Azure Data Explorer-Connector für Apache Spark
Wichtig
Dieser Connector kann in Echtzeitanalyse in Microsoft Fabric verwendet werden. Verwenden Sie die Anweisungen in diesem Artikel mit den folgenden Ausnahmen:
- Erstellen Sie bei Bedarf Datenbanken mithilfe der Anweisungen unter Erstellen einer KQL-Datenbank.
- Erstellen Sie bei Bedarf Tabellen mithilfe der Anweisungen unter Erstellen einer leeren Tabelle.
- Rufen Sie Abfrage- oder Erfassungs-URIs mithilfe der Anweisungen unter Kopieren von URI ab.
- Führen Sie Abfragen in einem KQL-Abfrageset aus.
Apache Spark ist eine vereinheitlichte Engine zur Verarbeitung von umfangreichen Daten. Azure Data Explorer ist ein schneller, vollständig verwalteter Datenanalysedienst für Echtzeitanalysen großer Mengen an Daten.
Der Azure Data Explorer-Connector für Spark ist ein Open Source-Projekt, das auf jedem Spark-Cluster ausgeführt werden kann. Er implementiert Datenquellen und Datensenken zum Verschieben von Daten zwischen Azure Data Explorer und Spark-Clustern. Mit Azure Data Explorer und Apache Spark können Sie schnelle und skalierbare Anwendungen für datengesteuerte Szenarien erstellen. Beispiele dafür sind maschinelles Lernen (Machine Learning, ML), Extrahieren, Transformieren und Laden (Extract-Transform-Load, ETL) und Protokollanalysen (Log Analytics). Durch den Connector wird Azure Data Explorer ein gültiger Datenspeicher für Spark-Standardvorgänge für Quellen und Senken wie„write“, „read“ und „writeStream“.
Sie können über die Erfassung in die Warteschlange oder die Streamingerfassung in Azure Data Explorer schreiben. Das Lesen aus Azure Data Explorer unterstützt das Löschen von Spalten und die Prädikatweitergabe. Dabei werden die Daten in Azure Data Explorer gefiltert, wodurch die Menge der übertragenen Daten verringert wird.
Hinweis
Informationen zum Arbeiten mit dem Synapse Spark-Connector für Azure Data Explorer finden Sie unter Verbinden mit Azure Data Explorer mithilfe von Apache Spark für Azure Synapse Analytics.
In diesem Thema wird beschrieben, wie Sie den Azure Data Explorer-Connector für Spark installieren und konfigurieren und Daten zwischen Azure Data Explorer und Apache Spark-Clustern verschieben.
Hinweis
Obwohl sich einige der unten stehenden Beispiele auf einen Azure Databricks Spark-Cluster beziehen, akzeptiert Azure Data Explorer-Connector für Spark keine direkten Abhängigkeiten von Databricks oder einer anderen Spark-Distribution.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Datenbank Erstellen eines Clusters und einer Datenbank
- Ein Spark-Cluster
- Installieren Sie die Azure Data Explorer-Connectorbibliothek:
- Vordefinierte Bibliotheken für Spark 2.4 und Scala 2.11 oder Spark 3 und Scala 2.12
- Maven-Repository
- Maven 3.x-Installation
Tipp
Spark 2.3.x-Versionen werden ebenfalls unterstützt, erfordern aber möglicherweise Änderungen in den pom.xml-Abhängigkeiten.
Erstellen des Spark-Connectors
Ab Version 2.3.0 werden neue Artefakt-IDs eingeführt, die „spark-kusto-connector“ ersetzen: kusto-spark_3.0_2.12 für Spark 3.x und Scala 2.12 sowie kusto-spark_2.4_2.11 für Spark 2.4.x und Scala 2.11.
Hinweis
Versionen vor 2.5.1 funktionieren nicht mehr für die Erfassung in einer vorhandenen Tabelle. Führen Sie die Aktualisierung auf eine höhere Version durch. Dieser Schritt ist optional. Wenn Sie vorgefertigte Bibliotheken (etwa Maven) verwenden, finden Sie weitere Informationen unter Einrichtung des Spark-Clusters.
