OneLake-Verknüpfungen
Mit Verknüpfungen in Microsoft OneLake können Sie Ihre Daten domänen-, cloud- und kontoübergreifend vereinheitlichen, indem Sie einen einzelnen virtualisierten Data Lake für Ihr gesamtes Unternehmen erstellen. Alle Fabric-Erfahrungen und Analyse-Engines können über einen einheitlichen Namespace eine direkte Verbindung mit Ihren vorhandenen Datenquellen wie Azure, Amazon Web Services (AWS) und OneLake herstellen. OneLake verwaltet alle Berechtigungen und Anmeldeinformationen, sodass Sie nicht jede Fabric Workload separat konfigurieren müssen, um eine Verbindung mit jeder Datenquelle herzustellen. Darüber hinaus können Sie Verknüpfungen verwenden, um Edgekopien von Daten zu vermeiden und die Prozesslatenz im Zusammenhang mit Datenkopien und Staging zu verringern.
Was sind Verknüpfungen?
Verknüpfungen sind Objekte in OneLake, die auf andere Speicherorte verweisen. Der Speicherort kann intern oder extern in Bezug auf OneLake sein. Der Speicherort, auf den eine Verknüpfung verweist, wird als Zielpfad der Verknüpfung bezeichnet. Der Speicherort, an dem die Verknüpfung angezeigt wird, wird als Verknüpfungspfad bezeichnet. Verknüpfungen werden in OneLake als Ordner angezeigt und kann von allen Workloads oder Diensten verwendet werden, die Zugriff auf OneLake haben. Verknüpfungen verhalten sich wie symbolische Verknüpfungen. Sie sind ein vom Ziel unabhängiges Objekt. Wenn Sie eine Verknüpfung löschen, bleibt das Ziel davon unberührt. Wenn Sie einen Zielpfad verschieben, umbenennen oder löschen, kann die Verknüpfung unterbrochen werden.

