Hochverfügbarkeit in Azure Database for PostgreSQL (Einzelserver)
GILT FÜR: Azure Database for PostgreSQL – Single Server
Azure Database for PostgreSQL – Single Server
Wichtig
Azure Database for PostgreSQL – Single Server wird eingestellt. Es wird dringend empfohlen, ein Upgrade auf Azure Database for PostgreSQL – Flexible Server auszuführen. Weitere Informationen zum Migrieren zu Azure Database for PostgreSQL – Flexible Server finden Sie unter Was geschieht mit Azure Database for PostgreSQL – Single Server?
Der Dienst Azure Database for PostgreSQL – Single Server bietet eine garantierte Hochverfügbarkeit mit der finanziell abgesicherten Vereinbarung zum Servicelevel (Service Level Agreement, SLA) für die Uptime. Azure Database for PostgreSQL bietet Hochverfügbarkeit sowohl bei geplanten Ereignissen wie benutzerseitig initiierten Skalierungscomputevorgängen als auch bei ungeplanten Ereignissen wie Ausfällen von zugrunde liegender Hardware oder Software oder Netzwerkausfällen. Der Dienst kann auch nach den kritischsten Umständen schnell wiederhergestellt werden, wodurch sichergestellt ist, dass es bei dessen Verwendung zu so gut wie keiner Anwendungsdowntime kommt.
Azure Database for PostgreSQL eignet sich für das Ausführen von unternehmenskritischen Datenbanken, die eine hohe Uptime erfordern. Der Dienst basiert auf der Azure-Architektur und verfügt über inhärente Hochverfügbarkeit, Redundanz und Resilienz, um die Datenbankdowntime aufgrund von geplanten und ungeplanten Ausfällen zu minimieren, ohne dass Sie zusätzliche Komponenten konfigurieren müssen.
Komponenten in Azure Database for PostgreSQL (Einzelserver)
| Komponente | Beschreibung |
|---|---|
| PostgreSQL-Datenbankserver | Azure Database for PostgreSQL bietet Sicherheit, Isolation, Ressourcenschutzvorrichtungen und ein schnelles Neustarten für Datenbankserver. Diese Funktionen ermöglichen das Ausführen von Vorgängen wie Skalierung und Wiederherstellung von Datenbankservern nach einem Ausfall innerhalb weniger Sekunden. Änderungen an Daten auf dem Datenbankserver finden in der Regel im Rahmen von Datenbanktransaktionen statt. Alle Änderungen an der Datenbank werden synchron in Form von Write-Ahead-Protokollen (Write-Ahead Log, WAL) im Dienst Azure Storage aufgezeichnet, der an den Datenbankserver angefügt ist. Während des Prüfpunktprozesses für die Datenbank werden außerdem Datenseiten aus dem Arbeitsspeicher des Datenbankservers in den Speicher geleert. |
| Remotespeicher | Alle physischen PostgreSQL-Datendateien und WAL-Dateien werden in Azure Storage gespeichert. Dieser Dienst ist so konzipiert, dass er drei Kopien der Daten in einer Region speichert, um die Redundanz, Verfügbarkeit und Zuverlässigkeit der Daten zu gewährleisten. Außerdem ist die Speicherebene unabhängig vom Datenbankserver. Sie kann von einem ausgefallenen Datenbankserver getrennt und innerhalb weniger Sekunden an einen neuen Datenbankserver angefügt werden. Darüber hinaus prüft Azure Storage die Daten kontinuierlich auf Speicherfehler. Wenn eine Blockbeschädigung erkannt wird, wird diese automatisch durch Instanziieren einer neuen Speicherkopie behoben. |
| Gateway | Das Gateway fungiert als Datenbankproxy und leitet alle Clientverbindungen an den Datenbankserver weiter. |
Minimierung von geplanter Downtime
Azure Database for PostgreSQL ist so konzipiert, dass bei geplanten Vorgängen mit Downtime Hochverfügbarkeit gewährleistet ist.
