Anwenden von Erkenntnissen in Power BI zum Ermitteln von Verteilungsabweichungen
GILT FÜR:![]() ️ Power BI Desktop
️ Power BI Desktop ![]() Power BI-Dienst
Power BI-Dienst
Visuals veranschaulichen oft Datenpunkte. Doch ist die Verteilung für verschiedene Kategorien gleich? Mit Erkenntnissen erhalten Sie in Power BI mit wenigen Klicks Aufschluss.
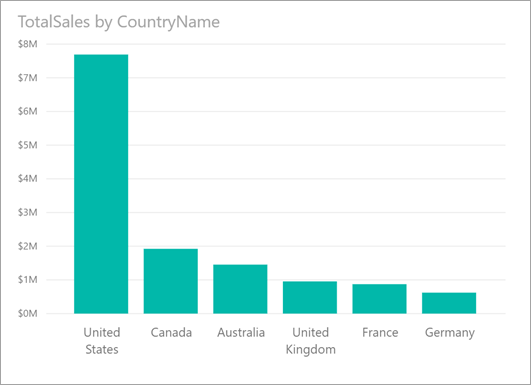
Betrachten Sie das folgende Visual, das den Gesamtumsatz pro Land veranschaulicht. Die meisten Umsätze stammen aus den USA – 57 % des Gesamtumsatzes. Der Anteil der anderen Länder/Regionen ist geringer. In solchen Fällen ist es oft interessant zu untersuchen, ob die gleiche Verteilung für verschiedene Teilpopulationen angezeigt wird. Gilt dies beispielsweise gleichermaßen für alle Jahre, alle Vertriebskanäle und alle Produktkategorien? Sie können zwar verschiedene Filter anwenden und die Ergebnisse visuell vergleichen, doch dieser Ansatz kann zeitaufwendig und fehleranfällig sein.
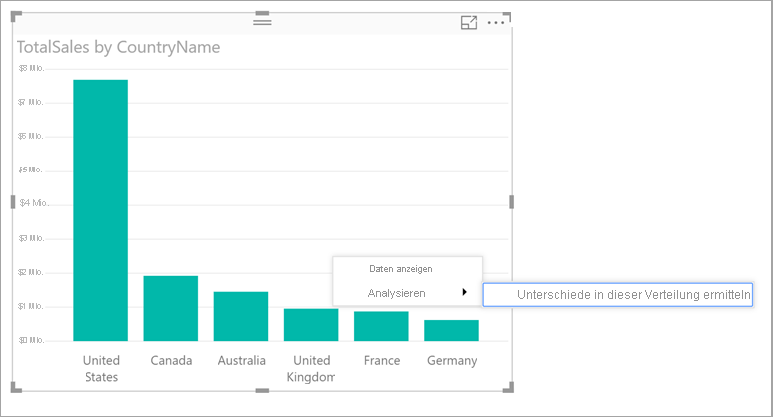
Sie können in Power BI Unterschiede in der Verteilung ermitteln und schnell automatische aussagekräftige Analysen der Daten erhalten. Klicken Sie mit der rechten Maustaste auf einen Datenpunkt, und wählen Sie Analysieren>Unterschiede in dieser Verteilung ermitteln aus. Daraufhin werden die Erkenntnisse in einem benutzerfreundlichen Fenster angezeigt.
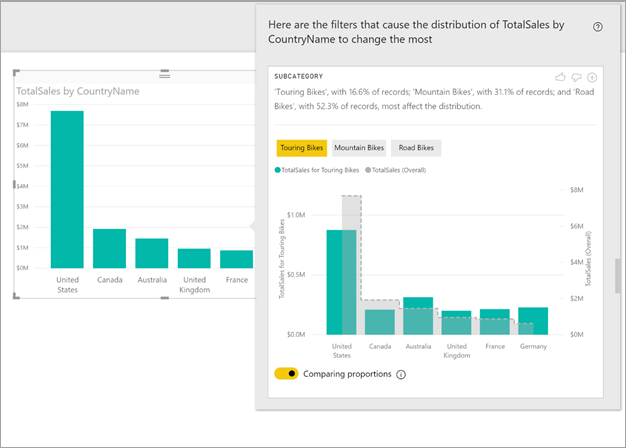
In diesem Beispiel zeigt die automatisierte Analyse, dass bei Tourenrädern der Umsatzanteil in den USA und Kanada geringer ist als der Anteil aus den anderen Ländern/Regionen.