Wo kann ich Verknüpfungen erstellen?
Sie können Verknüpfungen in Lakehouses und Kusto Query Language (KQL)-Datenbanken erstellen. Darüber hinaus können die in diesen Elementen erstellten Verknüpfungen auf andere OneLake-Standorte, Azure Data Lake Storage (ADLS Gen2), Amazon S3-Speicherkonten oder Dataverse verweisen.
Sie können die Fabric-Benutzeroberfläche verwenden, um Verknüpfungen interaktiv zu erstellen, und Sie können die REST-API zum programmgesteuerten Erstellen von Verknüpfungen verwenden.
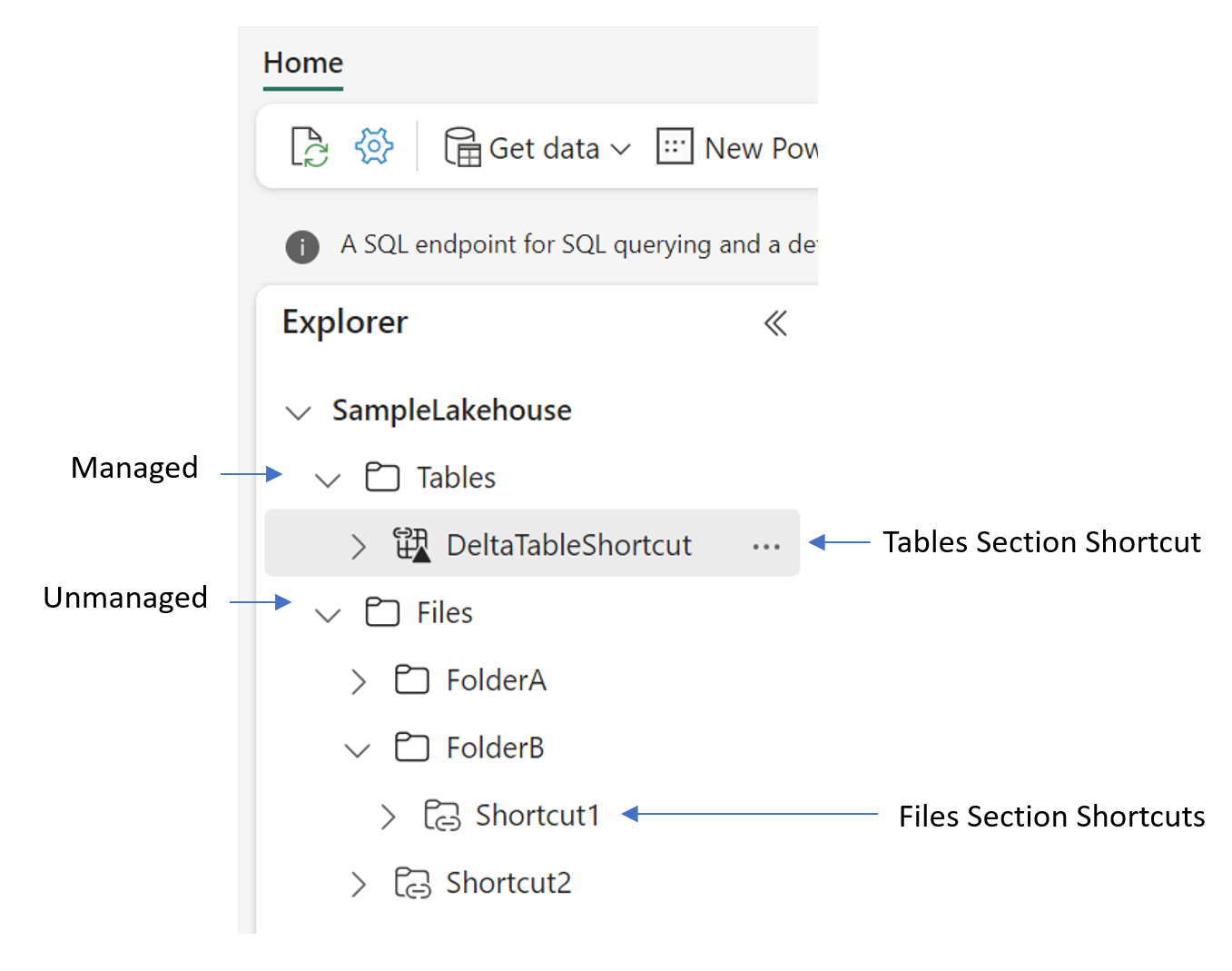
Lakehouse
Beim Erstellen von Verknüpfungen in einem Lakehouse müssen Sie die Ordnerstruktur des Elements verstehen. Lakehouses bestehen aus zwei Ordnern der obersten Ebene: dem Ordner Tables (Tabellen) und dem Ordner Files (Dateien). Der Ordner Tables stellt den verwalteten Teil des Lakehouse dar, während der Ordner Files der nicht verwaltete Teil des Lakehouse ist. Im Ordner Tables können Sie nur Verknüpfungen auf der obersten Ebene erstellen. Verknüpfungen werden in anderen Unterverzeichnissen des Ordners Tables nicht unterstützt. Wenn das Ziel der Verknüpfung Daten im Delta\Parquet-Format enthält, synchronisiert Lakehouse die Metadaten automatisch und erkennt den Ordner als Tabelle (Table). Im Ordner Files gibt es keine Einschränkungen dafür, wo Sie Verknüpfungen erstellen können. Sie können sie auf jeder Ebene der Ordnerhierarchie erstellen. Im Ordner Files erfolgt keine Tabellenermittlung.