Buildvoraussetzungen
Wenn Sie keine vorgefertigten Bibliotheken verwenden, müssen Sie die unter Abhängigkeiten aufgeführten Bibliotheken installieren, einschließlich der folgenden Kusto Java SDK-Bibliotheken. Die richtige Version für die Installation finden Sie in der POM-Datei des entsprechenden Releases:
Ziehe Sie diese Quelle zum Erstellen des Spark-Connectors zurate.
Wenn Sie Scala-/Java-Anwendungen mit Maven-Projektdefinitionen verwenden, verknüpfen Sie Ihre Anwendung mit dem folgenden Artefakt (die neueste Version kann abweichen):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Erstellen von Befehlen
Führen Sie den folgenden Befehl aus, um die JAR-Datei zu erstellen und alle Tests auszuführen:
mvn clean package
Um die JAR-Datei zu erstellen, führen Sie alle Tests aus, und installieren Sie die JAR-Datei in Ihrem lokalen Maven-Repository:
mvn clean install
Weitere Informationen finden Sie unter Connectorverwendung.
Einrichtung des Spark-Clusters
Hinweis
Es wird empfohlen, die aktuelle Version des Azure Data Explorer-Connectors für Spark zu verwenden, wenn Sie die folgenden Schritte ausführen.
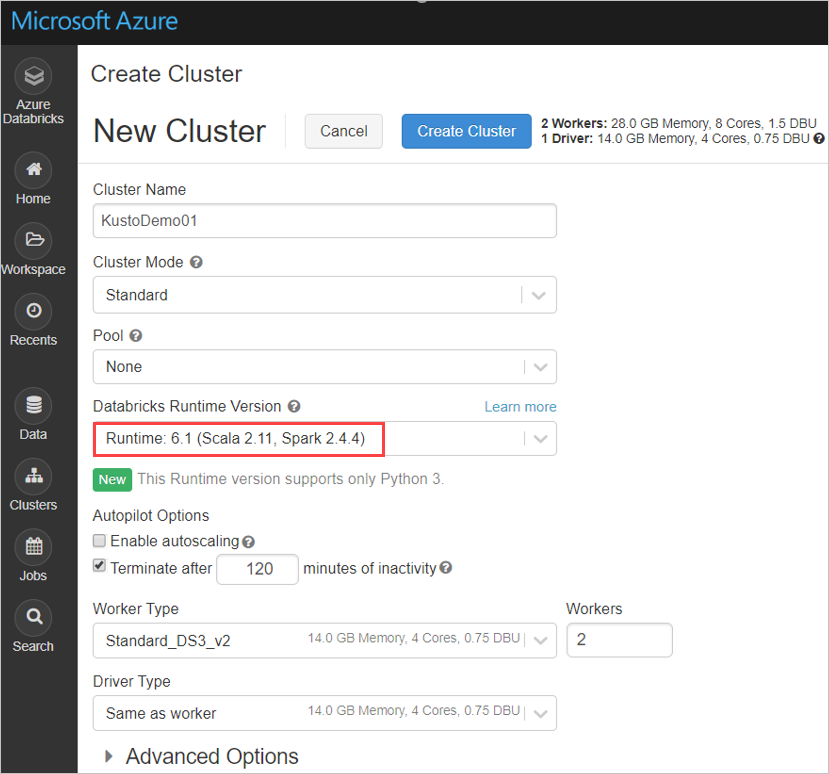
Konfigurieren Sie die folgenden Spark-Clustereinstellungen basierend auf dem Azure Databricks-Cluster unter Verwendung von Spark 2.4.4 und Scala 2.11 oder Spark 3.0.1 und Scala 2.12:
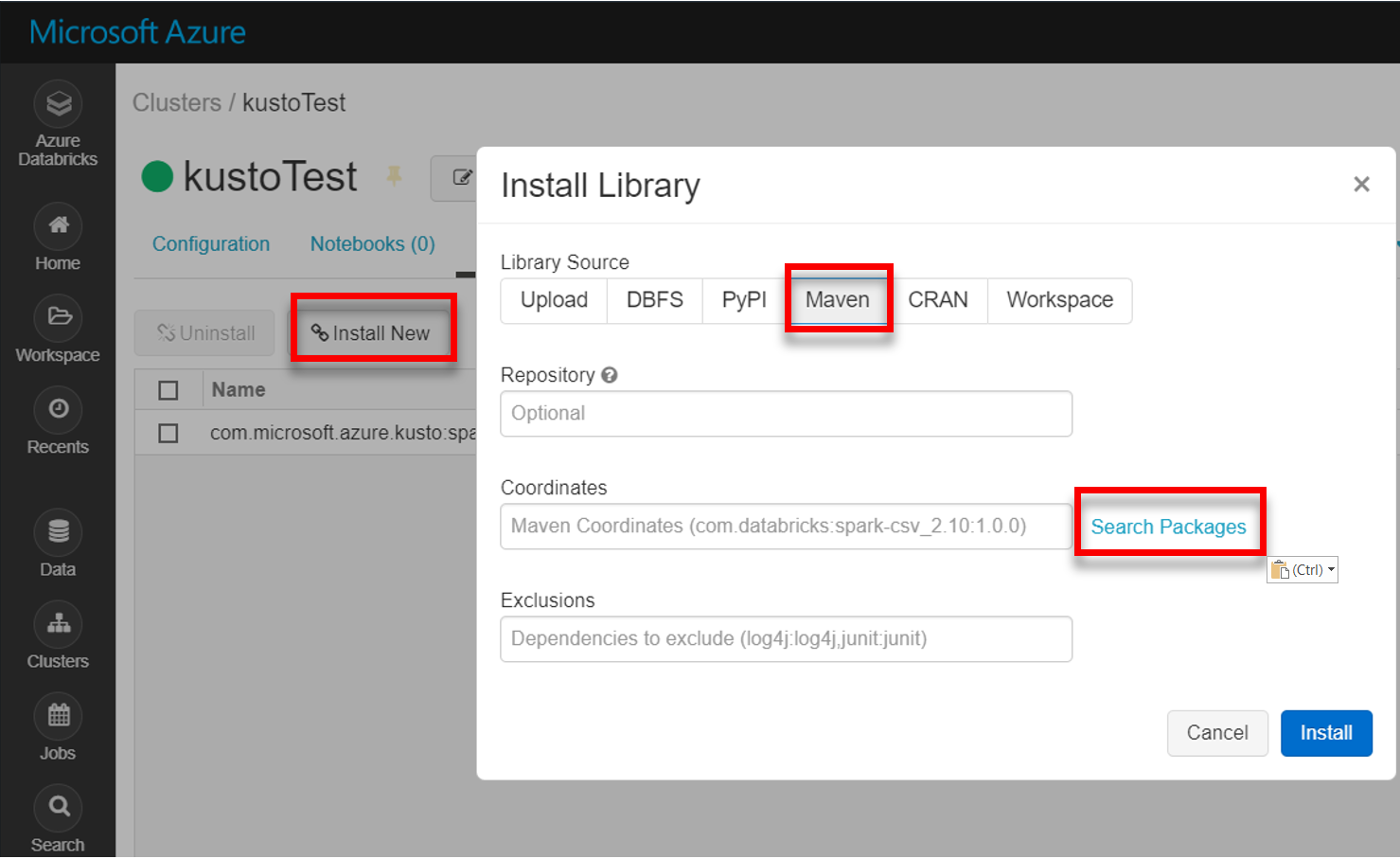
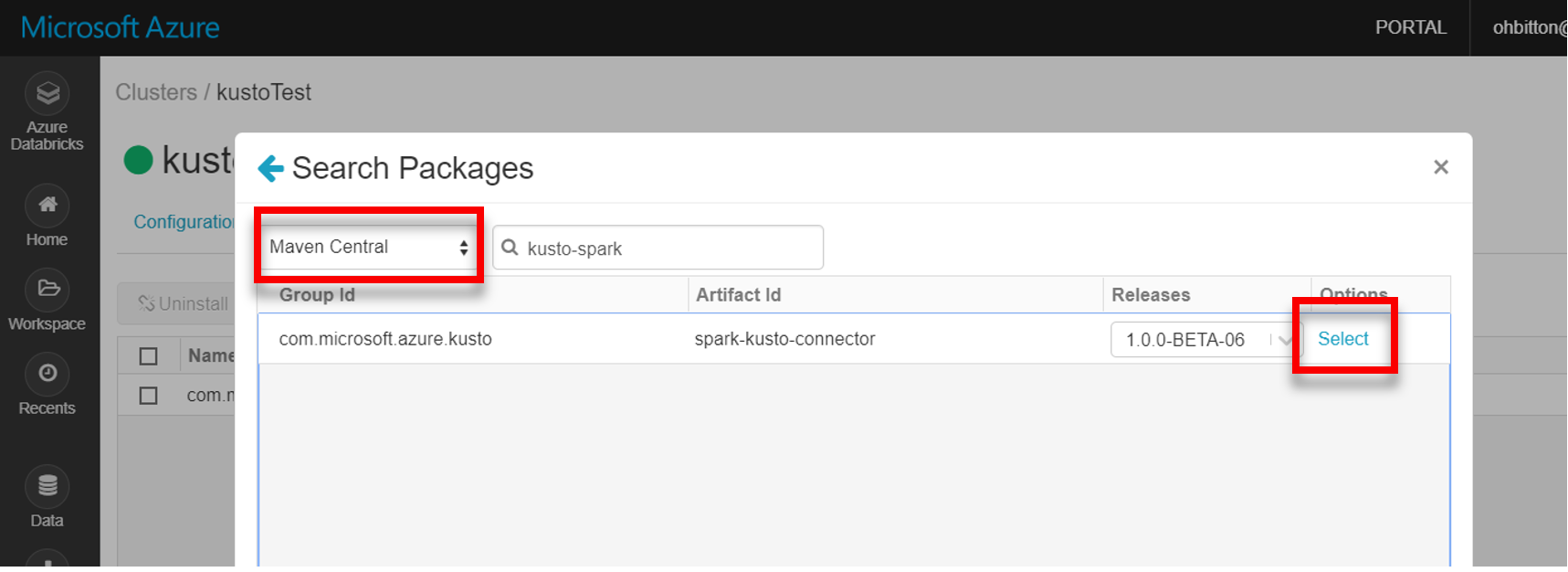