Verwenden von Erkenntnissen
Um mithilfe von Erkenntnissen Verteilungsunterschiede in Diagrammen zu ermitteln, klicken Sie einfach mit der rechten Maustaste auf einen beliebigen Datenpunkt oder auf das Visual als Ganzes. Wählen Sie dann Analysieren>Unterschiede in dieser Verteilung ermitteln.
Power BI führt seine Algorithmen mit maschinellem Lernen für die Daten aus. Power BI füllt dann ein Fenster mit einem Visual und einer Beschreibung dazu, welche Kategorien (Spalten) und welche Werte in den Spalten zu den größten Unterschieden in der Verteilung führen. Erkenntnisse werden als Säulendiagramm bereitgestellt, wie in der folgenden Abbildung gezeigt:
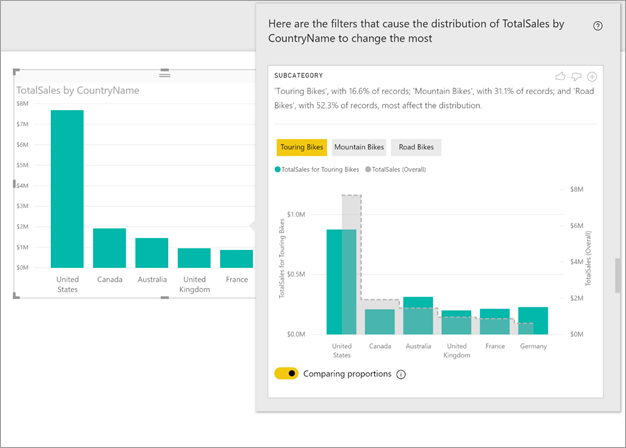
Die Werte mit dem ausgewählten Filter werden mit der Standardfarbe angezeigt. Die Gesamtwerte, wie auf dem ursprünglichen Visual zu sehen, werden zur besseren Vergleichbarkeit grau dargestellt. Bis zu drei verschiedene Filter sind möglich (in diesem Beispiel Tourenräder, Mountainbikes, Rennräder). Filter können durch Auswahl eines Datenpunkts (oder mehrere durch STRG + Klick) angewendet werden.
Bei einfachen additiven Measures (in diesem Beispiel Gesamtumsatz) basiert der Vergleich auf den relativen – statt absoluten – Werten. Die Verkäufe für Tourenräder sind niedriger als die Gesamtverkäufe für alle Kategorien. Das Visual verwendet standardmäßig eine Doppelachse, um den Umsatzanteil in verschiedenen Ländern/Regionen vergleichen zu können. Dies wird für Tourenräder im Vergleich zu allen Fahrradkategorien verwendet. Durch Aktivieren der Umschaltfläche unter dem Visual können die beiden Werte in der gleichen Achse angezeigt werden, sodass sich die absoluten Werte leicht vergleichen lassen (siehe folgendes Bild).
Der beschreibende Text weist auch auf die Bedeutung eines Filterwerts hin, indem die Anzahl der Datensätze angegeben wird, die dem Filter entsprechen. In diesem Beispiel können Sie sehen, dass die Verteilung für Tourenräder zwar Unterschiede aufweist, dies jedoch nur für 16,6 % der Datensätze gilt.
Mit den Symbolen Daumen hoch und Daumen runter am oberen Rand der Seite können Sie Feedback über das Visual und das Feature geben. Der Algorithmus wird jedoch nicht für die künftige Verwendung dieser Funktion trainiert, so dass keine Beeinflussung der Ergebnisse erfolgt.