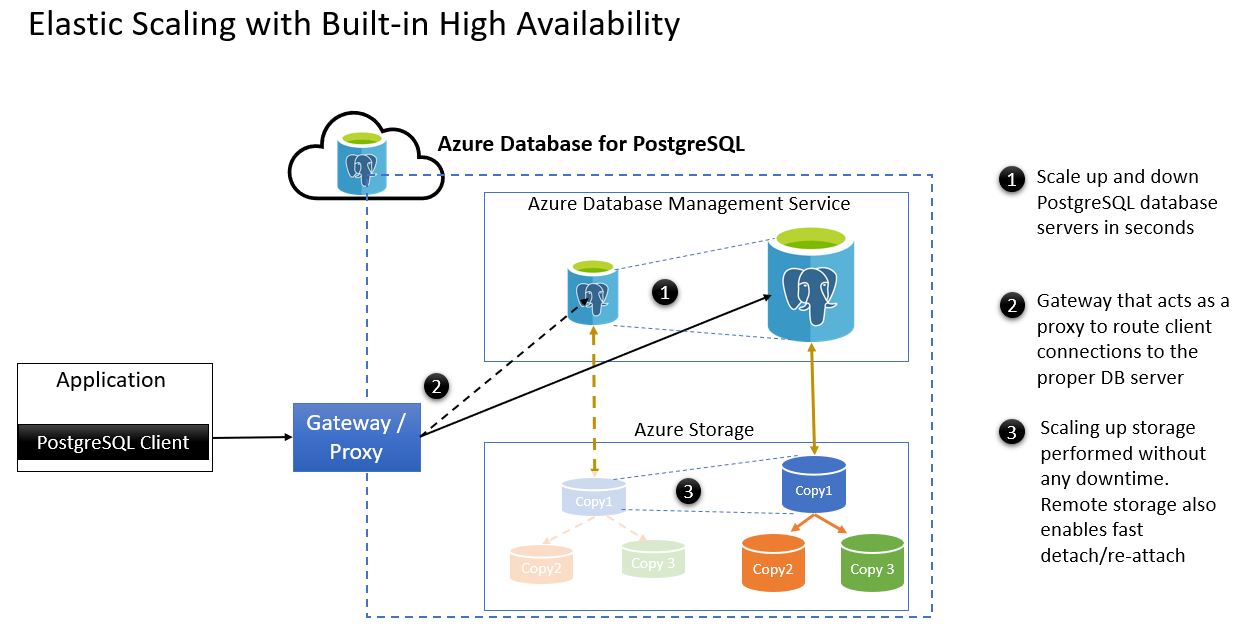
- Sekundenschnelles Hoch- und Herunterskalieren von PostgreSQL-Datenbankservern
- Gateway, das als Proxy fungiert und Clientverbindungen an den richtigen Datenbankserver weiterleitet
- Hochskalieren des Speichers ohne Downtime. Mithilfe von Remotespeicher ist nach einem Failover ein schnelles Trennen/Neuanfügen möglich. Hier finden Sie einige Szenarien mit geplanter Wartung:
| Szenario | Beschreibung |
|---|---|
| Hoch-/Herunterskalieren von Computeressourcen | Wenn ein Benutzer den Vorgang zum Hoch- bzw. Herunterskalieren von Computeressourcen ausführt, wird ein neuer Datenbankserver mit der skalierten Computekonfiguration bereitgestellt. Auf dem alten Datenbankserver können aktive Prüfpunkte abgeschlossen werden, Clientverbindungen werden entladen, alle Transaktionen ohne Commit werden abgebrochen, und anschließend wird der Server heruntergefahren. Der Speicher wird dann vom alten Datenbankserver getrennt und an den neuen Datenbankserver angefügt. Wenn die Clientanwendung versucht, die Verbindung wiederherzustellen oder eine neue Verbindung herzustellen, leitet das Gateway die Verbindungsanforderung an den neuen Datenbankserver weiter. |
| Hochskalieren des Speichers | Das Hochskalieren des Speichers ist ein Onlinevorgang, bei dem der Datenbankserver nicht unterbrochen wird. |
| Bereitstellung neuer Software (Azure) | Rollouts von neuen Features oder Fehlerbehebungen werden automatisch im Rahmen der geplanten Wartung des Diensts durchgeführt. Weitere Informationen finden Sie in der Dokumentation und im Portal. |
| Upgrades von Nebenversionen | Azure Database for PostgreSQL patcht Datenbankserver automatisch auf die von Azure festgelegte Nebenversion. Dies erfolgt im Rahmen der geplanten Wartung des Diensts. Dabei kommt es zu einer kurzen Downtime von ein paar Sekunden. Danach wird der Datenbankserver automatisch mit der neuen Nebenversion neu gestartet. Weitere Informationen finden Sie in der Dokumentation und im Portal. |
Minimierung von ungeplanter Downtime
Ungeplante Downtime kann aufgrund von unvorhergesehenen Fehlern auftreten, darunter Fehler in der zugrunde liegenden Hardware, Netzwerkprobleme und Softwarefehler. Wenn der Datenbankserver unerwartet ausfällt, wird automatisch innerhalb weniger Sekunden ein neuer Datenbankserver bereitgestellt. Der Remotespeicher wird automatisch an den neuen Datenbankserver angefügt. Die PostgreSQL-Engine führt den Wiederherstellungsvorgang mithilfe von WAL-Dateien und Datenbankdateien durch und öffnet den Datenbankserver, sodass Clients eine Verbindung herstellen können. Nicht committete Transaktionen gehen verloren und müssen von der Anwendung erneut ausgeführt werden. Ungeplante Downtime kann zwar nicht vermieden werden, Azure Database for PostgreSQL minimiert diese jedoch durch automatisches Ausführen von Wiederherstellungsvorgängen sowohl auf Ebene der Datenbankserver als auch auf der Speicherebene, ohne dass ein menschliches Eingreifen erforderlich ist.