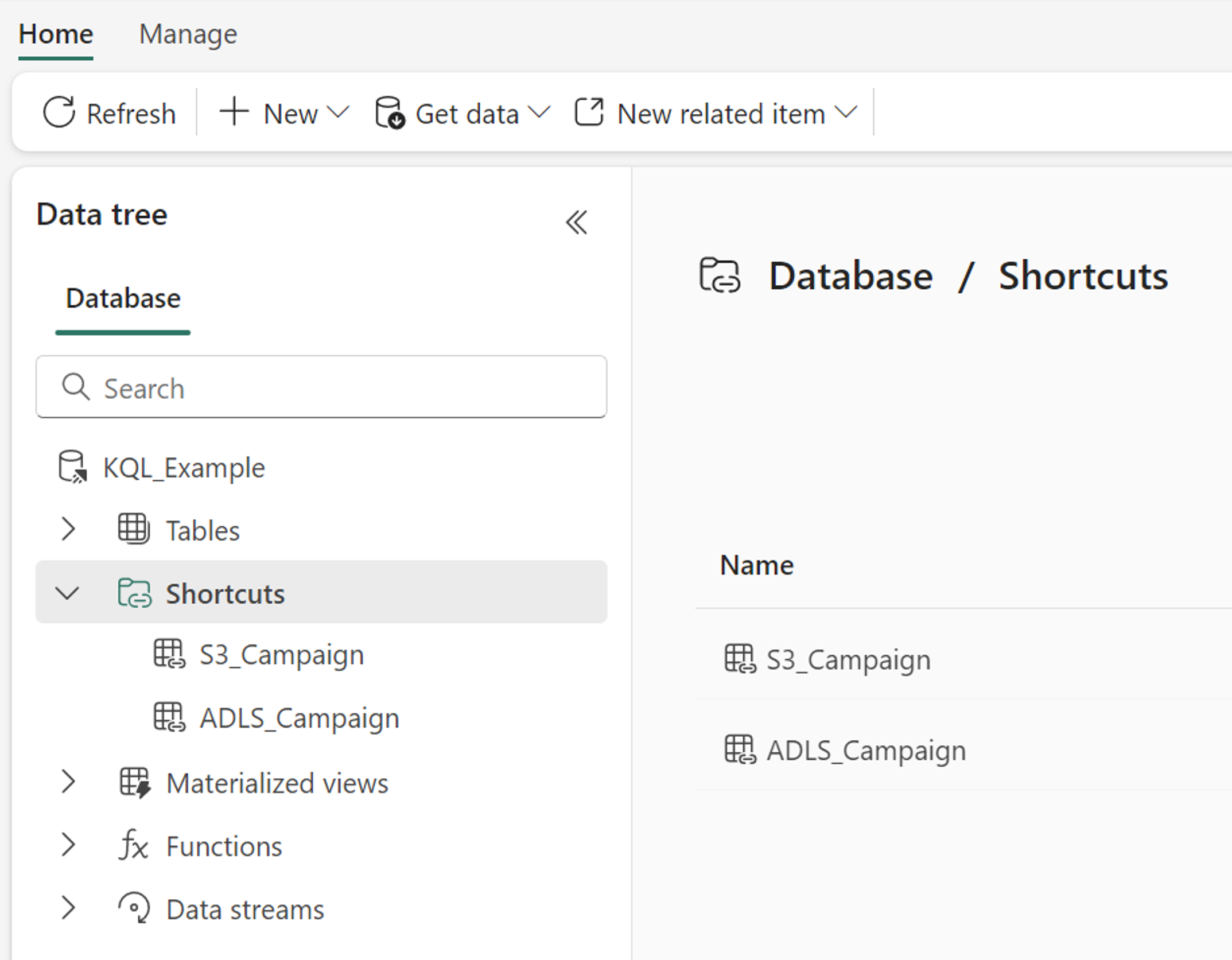
KQL-Datenbank
Wenn Sie eine Verknüpfung in einer KQL-Datenbank erstellen, wird sie im Ordner Shortcuts (Verknüpfungen) der Datenbank angezeigt. Die KQL-Datenbank behandelt Verknüpfungen wie externe Tabellen. Um die Verknüpfung abzufragen, verwenden Sie die Funktion external_table der Kusto-Abfragesprache (KQL).
Wo kann ich auf meine Verknüpfungen zugreifen?
Jeder Fabric- oder Nicht-Fabric-Dienst, der auf Daten in OneLake zugreifen kann, kann Verknüpfungen nutzen. Verknüpfungen sind für jeden Dienst transparent, der über die OneLake-API auf Daten zugreift. Verknüpfungen werden schlicht wie ein anderer Ordner im Lake angezeigt. Spark, SQL, Echtzeitanalyse und Analysis Services können Verknüpfungen beim Abfragen von Daten nutzen.
Spark
Spark-Notebooks und Spark-Aufträge können Verknüpfungen nutzen, die Sie in OneLake erstellt haben. Relative Dateipfade können verwendet werden, um Daten direkt aus Verknüpfungen zu lesen. Wenn Sie eine Verknüpfung im Abschnitt Tables (Tabellen) von Lakehouse erstellen und sie im Deltaformat vorliegt, können Sie sie auch als verwaltete Tabelle mithilfe der Spark SQL-Syntax lesen.
df = spark.read.format("delta").load("Tables/MyShortcut")
display(df)
df = spark.sql("SELECT * FROM MyLakehouse.MyShortcut LIMIT 1000")
display(df)
Hinweis
Das Deltaformat unterstützt keine Tabellen mit Leerzeichen im Namen. Jede Verknüpfung, die ein Leerzeichen im Namen enthält, wird im Lakehouse nicht als Deltatabelle ermittelt.
SQL
Sie können Verknüpfungen im Abschnitt Tables (Tabellen) von Lakehouse auch über den SQL-Analyseendpunkt für Lakehouse lesen. Sie können über die Modusauswahl des Lakehouse oder über SQL Server Management Studio (SSMS) auf den SQL-Analyseendpunkt zugreifen.
SELECT TOP (100) *
FROM [MyLakehouse].[dbo].[MyShortcut]
Echtzeitanalysen
Verknüpfungen in KQL-Datenbanken werden als externe Tabellen erkannt. Um die Verknüpfung abzufragen, verwenden Sie die Funktion external_table der Kusto-Abfragesprache (KQL).
external_table('MyShortcut')
| take 100
Analysis Services
Sie können semantische Modelle für Lakehouses, die Verknüpfungen enthalten, im Abschnitt Tables (Tabellen) des Lakehouse erstellen. Wenn das semantische Modell im Direct Lake-Modus ausgeführt wird, kann Analysis Services Daten direkt aus der Verknüpfung lesen.
Nicht-Fabric
Anwendungen und Dienste außerhalb von Fabric können auch über die OneLake-API auf Verknüpfungen zugreifen. OneLake unterstützt eine Teilmenge der ADLS Gen2- und Blob Storage-APIs. Weitere Informationen zur OneLake-API finden Sie unter OneLake-Zugriff mit APIs.
https://onelake.dfs.fabric.microsoft.com/MyWorkspace/MyLakhouse/Tables/MyShortcut/MyFile.csv
Typen von Verknüpfungen
OneLake-Verknüpfungen unterstützen mehrere Dateisystem-Datenquellen. Dazu gehören interne OneLake-Standorte, Azure Data Lake Storage (ADLS) Gen2, Amazon S3 und Dataverse.
Interne OneLake-Verknüpfungen
Mit internen OneLake-Verknüpfungen können Sie auf Daten in vorhandenen Fabric-Elementen verweisen. Zu diesen Elementen gehören Lakehouses, KQL-Datenbanken und Data Warehouses. Die Verknüpfung kann auf einen Ordnerspeicherort innerhalb desselben Elements, zwischen Elementen innerhalb desselben Arbeitsbereichs oder sogar zwischen Elementen in verschiedenen Arbeitsbereichen verweisen. Wenn Sie eine Verknüpfung zwischen Elementen erstellen, müssen die Elementtypen nicht übereinstimmen. Beispielsweise können Sie in einem Lakehouse eine Verknüpfung erstellen, die auf Daten in einem Data Warehouse verweist.
Wenn ein Benutzer über eine Verknüpfung zu einem anderen OneLake-Speicherort auf Daten zugreift, wird die Identität des aufrufenden Benutzers verwendet, um den Zugriff auf die Daten im Zielpfad der Verknüpfung* zu autorisieren. Dieser Benutzer muss über Berechtigungen am Zielspeicherort verfügen, um die Daten lesen zu können.
Wichtig
Beim Zugriff auf Tastenkombinationen über Power BI-Semantikmodelle oder T-SQL wird die Identität des aufrufenden Benutzers nicht an das Verknüpfungsziel übergeben. Stattdessen wird die Identität des Besitzers des aufrufenden Elements übergeben und der Zugriff an den aufrufenden Benutzer delegiert.
ADLS-Verknüpfungen
Verknüpfungen können auch für ADLS Gen2-Speicherkonten erstellt werden. Wenn Sie Verknüpfungen mit ADLS erstellen, kann der Zielpfad auf einen beliebigen Ordner im hierarchischen Namespace verweisen. Der Zielpfad muss mindestens einen Containernamen enthalten.
Access
ADLS-Verknüpfungen müssen auf den DFS-Endpunkt für das Speicherkonto verweisen.
Beispiel: https://accountname.dfs.core.windows.net/
Wenn das Speicherkonto durch eine Speicherfirewall geschützt ist, können Sie den Zugriff auf vertrauenswürdige Dienste konfigurieren. Siehe Zugriff auf vertrauenswürdige Arbeitsbereiche.
Autorisierung
ADLS-Verknüpfungen verwenden ein delegiertes Autorisierungsmodell. In diesem Modell gibt der Ersteller der Verknüpfung Anmeldeinformationen für die ADLS-Verknüpfung an, und der gesamte Zugriff auf diese Verknüpfung wird mit diesen Anmeldeinformationen autorisiert. Die unterstützten delegierten Typen sind Organisationskonto, Kontoschlüssel, Shared Access Signature (SAS) und Dienstprinzipal.
