Schließlich erzwingt das Containerisieren einer Anwendung eine Trennung zwischen der Geschäftslogik und dem Speicherserver. Wenn die Anwendung skaliert wird, verwenden alle Container ein einziges physisches Speichermedium. In der Regel ist dieses Speichermedium ein Hochverfügbarkeitsserver, der eine SQL Server-Datenbank ausführt.
Docker-Unterstützung
Der eShopOnWeb-Projekt wird mit .NET Core ausgeführt. Darum kann es entweder auf Linux- oder auf Windows-basierten Containern ausgeführt werden. Beachten Sie, dass Sie für die Docker-Bereitstellung den gleichen Hosttyp für SQL Server verwenden sollten. Linux-basierte Container haben einen geringeren Speicherbedarf und werden bevorzugt.
Sie können Visual Studio 2017 (oder höher) verwenden, um einer vorhandenen Anwendung Docker-Unterstützung hinzuzufügen, indem Sie mit der rechten Maustaste auf ein Projekt im Projektmappen-Explorer und dann auf Hinzufügen>Docker-Unterstützung klicken. Durch diesen Schritt werden die erforderlichen Dateien hinzugefügt, und das Projekt wird so geändert, dass es diese verwendet. Das aktuelle eShopOnWeb-Beispiel enthält diese Dateien bereits.
Die Datei auf Projektmappenebene docker-compose.yml enthält Informationen darüber, welche Images erstellt und welche Container gestartet werden müssen. Die Datei ermöglicht Ihnen die Verwendung des docker-compose-Befehls zum gleichzeitigen Starten mehrerer Anwendungen. In diesem Fall wird nur das Webprojekt gestartet. Sie können sie ebenfalls zum Konfigurieren von Abhängigkeiten verwenden, z.B. für einen separaten Datenbankcontainer.
version: '3'
services:
eshopwebmvc:
image: eshopwebmvc
build:
context: .
dockerfile: src/Web/Dockerfile
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "5106:5106"
networks:
default:
external:
name: nat
Die docker-compose.yml-Datei verweist auf die Dockerfile im Web-Projekt. Die Dockerfile-Datei wird verwendet, um anzugeben, welcher Basiscontainer verwendet und wie die Anwendung darauf konfiguriert wird. Die Dockerfile-Datei von Web:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.sln .
COPY . .
WORKDIR /app/src/Web
RUN dotnet restore
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS runtime
WORKDIR /app
COPY --from=build /app/src/Web/out ./
ENTRYPOINT ["dotnet", "Web.dll"]
Problembehandlung bei Docker
Wenn Sie die Containeranwendung ausführen, wird diese ausgeführt, bis Sie sie beenden. Mit dem Befehl docker ps können Sie anzeigen, welche Container ausgeführt werden. Sie können einen aktiven Container beenden, indem Sie den Befehl docker stop verwenden und die Container-ID angeben.
Beachten Sie, dass ausgeführte Docker-Container an Ports gebunden sein können, die Sie möglicherweise andernfalls in Ihrer Entwicklungsumgebung verwenden. Wenn Sie versuchen, eine Anwendung mit dem gleichen Port auszuführen oder zu debuggen, den ein aktiver Docker-Container verwendet, erhalten Sie eine Fehlermeldung, die angibt, dass der Server nicht an diesen Port gebunden werden kann. Auch hier sollte das Beenden des Containers das Problem beheben.
Wenn Sie Ihrer Anwendung mithilfe von Visual Studio Docker-Unterstützung hinzufügen möchten, stellen Sie sicher, dass Docker Desktop ausgeführt wird, während Sie dies tun. Der Assistent wird nicht ordnungsgemäß ausgeführt, wenn Docker Desktop beim Starten des Assistenten nicht ausgeführt wird. Darüber hinaus überprüft der Assistent Ihre aktuelle Containerwahl, um die richtige Docker-Unterstützung hinzuzufügen. Wenn Sie die Unterstützung von Windows-Containern hinzufügen möchten, müssen Sie den Assistenten ausführen, während Docker Desktop mit konfigurierten Windows-Containern ausgeführt wird. Wenn Sie die Unterstützung von Linux-Containern hinzufügen möchten, führen Sie den Assistenten aus, während Docker mit konfigurierten Linux-Containern ausgeführt wird.
Andere Architekturstile für Webanwendungen
- Web-Queue-Worker: Die Hauptkomponenten dieser Architektur sind ein Web-Front-End, mit dem Clientanforderungen bereitgestellt werden, und ein Worker, der ressourcenintensive Aufgaben, Workflows mit langer Ausführungsdauer oder Batchaufträge durchführt. Das Web-Front-End kommuniziert mit dem Worker über eine Nachrichtenwarteschlange.
- N-Ebene: Eine N-Ebenen-Architektur teilt eine Anwendung in logische und physische Ebenen auf.
- Microservice: Eine Microservicearchitektur besteht aus einer Sammlung kleiner, autonomer Dienste. Jeder Dienst ist eigenständig und sollte eine einzige Geschäftsfunktion in einem begrenzten Kontext implementieren.
Ressourcen: Häufig verwendete Webarchitekturen
- Clean Architecture
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html - Onion Architecture
https://jeffreypalermo.com/blog/the-onion-architecture-part-1/ - The Repository Pattern (Das Muster „Repository“)
https://deviq.com/repository-pattern/ - Clean Architecture Solution Sample (Projektmappenbeispiel unter Verwendung von Clean Architecture)
https://github.com/ardalis/cleanarchitecture - E-Book „Architecting Microservices“ (E-Book zur Architektur von Microservices)
https://aka.ms/MicroservicesEbook - Domänengesteuertes Design (Domain-Driven Design, DDD)
https://learn.microsoft.com/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für