Insbesondere können Sie das ausgewählte Visual mit der Schaltfläche + am oberen Rand des Visuals Ihrem Bericht hinzufügen, ganz so als hätten Sie es manuell erstellt. Anschließend können Sie das hinzugefügte Visual wie jedes andere Visual im Bericht formatieren oder anpassen. Sie können ein ausgewähltes Visual mit Erkenntnissen nur während der Bearbeitung eines Berichts in Power BI hinzufügen.
Sie können Erkenntnisse verwenden, wenn sich Ihr Bericht im Lese- oder Bearbeitungsmodus befindet. Dies bietet Ihnen die Flexibilität, sowohl Daten zu analysieren als auch Visuals zu erstellen, die Sie den Berichten hinzufügen können.
Details zu zurückgegebenen Ergebnissen
Der Algorithmus berücksichtigt im Grunde alle anderen Modellspalten, wendet sie auf alle Werte dieser Spalten als Filter für das ursprüngliche Visual an. Der Algorithmus ermittelt dann, welcher dieser Filterwerte den größten Unterschied im Vergleich zum Original aufweisen.
Doch was genau bedeutet unterschiedlich? Angenommen, dass die Gesamtaufteilung der Umsätze zwischen den USA und Kanada folgendermaßen aussieht:
| Land/Region | Umsatz (Mio. $) |
|---|---|
| USA | 15 |
| Canada | 5 |
Dann sieht die Umsatzaufteilung für eine bestimmte Produktkategorie („Rennräder“) möglicherweise so aus:
| Land/Region | Umsatz (Mio. $) |
|---|---|
| USA | 3 |
| Canada | 1 |
Während die Zahlen in jeder dieser Tabellen unterschiedlich sind, sind die relativen Werte für die USA und Kanada identisch: 75 % und 25 % insgesamt und für Rennräder. Daher werden diese nicht als unterschiedlich angesehen. Für einfache additive Measures wie diese sucht der Algorithmus nach Unterschieden im relativen Wert.
Betrachten Sie dagegen Measures wie die Marge, die als Gewinn/Verlust berechnet wird. Wenn die Gesamtmargen für die USA und Kanada wie folgt wären:
| Land/Region | Marge (%) |
|---|---|
| USA | 15 |
| Canada | 5 |
Dann sieht die Umsatzaufteilung für eine bestimmte Produktkategorie („Rennräder“) möglicherweise so aus:
| Land/Region | Marge (%) |
|---|---|
| USA | 3 |
| Canada | 1 |
Solche Measures weisen einen interessanten Unterschied auf. Für nicht additive Measures wie in diesem Margenbeispiel sucht der Algorithmus nach Unterschieden im absoluten Wert.
Die angezeigten Visuals sollen somit die Unterschiede zwischen der Gesamtverteilung (wie im ursprünglichen Visual zu sehen) und dem Wert unter Anwendung des jeweiligen Filters veranschaulichen.
Für additive Measures, z. B. Umsatz im vorherigen Beispiel, wird ein Säulen- und Liniendiagramm verwendet. Mit einer Doppelachse mit entsprechender Skalierung können relative Werte verglichen werden. Die Säulen zeigen den Wert mit dem angewandten Filter und die Linie den Gesamtwert an. Die Spaltenachse befindet sich wie gewohnt auf der linken Seite, und die Linienachse befindet sich auf der rechten Seite. Die angezeigte Linie verwendet ein abgestuftes Format mit einer gestrichelten Linie mit grauer Füllung. Wenn im vorherigen Beispiel der Maximalwert der Säulendiagrammachse 4 und der der Liniendiagrammachse 20 ist, können die relativen Werte für die USA und Kanada einfach für die gefilterten und die Gesamtwerte verglichen werden.