- Organisationskonto: Muss die Rolle „Leser von Speicherblobdaten“, „Mitwirkender an Speicherblobdaten“ oder „Besitzer von Speicherblobdaten“ für das Speicherkonto besitzen
- Shared Access Signature (SAS): Muss mindestens die folgenden Berechtigungen enthalten: „Lesen“, „Auflisten“ und „Ausführen“ (Read, List, Execute)
- Dienstprinzipal: Muss die Rolle „Leser von Speicherblobdaten“, „Mitwirkender an Speicherblobdaten“ oder „Besitzer von Speicherblobdaten“ für das Speicherkonto besitzen
Hinweis
Sie müssen hierarchische Namespaces auf Ihrem ADLS Gen 2 Speicherkonto aktiviert haben.
S3-Verknüpfungen
Sie können auch Verknüpfungen mit Amazon S3-Konten erstellen. Wenn Sie Verknüpfungen mit Amazon S3 erstellen, muss der Zielpfad mindestens einen Bucketnamen enthalten. S3 unterstützt hierarchische Namespaces nicht nativ, aber Sie können Präfixe verwenden, um eine Verzeichnisstruktur nachzuahmen. Sie können Präfixe in den Verknüpfungspfad einschließen, um den Datenbereich, auf den über die Verknüpfung zugegriffen werden kann, weiter einzuschränken. Beim Zugriff auf Daten über eine S3-Verknüpfung werden Präfixe als Ordner dargestellt.
Access
S3-Verknüpfungen müssen auf den HTTPS-Endpunkt für den S3-Bucket verweisen.
Beispiel: https://bucketname.s3.region.amazonaws.com/
Hinweis
Sie müssen die Einstellung für den öffentlichen Zugriff von S3 für Ihr S3-Konto für die S3-Verknüpfung zur Funktion nicht deaktivieren.
Der Zugriff auf den S3-Endpunkt darf nicht durch eine Speicherfirewall oder virtuelle private Cloud blockiert werden.
Autorisierung
S3-Verknüpfungen verwenden ein delegiertes Autorisierungsmodell. In diesem Modell gibt der Ersteller der Verknüpfung Anmeldeinformationen für die S3-Verknüpfung an, und der gesamte Zugriff auf diese Verknüpfung wird mit diesen Anmeldeinformationen autorisiert. Die unterstützten delegierten Anmeldeinformationen sind Schlüssel und Geheimnis für einen IAM-Benutzer.
Der IAM-Benutzer muss über die folgenden Berechtigungen für den Bucket verfügen, auf den die Verknüpfung verweist.
S3:GetObjectS3:GetBucketLocationS3:ListBucket
Hinweis
S3-Verknüpfungen sind schreibgeschützt. Sie unterstützen keine Schreibvorgänge, unabhängig von den Berechtigungen für den IAM-Benutzer.
Google Cloud-Speicher Verknüpfungen (Vorschau)
Verknüpfungen können mithilfe der XML-API für GCS zu Google Cloud-Speicher (GCS) erstellt werden. Wenn Sie Verknüpfungen mit Google Cloud-Speicher erstellen, muss der Zielpfad mindestens einen Bucketnamen enthalten. Sie können auch den Bereich der Verknüpfung einschränken, indem Sie das Präfix/den Ordner angeben, auf das Sie innerhalb der Speicherhierarchie verweisen möchten.
Access
Beim Konfigurieren der Verbindung für eine GCS-Verknüpfung können Sie entweder den globalen Endpunkt für den Storagedienst angeben oder einen bucketspezifischen Endpunkt verwenden.
- Beispiel für globalen Endpunkt:
https://storage.googleapis.com - Beispiel für bucketspezifischen Endpunkt:
https://<BucketName>.storage.googleapis.com
Autorisierung
GCS-Verknüpfungen verwenden ein delegiertes Autorisierungsmodell. In diesem Modell gibt der Ersteller der Verknüpfung Anmeldeinformationen für die GCS-Verknüpfung an, und der gesamte Zugriff auf diese Verknüpfung wird mit diesen Anmeldeinformationen autorisiert. Die unterstützten delegierten Anmeldedaten sind ein HMAC-Schlüssel und geheimer Schlüssel für ein Dienstkonto oder Benutzerkonto.
Das Konto muss über die Berechtigung zum Zugriff auf die Daten im GCS-Bucket verfügen. Wenn der bucketspezifische Endpunkt in der Verbindung für die Verknüpfung verwendet wurde, muss das Konto über die folgenden Berechtigungen verfügen:
storage.objects.getstoage.objects.list
Wenn der globale Endpunkt in der Verbindung für die Verknüpfung verwendet wurde, muss das Konto auch über die folgende Berechtigung verfügen:
storage.buckets.list
Hinweis
GCS-Verknüpfungen sind schreibgeschützt. Sie unterstützen keine Schreibvorgänge, unabhängig von den Berechtigungen für das verwendete Konto.
Dataverse-Verknüpfungen
Die direkte Integration von Dataverse in Microsoft Fabric ermöglicht es Organisationen, ihre Dynamics 365-Unternehmensanwendungen und Geschäftsprozesse in Fabric zu erweitern. Diese Integration erfolgt über Verknüpfungen, die auf zwei Arten erstellt werden können: über das PowerApps-Herstellerportal oder direkt über Fabric.
Erstellen von Verknüpfungen über das PowerApps-Herstellerportal
Autorisierte PowerApps-Benutzer*innen können auf das PowerApps-Herstellerportal zugreifen und das Feature Mit Microsoft Fabric verknüpfen verwenden. Mit dieser Einzelaktion wird ein Lakehouse in Fabric erstellt, zudem werden automatisch Verknüpfungen für alle Tabellen in der Dataverse-Umgebung generiert. Weitere Informationen finden Sie unter Direkte Dataverse-Integration in Microsoft Fabric.
Erstellen von Verknüpfungen über Fabric
Fabric-Benutzer*innen können außerdem Verknüpfungen mit Dataverse erstellen. Über die Oberfläche zum Erstellen von Verknüpfungen können Benutzer*innen Dataverse auswählen, die Umgebungs-URL angeben und die verfügbaren Tabellen durchsuchen. Dort können Benutzer*innen selektiv auswählen, welche Tabellen in Fabric eingefügt werden sollen, anstatt alle Tabellen einzufügen.
Hinweis
Dataverse-Tabellen müssen zuerst im Dataverse Managed Lake verfügbar sein, erst dann sind sie in der Fabric-Oberfläche zum Erstellen von Verknüpfungen sichtbar. Wenn die Tabellen in Fabric nicht sichtbar sind, nutzen Sie das Feature Mit Microsoft Fabric verknüpfen im PowerApps-Herstellerportal.
Autorisierung
Dataverse-Verknüpfungen verwenden ein delegiertes Autorisierungsmodell. In diesem Modell gibt der Ersteller der Verknüpfung Anmeldedaten für die Dataverse-Verknüpfung an, und der gesamte Zugriff auf die betreffende Verknüpfung wird mit diesen Anmeldedaten autorisiert. Der unterstützte delegierte Anmeldeinformationstyp ist Organisationskonto (OAuth2). Das Organisationskonto muss über die Systemadministratorberechtigung für den Zugriff auf Daten in Dataverse Managed Lake verfügen.
Hinweis
Dienstprinzipale werden derzeit für die Dataverse-Tastenkombinationsautorisierung nicht unterstützt.
Caching
Das Zwischenspeichern von Tastenkombinationen kann dazu verwendet werden, die Egress-Kosten für den cloudübergreifenden Datenzugriff zu senken Wenn Dateien über eine externe Verknüpfung gelesen werden, werden die Dateien in einem Cache für den Fabric-Arbeitsbereich gespeichert. Nachfolgende Leseanforderungen werden nicht vom Remotespeicher-Anbieter, sondern aus dem Cache bereitgestellt. Cachedateien haben einen Aufbewahrungszeitraum von 24 Stunden. Jedes Mal, wenn auf die Datei zugegriffen wird, wird der Aufbewahrungszeitraum zurückgesetzt. Wenn die Datei des Remotespeicher-Anbieters aktueller ist als die Datei im Cache, wird die Anforderung vom Remotespeicher-Anbieter erfüllt und die aktualisierte Datei im Cache zwischengespeichert. Wenn länger als 24 Stunden nicht auf eine Datei zugegriffen wurde, wird sie aus dem Zwischenspeicher gelöscht. Einzelne Dateien, die größer als 1 GB sind, werden nicht zwischengespeichert.
Hinweis
Das Zwischenspeichern von Verknüpfungen wird derzeit nur für GCS-, S3- und S3-kompatible-Verknüpfungen unterstützt.
Um die Zwischenspeicherung für Verknüpfungen zu aktivieren, öffnen Sie bitte den Bereich „Arbeitsbereichseinstellungen“. Wählen Sie die Registerkarte „OneLake“ aus. Schalten Sie die Zwischenspeicherungseinstellung auf „Ein“ um, und klicken Sie auf „Speichern“.

Verwendungsweise von Cloudverbindungen durch Verknüpfungen
Die ADLS- und S3-Verknüpfungsautorisierung wird mithilfe von Cloudverbindungen delegiert. Beim Erstellen einer neuen ADLS- oder S3-Verknüpfung erstellen Sie entweder eine neue Verbindung oder wählen eine vorhandene Verbindung für die Datenquelle aus. Das Festlegen einer Verbindung für eine Verknüpfung ist ein Bindungsvorgang. Nur Benutzer mit der Berechtigung für die Verbindung können den Bindungsvorgang ausführen. Wenn Sie nicht über Berechtigungen für die Verbindung verfügen, können Sie keine neuen Verknüpfungen mit dieser Verbindung erstellen.
Berechtigungen
Eine Kombination aus den Berechtigungen im Verknüpfungspfad und im Zielpfad regelt die Berechtigungen für Verknüpfungen. Wenn ein Benutzer auf eine Verknüpfung zugreift, wird die restriktivste Berechtigung der beiden Speicherorte angewendet. Daher darf ein Benutzer, der über Lese-/Schreibberechtigungen im Lakehouse verfügt, aber nur über Leseberechtigungen im Verknüpfungsziel, nicht in den Verknüpfungszielpfad schreiben. Ebenso darf ein Benutzer, der nur über Leseberechtigungen im Lakehouse verfügt, aber über Lese-/Schreibberechtigungen im Verknüpfungsziel, auch nicht in den Verknüpfungszielpfad schreiben.
Arbeitsbereichsrollen
In der folgenden Tabelle sind die verknüpfungsbezogenen Berechtigungen für die jeweilige Arbeitsbereichsrolle aufgeführt. Weitere Informationen finden Sie unter Arbeitsbereichsrollen.
| Funktion | Administrator | Member | Mitwirkender | Viewer |
|---|---|---|---|---|
| Eine Verknüpfung erstellen | Ja1 | Ja1 | Ja1 | - |
| Lesen von Datei-/Ordnerinhalten der Verknüpfung | Ja2 | Ja2 | Ja2 | - |
| Schreiben an den Zielspeicherort der Verknüpfung | Ja3 | Ja3 | Ja3 | - |
| Lesen von Daten aus Verknüpfungen im Tabellenabschnitt (table) des Lakehouse über den TDS-Endpunkt | Ja | Ja | Ja | Ja |
1 Benutzer müssen über eine Rolle verfügen, die Schreibberechtigung für den Verknüpfungsspeicherort und mindestens Leseberechtigung für den Zielspeicherort bereitstellt.
2 Benutzer müssen über eine Rolle verfügen, die Leseberechtigung sowohl am Verknüpfungs- als auch am Zielspeicherort bereitstellt.
3 Benutzer müssen über eine Rolle verfügen, die Schreibberechtigung sowohl am Verknüpfungs- als auch am Zielspeicherort bereitstellt.
OneLake-Datenzugriffsrollen (Vorschau)
OneLake-Datenzugriffsrollen ist ein neues Feature, mit dem Sie rollenbasierte Zugriffssteuerung (RBAC) auf Ihre in OneLake gespeicherten Daten anwenden können. Sie können Sicherheitsrollen definieren, die Lesezugriff auf bestimmte Ordner innerhalb eines Fabric-Elements gewähren und diese Benutzern oder Gruppen zuweisen. Die Zugriffsberechtigungen bestimmen, welche Ordner Benutzer beim Zugriff auf die Lakeanzeige der Daten sehen, entweder über die Lakehouse-UX, Notebooks oder OneLake-APIs. Bei Elementen mit aktivierter Previewfunktion bestimmen OneLake-Datenzugriffsrollen auch den Zugriff eines Benutzers auf eine Verknüpfung.
Benutzer in den Rollen Administrator, Mitglied und Mitwirkender haben vollständigen Zugriff auf Daten aus einer Verknüpfung, unabhängig von den definierten OneLake-Datenzugriffsrollen. Sie benötigen jedoch weiterhin Zugriff auf die Quelle und das Ziel der Verknüpfung, wie in Arbeitsbereichsrollen erwähnt.