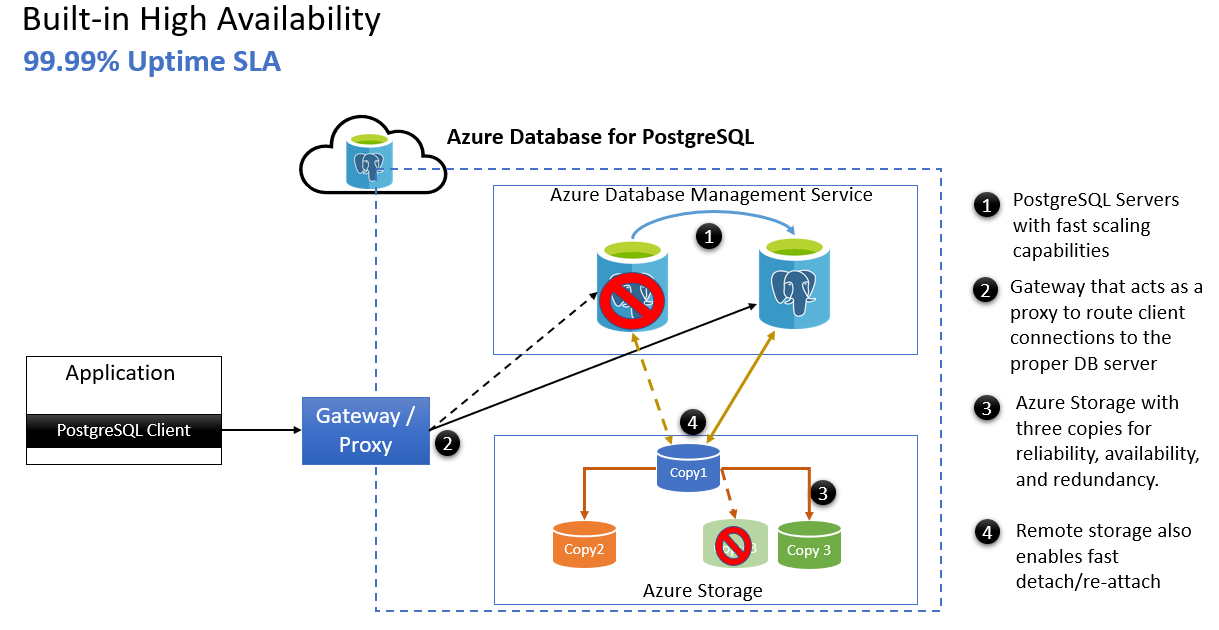
- Azure PostgreSQL-Server mit schnell skalierenden Funktionen
- Gateway, das als Proxy fungiert und Clientverbindungen an den richtigen Datenbankserver weiterleitet
- Azure-Speicher mit drei Kopien für eine höhere Zuverlässigkeit, Verfügbarkeit und Redundanz
- Mithilfe von Remotespeicher ist nach einem Serverfailover ein schnelles Trennen/Neuanfügen möglich.