Für nicht additive Measures wie die Marge im vorherigen Beispiel wird ebenfalls ein Säulen- und Liniendiagramm verwendet, wobei die Verwendung einer einzelnen Achse bedeutet, dass die absoluten Werte leicht verglichen werden können. Die grau gefüllte Zeile zeigt den Gesamtwert an. Ob nun die tatsächlichen oder die relativen Zahlen verglichen werden: Bei der Bestimmung des Grades, in dem sich zwei Verteilungen unterscheiden, geht es nicht nur um die Berechnung der Differenz der Werte. Beispiel:
Bei Berücksichtigung der Grundpopulation ist ein Unterschied weniger statistisch signifikant und weniger interessant, wenn er für einen kleineren Anteil der Population gilt. Beispielsweise kann die Verteilung der Verkäufe auf länder-/regionsübergreifend für ein bestimmtes Produkt unterschiedlich sein. Dies wäre nicht interessant, wenn es Tausende von Produkten gäbe, sodass ein bestimmtes Produkt nur einen kleinen Prozentsatz des Gesamtumsatzes auszahlte.
Unterschiede in Kategorien, in denen die ursprünglichen Werte sehr hoch oder sehr nahe bei Null waren, werden höher gewichtet als andere. Wenn beispielsweise ein Land/Region nur 1 % des Gesamtumsatzes ausmacht, aber 6 % zu einem bestimmten Produkttyp beiträgt, ist das statistisch bedeutsamer und daher interessanter als ein Land/Region, dessen Anteil von 50 % auf 55 % gestiegen ist.
Verschiedene Heuristiken werden verwendet, um die aussagekräftigsten Ergebnisse auszuwählen, z. B. unter Berücksichtigung anderer Beziehungen zwischen den Daten.
Nachdem verschiedene Spalten und die jeweiligen Werte untersucht wurden, werden die Werte ausgewählt, die die größten Unterschiede aufweisen. Zum besseren Verständnis werden diese dann als gruppierte Säulen ausgegeben, wobei die Säule, deren Werte den größten Unterschied ergeben, zuerst angezeigt wird. Pro Spalte werden bis zu drei Werte angezeigt, es können jedoch auch weniger angezeigt werden, wenn es weniger als drei Werte gibt, die eine große Bedeutung haben, oder wenn einige Werte viel wirkungsvoller sind als andere.
Möglicherweise werden nicht alle Spalten des Modells in der verfügbaren Zeit untersucht, sodass die bedeutendsten Spalten und Werte ggf. nicht angezeigt werden. Allerdings werden verschiedene Heuristiken eingesetzt, um sicherzustellen, dass die wahrscheinlichsten Spalten zuerst untersucht werden. Angenommen, dass nach Prüfung aller Spalten festgestellt wird, dass die folgenden Spalte/Werte den größten Einfluss auf die Verteilung haben (in absteigender Reihenfolge):
Subcategory = Touring Bikes
Channel = Direct
Subcategory = Mountain Bikes
Subcategory = Road Bikes
Subcategory = Kids Bikes
Channel = Store
Die ausgegebene Spaltenreihenfolge wäre wie folgt:
Subcategory: Touring Bikes, Mountain Bikes, Road Bikes. (Hier werden nur drei aufgeführt, zusammen mit dem Text „…amongst others“ (unter anderem), um darauf hinzuweisen, dass mehr als drei hier erhebliche Auswirkungen haben.)
Channel = Direct (Nur „Direct“ wird hier aufgeführt, wenn die dazugehörige Auswirkung größer als die von „Store“ ist.)
Überlegungen und Einschränkungen
In der folgenden Liste sind die Szenarien aufgeführt, die derzeit für Einblicke nicht unterstützt werden:
- TopN-Filter
- Kennzahlenfilter
- Nicht numerische Measures
- Verwendung von „Wert anzeigen als“
- Gefilterte Measures – Hierbei handelt es sich um Berechnungen auf Visualebene, auf die ein bestimmter Filter angewendet wurde (z. B. Gesamtumsatz Frankreich). Gefilterte Measures werden in einigen Visuals verwendet, die vom Feature „Erkenntnisse“ erstellt werden.
Außerdem werden die folgenden Modelltypen und Datenquellen für Einblicke derzeit nicht unterstützt:
- DirectQuery
- Live Connect
- Lokale Reporting Services
- Einbetten
Zugehöriger Inhalt
Weitere Informationen finden Sie unter: