Columnstore-Indizes: Leitfaden zum Datenladevorgang
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Optionen und Empfehlungen für das Laden von Daten mithilfe der Funktion zum SQL-Massenladen in einen Columnstore-Index und Einfügemethoden. Das Laden von Daten in einen Columnstore-Index ist ein wichtiger Teil des Warehousing-Prozesses, da Daten in den Index als Vorbereitung für die Analyse verschoben werden.
Neu bei Columnstore-Indizes? Weitere Informationen finden Sie unter Columnstore indexes - overview (Columnstore-Indizes: Übersicht) und Columnstore Index Architecture (Columnstore-Indizes: Architektur).
Was ist Massenladen?
Massenladen bezieht sich auf die Möglichkeit, eine große Anzahl von Zeilen in einen Datenspeicher hinzuzufügen. Dies ist die leistungsfähigste Methode zum Verschieben von Daten in einen Spaltenspeicherindex, da sie auf Batches von Zeilen ausgeführt wird. Das Massenladen füllt Zeilengruppen bis zur Kapazitätsgrenze auf und komprimiert diese direkt in den Columnstore. Nur Zeilen am Ende eines Ladevorgangs, die nicht mindestens 102.400 Zeilen pro Zeilengruppe erfüllen, werden in den Deltastore verschoben.
Um einen Massenladevorgang auszuführen, können Sie das bcp-Hilfsprogramm oder Integration Services verwenden, oder Sie können Zeilen aus einer Stagingtabelle auswählen.
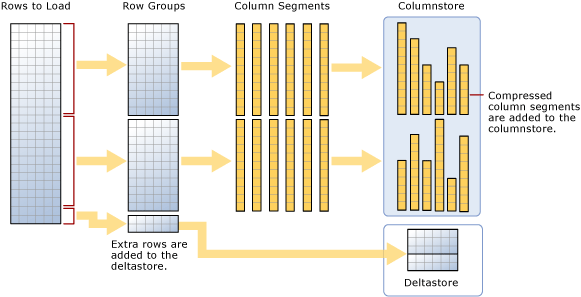
Gemäß dem Diagramm gilt Folgendes für das Massenladen:
- Die Daten werden nicht vorsortiert. Daten werden in Zeilengruppen in der Reihenfolge eingefügt, in der sie empfangen wird.
- Wenn die Batchgröße = 102400 ist >, werden die Zeilen direkt in die komprimierten Zeilengruppen geladen. Sie sollten eine Batchgröße >=102400 für einen effizienten Massenimport auswählen, da Sie das Verschieben von Datenzeilen in Delta-Zeilengruppen vermeiden können, bevor die Zeilen schließlich durch einen Hintergrundthread in komprimierte Zeilengruppen verschoben werden, Tupel-Mover (TM).
- Wenn die Batchgröße < 102.400 oder die neu Standard zeilen 102.400 sind<, werden die Zeilen in Delta-Zeilengruppen geladen.
Hinweis
In einer Rowstore-Tabelle mit nicht gruppierten Spaltenspeicherindexdaten fügt SQL Server immer Daten in die Basistabelle ein. Die Daten werden nie direkt in den Columnstore-Index eingefügt.
Das Massenladen verfügt über diese integrierten Leistungsoptimierungen:
Parallele Ladevorgänge: Sie können mehrere gleichzeitige Massenladevorgänge (bcp oder Masseneinfügung) haben, die jeweils eine separate Datendatei laden. Im Gegensatz zu Massenladevorgängen von Rowstores in SQL Server müssen Sie nicht angeben
TABLOCK, da jeder Massenimportthread Daten exklusiv in separate Zeilengruppen (komprimierte oder Delta-Zeilengruppen) mit exklusiver Sperrung lädt.Reduzierte Protokollierung: Die Daten, die direkt in komprimierte Zeilengruppen geladen werden, führen zu einer erheblichen Verringerung der Größe des Protokolls. Wenn z. B. Daten 10x komprimiert wurden, ist das entsprechende Transaktionsprotokoll ungefähr 10x kleiner, ohne TABLOCK oder Massenprotokollierung/Einfaches Wiederherstellungsmodell zu benötigen. Alle Daten, die in eine Delta-Zeilengruppe gehen, werden vollständig protokolliert. Dies schließt alle Batchgrößen ein, die weniger als 102.400 Zeilen sind. Bewährte Methode ist die Verwendung der Batchgröße >= 102400. Da kein TABLOCK erforderlich ist, können Sie die Daten parallel laden.
Minimale Protokollierung: Sie können die Protokollierung weiter reduzieren, wenn Sie die Voraussetzungen für die minimale Protokollierung einhalten. Im Gegensatz zum Laden von Daten in einen Rowstore führt TABLOCK jedoch zu einer X-Sperre in der Tabelle und nicht zu einer BU-Sperre (Massenaktualisierung), und daher können parallele Daten nicht geladen werden. Weitere Informationen zu Sperren finden Sie unter Sperren und Zeilenversionsverwaltung.
Sperroptimierung: Die X-Sperre einer Zeilengruppe wird automatisch erfasst, wenn Daten in eine komprimierte Zeilengruppe geladen werden. Beim Massenladen in eine Delta-Zeilengruppe wird jedoch eine X-Sperre in der Rowgroup abgerufen, aber SQL Server sperrt weiterhin die PAGE/EXTENT, da die X-Zeilengruppensperre nicht Teil der Sperrhierarchie ist.
Wenn Sie über einen nicht gruppierten B-Strukturindex für einen Columnstore-Index verfügen, gibt es keine Sperr- oder Protokollierungsoptimierung für den Index selbst, aber die Optimierungen für den gruppierten Columnstore-Index, wie zuvor beschrieben, sind anwendbar.
Datenänderung (Einfügen, Löschen, Aktualisieren) ist kein Batchmodusvorgang, da sie nicht parallel ist.
Planen von Massenladungsgrößen zum Minimieren von Delta-Zeilengruppen
Columnstore-Indizes sind am leistungsfähigsten, wenn die meisten Zeilen in den Columnstore komprimiert werden und sich nicht in Delta-Zeilengruppen befinden. Es wird empfohlen, die Größe Ihrer Ladungen so anzupassen, dass Zeilen direkt in den Columnstore verschoben werden und den Deltastore so weit wie möglich umgehen.
Diese Szenarien beschreiben, in welchen Fällen geladene Zeilen direkt in den Columnstore und in welchen Fällen sie in den Deltastore aufgenommen werden. In diesem Beispiel kann jede Zeilengruppe 102.400 bis 1.048.576 Zeilen pro Zeilengruppe enthalten. In der Praxis kann die maximale Größe einer Zeilengruppe kleiner als 1.048.576 Zeilen sein, wenn ein Arbeitsspeicherdruck besteht.
| Zeilen zum Massenladen | Zeilen, die der komprimierten Zeilengruppe hinzugefügt wurden | Zeilen, die der Delta-Zeilengruppe hinzugefügt wurden |
|---|---|---|
| 102.000 | 0 | 102.000 |
| 145,000 | 145,000 Zeilengruppengröße: 145.000. |
0 |
| 1,048,577 | 1,048,576 Zeilengruppengröße: 1.048.576. |
1 |
| 2,252,152 | 2,252,152 Zeilengruppengrößen: 1.048.576, 1.048.576, 155.000. |
0 |
Im folgenden Beispiel werden die Ergebnisse des Ladens von 1.048.577 Zeilen in eine Tabelle angezeigt. Aus den Ergebnissen wird ersichtlich, dass eine COMPRESSED-Zeilengruppe im Columnstore (in Form von komprimierten Spaltensegmenten) und eine Zeile im Deltastore vorhanden sind.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Verwenden einer Stagingtabelle zum Verbessern der Leistung
Wenn Sie Daten nur so laden, dass sie vor dem Ausführen weiterer Transformationen ausgeführt werden, ist das Laden der Tabelle in die Heap-Tabelle wesentlich schneller als das Laden der Daten in eine gruppierte Columnstore-Tabelle. Darüber hinaus wird das Laden von Daten in eine [temporäre Tabelle] [temporär] auch viel schneller sein als das Laden einer Tabelle für die permanente Speicherung.
Ein gängiges Muster für das Laden von Daten besteht darin, die Daten in eine Stagingtabelle zu laden, eine Transformation auszuführen und dann mithilfe des folgenden Befehls in die Zieltabelle zu laden:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Mit diesem Befehl werden die Daten auf ähnliche Weise in den Columnstore-Index geladen wie bcp oder Masseneinfügung, aber in einem einzigen Batch. Wenn die Anzahl der Zeilen in der Stagingtabelle < 102400 in eine Delta-Zeilengruppe geladen wird, andernfalls werden die Zeilen direkt in komprimierte Zeilengruppe geladen. Eine entscheidende Einschränkung bestand darin, dass dieser INSERT-Vorgang nur einen einzelnen Thread umfasste. Zum parallelen Laden der Daten könnten Sie mehrere Stagingtabellen erstellen, oder INSERT/SELECT mit nicht überlappenden Zeilenbereichen aus der Stagingtabelle ausgeben. Diese Einschränkung ist mit SQL Server 2016 (13.x) nicht mehr möglich. Mit dem folgenden Befehl werden die Daten parallel aus der Stagingtabelle geladen, sie müssen jedoch angegeben werden TABLOCK. Dies erscheint Ihnen möglicherweise im Widerspruch zu den zuvor genannten Informationen zum Massenladen, der Hauptunterschied liegt jedoch darin, dass der parallele Datenladevorgang aus der Stagingtabelle in derselben Transaktion ausgeführt wird.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Beim Laden in einen gruppierten Columnstore-Index aus staging-Tabelle stehen folgende Optimierungen zur Verfügung:
- Protokolloptimierung: Reduzierte Protokollierung, wenn die Daten in eine komprimierte Zeilengruppe geladen werden.
- Sperroptimierung: Beim Laden von Daten in eine komprimierte Zeilengruppe wird die X-Sperre für rowgroup abgerufen. Bei der Delta-Zeilengruppe wird jedoch eine X-Sperre in der Rowgroup abgerufen, SQL Server sperrt jedoch weiterhin die SPERREN PAGE/EXTENT, da die X-Zeilengruppensperre nicht Teil der Sperrhierarchie ist.
Wenn Sie über einen oder mehrere nicht gruppierte Indizes verfügen, gibt es keine Sperr- oder Protokollierungsoptimierung für den Index selbst, aber die Optimierungen im gruppierten Columnstore-Index, wie zuvor beschrieben, sind noch vorhanden.
Was ist das Anwenden der Einfügung?
Das Anwenden der Einfügung bezieht sich auf die Methode, wie einzelne Zeilen in den Columnstore-Index verschoben werden. Das Anwenden der Einfügung verwendet die INSERT INTO-Anweisung. Mit der Einfügungsanwendung werden alle Zeilen in den Deltastore verschoben. Dies ist nützlich für eine kleine Anzahl von Zeilen, aber für große Datenmengen nicht geeignet.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Hinweis
Parallele Threads, die INSERT INTO zum Einfügen von Werten in einen gruppierten Columnstore-Index verwenden, können Zeilen in dieselbe Deltazeilengruppe einfügen.
Sobald die Zeilengruppe 1.048.576 Zeilen enthält, wurde die Delta-Zeilengruppe als geschlossen markiert, ist aber weiterhin für Abfragen und Aktualisierungs-/Löschvorgänge verfügbar, aber die neu eingefügten Zeilen gehen in eine vorhandene oder neu erstellte Deltastore-Zeilengruppe. Es gibt einen Hintergrundthread Tuple Mover (TM), der die geschlossenen Delta-Zeilengruppen in regelmäßigen Abständen alle 5 Minuten komprimiert. Sie können den folgenden Befehl explizit aufrufen, um die geschlossene Delta-Zeilengruppe zu komprimieren.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Wenn Sie eine delta rowgroup geschlossen und komprimiert erzwingen möchten, können Sie den folgenden Befehl ausführen. Sie können diesen Befehl ausführen, wenn Sie mit dem Laden der Zeilen fertig sind und keine neuen Zeilen erwarten. Durch explizites Schließen und Komprimieren der Delta-Zeilengruppe können Sie weiteren Speicherplatz sparen und die Abfrageleistung für Analysen verbessern. Eine bewährte Methode ist das Aufrufen dieses Befehls, wenn Sie nicht erwarten, dass weitere neue Zeilen eingefügt werden.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
So funktioniert das Laden in eine partitionierte Tabelle
Bei partitionierten Daten weist SQL Server zunächst jede Zeile einer Partition zu und führt dann Spaltenspeichervorgänge für die Daten innerhalb der Partition aus. Jede Partition verfügt über eigene Zeilengruppen und mindestens eine Delta-Zeilengruppe.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für