Benutzer in der Rolle Zuschauer oder die ein für sie freigegebenes Lakehouse haben, haben Zugriffseinschränkung, je nachdem, ob der Benutzer über eine OneLake-Datenzugriffsrolle Zugriff hat. Weitere Informationen zum Zugriffssteuerungsmodell mit Verknüpfungen finden Sie unter Modell zur Datenzugriffssteuerung in OneLake.
Wie handhaben Verknüpfungen Löschungen?
Verknüpfungen führen keine kaskadierenden Löschvorgänge durch. Wenn Sie einen Löschvorgang für eine Verknüpfung ausführen, löschen Sie nur das Verknüpfungsobjekt. Die Daten am Verknüpfungsziel bleiben unverändert. Wenn Sie jedoch einen Löschvorgang für eine Datei oder einen Ordner innerhalb einer Verknüpfung ausführen und am Verknüpfungsziel über Berechtigungen zum Ausführen des Löschvorgangs verfügen, werden die Dateien und/oder Ordner am Ziel gelöscht. Das folgende Beispiel zeigt dieses Problem.
Beispiel für Löschen
Benutzer A verfügt über ein Lakehouse mit dem folgenden darin enthaltenen Pfad:
MyLakehouse\Files\MyShortcut\Foo\Bar
MyShortcut ist eine Verknüpfung, die auf ein ADLS Gen2-Konto verweist, das die Verzeichnisse Foo\Bar enthält.
Löschen eines Verknüpfungsobjekts
Benutzer A führt einen Löschvorgang für den folgenden Pfad aus:
MyLakehouse\Files\MyShortcut
In diesem Fall wird MyShortcut aus dem Lakehouse gelöscht. Verknüpfungen führen keine kaskadierenden Löschvorgänge durch, weshalb die Dateien und Verzeichnisse im ADLS Gen2-Konto Foo\Bar davon unberührt bleiben.
Löschen von Inhalten, auf die von einer Verknüpfung verwiesen wird
Benutzer A führt einen Löschvorgang für den folgenden Pfad aus:
MyLakehouse\Files\MyShortcut\Foo\Bar
Wenn Benutzer A über Schreibberechtigungen im ADLS Gen2-Konto verfügt, wird in diesem Fall das Verzeichnis Bar aus dem ADLS Gen2-Konto gelöscht.
Arbeitsbereichsherkunftsansicht
Beim Erstellen von Verknüpfungen zwischen mehreren Fabric-Elementen in einem Arbeitsbereich können Sie die Verknüpfungsbeziehungen über die Arbeitsbereichsherkunftsansicht visualisieren. Wählen Sie in der oberen rechten Ecke des Arbeitsbereichs-Explorers die Schaltfläche Herkunftsansicht ( ) aus.
) aus.

Hinweis
Der Umfang der Herkunftsansicht ist auf einen einzelnen Arbeitsbereich beschränkt. Verknüpfungen mit Speicherorten außerhalb des ausgewählten Arbeitsbereichs werden nicht angezeigt.
Einschränkungen und Aspekte
- Die maximale Anzahl von Verknüpfungen pro Fabric-Element beträgt 100.000. In diesem Zusammenhang bezieht sich der Begriff „Element“ auf: Apps, Lakehouses, Warehouses, Berichte und vieles mehr.
- Die maximale Anzahl von Verknüpfungen in einem einzelnen OneLake-Pfad beträgt 10.
- Die maximale Anzahl direkter Verknüpfungen mit Verknüpfungslinks beträgt 5.
- ADLS- und S3-Verknüpfungszielpfade dürfen keine reservierten Zeichen aus RFC 3986, Abschnitt 2.2 enthalten. Zulässige Zeichen finden Sie im Abschnitt 2.3 von RFC 3968.
- OneLake-Verknüpfungsnamen, übergeordnete Pfade und Zielpfade dürfen keine „%“- oder „+“-Zeichen enthalten.
- Verknüpfungen unterstützen keine nicht lateinischen Zeichen.
- Die Copy Blob-API wird für ADLS- oder S3-Verknüpfungen nicht unterstützt.
- Die Kopierfunktion funktioniert nicht bei Verknüpfungen, die direkt auf ADLS-Container verweisen. Es wird empfohlen, ADLS-Verknüpfungen mit einem Verzeichnis zu erstellen, das mindestens eine Ebene unterhalb eines Containers liegt.
- Innerhalb von ADLS- oder S3-Verknüpfungen können keine zusätzlichen Verknüpfungen erstellt werden.
- Die Herkunft für Verknüpfungen zu Data Warehouses und Semantikmodellen ist derzeit nicht verfügbar.
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für