Ungeplante Downtime: Fehlerszenarios und Dienstwiederherstellung
Im Folgenden sind einige Fehlerszenarios und die automatische Wiederherstellung von Azure Database for PostgreSQL im entsprechenden Fall aufgeführt:
| Szenario | Automatische Wiederherstellung |
|---|---|
| Ausfall des Datenbankservers | Wenn der Datenbankserver aufgrund eines Fehlers an der zugrunde liegenden Hardware ausfällt, werden die aktiven Verbindungen getrennt, und alle Transaktionen, die gerade ausgeführt werden, werden abgebrochen. Ein neuer Datenbankserver wird automatisch bereitgestellt, und der Remotedatenspeicher wird an den neuen Datenbankserver angefügt. Sobald die Datenbank wiederhergestellt wurde, können Clients über das Gateway eine Verbindung mit dem neuen Datenbankserver herstellen. Die Wiederherstellungszeit (Recovery Time Objective, RTO) hängt von verschiedenen Faktoren ab, z. B. der Aktivität zum Zeitpunkt des Fehlers. Zu diesen Aktivitäten zählen große Transaktionen und die Anzahl der Wiederherstellungsvorgänge, die während des Starts des Datenbankservers ausgeführt wurden. Anwendungen, die die PostgreSQL-Datenbanken verwenden, müssen so konzipiert sein, dass sie getrennte Verbindungen und Transaktionsfehler erkennen und entsprechende Wiederholungsversuche durchführen. Wenn die Anwendung einen Wiederholungsversuch durchführt, leitet das Gateway die Verbindung transparent an den neu erstellten Datenbankserver um. |
| Speicherfehler | Speicherbezogene Probleme wie der Ausfall eines Datenträgers oder physische Blockbeschädigungen haben keine Auswirkungen auf Anwendungen. Da drei Kopien der Daten gespeichert werden, wird eine Kopie der Daten vom verbleibenden Speicher bereitgestellt. Blockbeschädigungen werden automatisch behoben. Wenn eine Kopie der Daten verloren geht, wird automatisch eine neue erstellt. |
| Computefehler | Computefehler kommen selten vor. Im Falle eines Computefehlers wird ein neuer Computecontainer bereitgestellt, und der Speicher mit Datendateien wird diesem zugeordnet. Die PostgreSQL-Datenbank-Engine wird dann im neuen Container online geschaltet, und der Gatewaydienst stellt ein transparentes Failover ohne Anwendungsänderungen sicher. Beachten Sie auch, dass die Computeebene integrierte Resilienz für Verfügbarkeitszonen aufweist und im Falle eines AZ-Computefehlers ein neuer Computevorgang in einer anderen Verfügbarkeitszone gestartet wird. |
Im Folgenden finden Sie einige Fehlerszenarien, bei denen für die Wiederherstellung eine Benutzeraktion erforderlich ist:
| Szenario | Plan für die Wiederherstellung |
|---|---|
| Regionsausfall | Regionen fallen nur selten aus. Wenn Sie jedoch Schutz vor einem Regionsausfall benötigen, können Sie ein oder mehrere Lesereplikate in anderen Regionen für die Notfallwiederherstellung konfigurieren. (Weitere Informationen finden Sie in diesem Artikel zum Erstellen und Verwalten von Lesereplikaten.) Bei einem Ausfall auf Regionsebene können Sie das in der anderen Region konfigurierte Lesereplikat manuell zum Produktionsdatenbankserver höher stufen. |
| Verfügbarkeitszonenfehler | Ein Ausfall einer Verfügbarkeitszone ist ebenfalls ein seltenes Ereignis. Wenn Sie jedoch Schutz vor einem Ausfall einer Verfügbarkeitszone benötigen, können Sie mindestens ein Lesereplikat konfigurieren oder unser Angebot Flexibler Server nutzen, das zonenredundante Hochverfügbarkeit bietet. |
| Logische Fehler/Benutzerfehler | Die Wiederherstellung bei Benutzerfehlern, z. B. versehentlich gelöschten Tabellen oder falsch aktualisierten Daten, umfasst das Durchführen einer Zeitpunktwiederherstellung, bei der die Daten bis zu einem Zeitpunkt kurz vor dem Fehler wiederhergestellt werden. Wenn Sie anstelle aller Datenbanken auf dem Datenbankserver nur eine Teilmenge von Datenbanken oder bestimmte Tabellen wiederherstellen möchten, können Sie den Datenbankserver in einer neuen Instanz wiederherstellen, die Tabelle(n) über pg_dump exportieren und sie dann über pg_restore in Ihrer Datenbank wiederherstellen. |
Zusammenfassung
Azure Database for PostgreSQL bietet einen schnellen Neustart von Datenbankservern, redundanten Speicher und effizientes Routing über das Gateway. Für zusätzlichen Schutz von Daten können Sie Sicherungen so konfigurieren, dass sie georepliziert werden, und ein oder mehrere Lesereplikate in anderen Regionen bereitstellen. Mithilfe der inhärenten Hochverfügbarkeitsfunktionen schützt Azure Database for PostgreSQL Ihre Datenbanken vor den häufigsten Arten von Ausfällen und bietet eine branchenführende, finanziell abgesicherte SLA über 99,99 % Uptime. Dank all dieser Verfügbarkeits- und Zuverlässigkeitsfunktionen ist Azure die ideale Plattform für das Ausführen Ihrer unternehmenskritischen Anwendungen.
Nächste Schritte
- Erfahren Sie mehr über Azure-Regionen.
- Erfahren Sie mehr über Behandlung vorübergehender Verbindungsfehler
- Erfahren Sie, wie Sie Ihre Daten mit Lesereplikaten replizieren