Installieren Sie die neueste Spark-Kusto-Connectorbibliothek von Maven:
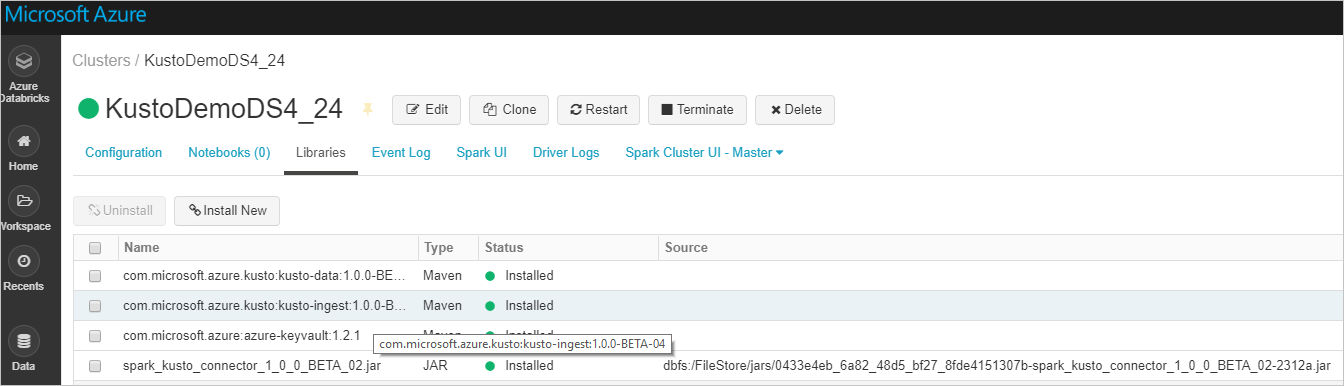
Überprüfen Sie, ob alle erforderlichen Bibliotheken installiert sind:
Überprüfen Sie bei der Installation mithilfe einer JAR-Datei, ob zusätzliche Abhängigkeiten installiert wurden:
Authentifizierung
Azure Data Explorer Spark-Connector ermöglicht Ihnen die Authentifizierung mit Microsoft Entra-ID mithilfe einer der folgenden Methoden:
- Eine Microsoft Entra Anwendung
- Ein Microsoft Entra-Zugriffstoken
- Geräteauthentifizierung (in Nicht-Produktionsszenarien)
- Azure Key Vault: Um auf die Key Vault-Ressource zugreifen zu können, müssen Sie das „azure-keyvault“-Paket installieren und die Anwendungsanmeldeinformationen bereitstellen.
Microsoft Entra Anwendungsauthentifizierung
Microsoft Entra Anwendungsauthentifizierung ist die einfachste und am häufigsten verwendete Authentifizierungsmethode und wird für den Azure Data Explorer Spark-Connector empfohlen.
| Eigenschaften | Optionszeichenfolge | BESCHREIBUNG |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra Anwendungsbezeichner (Client). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra Authentifizierungsberechtigung. Microsoft Entra Verzeichnis-ID (Mandant). Optional: Standardmäßig microsoft.com. Weitere Informationen finden Sie unter Microsoft Entra Autorität. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra Anwendungsschlüssel für den Client. |
Hinweis
Ältere API-Versionen (vor 2.0.0) haben den folgenden Namen: „kustoAADClientID“, „kustoClientAADClientPassword“, „kustoAADAuthorityID“.
Azure Data Explorer-Berechtigungen
Erteilen Sie die folgenden Berechtigungen für einen Azure Data Explorer-Cluster:
- Zum Lesen (Datenquelle) muss die Microsoft Entra Identität über Viewerberechtigungen für die Zieldatenbank oder Administratorrechte für die Zieltabelle verfügen.
- Zum Schreiben (Datensenke) muss die Microsoft Entra Identität über Ingestorberechtigungen für die Zieldatenbank verfügen. Außerdem benötigt sie Benutzerberechtigungen für die Zieldatenbank, um neue Tabellen zu erstellen. Wenn die Zieltabelle bereits vorhanden ist, müssen Sie Administratorberechtigungen für die Zieltabelle konfigurieren.
Weitere Informationen zu Azure Data Explorer Prinzipalrollen finden Sie unter Rollenbasierte Zugriffssteuerung. Informationen zum Verwalten von Sicherheitsrollen finden Sie unter Sicherheitsrollenverwaltung.
Spark-Senke: Schreiben in Azure Data Explorer
Einrichten von Senkenparametern:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Schreiben von Spark DataFrame in Azure Data Explorer-Cluster als Batch:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Oder verwenden Sie die vereinfachte Syntax:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Schreiben von Streamingdaten:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark-Senke: Lesen aus Azure Data Explorer
Wenn kleine Datenmengen gelesen werden, definieren Sie die Datenabfrage:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Optional: Wenn Sie den temporären Blobspeicher (und nicht Azure Data Explorer) bereitstellen, werden die Blobs in der Verantwortung des Aufrufers erstellt. Dies umfasst das Bereitstellen des Speichers, das Rotieren von Zugriffsschlüsseln und das Löschen temporärer Artefakte. Das KustoBlobStorageUtils-Modul enthält Hilfsfunktionen zum Löschen von Blobs, die entweder auf Konto- und Containerkoordinaten und Kontoanmeldeinformationen oder einer vollständigen SAS-URL mit Schreib-, Lese- und Listenberechtigungen basieren. Wenn das entsprechende RDD nicht mehr benötigt wird, speichert jede Transaktion temporäre Blobartefakte in einem separaten Verzeichnis. Dieses Verzeichnis wird als Teil der Lesetransaktionsinformationsprotokolle erfasst, die auf dem Spark-Treiberknoten gemeldet werden.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Im obigen Beispiel erfolgt der Zugriff auf den Schlüsseltresor nicht über die Connectorschnittstelle. Es wird eine einfachere Methode der Verwendung der Databricks-Geheimnisse verwendet.
Lesen aus Azure Data Explorer.
Wenn Sie den temporären Blobspeicher bereitstellen, lesen Sie die Daten aus Azure Data Explorer wie folgt:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Wenn Azure Data Explorer den temporären Blobspeicher bereitstellt, lesen Sie die Daten aus Azure Data Explorer wie folgt:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)
Verwandte Inhalte
- GitHub-Repository des Azure Data Explorer Spark-Connectors
- Sehen Sie sich den Beispielcode für Scala und Python an.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für